Spring Boot 使用阿里巴巴 Druid 数据源
Posted 认真对待世界的小白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring Boot 使用阿里巴巴 Druid 数据源相关的知识,希望对你有一定的参考价值。
Druid 是 Java 语言中最好的数据库连接池。Druid 能够提供强大的监控和扩展功能。
1、引入依赖
<dependency> <groupId>com.alibaba</groupId> <artifactId>druid-spring-boot-starter</artifactId> <version>1.1.10</version> </dependency>
2、配置数据源的基本参数
server: port: 8771 #Spring spring: datasource: username: dev password: 123456 url: jdbc:mysql://localhost:3306/htcpp?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC type: com.alibaba.druid.pool.DruidDataSource druid: #最大活跃数 max-active: 20 #初始化数量 initial-size: 1 #最大连接等待超时时间 max-wait: 60000 min-idle: 1 #配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 time-between-eviction-runs-millis: 60000 #配置一个连接在池中最小生存的时间,单位是毫秒 min-evictable-idle-time-millis: 300000 #打开PSCache,并且指定每个连接PSCache的大小 pool-prepared-statements: true max-open-prepared-statements: 20 test-while-idle: true test-on-borrow: false test-on-return: false async-init: true #配置监控统计拦截的filters filters: stat,wall,log4j
这样已经可以使用 Druid 了,如果还需要使用 Druid 的监控功能,还需要额外的配置。
引入配置类,当然这些配置完全可以在配置文件中进行设置,可以自由选择是写在类中或者配置文件中。
package com.haitaiinc.clinicpathservice.config; import com.alibaba.druid.support.http.StatViewServlet; import com.alibaba.druid.support.http.WebStatFilter; import org.springframework.boot.web.servlet.FilterRegistrationBean; import org.springframework.boot.web.servlet.ServletRegistrationBean; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @Configuration public class DruidConfiguration { @Bean public ServletRegistrationBean statViewServlet() { //创建servlet注册实体 ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*"); //设置ip白名单 servletRegistrationBean.addInitParameter("allow", "127.0.0.1"); //设置ip黑名单,如果allow与deny共同存在时,deny优先于allow servletRegistrationBean.addInitParameter("deny", "192.168.0.19"); //设置控制台管理用户 servletRegistrationBean.addInitParameter("loginUsername", "admin"); servletRegistrationBean.addInitParameter("loginPassword", "123456"); //是否可以重置数据 servletRegistrationBean.addInitParameter("resetEnable", "false"); return servletRegistrationBean; } @Bean public FilterRegistrationBean statFilter() { //创建过滤器 FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(new WebStatFilter()); //设置过滤器过滤路径 filterRegistrationBean.addUrlPatterns("/*"); //忽略过滤的形式 filterRegistrationBean.addInitParameter("exclusions", "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*"); return filterRegistrationBean; } }
启动项目,如果项目启动报如下图所示的错误。
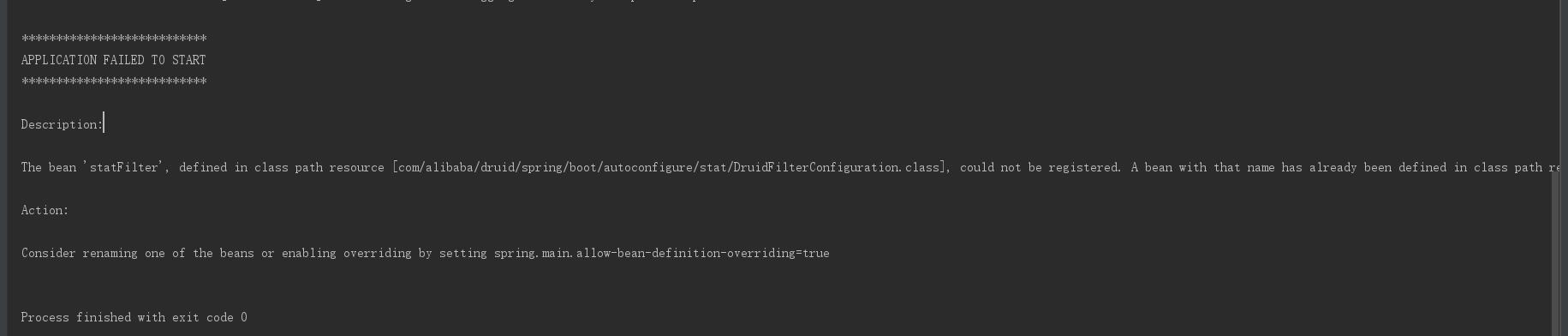
那是由于 Spring Boot 和 Druid 版本不兼容导致的,只需要在启动类中增加一行注解。
@EnableAutoConfiguration(exclude={DruidDataSourceAutoConfigure.class})
输入地址:http://127.0.0.1:8771/druid/login.html,IP地址,端口号根据项目的实际情况来
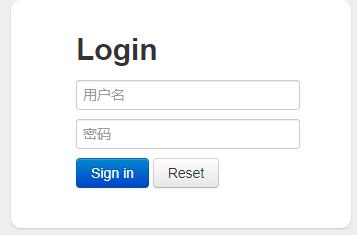
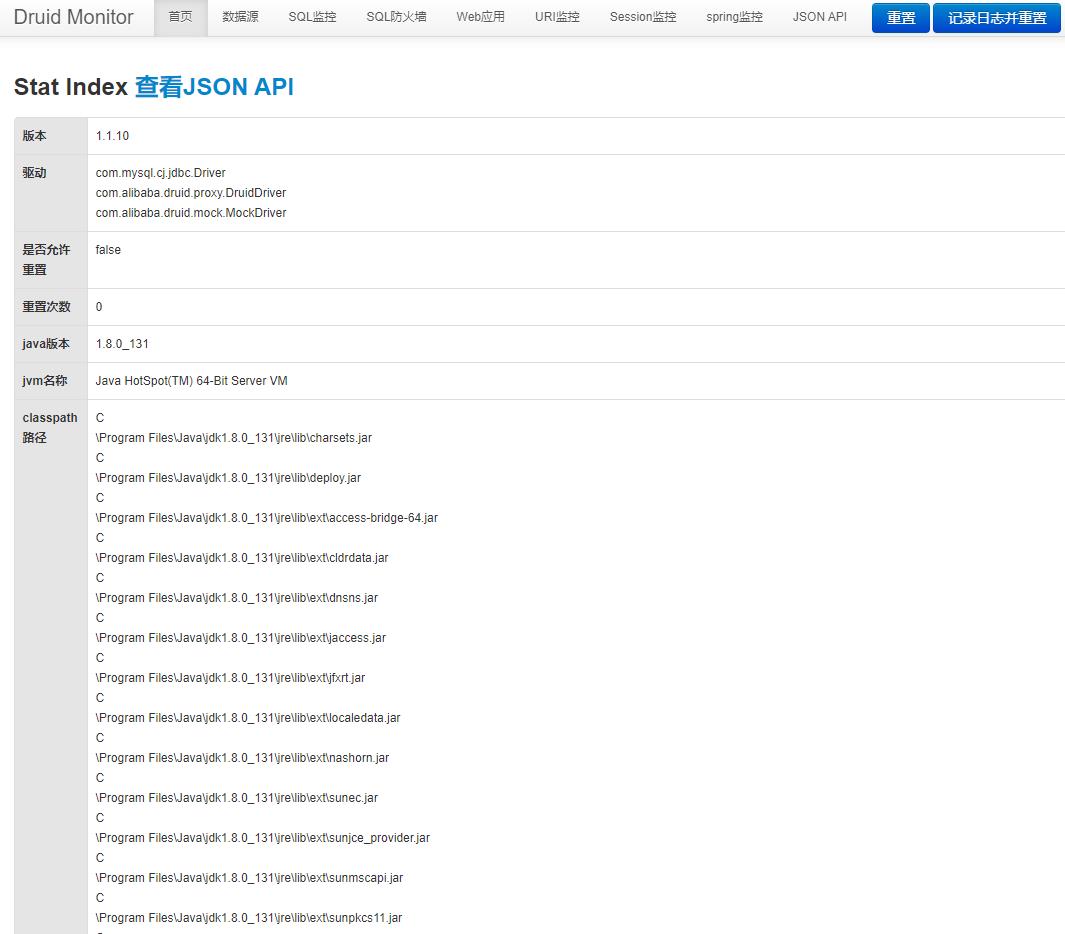
输入用户名,密码(配置文件中配置的用户名。密码)进行登录,登录后就可以看我们想看的信息。
参考文章:
https://blog.csdn.net/jay100500/article/details/81270298
https://github.com/alibaba/druid/tree/master/druid-spring-boot-starter
以上是关于Spring Boot 使用阿里巴巴 Druid 数据源的主要内容,如果未能解决你的问题,请参考以下文章