记录一次生产上的SpringCloudFeign的重试问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记录一次生产上的SpringCloudFeign的重试问题相关的知识,希望对你有一定的参考价值。
在上周在的微供有数项目中(数据产品),需要对接企业微信中第三方应用,在使用Feign的去调用微服务的用户模块用微信的code获取access_token以及用户工厂信息时出现Feign重试超时报错的情况,通过此篇文章记录问题解决的过程。
一.问题重现:
1.SpringCloud部分依赖如下
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.5.3.RELEASE</version> </parent> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>Dalston.SR1</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-eureka</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-feign</artifactId> </dependency>
2.微信相关的接口文档:
前端通过企业id,配置好回调域名之后,调用微信的Api去获取code
见文档https://work.weixin.qq.com/api/doc/90000/90135/91022
注意:
code只能用一次,见文档,因此获取到的access_token需要缓存起来,项目中是缓存到redis中的,用于后续的消息推送等等功能

3.请求流程图
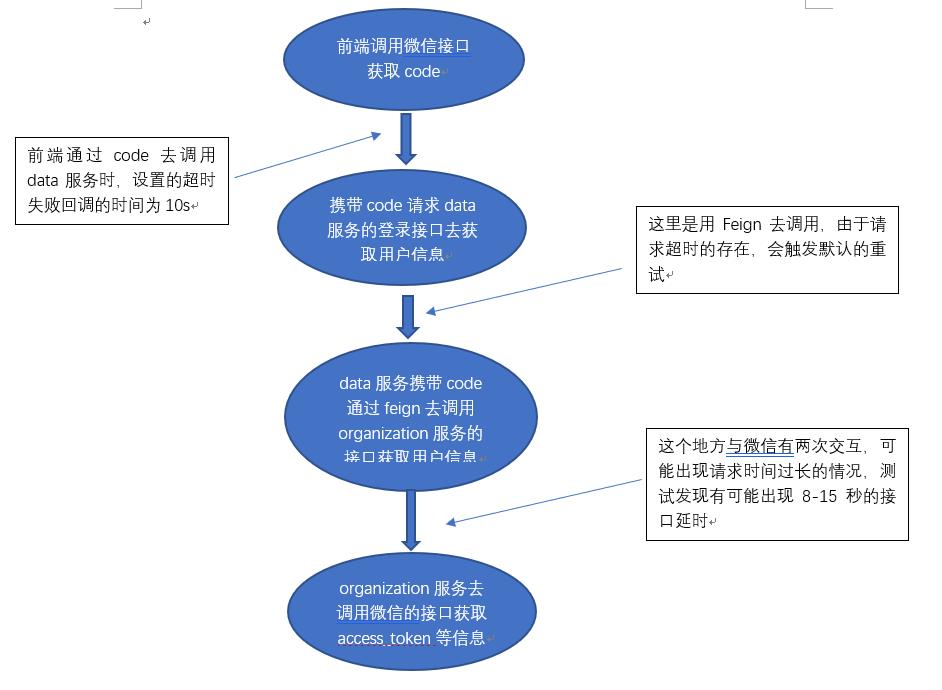
二.原因分析
1.整个请求的链路中,阶段2是feign请求的位置,但是yml配置文件中并没有配置feign,因此可以断定feign使用的默认的配置,问题发生时,查看feign的文档发现,feign重试默认超时时间是1s,
因此现在重新配置feign的超时时间,现有feign的配置如下
feign:
client:
config:
organization:
connectTimeout: 5000
readTimeout: 5000
其实organization表示的就是feign所调用的服务名称
connectTimeout表示建立请求连接的连接的时间(这里面包括获取请求eureka中保存的服务列表-推测)
readTimeout表示连接建立以后请求调用的时间
2.在上述配置中,通过查看organization和data服务的请求日志,发现请求都能顺利的建立,但是当阶段三去请求微信的接口一旦延迟,则会触发feign的重试进行第二次调用;
由于阶段三请求微信的接口并不是没有调用,而是由于网络或者其他原因导致的微信没有响应,但是code又已经被消费了,当阶段二携带同样的code去调用微信的接口,这时就会出现
code已经被消费
3.此时有另外一个问题就是,项目中的服务都是单实例部署,springcloud组件中feign和ribbon都有重试的功能,
Spring Cloud中Feign整合了Ribbon,但Feign和Ribbon都有重试的功能,Spring Cloud为了统一两者的行为,在C版本以后,将Feign的重试策略默认设置为 feign.Retryer#NEVER_RETRY(即永不重试)
因此Feign的调用本质还是通过ribbon去实现
feign:
client:
config:
eureka-client:
connectTimeout: 1000
readTimeout: 1000
配置二:
只配置ri\'bbon
注意 这里有个坑MaxAutoRetriesNextServer这个参数如果不配置为0,即使在单实例部署的情况下,仍然会发生重试1次,因此如果不想发生重试,则需要手动配置
MaxAutoRetriesNextServer=0和MaxAutoRetries=0
ribbon:
ReadTimeout: 4000
ConnectionTimeout: 4000
OkToRetryOnAllOperations: true
MaxAutoRetriesNextServer: 0 # 当前实例全部失败后可以换1个实例再重试,
MaxAutoRetries: 1 # 在当前实例只重试2次
配置三:
feign和ribbon都不配置,注意,经过测试后发现这里使用的是ribbon默认的超时配置,配置如下:
MaxAutoRetriesNextServer=1
MaxAutoRetries=0
public LoadBalancerContext(ILoadBalancer lb) { this.clientName = "default"; this.maxAutoRetriesNextServer = 1; this.maxAutoRetries = 0; this.defaultRetryHandler = new DefaultLoadBalancerRetryHandler(); this.okToRetryOnAllOperations = DefaultClientConfigImpl.DEFAULT_OK_TO_RETRY_ON_ALL_OPERATIONS; this.lb = lb; }
版本号:SpringCloud Dalston.SR1 与 Greenwich.SR1的测试结论一致
注意: Dalston.SR1 ribbon组件默认的超时时间
public static final int DEFAULT_READ_TIMEOUT = 5000;
public static final int DEFAULT_CONNECT_TIMEOUT = 2000;
Greenwich.SR1 ribbon组件默认的超时间
public static final int DEFAULT_CONNECT_TIMEOUT = 1000; public static final int DEFAULT_READ_TIMEOUT = 1000;
以上是关于记录一次生产上的SpringCloudFeign的重试问题的主要内容,如果未能解决你的问题,请参考以下文章