Java HashMap的原理扩容机制以及性能思考
Posted zhoujunjie
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java HashMap的原理扩容机制以及性能思考相关的知识,希望对你有一定的参考价值。
Java HashMap
说明
此文档所介绍的HashMap是基于JDK1.8之后的。此文受到网上很多其他Java生态爱好者文章的影响,写此文的目的是系统的概括下HashMap,并把一些优秀文章的脉络连接起来起到目录作用。在此感谢优秀文章作者的启发,由于自身实力有限,若有纰漏之处还请评论指导。
原理(参考[1][3])
HashMap类似于HashTable,本质都是存储的键值对,也就是key、value,key用作存储初始索引,通过对其进行一系列运算把value映射存储到底层数据结构中。其存储的数据结构(JDK 1.8之后)如下:
- 数据结构(引用[1])
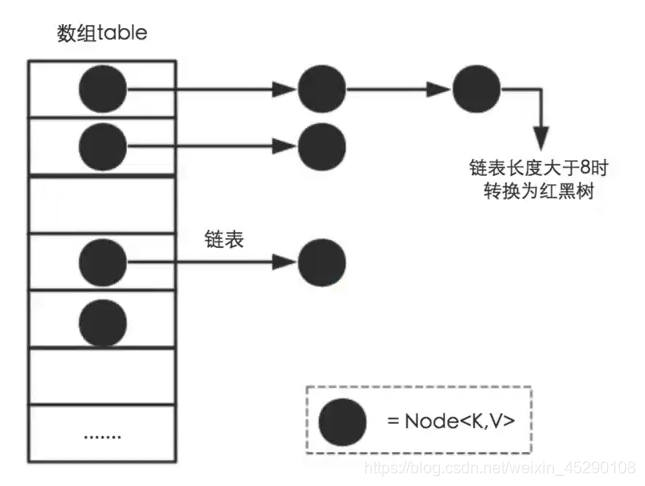
如上图所示,每个数组是有存储的是一个链表或者红黑树(视情况而定) * 数组 * 链表 * 红黑树
- 存储过程
- 对key进行hash运算,得到key的hash值。
- 把key的hash值和hashMap的(length-1)进行&运算,得到index,index即为数据的
索引下标,例如0,1,2,3。 - 根据
索引下标,把该Entry<key, value>存到对应的数据结构中。- 计算
索引下标,也就是keyHash&(length-1)时,不同的keyHash会产生同样的索引下标,也就是说一个数组元素可能会存储多个数据; - 所以每个数组元素存储的是一个链表,当链表的长度超过
TREEIFY_ THRESHOLD:8时,把链表改为红黑树。
- 计算
- HashMap的阈值(参考[1])
DEFAULT INITIAL CAPACITY: 数组的初始容量,也就是默认会数组初始长度为16,长度不能太大或者太小。如果太小,很容易触发扩容,如果太大, 遍历HashMap会比较慢。值: 1<<4; //16
MAXIMUM CAPACITY: HashMap最大容量,一.般情况下只要内存够用,HashMap不会出现问题。值: 1<<30 (整数最大值的一半)
DEFAULT LOAD FACTOR: 默认的负载因子。因此初始情况下,当键值对的数量大于16 * 0.75 = 12时,就会触发扩容。值: 0.75f。
TREEIFY_ THRESHOLD: 如果哈希函数不合理,即使扩容也无法数组元素中链表的长度,因此Java 的处理方案是当链表太长 时,转换成红黑树。这个值表示当某个数组元素中,链表长度大于8时,有可能会转化成树。值: 8
UNTREEIFY _THRESHOLD: 在HashMap扩容时,如果发现链表长度小于6,则会由树重新退化为链表。值: 6
MIN_ TREEIFY_ CAPACITY: 在转变成树之前,还会有一次判断,只有键值对数量大于64才会发生转换。这是为了避免在HashMap建立初期,多 个键值对恰好被放入了同一个链表中而导致不必要的转化。值: 64
扩容(参考[2])
* 当元素超过数组长度的75%就会发生扩容,既长度增加一倍。
* 默认的数组长度```DEFAULT _INITIAL_ CAPACITY```=16,默认的负载因子```DEFAULT LOAD FACTOR```=0.75;当键值对数量超过16 * 0.75 = 12时,就会触发扩容导致数组长度变为16 * 2 = 32。
注意:扩容后,每个键值对数据存储的索引下标需要重新计算。通过公式:keyHash&(newLength-1)。结果会变成:newIndex = oldIndex + 扩容增加的长度。
性能(参考[4])
影响性能的因素
- 存储长度(数组长度):需要为2的整数次幂,此文[5]已经详细解释,就不重复造轮子。
- 扩容频率->负载因子:选择一个合适的负载因子,如果负载因子太小会导致扩容太频繁,从而导致性能损失。
实践案例 文章[4]已经为我们很好地举了一个提高性能的实践案例。 ”比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面annegu已经说过,即使是1000,hashmap也自动会将其设置为1024。 但是new HashMap(1024)还不是更合适的,因为0.75*1000 < 1000, 也就是说为了让0.75 * size > 1000, 我们必须这样new HashMap(2048)才最合适,既考虑了&的问题,也避免了resize的问题。“
参考文章
- [1]https://blog.csdn.net/weixin_45290108/article/details/100056621
- [2]https://blog.csdn.net/wohaqiyi/article/details/81448176
- [3]https://blog.csdn.net/woshimaxiao1/article/details/83661464
- [4]https://blog.csdn.net/cnq2328/article/details/60783708
- [5]https://blog.csdn.net/wohaqiyi/article/details/81161735
以上是关于Java HashMap的原理扩容机制以及性能思考的主要内容,如果未能解决你的问题,请参考以下文章