学习使用Java的webmagic框架爬取网页内容
Posted 寂天风
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学习使用Java的webmagic框架爬取网页内容相关的知识,希望对你有一定的参考价值。
Maven官网:https://mvnrepository.com/artifact/net.sourceforge.htmlunit/htmlunit/2.37.0
(一)使用前的配置:
1,使用IDEA创建web项目:https://blog.csdn.net/MyArrow/article/details/50824793
2,(1)添加依赖:
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.7.3</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-selenium</artifactId>
<version>0.7.3</version>
</dependency>
(2)从GitHub官网下载webmagic的压缩包(https://codeload.github.com/code4craft/webmagic/zip/master),将webmagic-core使用Module from Existing Source..导入项目中
(3)在resources中添加资源文件log4j.properties中添加
# Set root logger level to DEBUG and its only appender to A1. log4j.rootLogger=INFO, A1 # A1 is set to be a ConsoleAppender. log4j.appender.A1=org.apache.log4j.ConsoleAppender # A1 uses PatternLayout. log4j.appender.A1.layout=org.apache.log4j.PatternLayout log4j.appender.A1.layout.ConversionPattern=%-d{yyyy-MM-dd HH:mm:ss,SSS} [%t] [%c]-[%p] %m%n
(二)写程序爬虫:
抽取元素:
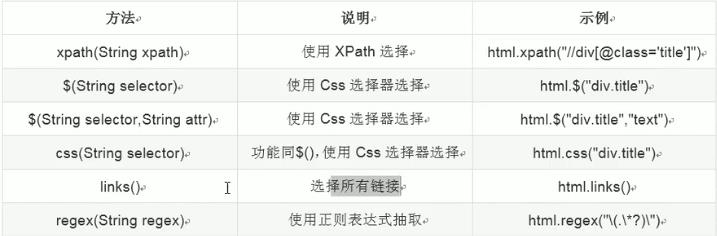
1,page使用css选择器
2,page使用XPath

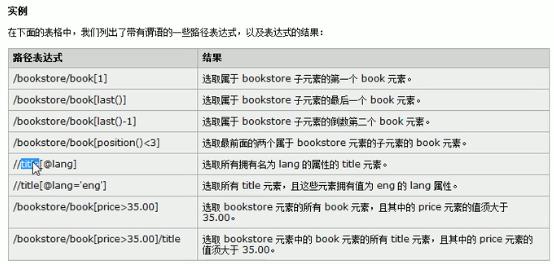
3,使用正则表达式
regex(“正则表达式”)
获取元素:

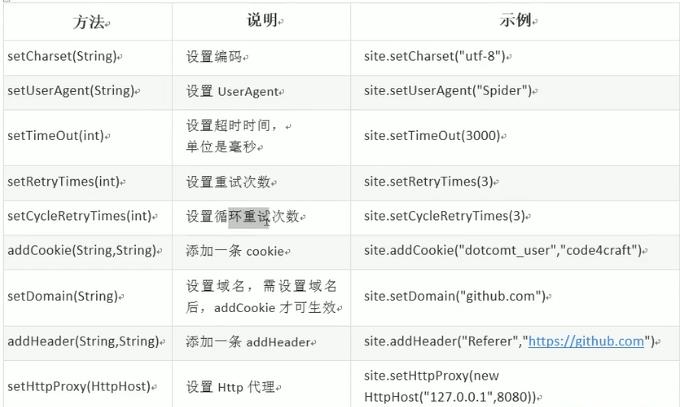
设置爬虫属性:site
Scheduler组件:
1,对抓取的url保存到队列
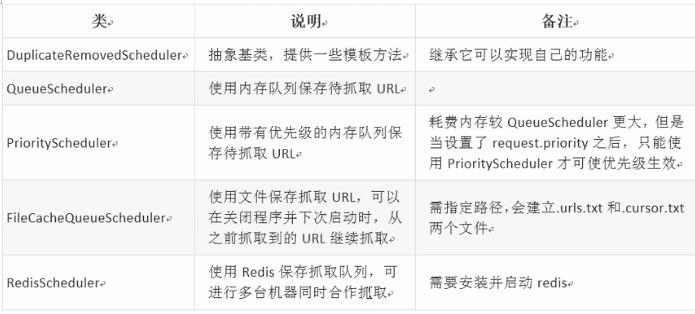
2,对抓取的url去重

(三)使用htmlunit模拟点击https://www.bilibili.com/video/av62605696;官方文档:http://htmlunit.sourceforge.net/apidocs/
htmlunit模拟js运行
1,获取文本框和按钮,设置文本框的值,然后使用按钮的click方法提交获得新的页面
例子:
package com.open1111; import java.io.IOException; import java.net.MalformedURLException; import com.gargoylesoftware.htmlunit.BrowserVersion; import com.gargoylesoftware.htmlunit.FailingHttpStatusCodeException; import com.gargoylesoftware.htmlunit.WebClient; import com.gargoylesoftware.htmlunit.html.HtmlForm; import com.gargoylesoftware.htmlunit.html.HtmlPage; import com.gargoylesoftware.htmlunit.html.HtmlSubmitInput; import com.gargoylesoftware.htmlunit.html.HtmlTextInput; public class HtmlUnitTest5 { public static void main(String[] args) { WebClient webClient=new WebClient(BrowserVersion.FIREFOX_52); // 实例化Web客户端 try { HtmlPage page=webClient.getPage("http://blog.java1234.com/index.html"); // 解析获取页面 HtmlForm form=page.getFormByName("myform"); // 得到搜索Form HtmlTextInput textField=form.getInputByName("q"); // 获取查询文本框 HtmlSubmitInput button=form.getInputByName("submitButton"); // 获取提交按钮 textField.setValueAttribute("java"); // 文本框“填入”数据 HtmlPage page2=button.click(); // 模拟点击 System.out.println(page2.asXml()); } catch (FailingHttpStatusCodeException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (MalformedURLException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); }finally{ webClient.close(); // 关闭客户端,释放内存 } } }
以上是关于学习使用Java的webmagic框架爬取网页内容的主要内容,如果未能解决你的问题,请参考以下文章