概述
java的集合主要有Collection和Map两个接口派生而出,包含了一些子接口和实现类组成了集合框架
继承树:
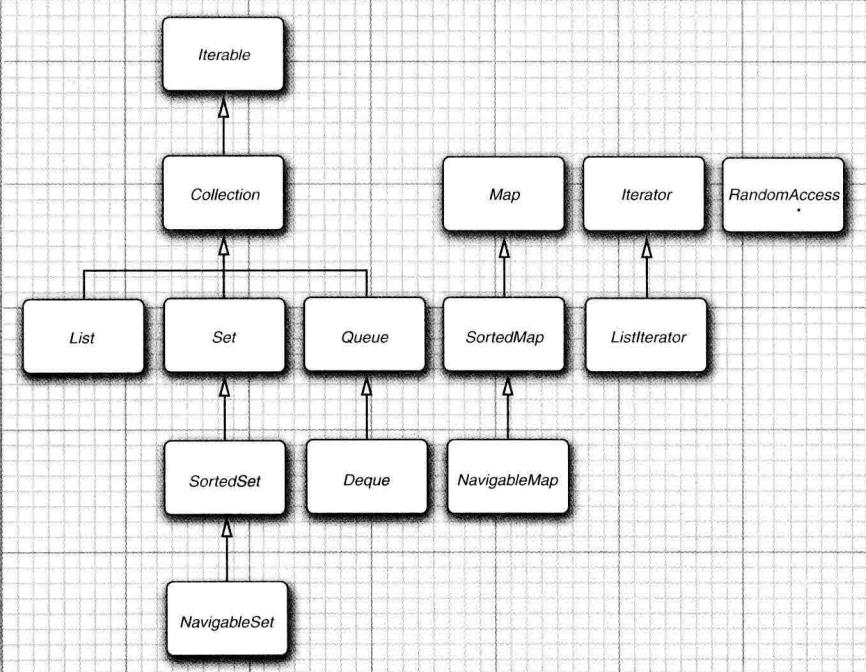
Collection接口
是List、Set、Queue的父接口,Collecation中定义的方法也可用于其子接口类型的集合;
子接口一:Set集合
无序 且 不允许包含相同的元素;像一个罐子,不同的数据被随意丢进去
HashSet类
Set的典型实现类,按Hash算法来存储集合中的元素,存取查找性能好
-
特点:
- 不能保证元素的排列顺序(受存储方式影响,可能与添加时不同,还可能变顺序)
- HashSet不是同步的,多线程使用需要解决线程安全问题
- 集合元素可以为null
- HashSet集合判断两个对象相等的标准:equals()比较、hashCode()返回值都相等
-
集合元素存储过程
- 存入元素时,HashSet会调用该对象的hashCode()方法获取该对象的hashCode值,然后根据该值确定该对象在HashSet中的存储位置,即使两个对象使用equals()比较的结果是true,但是它们的hashCode()的值不同,还是会保存在不同的位置
-
重写hashCode()方法基本规则
-
同一个对象多次调用hashCode()取得哈希值应该相同
-
两个对象调用equals()比较返回true,那么它们调用hashCode()获取的哈希值也应该相同(如果相同,集合中就会存储两个相同的元素,这与HashSet集合规则不符;从这里也可以看出,元素存储的位置是由hashCode值决定的)
-
对象中用在equals()方法比较;的变量,都应该用于计算hashCode值
-
一般步骤:
- ①把对象内参与equals()方法比较的实例变量计算出一个int类型的hashCode值
- ②利用①中计算出来的多个值计算出一个hashCode值并返回(通常会将各个值乘以任意质数再进行相加,避免与其他对象偶然相等)
-
LinkedHashSet类
- HashSet的子类,与其区别:用链表维护元素的次序,使得元素看起来是按照插入时的顺序保存的(实际是与HashSet一样通过计算哈希值保存),是因为每个元素都w维护了两个指针,指向自己前一个和后一个数据,使得不连续的元素之间能知道自己插入时的前一个数据是谁
- 这也使得LinkedHashSet集合在进行遍历操作时,效率高于HashSet
-
TreeSet类
EnumSet类
子接口二:List 集合
元素有序、可重复的集合(“动态”数组)
常用方法:
增:add(Object obj)
删:remove(int index) / remove(Object obj)
改:set(int index,Object ele)
查:get(int index)
插:add(int index,Object obj)
长度:size()
遍历:①Iterator迭代器;②foreach循环;③普通循环
- 可使用Collection中所有的方法,且由于是有序集合,List中增加了一些针对脚标操作的方法
- List集合可以通过索引找到元素位置,所以可以使用普通for循环进行遍历
- List集合判断两个对象是否相等只要equals()的结果为true即可()
- List相比Set额外提供了一个listIterator()方法,用于获取ListIterator对象(ListIterator是Iterator的子接口),在Iterator基础上新增方法:
- boolean hasPrevious():返回该迭代器关联的集合是否还有上一个元素
- Object previous():返回该迭代器的上一个元素
- void add(Object obj):在指定位置插入一个元素
ArrayList类 和 Vector类
List的典型实现类,支持List接口的所有功能;Vector与ArrayList用法几乎相同,但Vector是1.0就有了,有一些方法名过长之类的缺陷,主要使用ArrayList实现类
- 底层存储是通过封装一个Object[]数组,并使用initialCapacity参数来设置长度(默认为10),当增加元素到大限定值时,会自动扩容(会提前一定量扩容,不是等超了才扩)
- ensureCapacity(int minCapacity):增加集合指定值的长度
- trimToSize():调整ArrayList集合的Object[]数组长度为当前元素的个数(可减少集合对象对存储空间的占用)
- ArrayList是线程不安全的集合
固定长度的List
Arrays.ArrayList是一个固定长度的List集合,只能对其遍历访问,不可增加、删除元素
- 通过Arrays.asList(Object... a)方法,将一个数组或指定个数的对象转换成一个List集合
子接口三:Queue集合
队列集合,遵循”先进先出“原则,访问操作从头部开始,插入操作从尾部开始;标准实现类:PriorityQueue,子接口:Deque,代表“双端队列”(可同时在两端操作),其实现类可以当队列使用,也可当栈使用
PriorityQueue类
- PriorityQueue保存队列元素的顺序并不是加入队列的顺序,而是按队列元素的大小重新排序(因此其不能插入null值的元素)
- 排序方式与TreeSet的排序要求大致相同
Deque接口 与 ArrayDeque类
双端队列,接口中定义了操作双端队列的方法
- 其中包含了 出栈:pop()、入栈:push()方法,所以可以当成栈(“先进后出”)使用
- ArrayDeque类底层基于Object[]实现双端队列,默认长度16(与ArrayList底层机制基本相似)
LinkedList类
同时实现了List接口和Deque接口,因此可以通过索引随机访问集合中的元素以及当成“栈”、双端队列使用
- LinkedList的底层是用链表的形式实现的
分析
所有底层以数组实现的集合在随机访问是性能较好
而底层以链表实现的集合在执行插入、删除操作时性能较好
List集合使用建议:
- 需要遍历List集合,对于ArrayList、Vector集合,应该使用随机访问方法(get)来遍历集合,效率更高;对于LinkedList集合,则应该使用迭代器(Iterator)来遍历集合
- 如果需要经常执行插入、删除操作改变包含大量元素的List集合,可使用LinkedList集合
Lambda表达式详解:https://www.cnblogs.com/csyh/p/12445774.html
Iterator迭代器介绍:https:////www.cnblogs.com/csyh/p/12316962.html
-
遍历集合的几种方式
-
使用Lambda表达式遍历
-
/*一、使用java8新增的forEach(Consumer action)默认方法*/
public void collectionEach(){
HashSet hs = new HashSet();
hs.add("集合不能存储基本类型");
hs.add("但java会自动装箱");
hs.add(666);
//使用forEach()方法遍历集合
hs.forEach(obj -> System.out.println("迭代元素:"+obj);)
}
/*二、使用Iterator(迭代器)遍历集合元素*/
public void IteratorTest(){
//创建集合并添加集合元素(同上)
...;
//获取hs集合的迭代器
Iteractor it = ha.iterator();
//调用迭代器对象的hasNext()方法,用于判断当前指针位置的下一个集合元素是否存在
while(it.hasNext()){
//next()方法:将指针下移一位,并获取元素值
Object obj = it.next();
//从集合中删除上一次next()方法返回的元素
if(hs.equals(666)){
it.remove();
//且只能删除上一次的,不能对本次next()获取的元素操作,如:
//it.remove(obj);//报异常ConcurrentModificationException
}
//Iterator仅用于遍历集合,
//迭代器遍历是将集合元素值传递给迭代器变量,所以对迭代器变量进行操作并不会影响到集合本身
obj = "测试给迭代器变量赋值";
}
}
/*三、使用Lambda表达式遍历Iterator迭代器
java8中Iterator新增了forEachRemaining(Consumer action)方法*/
public void iteratorEach(){
//创建集合并添加元素(与第一个程序相同)
...;
//获取hs集合对应的迭代器
Iterator it = hs.iterator();
//使用Lambda表达式(目标类型是函数式接口comsumer)来遍历集合元素
it.forEachRemaining(obj -> System.out.println("迭代器集合:"+ obj));
}
/*使用foreach循环遍历集合*/
public void foreachTest(){
//创建集合并添加元素(与第一个程序相同)
...;
//使用foreach循环遍历集合hs
for(Object obj : hs){
System.out.println(obj);
//同样的,在遍历集合时不能去修改集合元素否则异常同上
}
}
-
使用Predicate过滤集合
/*使用Predicate进行多个条件的过滤操作*/
public void PredicateTest(){
//创建集合
HashSet hs = new HashSet();
hs.add("相比于传统方法一个过aa滤条件就要一个遍历");
hs.add("Predicate只需定义b一个方法");
hs.add("简化了aa集合的运算,以及代码量");
hs.add("下面我们对符合各个的数组元素数量进行累加操作");
hs.add("aab");
//统计包含a的集合元素个数
System.out.println(calAll(hs,obj -> ((String)obj).contains("a")));
//统计包含b的集合元素个数
System.out.println(calAll(hs,obj -> ((String)obj).contains("b")));
//统计字符串长度大于20的元素个数
System.out.println(calAll(hs,obj ->((String)obj).length > 20));
//输出结果为4 2 2
}
//定义方法:calAll(),此方法将用Predicate判断每个集合元素是否符合条件
//该条件将作为Predicate类型的参数,以Lambda表示的形式传入方法
public static int calAll(Collection hs,Predicate p){//集合,Predicate类型的参数
int total = 0;
for(Object obj : hs){
//使用Predicate的test方法判断该对象是否满足Predicate指定的条件
if(p.test(obj)){
//记录符合条件的次数
total++;
}
}
return total;
}
/*补充:
java8新增:removeIf(Predicate filter)方法,可批量删除满足filter条件的所有元素*/
-
使用Stream操作集合
- java8新增:Stream(通用流接口)、IntStream、LongStream、DoubleStream,代表对应元素类型的流,且各自有Builder子接口,用于创建流
- 流式API操作集合
- Collection接口提供了一个stream()默认方法,用于返回该集合对应的流,而后就可以通过流式API来操作集合元素
Map接口
用于保存具有映射关系的数据,key-value(键值对),其中key、value可以是任意引用类型的数据,key不允许重复,它们之间是单向的一对一关系,通过key可以找到唯一、确定的value
Set与Map的框架体系很相似,且java在实现Set时,是先实现了Map,而后通过包装一个所有value都为空对象的Map,作为Set集合(没有value的Map就和Set相同)