深入分析JavaWeb的中文编码问题
Posted Qiao_Zhi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深入分析JavaWeb的中文编码问题相关的知识,希望对你有一定的参考价值。
1.几种常见的编码格式
1.为什么需要编码?
(1)在计算机存储信息的最小单位是1个字节(byte),即8个bit,所以能表示的字符范围是0-255个。
(2)人类要表示的符号太多,无法用1个字节来完全表示。
要解决这个矛盾必须要有一个新的数据结构char,而从char到byte必须编码。
2.如何编码
在计算机中提供了多种编码方式,常见的有ASCII、ISO-8859-1、GB2312、GBK、UTF-8、UTF-16等。其中GB2312、GBK、UTF-8、UTF-16都可以表示汉子,下面介绍几种编码方式。
1.ACSII码
ACSII码总共128个,用1个字节的低7位表示,0-31控制字符如回车、换行等,32-126是打印字符串,可以通过键盘输入(键盘上能够找到的)并且能够显示处理。
2.ISO-8859-1
128个字符显然是不够用的,于是ISO在ASCII的基础上扩展出ISO-8859-1到ISO8859-15,其中ISO-8859-1涵盖了大多数西欧语言字符,所以应用最广泛。8829-1仍然是单字节编码,总共能表示256个字符。
3.GB2312
该编码集的全称是《信息技术中文编码字符集》,它是双字节编码,总的编码范围是A1-F7,其中A1-A9是符号区,总共包含682个符号,B0-B7是汉子区,包含6763个汉字。
4.GBK
全称《汉字内码扩展规范》,是为了扩展GB2312,并加入更多的汉字。编码范围是8140-FEFE(去掉XX7F),总共23940个码位,它能表示21003个汉字,它的编码和GB2312兼容,也就是说用GB2312编码的汉字可以用GBK来解码,并且不会乱码。
5.UTF-16
Unicode(Universal Code 统一码)是ISO试图创建的超语言字典,世界上所有的语言都可以用这个字典来翻译。Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。其实现方式主流的有UTF-8和UTF-16。
UTF-16具体定义了Unicode字符在计算机中的存取方法。UTF-16用两个字节来表示Unicode的转化格式,它采用定长的表示方法,即不论什么字符都可以使用两个字节来表示。两个字节是16bit,所以叫做UTF-16。UTF-16表示字符串非常方便,每两个字节表示一个字符,这就大大简化了字符串操作,这也是Java以UTF-16作为内存的字符存储格式的一个重要原因。
6.UTF-8
UTF-16使用两个字节来表示一个字符,有时候一个字节就够用,所以会造成存储空间的浪费,而且会增大网络传输的流量。
UTF-8采用了一种变长技术,每个编码区域有不同的字码长度。不同类型的字符可以由1-6个字节组成。UTF-8有如下规则:
(1)如果是1个字节,最高位(第8位)为0,则表示这是1个ASCII字符(00-7F)可见,所有ASCII编码已经是UTF-8编码了。
(2)如果是1个字节,以11开头,则连续的1的个数暗示这个字符的字节数。例如:110xxxxx代表它是双字节UTF-8的首字节。
(3)如果是1个字节,以10开始,代表它不是首字节,则需要向前查找才能得到当前字符的首字节。
例如:
1字节 0xxxxxxx
2字节 110xxxxx 10xxxxxx
3字节 1110xxxx 10xxxxxx 10xxxxxx
4字节 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
5字节 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
6字节 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
补充:参考网上的一个U8和unicode转换的例子
UTF-8中可以用来表示字符编码的实际位数最多有31位,即上表中x所表示的位。除去那些控制位(每字节开头的10等),这些x表示的位与UNICODE编码是一一对应的,位高低顺序也相同。 实际将UNICODE转换为UTF-8编码时应先去除高位0,然后根据所剩编码的位数决定所需最小的UTF-8编码位数。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式 (十六进制) | (二进制) --------------------+--------------------------------------------- 0000 0000-0000 007F | 0xxxxxxx 0000 0080-0000 07FF | 110xxxxx 10xxxxxx 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
以汉字严为例演示如何实现utf-8编码。"严"的unicode编码为4e25,二进制0100111000100101,根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF),,因此"严"的UTF-8编码需要三个字节,即格式是"1110xxxx 10xxxxxx 10xxxxxx"。然后,从"严"的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,"严"的UTF-8编码是"11100100 10111000 10100101",转换成十六进制就是E4B8A5。
验证如下:
import java.math.BigInteger; public class Client { public static void main(String[] args) throws Exception { // Integer.toHexString(\'严\') 获取unicode码 // 十六进制unicode System.out.println(Integer.toHexString(\'严\')); // 二进制的unicode System.out.println(hexString2binaryString(Integer.toHexString(\'严\'))); // 二进制的UTF-8 System.out.println(binary("严".getBytes("utf-8"), 2)); // 十六进制的UTF-8 System.out.println(binary("严".getBytes("utf-8"), 16)); } /** * 将byte[]转为各种进制的字符串 * * @param bytes * byte[] * @param radix * 基数可以转换进制的范围,从Character.MIN_RADIX到Character.MAX_RADIX, * 超出范围后变为10进制 * @return 转换后的字符串 */ public static String binary(byte[] bytes, int radix) { return new BigInteger(1, bytes).toString(radix);// 这里的1代表正数 } /** * 16进制转二进制 * * @param hexString * @return */ public static String hexString2binaryString(String hexString) { if (hexString == null || hexString.length() % 2 != 0) return null; String bString = "", tmp; for (int i = 0; i < hexString.length(); i++) { tmp = "0000" + Integer.toBinaryString(Integer.parseInt(hexString.substring(i, i + 1), 16)); bString += tmp.substring(tmp.length() - 4); } return bString; } // 2进制转16进制 public static String binaryString2hexString(String bString) { if (bString == null || bString.equals("") || bString.length() % 8 != 0) return null; StringBuffer tmp = new StringBuffer(); int iTmp = 0; for (int i = 0; i < bString.length(); i += 4) { iTmp = 0; for (int j = 0; j < 4; j++) { iTmp += Integer.parseInt(bString.substring(i + j, i + j + 1)) << (4 - j - 1); } tmp.append(Integer.toHexString(iTmp)); } return tmp.toString(); } }
结果:
4e25
0100111000100101
111001001011100010100101
e4b8a5
关于更多的参考:http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
补充:Little endian 和 Big endian编码方式
以汉字严为例,Unicode 码是4E25,需要用两个字节存储,一个字节是4E,另一个字节是25。存储的时候,4E在前,25在后,这就是 Big endian 方式;25在前,4E在后,这是 Little endian 方式。
第一个字节在前,就是"大头方式"(Big endian),第二个字节在前就是"小头方式"(Little endian)。
那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码?
Unicode 规范定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(zero width no-break space),用FEFF表示。这正好是两个字节,而且FF比FE大1。
如果一个文本文件的头两个字节是FE FF,就表示该文件采用大头方式;如果头两个字节是FF FE,就表示该文件采用小头方式。
例如,另一种方式获取unicode码:
System.out.println(binary("严".getBytes("unicode"), 16));
结果:(表示大头存储方式)
feff4e25
2.在Java中需要编码的场景
1.I/O操作中存在的编码
涉及编码的地方一般是从字符到字节或者是从字节到字符的转换上,需要转换的场景主要是IO,包括磁盘IO和网络IO,这里先介绍磁盘IO。
java中处理IO问题的接口如下:
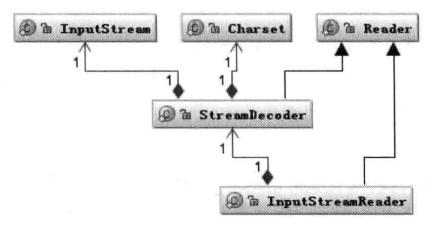
Reader类是在Java的IO读字符的父类,而InputStream是读字节的父类,InputStreamReader类就是关联字节到字符的桥梁,它负责在IO过程中读取字节到字符的转换,而对字节到字符的解码实现,它又委托StreamDecoder实现,在StreamDecoder解码过程中必须由用户指定Charset编码格式。值得注意的是,如果没有指定Charset,则将使用本地环境中的默认字符集,如在中文环境使用GBK。
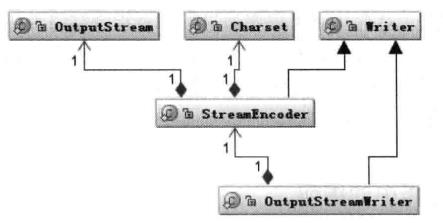
写的情况也类似,字符的父类是Writer,字节的父类是OutputStream,通过OutputStreamWriter转换字符到字节。同样,StreamEncoder负责将字符编码成字节,编码格式和默认编码规则与解码是一致的。如下:
如下代码实现文件的读写:
import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.IOException; import java.io.InputStreamReader; import java.io.OutputStreamWriter; public class PlainTest { public static void main(String[] a) throws IOException { // 写 String file = "G:/test.txt"; String charSet = "UTF-8"; OutputStreamWriter outputStreamWriter = new OutputStreamWriter(new FileOutputStream(file), charSet); try { outputStreamWriter.write("测试字符串"); } finally { outputStreamWriter.close(); } // 读 InputStreamReader inputStreamReader = new InputStreamReader(new FileInputStream(file), charSet); StringBuffer stringBuffer = new StringBuffer(); char[] buffer = new char[20]; int count = 0; try { while ((count = inputStreamReader.read(buffer)) != -1) { stringBuffer.append(buffer, 0, count); } } finally { inputStreamReader.close(); } System.out.println(stringBuffer.toString()); } }
在我们的应用涉及IO操作时,只要注意指定统一的编码解码Charset字符集,一般不会出现乱码问题。对有些应用程序不指定字符编码,则在中文环境中会使用操作系统默认编码。不建议使用操作系统默认的编码,因为这样会使应用程序和运行环境绑定起来,在跨环境时很可能出现乱码问题。
2. 内存中的编码
在内存中进行从字符到字节的数据类型转换也涉及编码,在Java中用String表示字符串,所以String类就提供了转换到字节的方法,也支持将字节转换为字符串的构造函数。
String string = "测试字符串"; byte[] bytes = string.getBytes("UTF-8"); String string2 = new String(bytes, "UTF-8");
3.在Java中如何编解码
以" I am 君山" 为例子介绍在java中如何以ISO-8859-1、GB2312、GBK、UTF-8、UTF-16进行编解码。
java中编码用到的类图如下:
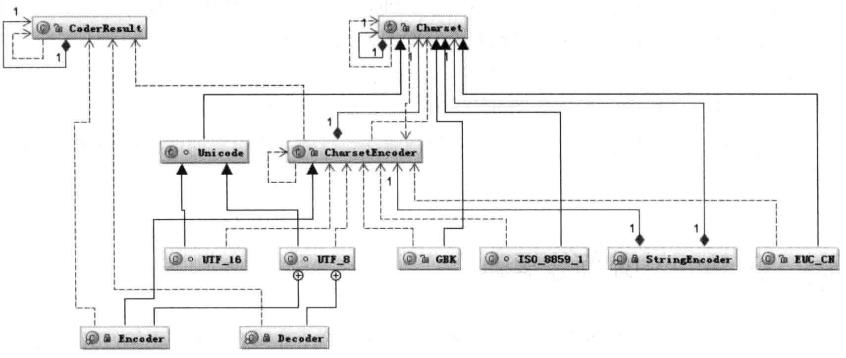
首先根据指定的charsetName通过Charset.forName(charsetName)找到Charset类,然后根据Charset创建CharsetEncoder,再调用charsetEncoder.encode()方法对字符串进行编码,不同的编码类型都会对应到一个类中,实际的编码过程是在这些类中完成的。
string.getBytes(charsetName)编码过程的时序图如下:

1.按照ISO-8859-1编码
String str = "I am 君山"; String charset = "ISO-8859-1"; byte[] bytes = str.getBytes(charset); System.out.println(binary(bytes, 16)); System.out.println(new String(bytes, charset));
结果:
4920616d203f3f
I am ??
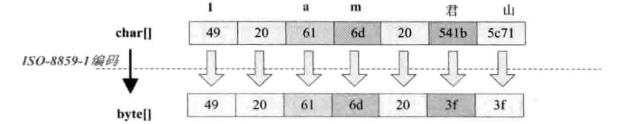
可以看出,7个char字符应该ISO-8859-1变为7个byte数组,ISO-8859-1是单字节编码,中文"君山"被转换成是 3f 的byte,也就是"?",所以经常出现中文变成?。中文字符经过该编码会丢失信息,通常称之为"黑洞",它会把不认识的字符吸收掉。
2.GB2312编码
String str = "I am 君山"; String charset = "GB2312"; byte[] bytes = str.getBytes(charset); System.out.println(binary(bytes, 16)); System.out.println(new String(bytes, charset));
结果:
4920616d20befdc9bd
I am 君山

可以看出,前五个字符经过编码后仍然是五个字节,汉字被编码成双字节,GB2312只支持6763个汉字,所以并不是所有汉字都能够用GB2312编码。
3.GBK编码
结果:
4920616d20befdc9bd
I am 君山
编码的结果与GB2312一样。GBK兼容GB2312,它们的编码算法一样,不同的是码表长度不同,GBK支持的汉字更多。所以只要是GB2312编码的汉字都可以用GBK进行解码,反之则不然。
4.UTF-8编码
结果:
4920616d20e5909be5b1b1
I am 君山

UTF-8对单字节范围内的字符仍然采用单字节,汉字采用3个字节。这也是U8采用0-6字节变长编码的优点。
5.UTF-16
结果如下:(feff表示大头存储)
feff004900200061006d0020541b5c71
I am 君山

UTF-16编码将char数组放大了一倍,单字节范围内的字符在高位补0变长两个字节,中文字符也变为两个字节。特点是编码效率高,规则很简单,缺点就是对单字节扩大为双字节浪费存储。
补充:几种编码格式的比较
GB2312与GBK编码规则类似,但是GBK范围更大,它能处理所有汉字字符。GB2312编码的GBK都可以解码,反之不然。
UTF-16与UTF-8都是处理Unicode编码,它们的编码规则不太相同。相对来说,UTF-16的编码效率更高,从字符到字节的相互转换更简单,进行字符串操作也更好。它适合在本地磁盘和内存之间使用,可以进行字符和字节之间的快速转换,如Java的内存管理就使用UTF-16编码。但是它不适合在网络之间传输,因为网络传输容易损坏字节流,一旦字节流损坏将很难修复,所以相比较而言UTF-8更适合网络传输。UTF-8对ASCII码采用单字节存储,另外单个字符损坏也不会影响后面的字符,在编码效率上介于GBK和UTF-16之间,所以U8在编码效率和编码安全性上做了平衡,是理想的编码方式。
4.JavaWeb设计编码的地方
从使用中文的角度来说, 有IO的地方就会设计编码,大部分的IO是网络IO,数据经过网络传输时是以字节为单位,所以所有的数据都被序列化为字节。在Java中,要被序列化必须实现Serializable接口。
这里考虑两个问题:
1.一段文本的实际大小如何计算?
一个简单的例子就是如何压缩Cookie的大小,减少网络传输量。所谓的压缩只是将多个单字节字符变成一个多字节字符,较少的是String.length(),而并没有减少最终的字节数。例如将 ab 两个字符通过某种编码变成一个奇怪的字符,虽然字符数从两个变成一个,但是如果采用UTF-8编码,这个奇怪的字符最后经过编码可能会变成3个或者更多的字节。同样的,如果整型数字 1234567 作为字符串处理,则采用UTF-8编码占用7个字节;采用UTF-16将占用14个字节,但是作为int类型的数字来存储时则只需要4个字节。所以看一段文本的大小,只看字符本身的长度是没有意义的,即使一样的字符,采用不同的编码最终的存储结果也不同,所以从字符到字节一定要看编码类型。
2.当我们在文本编辑器中输入汉字时它到底是怎么表示的?
我们知道,在计算机里所有的信息都是0和1表示的,那么一个汉字到底是多少个0和1呢。例如在"淘宝"的unicode编码是 "feff6dd85b9d", feff表示大头存储方式,所以16进制是 "6dd85b9d"。在java中,每个char占2byte,所以两个汉字在java中用char表示,会占用4个字节。
把这两个问题搞清楚以后,看一下在javaweb中哪些地方可能会存在编码转换。
用户从发起一个HTTP请求,需要存在编码的地方是URL、Cookie、Parameter。服务端收到请求后要解析HTTP,其中URI、Cookie、Post参数需要解码,服务端还可以读取数据库中的数据----本地或者网络中其他地方的文本文件,这些数据都存在编码问题。当Servlet处理完所有的请求后,需要再将这些数据编码,通过Socket发送到用户请求的浏览器里,再通过浏览器解码成为文本。过程如下:
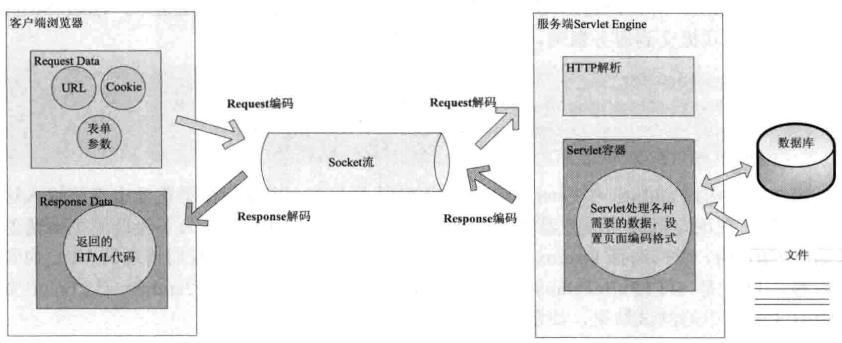
2.1URL的编码解码
用户提交一个URL,可能存在中文,因此需要编码。URL的组成部分如下:
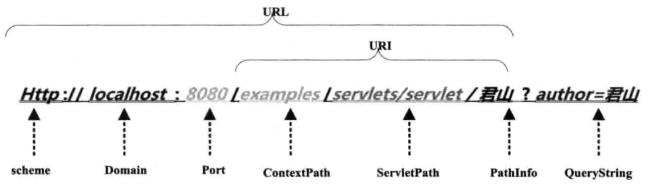
以tomcat作为Servlet Engine为例,把它们分别对应到下面这些配置文件中。
Port对应在<Connector port="8080">中配置,ContextPath在<Context docBase="MyWeb" path="/examples"/>配置,ServletPath在Web应用的web.xml的<url-pattern>配置,PathInfo是我们请求的具体的Servlet,QueryString是要传递的参数。注意这里是在浏览器直接输入URL,所以是Get方式提交,如果是POST方法请求,QueryString将通过表单方式提交到服务器端。
我们验证浏览器有中文的时候如何编码和解码,如下地址:
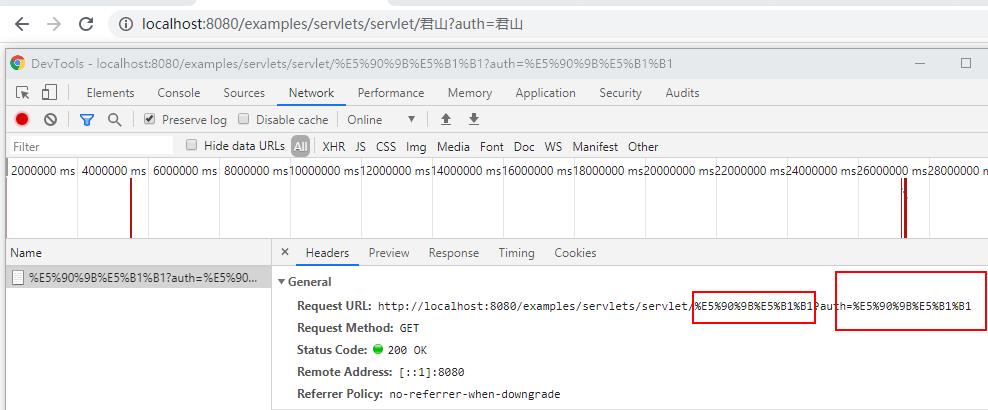
可以看到"君"的编码后为"%e5%90%9b","山"为"%e5%b1%b1"。可以看到PathInfo的编码和QueryString的编码都是UTF-8。至于为什么会有%,URL的编码规范RFC3986可知,浏览器编码URL是将非ASCII码按照某种格式编码成16进制数字后将每个16进制表示的字节前加"%"。
1.解释tomcat如何解码URI和QueryString
对URL的URI部分、QueryString 进行解码的字符集是在connector的<Connector URIEncoding="UTF-8"/>中定义的,如果没有定义,将以默认的编码集,所以有中文URI时最好指定为UTF-8编码。
这里解释一下解决get乱码以及解决办法:
(1)如果connector的URIEncoding是UTF-8编码,对URI和QueryString会采用UTF-8进行一次解码,如果前端的URI和QueryString是U8编码,会解码正确;
(2)一般URI没人写中文,所以一般乱码是QueryString乱码;如果server.xml不是U8编码会默认以ISO-8859-1解码,而前台编码用的是U8,所以会导致解码失败。解决办法就是前台用JS进行encodeURI(encodeURI(param))进行编码。关于两次encodeURI的原因如下:
前台一次encodeURI有可能导致后台解码乱码,比如前台用U8进行encodeURI,后台server.xml用ISO-8859-1解码就会乱码。
前台两次编码,后台代码中主动进行一次解码不会出错。例如:
汉字"中",一次encodeURI之后变为 "%e4%b8%ad", 两次encodeURI之后变为"%25e4%25b8%25ad" ,加%25是因为"%"编码后变为"%25"。后台接受到之后用server.xml指定的编码集解码为: "%e4%b8%ad",然后代码中主动解码一次即可:
URLDecoder.decode("%E4%B8%AD", "utf-8")
2. HTTPHeader的编解码
当客户端发起一个HTTP请求时,除上面的URL外,还可能在Header中传递其他参数,比如cookie、redirectPath。对header的解码是在调用request.hetHeader时进行的,只能使用ISO-8859-1,不能指定其他编码,所以如果Header中有非ASCII码字符,解码肯定会乱码。
所以Header中传递中文只能编码再添加到Header中。
3.POST表单的编解码
POST表单提交的参数的解码是在第一次调用request.getParameter时发生的,POST表单的参数传递 方式与QueryString不同,它是通过HTTP的BODY传递到服务端的。当我们提交时,浏览器首先将根据ContentType的Charset编码格式对在表单中填入的参数进行编码,然后提交到服务端,在服务端同样也是用ContentType的Charset编码格式进行解码。所以通过POST提交一般不会乱码,可以通过request.setCharacterEncoding进行设置。
需要注意:一定要在第一次调用request.getParameter方法之前就设置request.setCharacterEncoding(charset),否则提交上来的数据也可能出现乱码。
另外,针对multipart/form-data类型的参数,也就是上传文件的编码,同样也使用ContentType定义的字符集编码。需要注意的是,上传文件是用字节流的方式传输到服务器的本地临时目录,这个过程并没有涉及字符编码,而真正编码是在将文件内容添加到parameters中时,如果用这个不能编码,会使用ISO-8859-1。
4.HTTP Body的编解码
当用户请求的资源成功后,这些内容将通过Response返回客户端浏览器。z合格过程要先经过编码,再到浏览器进行解码。编码字符集可以通过response.setCharacterEncoding来设置,它将会覆盖request.getCharacterEncoding的值,并且通过Header的Content-Type返回客户端,浏览器收到返回的Socket流时将通过Content-Type的charset进行解码。如果返回的Content-Type没有设置charset,那么浏览器将根据<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />中的charset进行解码,如果也没指定会使用浏览器默认的编码来解码。
5.JS需要编码的地方
JS操作页面元素的情况越来越多,尤其是JS发起异步请求的情况遇到的编码问题更会经常出现。
1.外部引入JS文件
在一个单独的JS文件中包含字符串输入的情况,如:
<!DOCTYPE html> <html> <head> <title></title> <script src="js/test.js"></script> </head> <body> </body> </html>
test.js代码如下:
document.write("测试汉字");
效果如下:
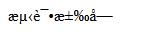
这时如果script标签没有设置charset,浏览器会以当前页面默认的编码解析这个JS,由于上面JS没有指定页面的编码,也没有指定script的编码集,所以编码错误,可以指定页面编码,也可以指定script编码,如下:
<script src="js/test.js" charset="UTF-8"></script>
或者指定页面编码集:
<meta charset="utf-8" />
2.JS的URL编码
JS处理编码有三个函数,escape、encodeURI和encodeURIComponent。
关于这三个函数的区别以及用法参考之前的文章:https://www.cnblogs.com/qlqwjy/p/9934706.html
3.其他需要编码的地方
除了URL和 参数编码问题,在服务端还有很多地方需要编码,如:XML、Velocity、JSP或者从数据库读取数据等。

以上是关于深入分析JavaWeb的中文编码问题的主要内容,如果未能解决你的问题,请参考以下文章