Mybatis源码阅读之--整体执行流程
Posted autumnlight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Mybatis源码阅读之--整体执行流程相关的知识,希望对你有一定的参考价值。
Mybatis执行流程分析
Mybatis执行SQL语句可以使用两种方式:
- 使用SqlSession执行update/delete/insert/select操作
- 使用SqlSession获得对应的Mapper,然后调用mapper的相应方法执行语句
其中第二种方式获取Mapper的流程在前面已经解析过,请查看文章Mybatis源码阅读之--Mapper执行流程
其实这个方法最后的MapperMthod也是调用SqlSession的相应方法执行增删该的操作,这边文章主要介绍SqlSession执行Sql的流程。
此处以最为复杂的select举例说明--SqlSession的默认实现类为DefaultSqlSession:
- selectOne 处理返回单条数据的逻辑
// DefaultSqlSession类中
public <T> T selectOne(String statement, Object parameter) {
List<T> list = this.selectList(statement, parameter);
if (list.size() == 1) {
return list.get(0);
} else if (list.size() > 1) {
throw new TooManyResultsException("Expected one result (or null) to be returned by selectOne(), but found: " + list.size());
} else {
return null;
}
}
调用selectList()返回一个List,如果返回的数据大于一条,那么抛出ToooManyResultsException,否则,如果List的大小为1,返回第一个数据,否则返回null
2. selectList 处理返回多条数据的逻辑
// DefaultSqlSession类中
public <E> List<E> selectList(String statement, Object parameter, RowBounds rowBounds) {
try {
MappedStatement ms = configuration.getMappedStatement(statement);
return executor.query(ms, wrapCollection(parameter), rowBounds, Executor.NO_RESULT_HANDLER);
} catch (Exception e) {
throw ExceptionFactory.wrapException("Error querying database. Cause: " + e, e);
} finally {
ErrorContext.instance().reset();
}
}
我们看到,先获得String类型指定的statemnet获得MappedStatement ms,然后调用executer.query方法处理sql语句
Executor有多个实现,SimpleExecutor、BatchExecutor、CachingExecutor,其中BatchExecutor是执行批处理操作的,而CachingExecetor对Executor进行了一层包装完成二级缓存的功能(详见文章Mybatis源码阅读之--二级缓存实现原理分析)。
这里我们主要分析SimpleExecutor
public class SimpleExecutor extends BaseExecutor {
}
SimpleExecutor继承自BaseExecutor,后者实现了query方法
// SimpleExecutor
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameter);
// 获得缓存键
CacheKey key = createCacheKey(ms, parameter, rowBounds, boundSql);
return query(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
创建CacheKey,然后根据CacheKey执行查询操作
// BaseExecutor类
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
// 由于嵌套查询,这里会查询多次
// 第一个查询,并且当前的语句需要刷新缓存,则进行缓存的刷新
if (queryStack == 0 && ms.isFlushCacheRequired()) {
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null;
if (list != null) { // 缓存中拿到了,处理输出参数
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else { // 缓存中没有拿到,则从数据库中拿
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql);
}
} finally {
queryStack--;
}
if (queryStack == 0) { // 最外层的查询已经结束
// 所有非延迟的嵌套查询也已经查完了,那么就可以把嵌套查询的结果放入到需要的对象中
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
其中有一些一级缓存的处理,这里不再详细分析,欲了解详情,请参考文章Mybatis源码阅读之--本地(一级)缓存实现原理分析
这里就从queryFromDatabase方法进行分析,一级缓存没有拿到数据会执行从数据库中获取数据的操作。
// BaseExecutor类
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
// 这里为什么要先占位呢?
// 回答:嵌套的延迟加载有可能用的是同一个对象,这里说明已经开始查了,
// 但是由于处理嵌套的查询,此查询还没有查完,再次执行嵌套查询,且查询的是相同的东西,那么就不用再查了
localCache.putObject(key, EXECUTION_PLACEHOLDER);
try {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
} finally {
// 删除占位
localCache.removeObject(key);
}
// 将数据放入到缓存中
localCache.putObject(key, list);
// 对于callable的statement来说,出参也需要缓存,而出参也是放在了入参中
// 因此这里缓存了入参
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
此方法去除一级缓存的处理之后就一句话
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql);
可以发现BaseExecutor并没有实现doQuery方法,而是将doQuery交给具体的子类进行实现(SimpleExecutor和BatchExecutor对于doQuery的方法实现有所不同),
这里使用了模板方法模式,BaseExecutor只对一级缓存进行处理,具体从数据库中查询数据的操作交给子类去处理。
目光再次回到SimpleExecutor的doQuery方法
// SimpleExecutor
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
此方法的主要过程如下:
- 创建一个StatementHandler
- 创建Statement对象
- 调用StatementHandler的query方法完成查询的操作
先看第一步,如何创建一个StatementHander
// Configuration类
public StatementHandler newStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
StatementHandler statementHandler = new RoutingStatementHandler(executor, mappedStatement, parameterObject, rowBounds, resultHandler, boundSql);
statementHandler = (StatementHandler) interceptorChain.pluginAll(statementHandler);
return statementHandler;
}
创建了一个RoutingStatementHandler,并将插件应用到statementHandler上。此处设计到Mybatis插件的实现原理,不再赘述,详情参见Mybatis源码阅读之--插件实现原理分析
看下RoutingStatementHandler的创建过程
public class RoutingStatementHandler implements StatementHandler {
private final StatementHandler delegate;
public RoutingStatementHandler(Executor executor, MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
switch (ms.getStatementType()) {
case STATEMENT:
delegate = new SimpleStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case PREPARED:
delegate = new PreparedStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
case CALLABLE:
delegate = new CallableStatementHandler(executor, ms, parameter, rowBounds, resultHandler, boundSql);
break;
default:
throw new ExecutorException("Unknown statement type: " + ms.getStatementType());
}
}
}
这里又一次使用到了装饰者模式,根据Statement的类型不同,创建不同的StatementHandler,如果此语句类型为statement,则创建一个SimpleStatementHandler,若是一个prepared,则创建一个PreparedStatementHandler,若是Callable,则创建一个CallableStatementHandler。
由于篇幅问题,这里只分析用到最多的PreparedStatementHandler。
而RoutingStatementHandler的其他方法都是调用了delegate的相应方法。
public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException {
return delegate.prepare(connection, transactionTimeout);
}
public void parameterize(Statement statement) throws SQLException {
delegate.parameterize(statement);
}
我们再次回到SimpleExecutor中,创建完了StatementHandler之后,进行Statement的创建。
// SimpleExecutor
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}
首先获得一个连接,然后调用StatementHandler.prepare方法创建Statement
// BaseSatementHandler
public Statement prepare(Connection connection, Integer transactionTimeout) throws SQLException {
ErrorContext.instance().sql(boundSql.getSql());
Statement statement = null;
try {
// 初始化(创建)statement
statement = instantiateStatement(connection);
// 设置语句执行超时时间
setStatementTimeout(statement, transactionTimeout);
// 设置返回数据的大小
setFetchSize(statement);
return statement;
} catch (SQLException e) {
closeStatement(statement);
throw e;
} catch (Exception e) {
closeStatement(statement);
throw new ExecutorException("Error preparing statement. Cause: " + e, e);
}
}
该方法先调用子类的instantiateStatement方法,完成Statement的初始化
然后在设置statement的超时时间以及fetchSize。依然是模板方法模式。
// PreparedStatementHandler
protected Statement instantiateStatement(Connection connection) throws SQLException {
String sql = boundSql.getSql();
// 创建statement需要四个参数:
// 1. sql
// 2. resultSetType 参见ResultSetType枚举
// 3. columnNames
// 4. autoGeneratedKeys
// 5. concurrencyLevel
if (mappedStatement.getKeyGenerator() instanceof Jdbc3KeyGenerator) {
String[] keyColumnNames = mappedStatement.getKeyColumns();
if (keyColumnNames == null) {
return connection.prepareStatement(sql, PreparedStatement.RETURN_GENERATED_KEYS);
} else {
return connection.prepareStatement(sql, keyColumnNames);
}
} else if (mappedStatement.getResultSetType() == ResultSetType.DEFAULT) {
return connection.prepareStatement(sql);
} else {
return connection.prepareStatement(sql, mappedStatement.getResultSetType().getValue(), ResultSet.CONCUR_READ_ONLY);
}
}
通过connection创建PreparedStatement。
至此Statement的创建完成。
再次回到SimpleExecutor中,进行参数的设置:
// SimpleExecutor
private Statement prepareStatement(StatementHandler handler, Log statementLog) throws SQLException {
Statement stmt;
Connection connection = getConnection(statementLog);
stmt = handler.prepare(connection, transaction.getTimeout());
handler.parameterize(stmt);
return stmt;
}
使用StatementHandler进行参数的初始化
// PreparedStatementHandler
public void parameterize(Statement statement) throws SQLException {
parameterHandler.setParameters((PreparedStatement) statement);
}
这里调用了ParameterHandler.setParameters方法进行初始化参数,ParameterHandler的默认实现类为DefaultParameterHandler
而ParameterHandler是在StatementHanler创建的时候进行创建的
protected BaseStatementHandler(Executor executor, MappedStatement mappedStatement, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) {
// ....其他操作
this.parameterHandler = configuration.newParameterHandler(mappedStatement, parameterObject, boundSql);
this.resultSetHandler = configuration.newResultSetHandler(executor, mappedStatement, rowBounds, parameterHandler, resultHandler, boundSql);
}
// Configuration类
public ParameterHandler newParameterHandler(MappedStatement mappedStatement, Object parameterObject, BoundSql boundSql) {
ParameterHandler parameterHandler = mappedStatement.getLang().createParameterHandler(mappedStatement, parameterObject, boundSql);
parameterHandler = (ParameterHandler) interceptorChain.pluginAll(parameterHandler);
return parameterHandler;
}
使用LanguageDriver创建ParameterHandler,然后处理插件。
DefaultParameter处理参数的代码就不解释了,有兴趣自己可以看一看。
思绪拉回到SimpleExecutor的doQuery方法:
public <E> List<E> doQuery(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, BoundSql boundSql) throws SQLException {
Statement stmt = null;
try {
Configuration configuration = ms.getConfiguration();
StatementHandler handler = configuration.newStatementHandler(wrapper, ms, parameter, rowBounds, resultHandler, boundSql);
stmt = prepareStatement(handler, ms.getStatementLog());
return handler.query(stmt, resultHandler);
} finally {
closeStatement(stmt);
}
}
目前已经分析到最后一步,handler.query()。
// PreparedStatementHandler
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
return resultSetHandler.handleResultSets(ps);
}
执行ps.execute()的方法进行数据的查询,然后调用resultSetHandler.handleResultStes方法处理结果集,将结果集转换为List,并返回。
至此,整体流程已经分析完毕。
总结:
Mybatis整体操作流程主要为以下几点:
- sqlSessiong.query
- executor.query
- statementHandler.prepareStatement准备statement
- parameterHanler.setParameter设置参数
- resultSetHandler.handleResultSets处理结果集
最后来一张时序图来有个直观的感受
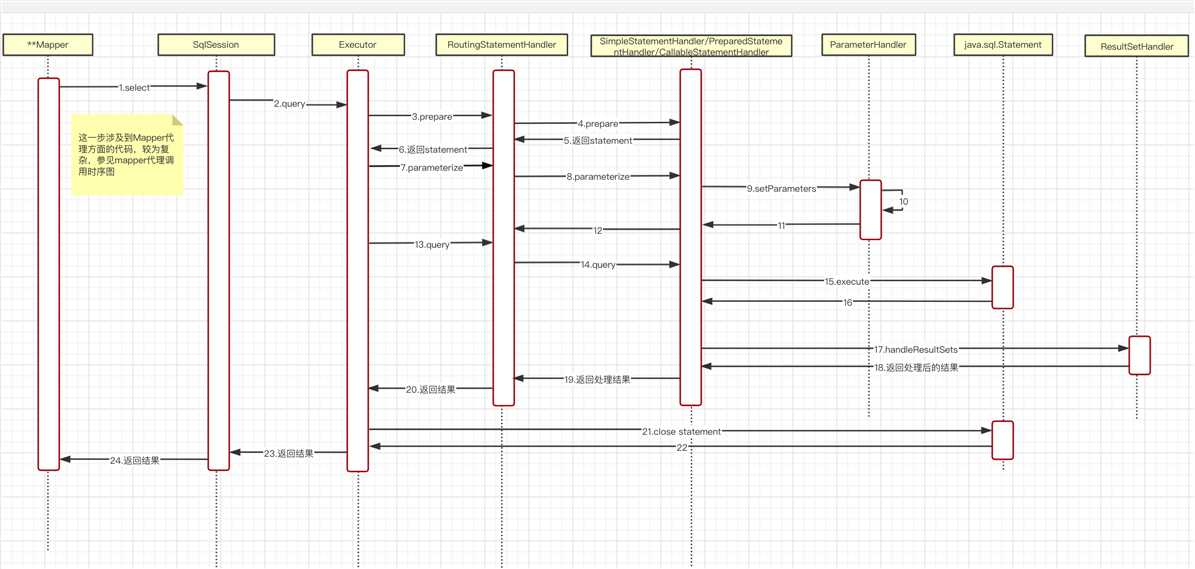
以上是关于Mybatis源码阅读之--整体执行流程的主要内容,如果未能解决你的问题,请参考以下文章
Android 逆向整体加固脱壳 ( DEX 优化流程分析 | DexPrepare.cpp 中 dvmOptimizeDexFile() 方法分析 | /bin/dexopt 源码分析 )(代码片段
图文并茂源码解析MyBatis Sharding-Jdbc SQL语句执行流程详解