Java集合框架04
Posted zhaochuming
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java集合框架04相关的知识,希望对你有一定的参考价值。
集合框架·Map 和 Collections集合工具类
Map集合的概述和特点
* A:Map接口概述
* 查看API可知:
* 将键映射到值的对象
* 一个映射不能包含重复的键
* 每个键最多只能映射到一个值
* B:Map接口和Collection接口的不同
* Map是双列的,Collection是单列的
* Map的键唯一,Collection的子体系Set是唯一的
* Map集合的数据结构值针对键有效,跟值无关;Collection集合的数据结构是针对元素有效
* Set底层依赖的是Map

Map集合的功能概述
* A:Map集合的功能概述
* a:添加功能
* V put (K key, V value) ;添加元素
* 如果键是第一次存储,就直接存储元素,返回null
* 如果键不是第一次存储,就用替换原来的值,返回以前的值
* b:删除功能
* void clear() :移除所有的键值对元素
* V remove(Object key) :根据键删除键值对的元素,并把值返回
* c:判断功能
* boolean containsKey(Object key) :判断集合是否包含指定的键
* boolean containsValue(Object value) :判断集合是否包含指定的值
* boolean isEmpty() :判断集合是否为空
* d:获取功能
* Set<Map.Entry<K, V>> entrySet()
* V get(Object key) :根据键获取值
* Set<K> keySet() :获取集合中所有键的集合
* Collection<V> values() :获取集合中所有值的集合
* e:长度功能
* int size() :返回集合中的键值对个数


package com.heima.map; import java.util.Collection; import java.util.HashMap; import java.util.Map; public class Demo1_Map { public static void main(String[] args) { // demo1(); // 添加元素 // demo2(); // 删除元素 // demo3(); } public static void demo3() { Map<String, Integer> map = new HashMap<String, Integer>(); map.put("张三", 23); map.put("李四", 24); map.put("王五", 25); map.put("赵六", 26); Collection<Integer> c = map.values(); System.out.println(c); System.out.println(map.size()); // 返回元素的值,一个键值对算作一个元素 } public static void demo2() { Map<String, Integer> map = new HashMap<String, Integer>(); map.put("张三", 23); map.put("李四", 24); map.put("王五", 25); map.put("赵六", 26); Integer integer = map.remove("张三"); // 根据键删除元素,并且返回键对应的值 System.out.println(map); System.out.println(integer); System.out.println(map.containsKey("张三")); // 判断是否包含指定键 System.out.println(map.containsValue(24)); // 判断是否包含指定值 } public static void demo1() { Map<String, Integer> map = new HashMap<String, Integer>(); // 创建双链集合对象 Integer v1 = map.put("张三", 23); // 返回被覆盖的值,原先如果没有值,就返回null Integer v2 = map.put("李四", 24); Integer v3 = map.put("王五", 25); Integer v5 = map.put("张三", 26); // 相同的键不存储,替换值并返回原值 System.out.println(map); // System.out.println(v1); // null System.out.println(v2); // null System.out.println(v3); // null System.out.println(v5); // 23 } }
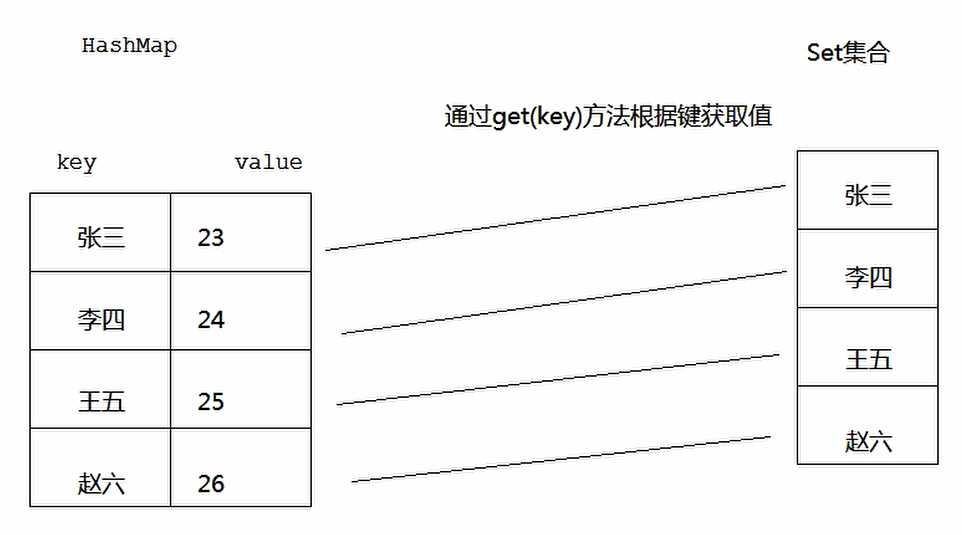
Map集合的遍历之根据键找值
* A:键找值的思路
* 获取所有键的集合
* 遍历键的集合,获取到每一个键
* 根据键找值
* B:案例演示
* Map集合的遍历之键找值
* C:Map集合不能直接迭代
package com.heima.map; import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Set; public class Demo2_Iterator { // Map集合不能直接得带 public static void main(String[] args) { Map<String, Integer> map = new HashMap<String, Integer>(); map.put("张三", 23); map.put("李四", 24); map.put("王五", 25); map.put("赵六", 26); Integer i = map.get("张三"); // 根据键获取值 System.out.println(i); demo1(map); System.out.println("---------"); demo2(map); } public static void demo2(Map<String, Integer> map) { // 使用增强for循环 for (String key : map.keySet()) { // map.KeySet() 是所有键的集合 System.out.println(key + "=" + map.get(key)); } } public static void demo1(Map<String, Integer> map) { // 获取所有键, 对键的集合迭代 Set<String> keySet = map.keySet(); // 获取所有键的集合 // System.out.println(keySet); Iterator<String> it = keySet.iterator(); // 获取键的集合的迭代器 while (it.hasNext()) { // 判断集合中是否有元素 String string = (String) it.next(); // 获取每一个键 Integer valueInteger = map.get(string); System.out.println(string + "=" + valueInteger); } } }
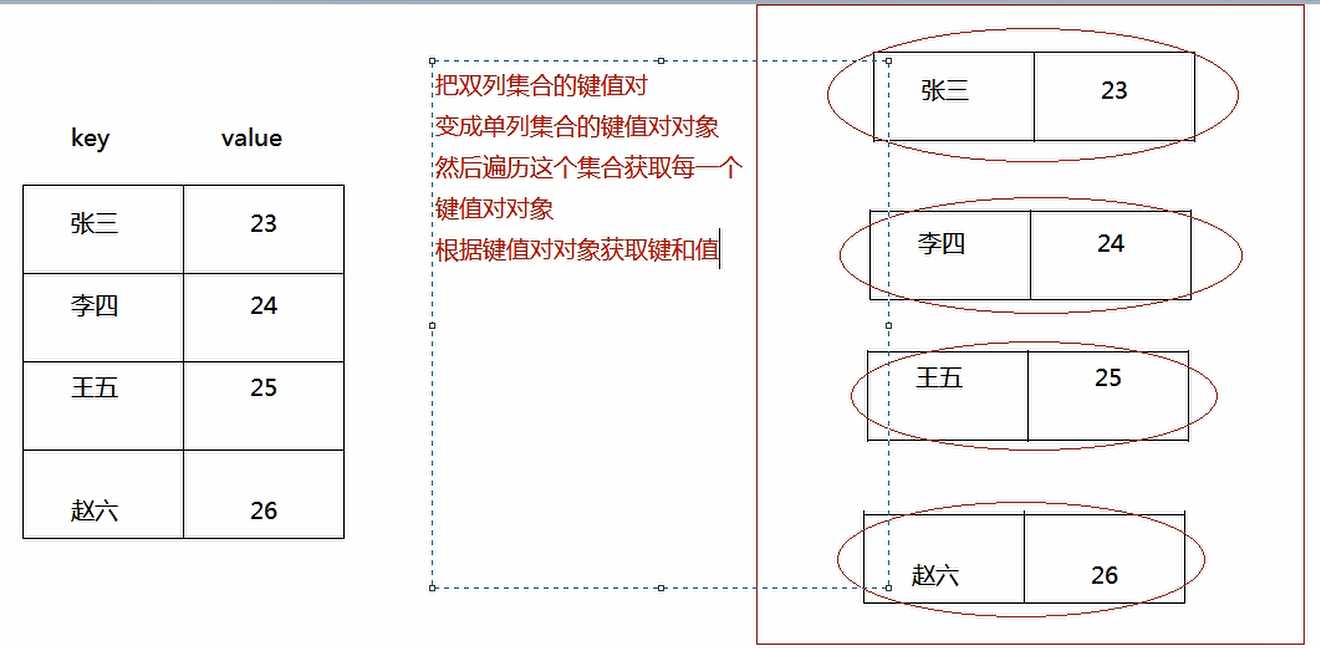
Map集合的遍历之通过键值对对象找键和值
* A:键值对对象找键和值的思路
* 获取所有键值对对象的集合
* 遍历键值对对象的集合,获取到每一个键值对对象
* 根据键值对对象找键和值
* B:案例演示
* Map集合的遍历之键值对对象中键和值
package com.heima.map; public class Demo4_MapEntry { public static void main(String[] args) { } } interface Inter { interface Inter2 { public void show(); } } class Demo implements Inter.Inter2 { // 实现 接口内的接口 @Override public void show() { // 重写抽象方法 System.out.println("show"); } }
package com.heima.map; import java.util.HashMap; import java.util.Iterator; import java.util.Map; import java.util.Map.Entry; import java.util.Set; public class Demo3_Iterator { // 根据键值对对象获取键和值 public static void main(String[] args) { Map<String, Integer> map = new HashMap<String, Integer>(); map.put("张三", 23); map.put("李四", 24); map.put("王五", 25); map.put("赵六", 26); // demo1(map); // demo2(map); } public static void demo2(Map<String, Integer> map) { // 开发中推荐使用 for (Map.Entry<String, Integer> entry : map.entrySet()) { System.out.println(entry.getKey() + "=" + entry.getValue()); } } public static void demo1(Map<String, Integer> map) { // Map.Entry 说明 Entry是Map接口内的接口,将 键值对 封装成Entry对象,并存储在Set集合中 //Set<Map.Entry<String, Integer>> entrySet = map.entrySet(); //Iterator<Map.Entry<String, Integer>> it = entrySet.iterator; Iterator<Map.Entry<String, Integer>> it = map.entrySet().iterator(); while (it.hasNext()) { Map.Entry<String, Integer> entry = it.next(); String key = entry.getKey(); // 根据键值对对象 获取键 Integer value = entry.getValue(); // 根据键值对对象 获取值 System.out.println(key + "=" + value); } } }
HashMap集合键是Student,值是String的案例
* A:案例分析
* HashMap集合键是Student,值是String的案例
package com.heima.map; import java.util.HashMap; import com.heima.bean.Student; public class Demo5_HashMap { public static void main(String[] args) { HashMap<Student, String> hm = new HashMap<Student, String>(); // 键是学生对象,代表每一个学生 // 值是字符串对象,代表学生归属地 hm.put(new Student("张三", 23), "北京"); hm.put(new Student("张三", 23), "杭州"); // 自定义类的对象需要重写hashCode和equals hm.put(new Student("李四", 24), "上海"); hm.put(new Student("王五", 25), "广州"); hm.put(new Student("赵六", 26), "深圳"); System.out.println(hm); } }
LinkedHashMap的概述和使用
* A:案例演示
* LinkedHashMap的特点
* 底层是链表实现的可以保证怎么存就怎么取

package com.heima.map; import java.util.LinkedHashMap; public class Demo6_LinkedHashMap { public static void main(String[] args) { LinkedHashMap<String, Integer> lhm = new LinkedHashMap<String, Integer>(); lhm.put("张三", 23); lhm.put("李四", 24); lhm.put("赵六", 26); lhm.put("王五", 25); System.out.println(lhm); } }
TreeMap集合键是Student,值是String的案例
* A:案例演示
* TreeMap集合键是Student,值是String的案例
package com.heima.map; import java.util.Comparator; import java.util.TreeMap; import com.heima.bean.Student; public class Demo7_TreeMap { public static void main(String[] args) { // demo1(); // 类中实现comparable接口,add方法调用compareTo方法 // demo2(); // 集合的构造方法中使用比较器comparator,add方法调用compare方法 } public static void demo2() { TreeMap<Student, String> tm = new TreeMap<Student, String>(new Comparator<Student>() { @Override public int compare(Student o1, Student o2) { int num = o1.getName().compareTo(o2.getName()); return num == 0 ? o1.getAge() - o2.getAge() : num; } }); tm.put(new Student("张三", 23), "北京"); tm.put(new Student("李四", 24), "上海"); tm.put(new Student("赵六", 26), "深圳"); tm.put(new Student("王五", 25), "广州"); System.out.println(tm); } public static void demo1() { TreeMap<Student, String> tm = new TreeMap<Student, String>(); tm.put(new Student("张三", 23), "北京"); tm.put(new Student("李四", 24), "上海"); tm.put(new Student("赵六", 26), "深圳"); tm.put(new Student("王五", 25), "广州"); System.out.println(tm); } }
统计字符串中每个字符出现的次数
* A:案例演示
* 需求:统计字符串中每个字符出现的次数
package com.heima.test; import java.util.HashMap; import java.util.Scanner; public class Test1 { /* * 分析: * 1、创建键盘录入对象 * 2、录入字符串 * 3、将字符串转换为字符数组 * 4、定义双列集合,存储字符串中的字符以及字符出现的次数 * 5、遍历字符数组,获取每一个字符,并将字符存储在双列集合中 * 6、存储过程中做判断,如果集合中不包含这个键,就把这个字符作为键,值存储为1;如果包含,就将值加1存储 * 7、打印双列集合 */ public static void main(String[] args) { Scanner sc = new Scanner(System.in); // 创建键盘录入对象 String line = sc.nextLine(); // 录入字符串 char[] arr = line.toCharArray();// 将字符串转换为字符数组 HashMap<Character, Integer> map = new HashMap<Character, Integer>();// 没有特殊要求就用HashMap,因为它是所有Map中效率最高的 for (char c : arr) { // 遍历字符数组,获取每一个字符 /*if (!map.containsKey(c)) { // 如果不包含 map.put(c, 1); // 键为字符,值为1 } else { // 如果包含 map.put(c, map.get(c) + 1); // 键为字符,值为原值加一 }*/ map.put(c, !map.containsKey(c) ? 1 : map.get(c) + 1); // 做判断,并存储 } System.out.println(map); // 打印双列集合 } }
集合框架之HashMap嵌套HashMap
* A:案例演示
* 集合嵌套之HashMap嵌套HashMap
package com.heima.map; import java.util.HashMap; import com.heima.bean.Student; public class Demo8_HashMap { public static void main(String[] args) { // 定义88期基础班 HashMap<Student, String> hm88 = new HashMap<Student, String>(); hm88.put(new Student("张三", 23), "北京"); hm88.put(new Student("李四", 24), "北京"); hm88.put(new Student("王五", 25), "上海"); hm88.put(new Student("赵六", 26), "广州"); // 定义99期基础班 HashMap<Student, String> hm99 = new HashMap<Student, String>(); hm99.put(new Student("唐僧", 1023), "花果山"); hm99.put(new Student("悟空", 1024), "长安城"); hm99.put(new Student("八戒", 1025), "高老庄"); hm99.put(new Student("沙僧", 1026), "流沙河"); // 定义双元课堂 HashMap<HashMap<Student, String>, String> hm = new HashMap<HashMap<Student, String>, String>(); hm.put(hm88, "第88期基础班"); hm.put(hm99, "第99期基础班"); for (HashMap<Student, String> hMap : hm.keySet()) { // hm.KeySet()代表的是双链集合中键的集合 String valString = hm.get(hMap); // get(hMap)根据键对象获取值对象 for (Student s : hMap.keySet()) { // 遍历键的双列集合对象,hMap.KeySet()获取集合中所有的学生键对象 String val2String = hMap.get(s); System.out.println(s + "=" + val2String + "=" + valString); } System.out.println("---------------------------"); } } }
HashMap和Hashtable的区别
* A: 面试题
* HashMap和Hashtable的区别
* Hashtable是JDK1.0版本出现的,是线程安全的,效率低;HashMap是JDK1.2版本出现的,是线程不安全的,效率高
* Hashtable不可以存储null键和null值,HashMap可以存储null键和null值
* B:案例演示
* HashMap和Hashtable的区别
package com.heima.map; import java.util.HashMap; import java.util.Hashtable; public class Demo9_HashTable { /* 面试题 * HashMap和Hashtable的区别: * 共同点:底层都是哈希算法,都是双列集合 * 区别:前者线程不安全,效率高,JDK1.2版本出现;后者线程安全,效率相对较低,JDK1.0版本出现 * 前者可以存储null键和null值;后者不可以 */ public static void main(String[] args) { HashMap<String, Integer> hm = new HashMap<String, Integer>(); hm.put(null, null); hm.put("张三", null); System.out.println(hm); Hashtable<String, Integer> ht = new Hashtable<String, Integer>(); //ht.put(null, 23); // NullPointerException //ht.put("张三", null); } }
Collections工具类的概述和常见方法讲解
* A:Collections类概述
* 针对集合操作的工具类
* B:Collections成员方法
public static <T> void sort(List<T>list) public static <T> int binarySearch(List<?> list, T key) public static <T> T max(Collection<?> coll) public static void reverse(List<?> list) public static void shuffle(List<?> list)

package com.heima.collections; import java.util.ArrayList; import java.util.Collections; public class Demo1_Collections { public static void main(String[] args) { // demo1(); // demo2(); // demo3(); } public static void demo3() { ArrayList<String> list = new ArrayList<String>(); list.add("a"); list.add("b"); list.add("c"); list.add("d"); list.add("e"); list.add("f"); list.add("g"); System.out.println(Collections.max(list)); // 底层会先排序,因此即使是无序的也能max Collections.reverse(list); // 反转集合 Collections.shuffle(list); // 将元素打乱,可以用来洗牌 System.out.println(list); } public static void demo2() { ArrayList<String> list = new ArrayList<String>(); list.add("a"); list.add("b"); list.add("c"); list.add("d"); list.add("e"); list.add("f"); list.add("g"); System.out.println(Collections.binarySearch(list, "s")); } public static void demo1() { ArrayList<String> list = new ArrayList<String>(); list.add("a"); list.add("a"); list.add("b"); list.add("c"); list.add("a"); list.add("c"); list.add("a"); System.out.println(list); Collections.sort(list); // 排序,底层调用compareTo或compare方法,重复的保留 System.out.println(list); } }
模拟斗地主洗牌和发牌
* A:案例演示
* 模拟斗地主洗牌和发牌,牌没有顺序
package com.heima.test; import java.util.ArrayList; import java.util.Collections; public class Test2 { /* * 分析: * 1、买一副扑克,其实就是自己创建一个集合对象,将扑克牌存储进去 * 2、洗牌,调用Collections.shuffle方法 * 3、发牌,每个人17张, * 4、看牌 */ public static void main(String[] args) { String[] num = { "A", "2", "3", "4", "5", "6", "7", "8", "9", "10", "J", "Q", "K" }; // 定义牌的大小 String[] color = { "红桃", "黑桃", "方块", "梅花" }; // 定义牌的花色 ArrayList<String> poker = new ArrayList<String>(); // 定义扑克牌集合 // 拼接花色和数字 for (String s1 : color) { // 遍历花色数组 for (String s2 : num) { // 遍历牌面数组 poker.add(s1.concat(s2)); // 字符串拼接 } } poker.add("大王"); poker.add("小王"); Collections.shuffle(poker); // 洗牌 ArrayList<String> gaojin = new ArrayList<String>(); ArrayList<String> longwu = new ArrayList<String>(); ArrayList<String> me = new ArrayList<String>(); ArrayList<String> dipai = new ArrayList<String>(); for (int i = 0; i < poker.size(); i++) { // 发牌 if (i >= poker.size() - 3) { dipai.add(poker.get(i)); // 将三张底牌存储在底牌集合中 } else if (i % 3 == 0) { gaojin.add(poker.get(i)); } else if (i % 3 == 1) { longwu.add(poker.get(i)); } else { me.add(poker.get(i)); } } System.out.println(dipai); // 看牌 System.out.println(gaojin); System.out.println(longwu); System.out.println(me); } }
* 模拟斗地主洗牌和发牌,牌有顺序

package com.heima.test; import java.util.ArrayList; import java.util.Collections; import java.util.HashMap; import java.util.TreeSet; public class Test3 { /* * 分析: */ public static void main(String[] args) { String[] num = { "3", "4", "5", "6", "7", "8", "9", "10", "J", "Q", "K", "A", "2" }; // 定义牌面大小 String[] color = { "红桃", "黑桃", "方块", "梅花" }; // 定义花色 HashMap<Integer, String> hm = new HashMap<Integer, String>(); // 定义双链集合,存储索引和扑克牌 ArrayList<Integer> list = new ArrayList<Integer>(); // 存储索引,方便洗牌 int index = 0; // 定义索引 for (String s1 : num) { for (String s2 : color) { hm.put(index, s2.concat(s1)); // 拼接扑克牌,并将索引和扑克牌 存储在双链集合中 list.add(index); // 存储索引值 index++; // 索引值加加 } } hm.put(index, "小王"); // 添加小王 list.add(index++); // 先添加小王索引,再加加 hm.put(index, "大王"); // 添加大王 list.add(index); // 添加大王索引 Collections.shuffle(list); // 洗牌 TreeSet<Integer> gaojin = new TreeSet<Integer>(); // 定义TreeSet使牌自动排序 TreeSet<Integer> longwu = new TreeSet<Integer>(); TreeSet<Integer> me = new TreeSet<Integer>(); TreeSet<Integer> dipai= new TreeSet<Integer>(); for (int i = 0; i < list.size(); i++) { //发牌 if (i >= list.size() - 3) { dipai.add(list.get(i)); // 将三张底牌存储在底牌集合中 } else if (i % 3 == 0) { gaojin.add(list.get(i)); } else if (i % 3 == 1) { longwu.add(list.get(i)); } else { me.add(list.get(i)); } } kanpai(hm, dipai); // 看牌 kanpai(hm, gaojin); kanpai(hm, longwu); kanpai(hm, me); } /* * 看牌: * 1、返回值类型是void * 2、参数列表HashMap键值关系,TreeMap牌的索引 */ public static void kanpai(HashMap<Integer, String> hm, TreeSet<Integer> dipai) { for (Integer integer : dipai) { System.out.print(hm.get(integer)+" "); } System.out.println(); } }
泛型固定下边界
* ?super E
package com.heima.collections; import java.util.ArrayList; import java.util.Comparator; import java.util.TreeSet; import com.heima.bean.BaseStudent; import com.heima.bean.Student; public class Demo2_Genric { /* * ? super E 泛型固定下边界 儿子可以调用父亲的,存储子类的集合可以调用父类的comparator comparator * ? extends E 泛型固定上边界 儿子的是父亲的,存储子类的集合可以添加到存储父类的集合中中 addAll */ public static void main(String[] args) { // demo1(); TreeSet<Student> ts1 = new TreeSet<Student>(new CompareByName()); ts1.add(new Student("张三", 23)); ts1.add(new Student("李四", 13)); ts1.add(new Student("王五", 23)); ts1.add(new Student("赵六", 43)); System.out.println(ts1); TreeSet<BaseStudent> ts2 = new TreeSet<BaseStudent>(new CompareByName()); ts2.add(new BaseStudent("张三", 23)); ts2.add(new BaseStudent("李四", 13)); ts2.add(new BaseStudent("王五", 23)); ts2.add(new BaseStudent("赵六", 43)); System.out.println(ts2); } public static void demo1() { // ? extends E 泛型固定上边界 ArrayList<Student> list1 = new ArrayList<Student>(); list1.add(new Student("张三", 23)); list1.add(new Student("李四", 24)); ArrayList<BaseStudent> list2 = new ArrayList<>(); list2.add(new BaseStudent("张三", 23)); list2.add(new BaseStudent("李四", 24)); list1.addAll(list2); // 把子类对象添加到父类中 } } class CompareByName implements Comparator<Student> { @Override public int compare(Student o1, Student o2) { int num = o1.getName().compareTo(o2.getName()); return num == 0 ? o1.getAge() - o2.getAge() : num; } }
以上是关于Java集合框架04的主要内容,如果未能解决你的问题,请参考以下文章