java-CPU Cache 与缓存行 转
Posted myseries
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java-CPU Cache 与缓存行 转相关的知识,希望对你有一定的参考价值。
引言
首先我们来看一个Java的例子:
public class Main { static long[][] arr; public static void main(String[] args) { arr = new long[1024 * 1024][8]; // 横向遍历 long marked = System.currentTimeMillis(); for (int i = 0; i < 1024 * 1024; i += 1) { for (int j = 0; j < 8; j++) { sum += arr[i][j]; } } System.out.println("Loop times:" + (System.currentTimeMillis() - marked)+ "ms"); marked = System.currentTimeMillis(); // 纵向遍历 for (int i = 0; i < 8; i += 1) { for (int j = 0; j < 1024 * 1024; j++) { sum += arr[j][i]; } } System.out.println("Loop times:" + (System.currentTimeMillis() - marked)+ "ms"); } }
如上述代码所示,定义了一个二维数组 long[][] arr 并且使用了横向遍历和纵向遍历两种顺序对这个二位数组进行遍历,遍历总次数相同,只不过循环的方向不同,代码中记录了这两种遍历方式的耗时,不妨先卖个关子,他们的耗时会有区别吗?
这问题问的和中小学试卷中的:“它们之间有区别吗?如有,请说出区别。”一样没有水准,没区别的话文章到这儿就结束了。事实上,在我的机器上(64 位 mac)多次运行后可以发现:横向遍历的耗时大约为 25 ms,纵向遍历的耗时大约为 60 ms,前者比后者快了 1 倍有余。如果你了解上述现象出现的原因,大概能猜到,今天这篇文章的主角便是他了— CPU Cache&Cache Line。
在学生生涯时,不断收到这样建议:《计算机网络》、《计算机组成原理》、《计算机操作系统》、《数据结构》四门课程是至关重要的,而在我这些年的工作经验中也不断地意识到前辈们如此建议的原因。作为一个 Java 程序员,你可以选择不去理解操作系统,组成原理(相比这二者,网络和数据结构跟日常工作联系得相对紧密),这不会降低你的 KPI,但了解他们可以使你写出更加计算机友好(Mechanical Sympathy)的代码。
下面的章节将会出现不少操作系统相关的术语,我将逐个介绍他们,并最终将他们与 Java 联系在一起。
什么是 CPU 高速缓存?
CPU 是计算机的心脏,最终由它来执行所有运算和程序。主内存(RAM)是数据(包括代码行)存放的地方。这两者的定义大家应该不会陌生,那 CPU 高速缓存又是什么呢?
在 计算机 系统中,CPU 高速缓存 是用于减少处理器访问内存所需平均时间的部件。在金字塔式存储体系 中它位于自顶向下的第二层,仅次于CPU 寄存器。其容量远小于内存,但速度却可以接近处理器的频率。
当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。
缓存之所以有效,主要是因为程序运行时对内存的访问呈现局部性(Locality)特征。这种局部性既包括空间局部性(Spatial Locality),也包括时间局部性(Temporal Locality)。有效利用这种局部性,缓存可以达到极高的命中率。
在处理器看来,缓存是一个透明部件。因此,程序员通常无法直接干预对缓存的操作。但是, 确实可以根据缓存的特点对程序代码实施特定优化,从而更好地利用缓存 。
— 维基百科

CPU 缓存架构
上图为最简单的高速缓存的架构,数据的读取和存储都经过高速缓存,CPU 核心与高速缓存有一条特殊的快速通道;主存与高速缓存都连在系统总线上(BUS),这条总线还用于其他组件的通信。简而言之,CPU 高速缓存就是位于 CPU 操作和主内存之间的一层缓存。
为什么需要有 CPU 高速缓存?
随着工艺的提升,最近几十年 CPU 的频率不断提升,而受制于制造工艺和成本限制,目前计算机的内存在访问速度上没有质的突破。因此,CPU 的处理速度和内存的访问速度差距越来越大,甚至可以达到上万倍。这种情况下传统的 CPU 直连内存的方式显然就会因为内存访问的等待,导致计算资源大量闲置,降低 CPU 整体吞吐量。同时又由于内存数据访问的热点集中性,在 CPU 和内存之间用较为快速而成本较高(相对于内存)的介质做一层缓存,就显得性价比极高了。
为什么需要有 CPU 多级缓存?
结合 图片 – CPU 缓存架构,再来看一组 CPU 各级缓存存取速度的对比
- 各种寄存器,用来存储本地变量和函数参数,访问一次需要 1cycle,耗时小于 1ns;
- L1 Cache,一级缓存,本地 core 的缓存,分成 32K 的数据缓存 L1d 和 32k 指令缓存 L1i,访问 L1 需要 3cycles,耗时大约 1ns;
- L2 Cache,二级缓存,本地 core 的缓存,被设计为 L1 缓存与共享的 L3 缓存之间的缓冲,大小为 256K,访问 L2 需要 12cycles,耗时大约 3ns;
- L3 Cache,三级缓存,在同插槽的所有 core 共享 L3 缓存,分为多个 2M 的段,访问 L3 需要 38cycles,耗时大约 12ns;
大致可以得出结论,缓存层级越接近于 CPU core,容量越小,速度越快,同时,没有披露的一点是其造价也更贵。所以为了支撑更多的热点数据,同时追求最高的性价比,多级缓存架构应运而生。
什么是缓存行 (Cache Line)?
上面我们介绍了 CPU 多级缓存的概念,而之后的章节我们将尝试忽略“多级”这个特性,将之合并为 CPU 缓存,这对于我们理解 CPU 缓存的工作原理并无大碍。
缓存行 (Cache Line) 便是 CPU Cache 中的最小单位,CPU Cache 由若干缓存行组成,一个缓存行的大小通常是 64 字节(这取决于 CPU),并且它有效地引用主内存中的一块地址。一个 Java 的 long 类型是 8 字节,因此在一个缓存行中可以存 8 个 long 类型的变量。
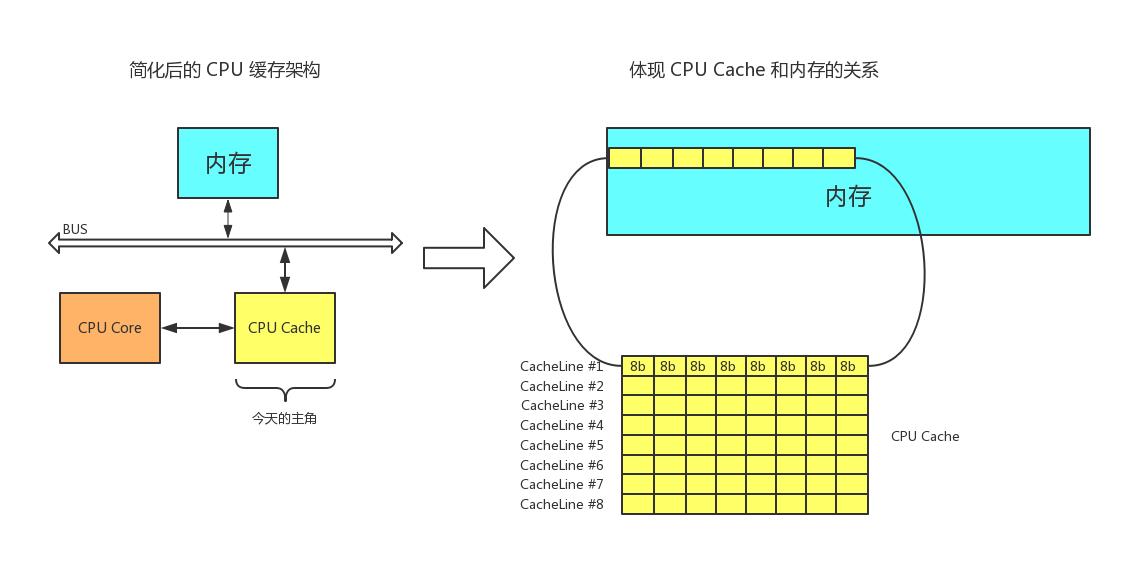
多级缓存
试想一下你正在遍历一个长度为 16 的 long 数组 data[16],原始数据自然存在于主内存中,访问过程描述如下
- 访问 data[0],CPU core 尝试访问 CPU Cache,未命中。
- 尝试访问主内存,操作系统一次访问的单位是一个 Cache Line 的大小 — 64 字节,这意味着:既从主内存中获取到了 data[0] 的值,同时将 data[0] ~ data[7] 加入到了 CPU Cache 之中,for free~
- 访问 data[1]~data[7],CPU core 尝试访问 CPU Cache,命中直接返回。
- 访问 data[8],CPU core 尝试访问 CPU Cache,未命中。
- 尝试访问主内存。重复步骤 2
CPU 缓存在顺序访问连续内存数据时挥发出了最大的优势。试想一下上一篇文章中提到的 PageCache,其实发生在磁盘 IO 和内存之间的缓存,是不是有异曲同工之妙?只不过今天的主角— CPU Cache,相比 PageCache 更加的微观。
再回到文章的开头,为何横向遍历 arr = new long[1024 * 1024][8] 要比纵向遍历更快?此处得到了解答,正是更加友好地利用 CPU Cache 带来的优势,甚至有一个专门的词来修饰这种行为 — Mechanical Sympathy。
伪共享
通常提到缓存行,大多数文章都会提到伪共享问题(正如提到 CAS 便会提到 ABA 问题一般)。
伪共享指的是多个线程同时读写同一个缓存行的不同变量时导致的 CPU 缓存失效。尽管这些变量之间没有任何关系,但由于在主内存中邻近,存在于同一个缓存行之中,它们的相互覆盖会导致频繁的缓存未命中,引发性能下降。伪共享问题难以被定位,如果系统设计者不理解 CPU 缓存架构,甚至永远无法发现 — 原来我的程序还可以更快。
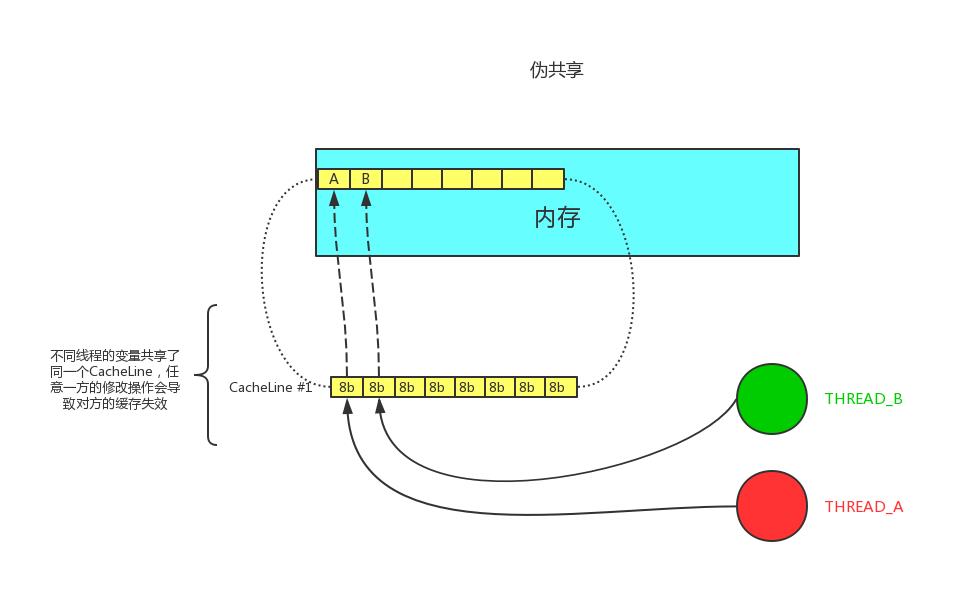
伪共享
正如图中所述,如果多个线程的变量共享了同一个 CacheLine,任意一方的修改操作都会使得整个 CacheLine 失效(因为 CacheLine 是 CPU 缓存的最小单位),也就意味着,频繁的多线程操作,CPU 缓存将会彻底失效,降级为 CPU core 和主内存的直接交互。
伪共享问题的解决方法便是字节填充。
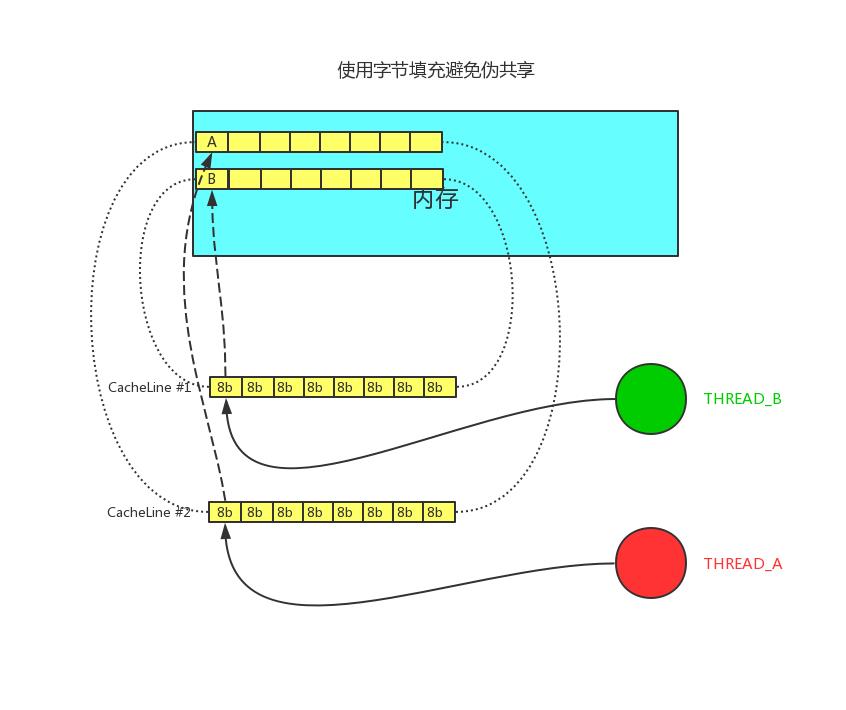
伪共享 - 字节填充
我们只需要保证不同线程的变量存在于不同的 CacheLine 即可,使用多余的字节来填充可以做点这一点,这样就不会出现伪共享问题。在代码层面如何实现图中的字节填充呢?
简单分析一个伪共享的案例
MESI协议
多核CPU都有自己的专有缓存(一般为L1,L2),以及同一个CPU插槽之间的核共享的缓存(一般为L3)。不同核心的CPU缓存中难免会加载同样的数据,那么如何保证数据的一致性呢,就是MESI协议了。
在MESI协议中,每个Cache line有4个状态,可用2个bit表示,它们分别是:
- M(Modified):这行数据有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中;
- E(Exclusive):这行数据有效,数据和内存中的数据一致,数据只存在于本Cache中;
- S(Shared):这行数据有效,数据和内存中的数据一致,数据存在于很多Cache中;
- I(Invalid):这行数据无效。
那么,假设有一个变量i=3(应该是包括变量i的缓存块,块大小为缓存行大小);已经加载到多核(a,b,c)的缓存中,此时该缓存行的状态为S;此时其中的一个核a改变了变量i的值,那么在核a中的当前缓存行的状态将变为M,b,c核中的当前缓存行状态将变为I。如下图:

伪共享问题
那么为什么会出现伪共享问题呢?上诉的情况再扩展一下,假设在多线程情况下,x,y两个共享变量在同一个缓存行中,核a修改变量x,会导致核b,核c中的x变量和y变量同时失效。
此时对于在核a上运行的线程,仅仅只是修改了了变量x,却导致同一个缓存行中的所有变量都无效,需要重新刷缓存(并不一定代表每次都要从内存中重新载入,也有可能是从其他Cache中导入数据,具体的实现要看各个芯片厂商的实现了)。
假设此时在核b上运行的线程,正好想要修改变量Y,那么就会出现相互竞争,相互失效的情况,这就是伪共享啦。
Java中是如何避免伪共享的呢?
Java6 中实现字节填充
public class PaddingObject{ public volatile long value = 0L; // 实际数据 public long p1, p2, p3, p4, p5, p6; // 填充 }
PaddingObject 类中需要保存一个 long 类型的 value 值,如果多线程操作同一个 CacheLine 中的 PaddingObject 对象,便无法完全发挥出 CPU Cache 的优势(想象一下你定义了一个 PaddingObject[] 数组,数组元素在内存中连续,却由于伪共享导致无法使用 CPU Cache 带来的沮丧)。
不知道你注意到没有,实际数据 value + 用于填充的 p1~p6 总共只占据了 7 * 8 = 56 个字节,而 Cache Line 的大小应当是 64 字节,这是有意而为之,在 Java 中, ,所以一个 PaddingObject 对象可以恰好占据一个 Cache Line。
Java7 中实现字节填充
在 Java7 之后,一个 JVM 的优化给字节填充造成了一些影响,上面的代码片段 public long p1, p2, p3, p4, p5, p6; 会被认为是无效代码被优化掉,有回归到了伪共享的窘境之中。
为了避免 JVM 的自动优化,需要使用继承的方式来填充。
abstract class AbstractPaddingObject{ protected long p1, p2, p3, p4, p5, p6;// 填充 } public class PaddingObject extends AbstractPaddingObject{ public volatile long value = 0L; // 实际数据 }
Tips:实际上我在本地 mac 下测试过 jdk1.8 下的字节填充,并不会出现无效代码的优化,个人猜测和 jdk 版本有关,不过为了保险起见,还是使用相对稳妥的方式去填充较为合适。
如果你对这个现象感兴趣,测试代码如下:
public final class FalseSharing implements Runnable { public final static int NUM_THREADS = 4; // change public final static long ITERATIONS = 500L * 1000L * 1000L; private final int arrayIndex; private static VolatileLong[] longs = new VolatileLong[NUM_THREADS]; static { for (int i = 0; i < longs.length; i++) { longs[i] = new VolatileLong(); } } public FalseSharing(final int arrayIndex) { this.arrayIndex = arrayIndex; } public static void main(final String[] args) throws Exception { final long start = System.currentTimeMillis(); runTest(); System.out.println("duration = " + (System.currentTimeMillis() - start)); } private static void runTest() throws InterruptedException { Thread[] threads = new Thread[NUM_THREADS]; for (int i = 0; i < threads.length; i++) { threads[i] = new Thread(new FalseSharing(i)); } for (Thread t : threads) { t.start(); } for (Thread t : threads) { t.join(); } } public void run() { long i = ITERATIONS + 1; while (0 != --i) { longs[arrayIndex].value = i; } } public final static class VolatileLong { public volatile long value = 0L; public long p1, p2, p3, p4, p5, p6; // 填充,可以注释后对比测试 } }
Java8 中实现字节填充
@Retention(RetentionPolicy.RUNTIME) @Target({ElementType.FIELD, ElementType.TYPE}) public @interface Contended { String value() default ""; }
注意需要同时开启 JVM 参数:-XX:-RestrictContended=false
@Contended 注解会增加目标实例大小,要谨慎使用。默认情况下,除了 JDK 内部的类,JVM 会忽略该注解。要应用代码支持的话,要设置 -XX:-RestrictContended=false,它默认为 true(意味仅限 JDK 内部的类使用)。当然,也有个 –XX: EnableContented 的配置参数,来控制开启和关闭该注解的功能,默认是 true,如果改为 false,可以减少 Thread 和 ConcurrentHashMap 类的大小。参加《Java 性能权威指南》210 页。
— @Im 的补充
Java8 中终于提供了字节填充的官方实现,这无疑使得 CPU Cache 更加可控了,无需担心 jdk 的无效字段优化,无需担心 Cache Line 在不同 CPU 下的大小究竟是不是 64 字节。使用 @Contended 注解可以完美的避免伪共享问题。
更多关于避免伪共享的一些Java实践可以参考《CPU Cache 与缓存行》。
一些最佳实践
可能有读者会问:作为一个普通开发者,需要关心 CPU Cache 和 Cache Line 这些知识点吗?这就跟前几天比较火的话题:「程序员有必要懂 JVM 吗?」一样,仁者见仁了。但确实有不少优秀的源码在关注着这些问题。他们包括:
ConcurrentHashMap
面试中问到要吐的 ConcurrentHashMap 中,使用 @sun.misc.Contended 对静态内部类 CounterCell 进行修饰。另外还包括并发容器 Exchanger 也有相同的操作。
/* ---------------- Counter support -------------- */ /** * A padded cell for distributing counts. Adapted from LongAdder * and Striped64. See their internal docs for explanation. */ @sun.misc.Contended static final class CounterCell { volatile long value; CounterCell(long x) { value = x; } }
Thread
Thread 线程类的源码中,使用 @sun.misc.Contended 对成员变量进行修饰。
// The following three initially uninitialized fields are exclusively // managed by class java.util.concurrent.ThreadLocalRandom. These // fields are used to build the high-performance PRNGs in the // concurrent code, and we can not risk accidental false sharing. // Hence, the fields are isolated with @Contended. /** The current seed for a ThreadLocalRandom */ @sun.misc.Contended("tlr") long threadLocalRandomSeed; /** Probe hash value; nonzero if threadLocalRandomSeed initialized */ @sun.misc.Contended("tlr") int threadLocalRandomProbe; /** Secondary seed isolated from public ThreadLocalRandom sequence */ @sun.misc.Contended("tlr") int threadLocalRandomSecondarySeed;
RingBuffer
来源于一款优秀的开源框架 Disruptor 中的一个数据结构 RingBuffer ,我后续会专门花一篇文章的篇幅来介绍这个数据结构
abstract class RingBufferPad { protected long p1, p2, p3, p4, p5, p6, p7; } abstract class RingBufferFields<E> extends RingBufferPad{}
使用字节填充和继承的方式来避免伪共享。
面试题扩展
问:说说数组和链表这两种数据结构有什么区别?
了解了 CPU Cache 和 Cache Line 之后想想可不可以有一些特殊的回答技巧呢?
REFERENCE
以上是关于java-CPU Cache 与缓存行 转的主要内容,如果未能解决你的问题,请参考以下文章