浅析Android启动优化
Posted 初一十五啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅析Android启动优化相关的知识,希望对你有一定的参考价值。
一、引言
本文主要说了四部分内容,第一部分内容是启动基础,第二部分内容是启动优化价值,第三部分内容是启动优化业务痛点,第四部分内容是总结与展望。
启动优化业务痛点主要分为五个方面,第一个方面是业务问题背景,第二个方面是防劣化机制建设,第三个方面是优化思路,第四个方面是调度框架,第五个方面是业务框架。
如果学完启动优化的基础论、工具论、方法论和实战论,那么任何人做启动优化都可以拿到结果。
二、启动基础
我们先进入第二部分内容启动基础,启动基础有六个关键点可以和大家分享一下,第一个关键点是启动进程。第二个关键点是启动方式。第三个关键点是启动流程。第四个关键点是归因分析。第五个关键点是优化方向。第六个关键点是启动指标。

2.1 启动进程
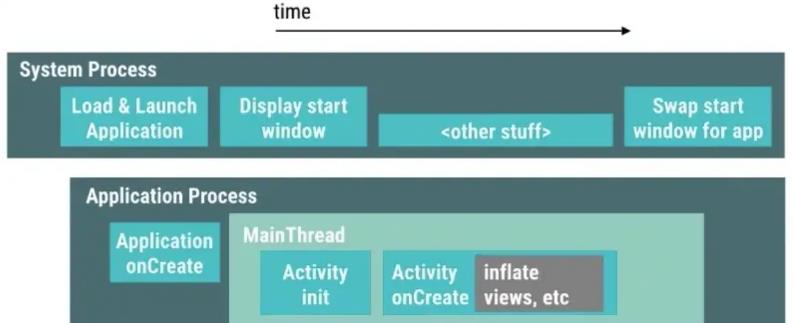
首先,说说第一个关键点启动进程,按照业务是否可直接操作分为SystemServer 和 App Process 。 其职责划分如下:
SystemServer 负责应用的启动流程调度、进程的创建和管理、窗口的创建和管理(StartingWindow 和 AppWindow) 等
应用进程被 SystemServer 创建后,进行一系列的进程初始化、组件初始化(Activity、Service、ContentProvider、Broadcast)、主界面的构建、内容填充等
2.2 启动方式
接着,说说第二个关键点启动方式,android应用的启动方式大概分为热启动、冷启动、温启动三种,关于冷启动、热启动、温启动三者启动方式对比可以参考下面的流程图学习。
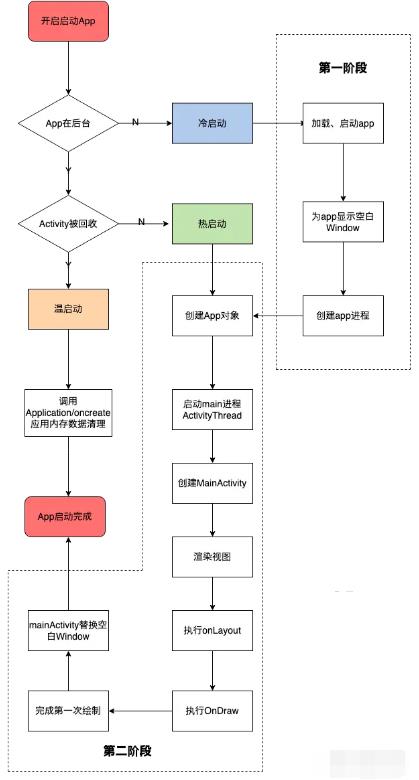
2.1.1 冷启动
冷启动具有耗时最多,衡量标准的特征,冷启动常见的场景是APP首次启动或APP被完全杀死,冷启动、热启动和温启动中冷启动CPU时间开销最大。启动流程简化如下,后文会详细介绍。
2.1.2 温启动
当启动应用时,后台已有该应用的进程,但是Activity可能因为内存不足被回收。这样系统会从已有的进程中来启动这个Activity,这个启动方式叫温启动。
温启动常见的场景有两种:第一种是首先用户按连续按返回退出了app,最后重新启动app,第二种是首先系统收回了app的内存,最后重新启动app。
2.1.3 热启动
热启动只执行了冷启动的第二阶段,如果由于内存不足导致对象被回收,那么需要在热启动时重建对象,后面与冷启动时将界面显示到手机屏幕流程是一样的。
热启动时,系统将activity带回前台。如果应用程序的所有activity存在内存中,那么应用程序可以避免重复对象初始化、渲染、绘制操作。
热启动常见的场景如: 当我们按了Home键或其它情况app被切换到后台,再次启动app的过程。
2.3 启动流程
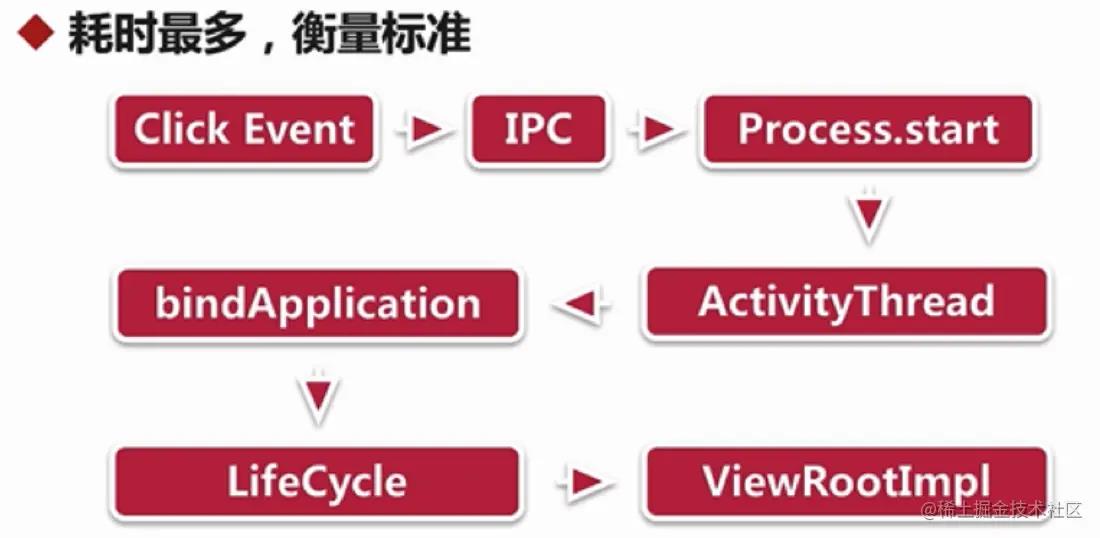
其次,说说第三个关键点启动流程,应用的启动流程一般指的是冷启动流程,即应用进程不存在的情况下,从点击桌面应用图标,到应用启动的过程。
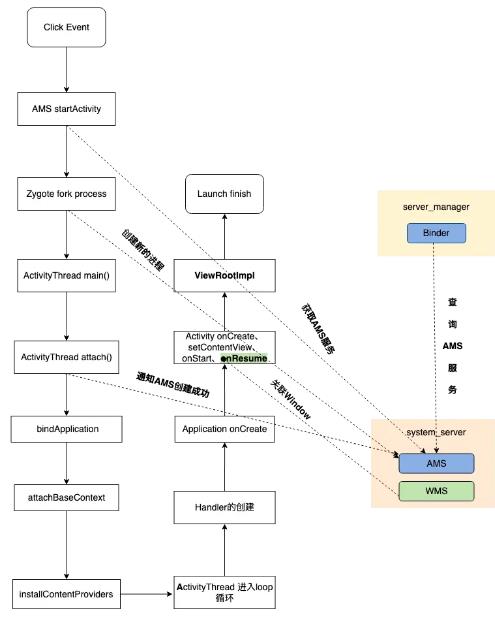
首先,用户进行了一个点击操作,这个点击事件它会触发一个IPC的操作,之后便会执行到Process的start方法中,这个方法是用于进程创建的。
然后,便会执行到ActivityThread的main方法,这个方法可以看做是我们单个App进程的入口,相当于Java进程的main方法,在其中会执行消息循环的创建与主线程Handler的创建。
接着,创建完成之后,就会执行到 bindApplication 方法,在这里使用了反射去创建 Application以及调用了 Application相关的生命周期。
最后,Application结束之后,便会执行Activity的生命周期,在Activity LifeCycle结束之后,就会执行到 ViewRootImpl,这时才会进行真正的一个页面的绘制。
2.4 优化方向
其四,我们说说第四个关键点优化方向,创建Application、启动主线程、创建MainActivity、加载布局、布置屏幕和界面首帧绘制完成后,我们就可以认为启动已经结束了。
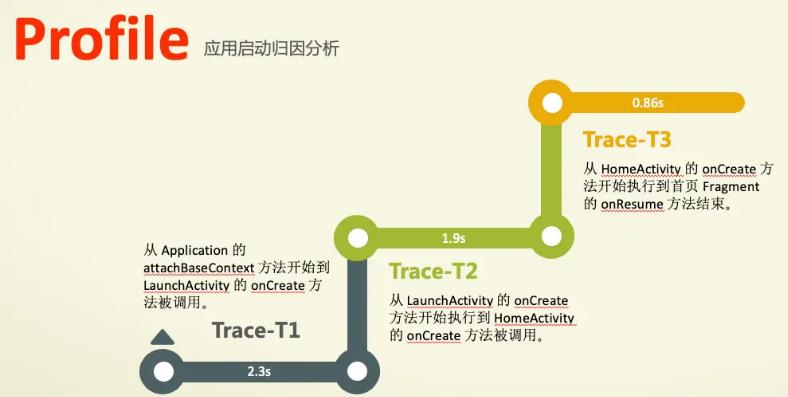
综上所述,除了Application atttachBaseContext、Appication onCreate 和 Activity LifeCycle,无需Hook源码,其余流程都是系统层面的。因此,我们能优化的空间只有Application atttachBaseContext、Appication onCreate 和 Activity LifeCycle三个流程。

2.5 归因分析
其五,我们先说说第五个关键点归因分析,程序运行最根本的是需要得到CPU时间片,如果一个任务需要较多的CPU时间执行,那么它将影响其他任务的执行,从而影响整体任务队列的运行;
线程切换涉及到 CPU调度,而CPU调度会有系统资源的开销,所以大量的线程频繁切换也会产生巨大的性能损耗;
IO和锁的等待会直接阻塞任务的执行,不能充分地利用CPU等系统资源。

因此,做启动优化的关键点是找到占用过多CPU时间、频繁的CPU调度、I/O等待和锁抢占等不合理消耗资源三个因素,这里先简单的看一下Profile分析文件,工具论会带大家详细学习如何使用工具进行线下监控与治理。
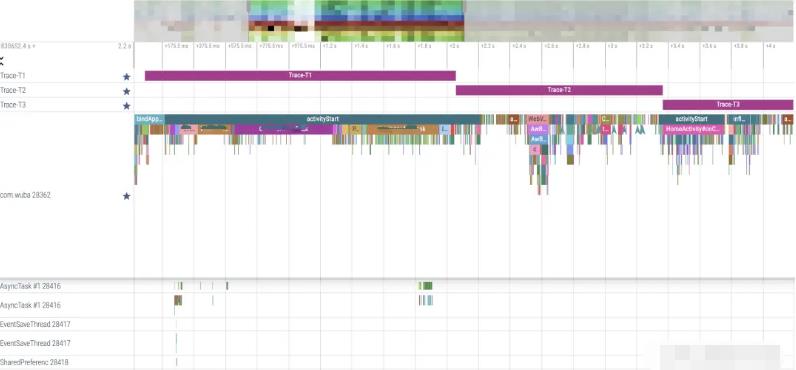
2.6 启动指标
最后,我们说说第六个关键点启动指标,关于启动优化监控当然是在冷启动阶段进行健康预测的。有三个启动指标我们需要额外注意,
第一个是启动开始,启动开始是进程创建的时间
第二个是启动结束,首页首屏渲染完成的时间;
第三个是启动时长,启动时长是指启动结束的时间戳减去启动开始的时间戳;
三、启动优化价值
说完启动基础,我们进入第三部分内容启动优化价值,启动耗时增长可能缩减App用户的留存,因此,启动性能优化是每一家互联网公司在体验优化方向上必须要做的关键技术突破。
启动性能优化目标是以低端机为重点,辐射中高端机,通过技术和产品上的深度优化,可感知的提升用户体验,实现扩大用户规模、提升留存和提升收入。
四、启动优化业务痛点
说完启动优化价值,我们进入第四部分内容启动优化业务痛点。带着问题出发,关于启动优化有低端机性能问题复杂、缺乏整体调度机制、问题定位成本高和监控机制不完善四大业务痛点亟需解决。关于这四大业务痛点我们对如何定义低端机?如何快速发现性能问题? 如何系统化的优化性能问题?如何避免性能优化的同时出现劣化问题,并打造劣化问题修复自运转的飞轮?有了进一步思考。
4.1 如何定义低端机?
关于如何定义低端机?低端机定义要双端对齐思考
Android
Android方面,内存和CPU是描述低端机型的比较关键的两个指标,我们根据Android用户的不同设备做了性能划分,初步可划分为高、中、低3种等级。
根据现有CPU、GPU的跑分软件安兔兔公测跑分维护一份CPU、GPU的设备性能档位表,按照不同档位划分为高、中、低三档。
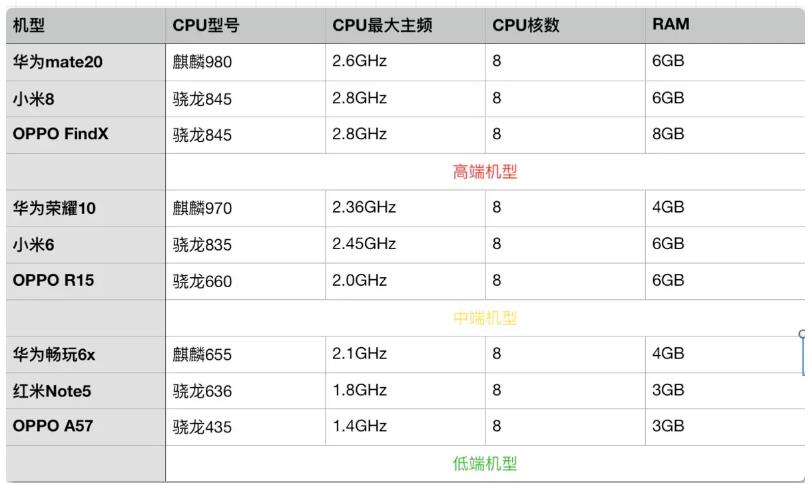
先判断设备的Android系统版本号,如果Android系统低于Android6.0,可以直接划分为低档机再判断设备的内存和内核数:
public static void isLowerDevice()
return Build.VERSION.RELEASE < 6;
//获取RAM容量
public static long getTotalMemory(Context c)
// memInfo.totalMem not supported in pre-Jelly Bean APIs.
if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.JELLY_BEAN)
ActivityManager.MemoryInfo memInfo = new ActivityManager.MemoryInfo();
ActivityManager am = (ActivityManager) c.getSystemService(Context.ACTIVITY_SERVICE);
am.getMemoryInfo(memInfo);
if (memInfo != null)
return memInfo.totalMem;
else
return DEVICEINFO_UNKNOWN;
else long totalMem = DEVICEINFO_UNKNOWN;
try
FileInputStream stream = new FileInputStream("/proc/meminfo");
try
totalMem = parseFileForValue("MemTotal", stream);
totalMem *= 1024;
finally
stream.close();
catch (IOException e)
e.printStackTrace();
return totalMem;
// 获取CPU核心数
public static int getNumberOfCPUCores()
int cores;
try
cores = getCoresFromFileInfo("/sys/devices/system/cpu/possible");if (cores == DEVICEINFO_UNKNOWN)
cores = getCoresFromFileInfo("/sys/devices/system/cpu/present");
if (cores == DEVICEINFO_UNKNOWN)
cores = new File("/sys/devices/system/cpu/").listFiles(CPU_FILTER).length;
catch (SecurityException e)
cores = DEVICEINFO_UNKNOWN;
catch (NullPointerException e)
cores = DEVICEINFO_UNKNOWN;return cores;
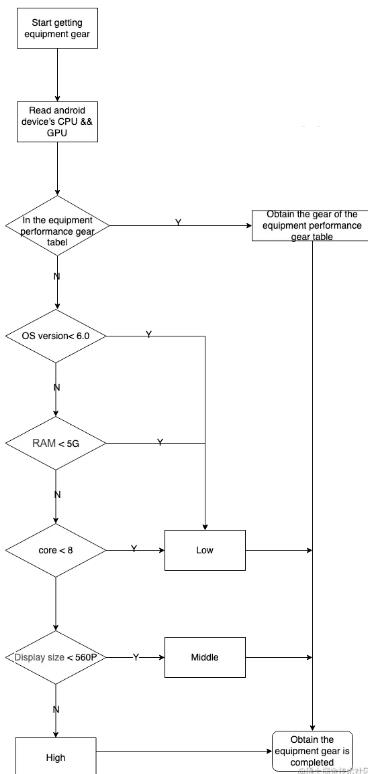
当没有取到CPU、GPU型号或者CPU、GPU型号在设备性能档位表里面不存在时,通过设备的CPU和RAM组合信息来判定。判定规则如下:
高端机型: CPU为骁龙845或麒麟980,RAM大于等于6GB
低端机型: 骁龙或联发科系列,CPU最大主频小于等于1.8GHz且RAM小于4GB。麒麟系列,CPU最大主频小于等于2.1GHz且RAM小于等于4GB
中端机型: 剩余法
//获取CPU型号
public static String getCPUName()
try
FileReader fr = new FileReader("/proc/cpuinfo");
BufferedReader br = new BufferedReader(fr);
String text;
String last = "";
while ((text = br.readLine()) != null)
last = text;
//一般机型的cpu型号都会在cpuinfo文件的最后一行
if (last.contains("Hardware"))
String[] hardWare = last.SharedPreferenceslit(":\\s+", 2);
return hardWare[1];
catch (FileNotFoundException e)
e.printStackTrace();
catch (IOException e)
e.printStackTrace();
return Build.HARDWARE;
ios
iOS方面,机型种类优先,可枚举,因此可通过配置表直接读取机型评分分数,低端机占大盘比例 15%。
4.2 如何快速发现性能问题?
关于如何快速发现性能问题?我们是根据设备类型、Android系统版本号、手机品牌、启动时长、系统平台、app版本号、app名称、闪屏广告阻断次数和设备ID等字段结合数据大盘分析平台,针对预发布环境和正式环境建设应用级的基础调度机制,服务于业务,并协助业务优化性能;如果预发布环境启动超标,那么向开发主力团队发送飞书机器人告警提醒。
4.3 如何系统化的优化性能问题?
关于如何系统化的优化性能问题?我们借助了 Dokit工具提效,自建稳定且高效性能工具,通过DoKit进行源码魔改,提高发现问题效率;慢函数闭环监控借助了ASM插桩打点实现,详细内容我们可以参考后续的启动优化 · 实战论 · 手把手教你破解启动优化十大难题。
4.4 如何避免性能优化的同时出现劣化问题,并打造劣化问题修复自运转的飞轮?
关于如何避免性能优化的同时出现劣化问题,并打造劣化问题修复自运转的飞轮?我们首先利用启动器将启动任务颗粒化,然后针对任务的时长统计上报,最后通过 **Appium**等自动化测试架构进行测试,app每个版本集成回归时,测试同学会在测试平台跑一遍性能测试并输出测试报告。
报告包含了定义的核心场景下,app的内存、CPU、启动时长等性能指标数据及版本对比波动值。
在允许的波动范围内,比如启动时长波动<100ms,那么就认为测试通过,否则就认为数据有恶化趋势,测试不通过,需要研发排查优化,直到测试通过。
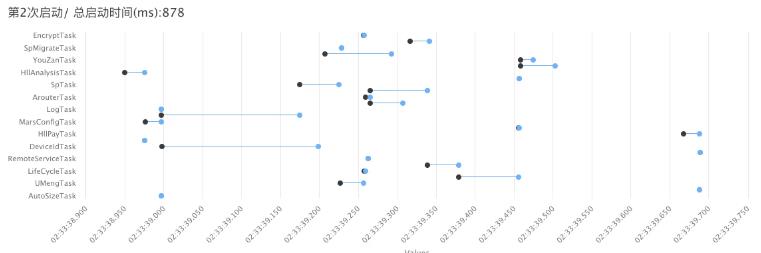
当然未来希望借助已 搭建云真机测试平台,可以考虑通过Docker容器化技术在云真机上自动化测试。测试平台直接自动化分析、自动化转发,全程自助,无人工干预。
下面我们一起来学习一下百度低端机启动性能优化观测设施、基础设施和业务优化吧。
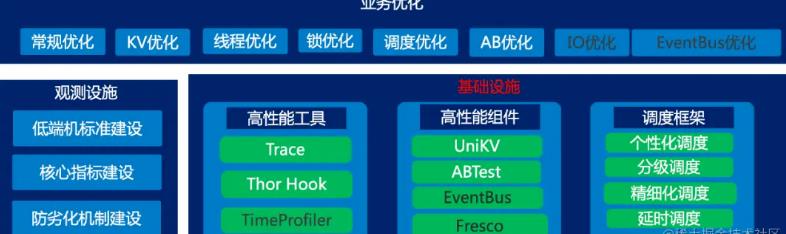
4.4.1 防劣化机制建设
百度的观测设施有三个关键点,第一个关键点是低端机标准建设,上文如何定义低端机已经提供了不错的解决方案。
第二个关键点是核心指标建设,设备类型、Android系统版本号、手机品牌、启动时长、系统平台、app版本号、app名称、闪屏广告阻断次数和设备ID等字是我们常用的上报字段。
第三个关键点是防劣化机制建设,是本文的重中之重。客户端防劣化机制建设主要思考两个方向,第一个方向是线下防劣化。第二个方向是线上防劣化。

线下防劣化
首先我们来说一下线下防劣化,关于线下防劣化主要分为四个部分,第一个部分是打包自动化。第二个部分是测试自动化。第三个部分是分析自动化。第四个部分是分发自动化。

打包自动化,一般中大型的互联网公司都有做,如阿里的摩天轮、美团的MCI和货拉拉的MDAP等等。打包自动化是客户端持续化部署关键一步,通过打包自动化的方式方便我们严控开发版本权限,降低发版风险。
测试自动化,通过Docker镜像实现快速部署和迁移Appium自动化测试框架,执行定制化case实现app在云真机启动过程中进行自动化测试。货拉拉好像也在做这件事,目前云真机平台建设有了基础雏形。
分析自动化,Android端上建议参考字节跳动的btrace。我们可以利用该工具记录事件的CPU执行时间开销,写到本地日志后上传分析平台,这样会更方便排查问题。
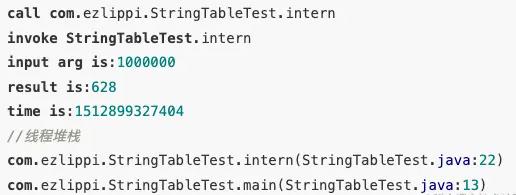
反混淆解析首先可以参考progard的mapping.txt文件,然后再通过retrace.sh -verbose mapping.txt obfuscated_trace.txt 进行反混淆,最后将obfuscated_trace.txt 透传给测试平台进行渲染即可。

分发自动化,首先通过脚本对劣化问题进行去重、置信度过滤,然后通过分发服务进行问题归属定位,最后通过企业办公软件QA机器人分发。
线上防劣化
线上防劣化主要分为两种,第一种是实验防劣化,第二种是函数级防劣化。
实验防劣化
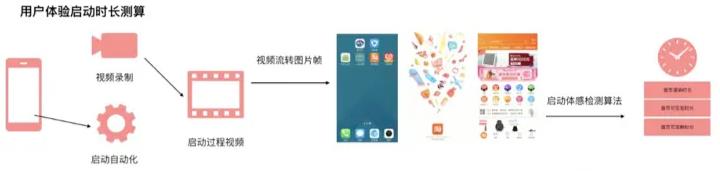
关于实验防劣化,如果云真机测试平台搭建好了,首先可以通过自动化,启动录制视频,然后将视频分帧,通过算法筛选出点击帧和渲染完成帧。最后检测跑多次数据,关注波动曲线和平均值。

函数级防劣化
关于函数防劣化,用的是ASM字节码插桩技术,启动耗时统计目前有两种方法,即线上统计和线下监测,线上统计是指通过分析统计所有手机的耗时情况,求取每个应用的不同启动时间段占比。
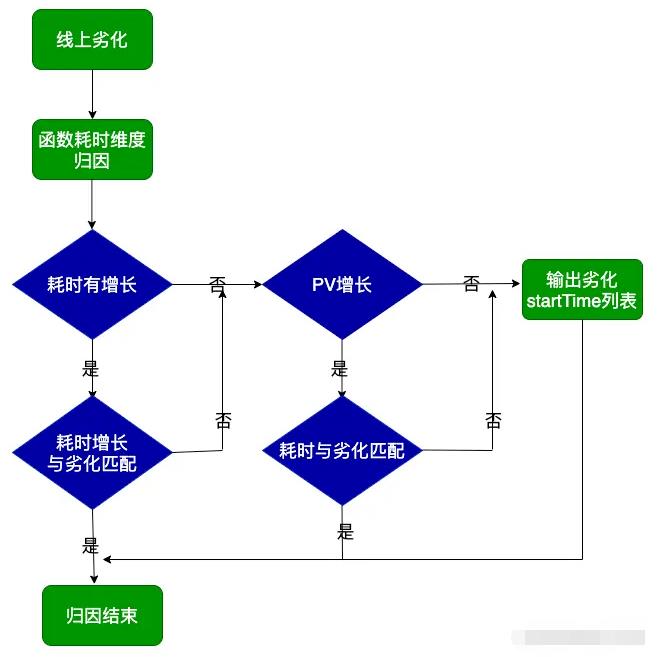
一定程度可以反应每个版本启动耗时情况,可以针对不同版本差异化代码进行优化排查。
线下监测是指利用adb命令或Systrace工具在严格控制的环境下监控应用,该方案存在明显的不足:无法精确到每个函数级别,统计过程会比较复杂,数据也不够直观。
工程编译过程的角度出发,拦截Android构建由Class字节码文件转换成Dex文件的过程,因为每个字节码文件都有来源路径,如果在当前字节码文件内容中能够检测出符合命中策略的指令,我们就可以知道当前的指令所处文件名,调用位置、文件路径,进行插入日志信息,首先我们使用的是自定义注解Anotaton方式处理我们特殊的字节码来源,然后根据来源进行周期性拦截,并统计代码执行周期内耗时信息。
最后,我们给每一个启动执行周期设置一个卡口时间,如果超出卡口时间就证明测试是不通过的。并且输出每一个子函数的耗时长度。
4.4.2 优化思路
关于优化思路,主要有两个方面,第一个方面是SharedPreferences优化,第二个方面是锁优化。
SharedPreferences优化
首先,我们来说一说SharedPreferences优化,为什么要对SharedPreferences进行优化呢?SharedPreferences的缺点很明显,第一明文存储,第二多进程存储数据易丢失,第三效率低,IO读写使用xml数据格式,全量更新效率低。
SharedPreferences存储格式
我们首先来看一下SharedPreferences的数据存储和编码格式,SharedPreferences数据存储和编码格式采用的是Xml,明文存储,可读性强,数据冗余度较高。
<?xml version='1.0' encoding='utf-8' standalone='yes' ?>
<map>
<int name="MicroKibaco" value="小小" />
</map>
SharedPreferences低效读取
SharedPreferences初始化的时候,子线程使用IO读取整个文件,进行XML解析,因为存入内存,SharedPreferences具有Map集合的数据结构特征,在我们每次追加数据更新的时候,只有采用全量更新方式,才能把map中的数据全部序列化为XML,如果文件较大,那么会导致存储效率降低。
SharedPreferences多进程操作
其实SharedPreferences也有支持多进程的模式MODE_MULTI_PROCESS,不过API过时了。

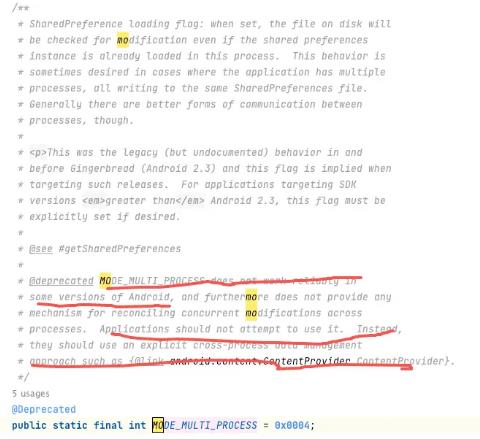
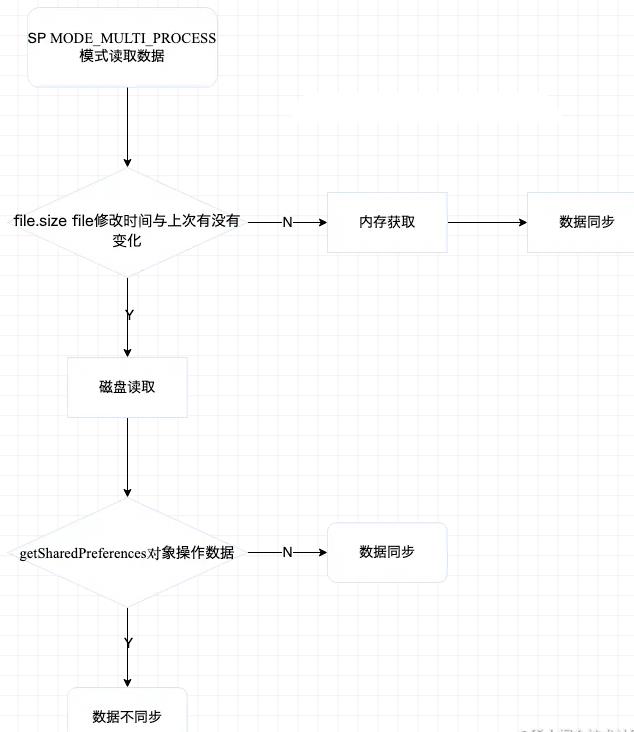
SharedPreferences在MODE_MULTI_PROCESS多进程模式下,读写数据可能出现数据丢失,具体可以参考一下下面的流程图和源码。
class ContextImpl extends Context
@Override
public SharedPreferences getSharedPreferences(File file, int mode)
SharedPreferencesImpl sp;
synchronized (ContextImpl.class)
···
if ((mode & Context.MODE_MULTI_PROCESS) != 0 ||
getApplicationInfo().targetSdkVersion < VERSION_CODES。HONEYCOMB)
//重新去加载磁盘文件
sp.startReloadIfChangedUnexpectedly();
return sp;
Sharepreferences在Andorid 7.0及以上进行多进程读写操作的时候,会抛出异常,因为Sharepreferences不支持多进程模式。多进程共享文件会出现问题的本质在于,不同进程磁盘读写,线程同步会失效。怎么理解呢?
异步提交过程中,如果此刻SharePreference正在IO磁盘文件,但用户退出当前进程,数据没有及时更新文件,提交操作却提前打断,那么数据就丢失。
要解决Sharepreferences数据丢失问题,我们可以采用跨进程方案,如ContentProvider、AIDL、Service。但ContentProvider、AIDL、Service操作文件有点大才小用,我们可以考虑MMKV或DataStore。
SharedPreferences IO磁盘读写
虚拟内存被操作系统划分成两块:用户空间和内核空间,用户空间是用户程序代码运行的地方,内核空间是内核代码运行的地方。为了安全,用户空间和内核空间是隔离的,即使用户的程序崩溃了,内核也不受影响。
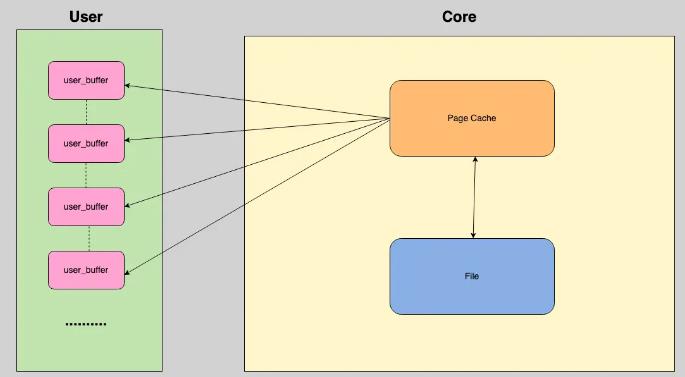
那么, IO读取数据为什么会造成数据不同步呢?以用户修改文件为例,如果是IO读取文件遵循下面的流程,首先调用 write,告诉内核需要写入数据的开始地址与长度,然后内核将数据拷贝到内核缓存,最后由操作系统调用,将数据拷贝到磁盘,完成写入。

如果用户对EditText进行Input输入事件,其他耗时事件导致Input输入事件处于等待状态,时间超过5s,那么会阻塞主线程,导致ANR。经测试发现,SharedPreferences同步更新过程中,大文件读写操作,耗时超过5s很容易出现。因此,为了避免出现ANR,不要使用SharedPreferences进行大文件读写。
MMKV的原理
MMKV的C++层代码比较复杂,从内存准备、数据组织和写入优化三个方面简单的和大家聊一下原理。
内存准备
第一,内存准备方面,通过 mmap 内存映射文件,提供一段可供随时写入的内存块,App 只管往内存写数据,由操作系统负责将内存回写到文件,不必担心 crash 导致数据丢失。
数据组织
第二,数据组织方面,数据序列化方面选用protobuf协议,pb在性能和空间占用上都有不错的表现。
写入优化
第三,写入优化方面,考虑到主要使用场景是频繁地进行写入更新,我们需要有增量更新的能力,我们考虑将增是 kv 对象序列化后,append 到内存末尾。
MMKV之mmap内存读写
因为SharedPreferences有不够精简的xml数据格式、操作文件耗时长、阻塞主线程易出现数据丢失和不支持增量更新弊端,所以有没有SharedPreferences的备胎方案呢?
有! 腾讯的MMKV, MMKV有四大优点,第一是mmap内存映射,读写快,操作内存相当于操作文件,不必担心crash导致数据存储失败。第二是采用protobuf数据格式,性能和大小更有优势。第三是写入优化,增量更新,大小不足时进行扩容。第四是支持多进程模式。首先说一下第一部分内容mmap,mmap有四个问题需要聊一下。
问题一: mmap是什么?
Linux 通过将一个虚拟内存区域与一个磁盘上的对象关联起来,以初始化这个虚拟内存区域的内容,这个过程称为内存映射(memory mapping)。
对文件进行 mmap,会在进程的虚拟内存分配地址空间,创建映射关系。实现这样的映射关系后,就可以采用指针的方式读写操作这一段内存,而系统会自动回写到对应的文件磁盘上。
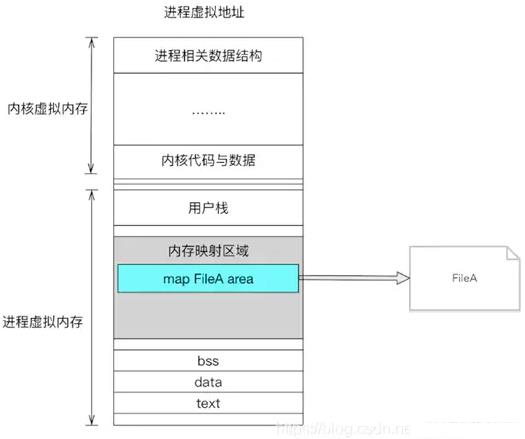
问题二: mmap相对于IO磁盘读写有什么优点?
第一,mmap 对文件的读写操作只需要从磁盘到用户主存的一次数据拷贝过程,减少了数据的拷贝次数,提高了文件读写效率,mmap读写操作可以看一下下面的图。
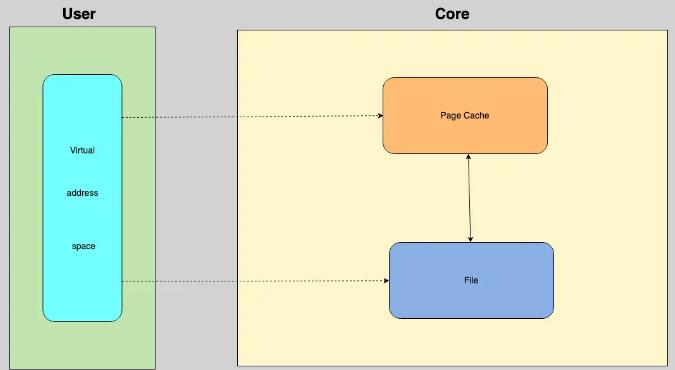
第二,mmap 使用逻辑内存对磁盘文件进行映射,操作内存就相当于操作文件,不需要开启线程,操作 mmap的速度和操作内存的速度一样快
第三,mmap 提供一段可供随时写入的内存块,App 只管往里面写数据,由操作系统如内存不足、进程退出等时候负责将内存回写到文件,不必担心 crash 导致数据丢失
下面来对比一下SharedPreferences 和 MMKV同时存储1000条数据的耗时:
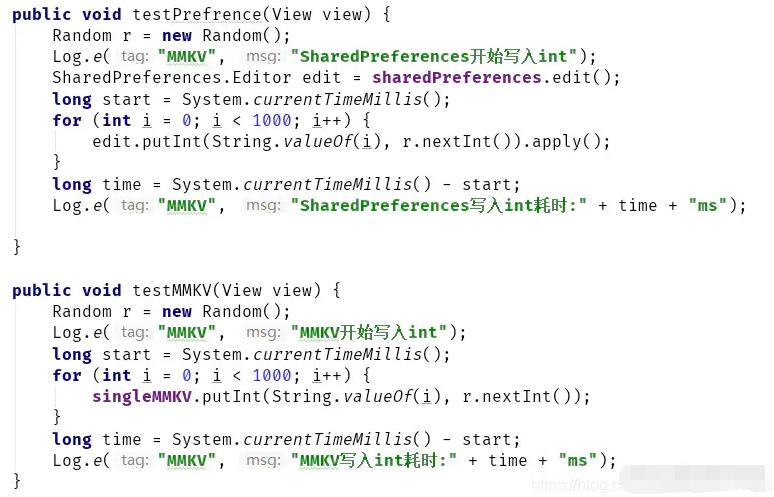

因为MMKV和SharedPreferences都是从map里面读数据,所以读取速度相差不大。因为mmap内存写文件0次拷贝,SharedPreferences IO磁盘写文件多次拷贝,所以MMKV的写入速度优于SharedPreferences。
问题三: mmap映射的内存到磁盘的时机是什么时候?
mmap映射的内存到磁盘的时机有四个,第一个是主动调用msync,第二个是mmap解除映射,第三个是进程退出,第四个是系统关机。
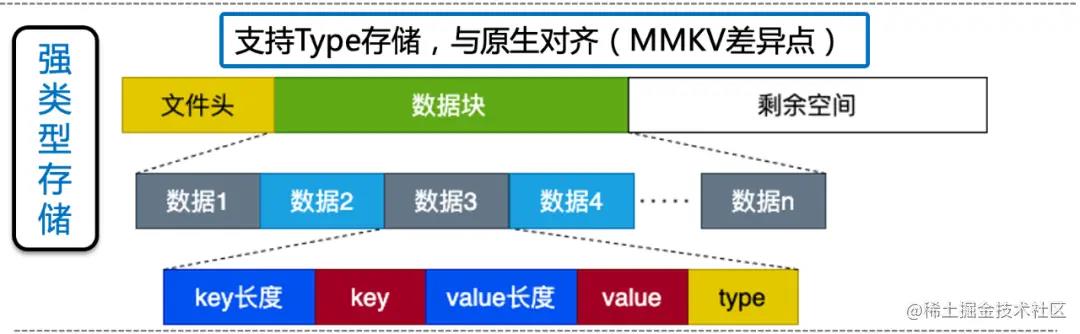
MMKV数据存储和编码格式
数据存储和编码格式方面,mmkv采用protobuf,protobuf数据紧凑,非明文存储。protobuf底层是基于二进制保存的,保存文件非常小,解析速度更快! protobuf相比XML、JSON、Lua有如下优势:
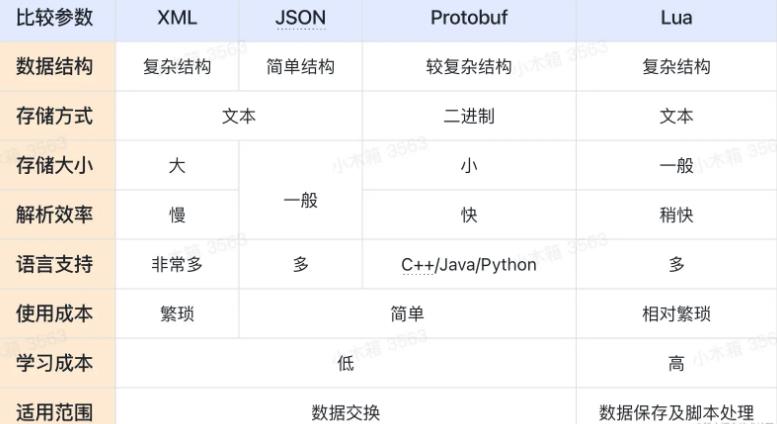
protobuf数据结构
protobuf底层是基于二进制保存的,保存文件非常小,解析速度更快!
MMKV 默认把文件存放在 $(FilesDir)/mmkv/ 目录, 我们用010Editor看到protobuf映射文件二进制存储格式如下:

前4个字节表示整个protobuf映射文件中数据的有效长度。那么为什么需要有效长度?
其实,因为mmap内存映射的时候,文件大小必须是4096(这个数字与与操作系统位数有关)或者其整数倍,所以并非整个文件内容都是有效数据,需要用有效数据长度来标明有效数据。
从第五个字节开始,依次为k1长-->k1值-->v1长-->v1值-->k2长->k2值-->v2长-->V2值...>v2值-->
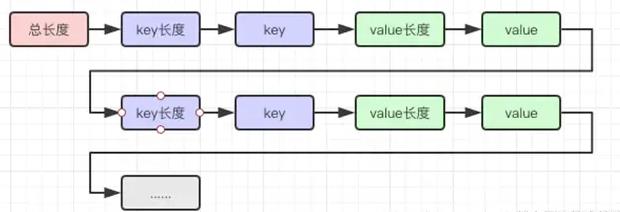
那么问题来了,protobuf是怎么做到数据紧凑的呢?我们来了解一下protobuf的解码规则:
protobuf解码规则
我们以整型数据来说明,每一个字节的首位作标志位,标志位为1,则表示该字节无法完整表示数据,需要更多的字节;标志位为0,则表示该字节已经是表示该数据的最后一个字节,该数据的的读取到该字节为止。每一个字节的后七位保存数据。
<=0x7f的10进制表示为127,2进制表示为0111111111。如果写入的数据<=0x7f,那么一个字节的七个数据位足够表示这个数据,则字节首位置0,后七位写入数据。
如果写入的数据>0x7,那么一个字节的七个数据位不足以表示这个数据,则字节首位置11后七位写入数据,并将原数右移7位,继续执行判断。
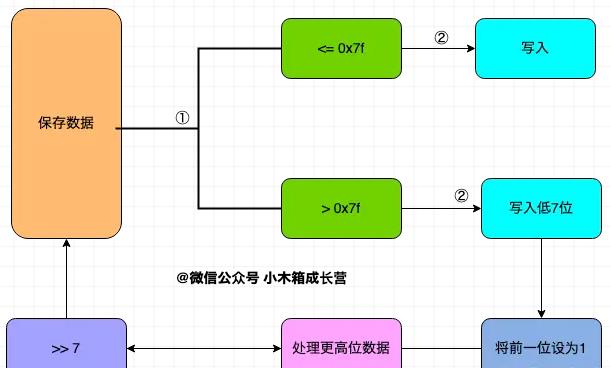
protobuf解码案例分析
编码128, 即10000000

读取128的protobuf编码, 即1000 000000000 000

编码318242,即00000100110110110010 0010
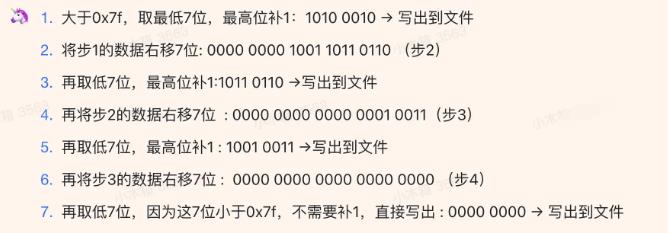
318242的protobuf解码
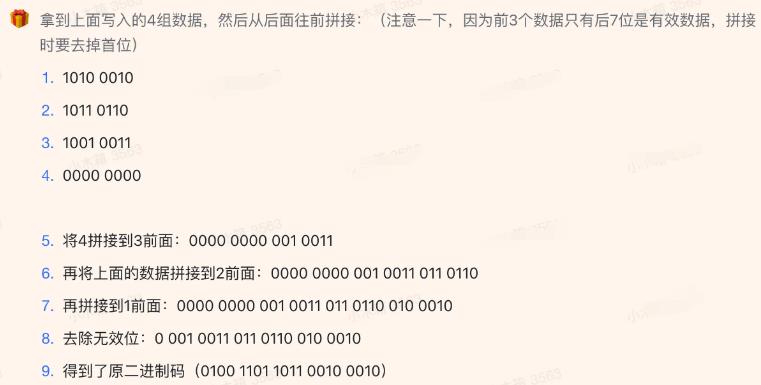
综上所述,普通方式存储是定长的,而protobuf存储方式是变长的。所以,在多数情况下,protobuf的存储方式,会使得数据更小。protobuf的数据格式特征解释了为什么MMKV比SharedPreferences的性能和大小更有优势。
MMKV增量修改
好了,介绍完了MMKV数据在文件中的存储结构,这种结构如何实现增量修改的呢?
原因是MMKV在内存中是一个map表结构。
完成首次mmap映射系的建立后,之后再次写入一个同名key的键值对,该键值对直接存储在映射文件的末尾,并修改有效长度。
当映射关系断开后重新建立映射关系的时候,旧的键值对先写入map表,新的键值对后读入,将会覆盖掉旧的键值对,也就实现了增量修改。
MMKV是在末尾追加新数据,重复数据不进行覆盖,当要发生扩容时进行数据重整。
MMKV多进程操作
Linux中多进程锁通常考虑pthread_mutex,创建于共享内存的 pthread_mutex 是可以用作进程锁的。
但是Android版本的健壮性不足,进程被kill时并不会释放锁,导致其他进程一直阻塞。
所以mmkv采用的是文件锁进行多进程同步,但是文件锁存在两个问题:
第一个问题是不支持递归加锁:因为文件锁是状态锁,没有计数器,无论加了多少次锁,一个解锁操作就全解掉。只要用到子函数,就非常需要递归锁。
第二个问题是不支持读写锁升级/降级:读锁升级为写锁,写锁可以降级为读锁。对于读锁,我们允许多进程访问,写锁则不允许多进程访问。所以mmkv增加了读写计数器以此支持这个功能,增加CRC文件校验。
具体逻辑:
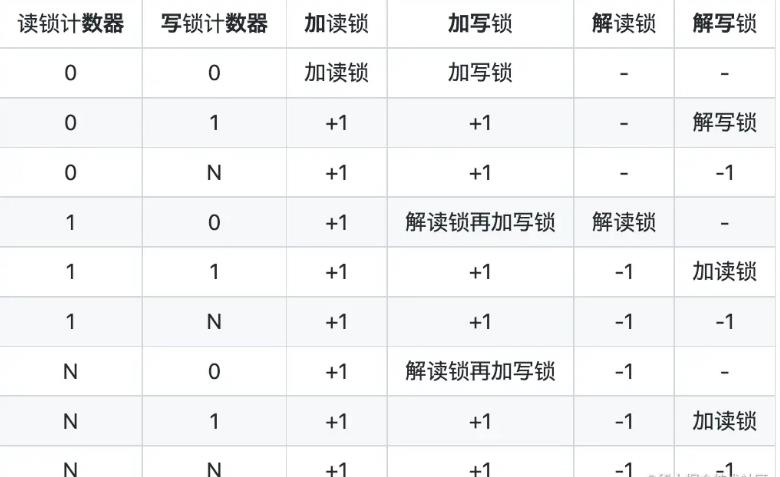
-
保证每一个文件存储的数据都比较小,也就说需要把数据根据业务线存储分散。内存消耗不会过快,数据不用了可以进行释放。
-
还需要在内存不足的时候释放一部分内存数据,比如在App中监听onTrimMemory方法,在Java内存吃紧的情况下进行MMKV的trim操作。
-
在不需要使用的时候,最好把MMKV给close掉。
MMKV与SharedPreferences优缺点比较
写了这么多,首先简单的总结一下SharedPreferences和MMKV的存储格式、优点和缺点。最后再通过实验分析验证一下结论。

MMKV与SharedPreferences性能测试
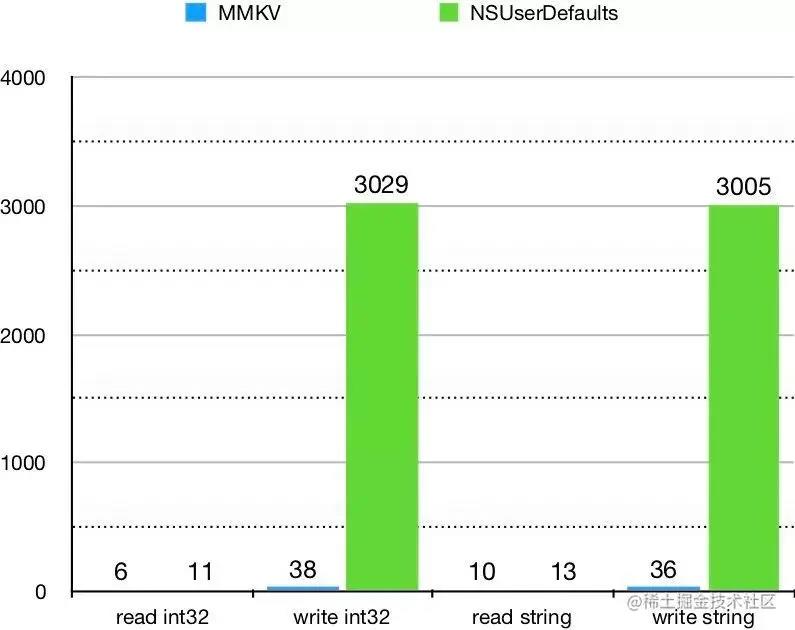
下面进入我们的MMKV与SharedPreferences性能测试环节。读写性能方面,无论是ios还是android上,MMKV的表现均优于SharedPreferences。iOS的MMKV 和 NSUserDefaults 进行对比,重复读写操作 1w 次。性能比较数据如下:
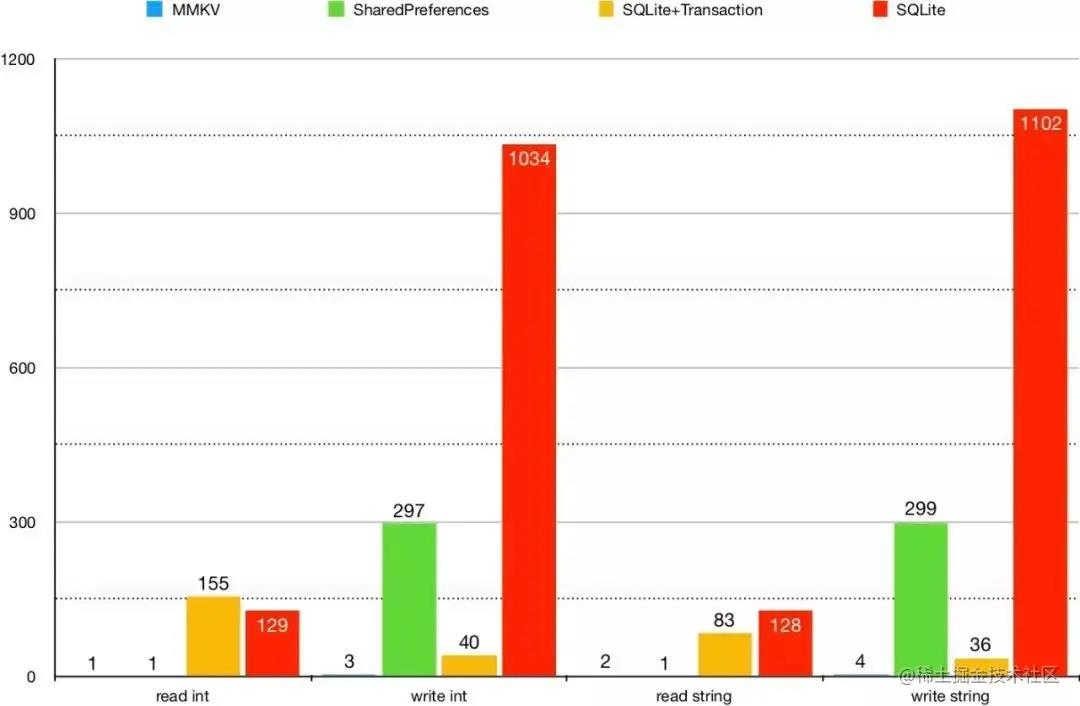
Android,MMKV 和 SharedPreferences、SQLite 进行对比, 重复读写操作 1k 次。结果如下图表。
Android,MMKV 和 SharedPreferences、SQLite 进行对比, 多进程操作性能如下图表。
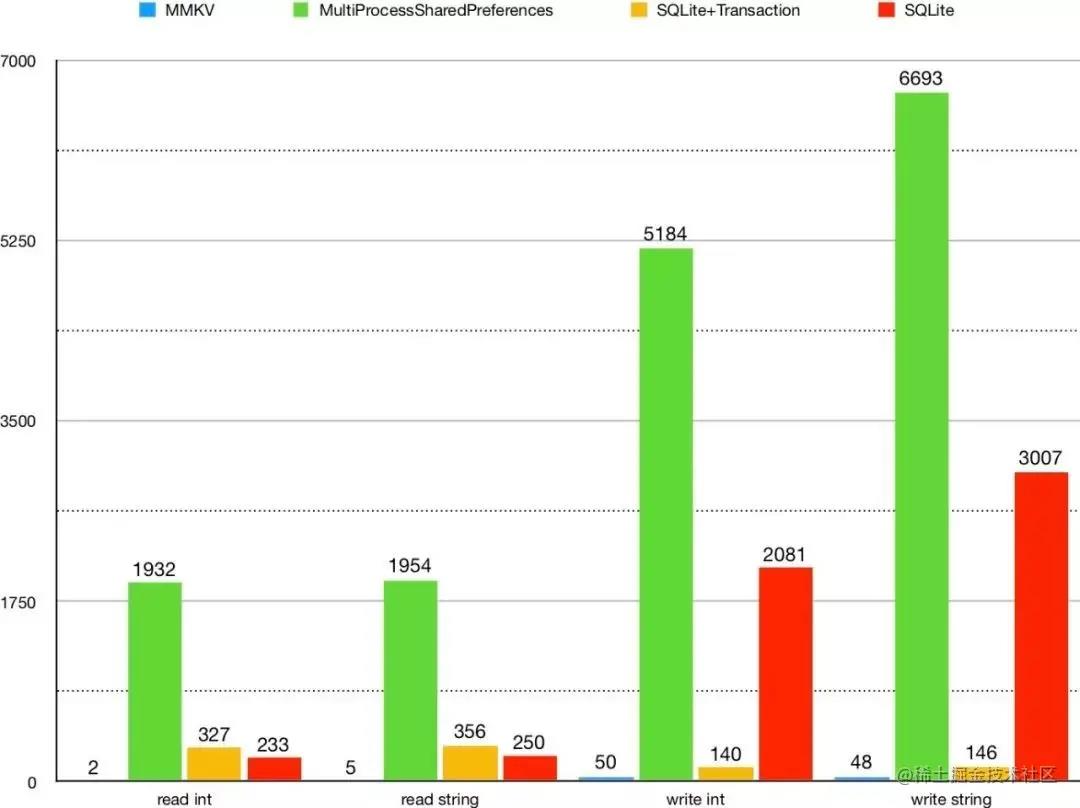
MMKV 无论是在写入性能还是在读取性能,都远远超越 MultiProcessSharedPreferences & SQLite & SQLite, 基于SharedPreference以上缺陷,团队要放弃SharedPreferences使用。
MMKV二次开发与迭代
尽管MMKV已经足够优秀,但是美中不足是不支持强类型、和SharedPreferences接口无法对齐,国内能兼顾这两个优势的数据存储模型的只有Booster和UniKV。但相比MMKV,Booster有点相形见绌了,因为Booster不支持多进程而且线程优化个数表现不佳。在 百度App 低端机优化-启动性能优化(概述篇)一文中,UniKV,突破系统限制,彻底解决原生 SharedPreferences 有首次读取性能差、创建线程多、卡顿/ANR、多进程支持差等缺点,实现流程图大概如下:
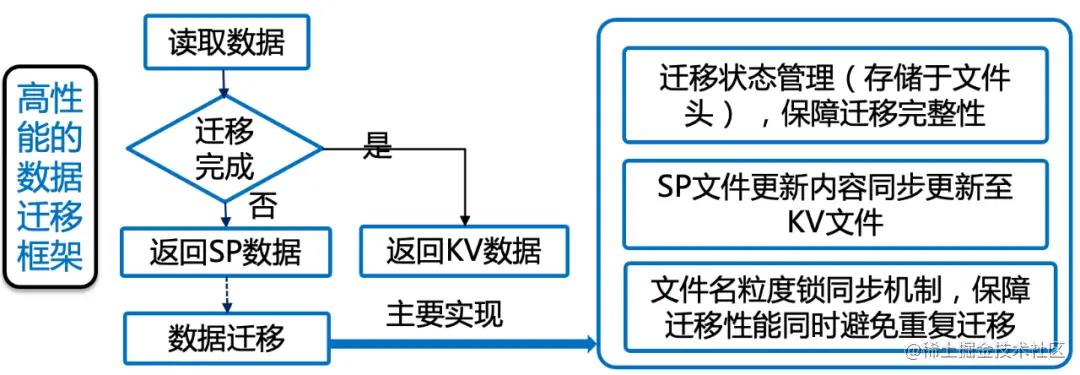
UniKV是闭源的,从SDK研发到落地上线,百度应该踩了不少坑,未来希望可以开发一套方便从MMKV切换到SharedPreferences的开源工具,SharedPreferences0风险替换MMKV。因为篇幅有限,关于MMKV的改造提效,可以参考后续文章 架构优化· 框架论 · 什么! 从SharedPreferences过渡MMKV,线上崩溃率提高3%?
锁优化
说完SharedPreferences优化,我们进入优化思路的第二个环节锁优化, 学习锁优化之前,简单的和大家过一下Java的主流锁。
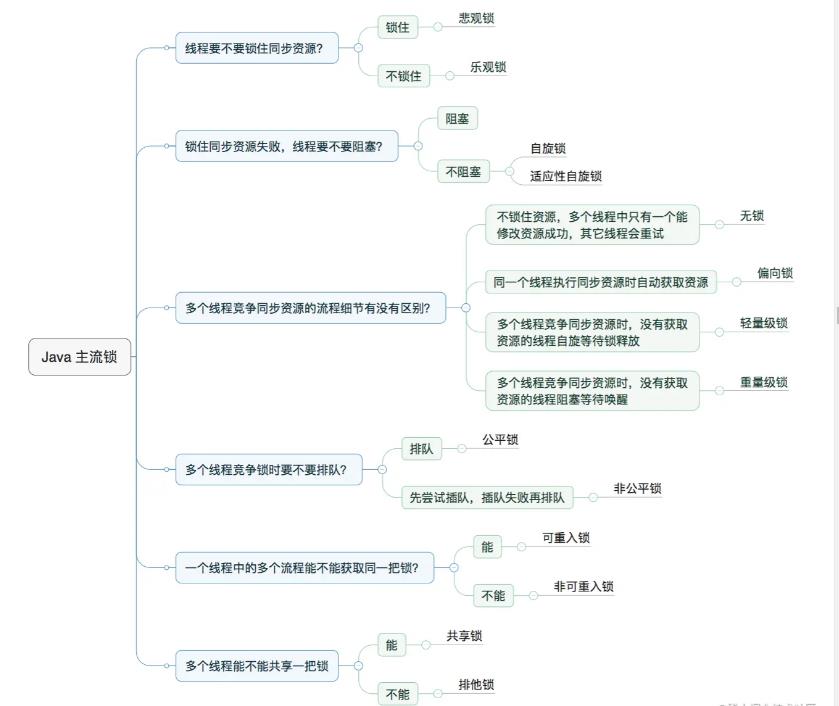
Java主流锁
Java的主流锁一共有六个问题需要搞清楚,搞清楚这6个问题,Java主流锁基础知识掌握的也差不多了。
问题一: 线程要不要锁住同步资源?
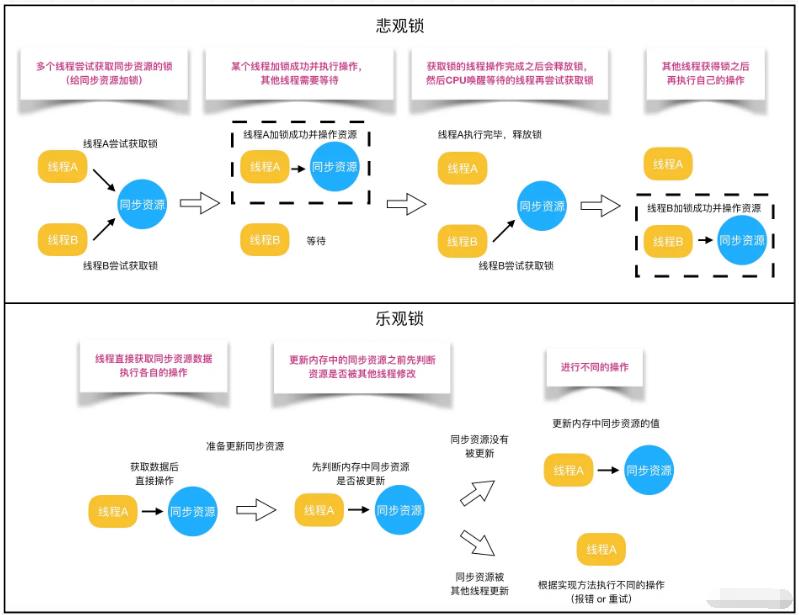
从线程是否需要同步角度出发,我们把锁分为两种。第一种是悲观锁,第二种是乐观锁。synchronized、Lock实现类都是悲观锁,作用在于其他线程访问数据的时候,保护数据不会被其他线程修改。很好理解这个概念,只有患得患失,才给自己数据设置修改权限。患得患失的锁普遍悲观。
乐观锁就不一样了,乐观锁比较开放,唯我独尊,认为没人敢乱动自己的数据,所以从不给自己的数据加锁。
只是别的线程访问自己的数据的时候,判断一下有没有偷偷更新自己的数据,如果数据没有被更新,那么当前线程将自己修改的数据成功写入。
如果数据已经被别的线程更新,那么根据不同的实现方式执行抛出异常或者自动重试操作。
那么乐观锁在Java中是怎样实现的呢?
AtomicBoolean等原子类中的递增操作通过CAS自旋实现的。而乐观锁在Java中也是基于类似CAS算法等方式来实现
能不能都用悲观锁保证数据正确性呢?
其实是不建议的,我们都知道如果加锁会使读操作的性能大幅下降。那么什么时候不需要加锁呢?
当然是在不更改数据的场景下啦,比如: 批量读文件、批量删除文件等等。这也是乐观锁适合的场景。
悲观锁相反,加锁可以保证写操作时数据正确,因此,悲观锁适合写操作多的场景。
悲观锁和乐观锁在Java编程中调用方式是怎样的呢?
// ------------------------- 悲观锁的调用方式 -------------------------
// synchronized
public synchronized void testMethod()
// 操作同步资源
// ReentrantLock
private ReentrantLock lock = new ReentrantLock(); // 需要保证多个线程使用的是同一个锁
public void modifyPublicResources()
lock.lock();
// 操作同步资源
lock.unlock();
// ------------------------- 乐观锁的调用方式 -------------------------
private AtomicInteger atomicInteger = new AtomicInteger(); // 需要保证多个线程使用的是同一个AtomicInteger
atomicInteger.incrementAndGet(); //执行自增1
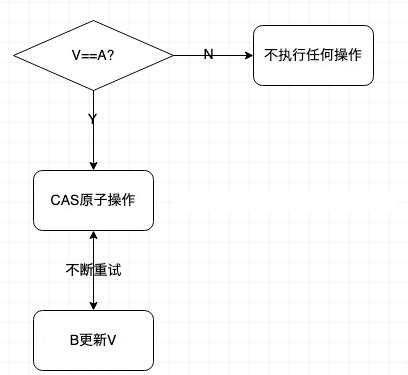
为什么乐观锁能够做到不锁定同步资源也可以正确的实现线程同步呢?
主要是通过CAS方式实现的,是一种无锁算法。在没有线程被阻塞的情况下实现多线程之间的变量同步。JUC包中的原子类就是通过CAS来实现了乐观锁。

public class AtomicInteger extends Number implements java.io.Serializable
private static final long serialVersionUID = 6214790243416807050L;
// unsafe: 获取并操作内存的数据。
private static final Unsafe U = Unsafe.getUnsafe();
// VALUE: 存储value在AtomicInteger中的偏移量。
private static final long VALUE;
// value: 存储AtomicInteger的int值,该属性需要借助volatile关键字保证其在线程间是可见的。
private volatile int value;
static
try
VALUE = U.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
catch (ReflectiveOperationException e)
throw new Error(e);
// ------------------------- JDK 8 -------------------------
// AtomicInteger 自增方法
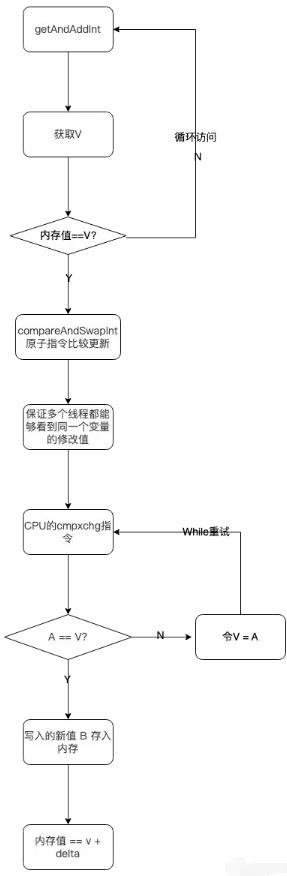
public final int incrementAndGet()
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
// Unsafe。class
public final int getAndAddInt(Object var1, long var2, int var4)
int var5;
do
var5 = this.getIntVolatile(var1, var2);
while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
// ------------------------- OpenJDK 8 -------------------------
// Unsafe。java
public final int getAndAddInt(Object o, long offset, int delta)
int v;
do
v = getIntVolatile(o, offset);
while (!compareAndSwapInt(o, offset, v, v + delta));
return v;

CAS虽然很高效,但是CAS有三大缺陷:
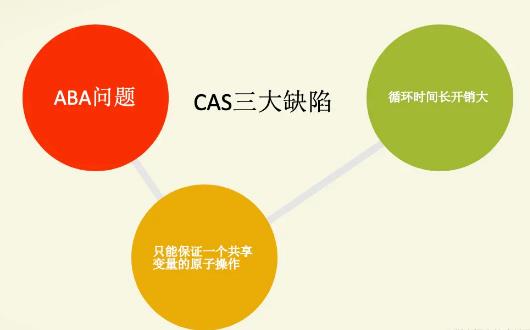
- 缺陷一: ABA问题。CAS需要在操作值的时候检查内存值是否发生变化,没有发生变化才会更新内存值。但是如果内存值原来是A,后来变成了B,然后又变成了A,那么CAS进行检查时会发现值没有发生变化,但是实际上是有变化的。ABA问题的解决思路就是在变量前面添加版本号,每次变量更新的时候都把版本号加一,这样变化过程就从“A-B-A”变成了“1A-2B-3A”。
- JDK从1.5开始提供了AtomicStampedReference类来解决ABA问题,具体操作封装在compareAndSet()中。compareAndSet()首先检查当前引用和当前标志与预期引用和预期标志是否相等,如果都相等,则以原子方式将引用值和标志的值设置为给定的更新值。
缺陷二: 循环时间长开销大。CAS操作如果长时间不成功,会导致其一直自旋,给CPU带来非常大的开销。
- 缺陷三: 只能保证一个共享变量的原子操作。对一个共享变量执行操作时,CAS能
以上是关于浅析Android启动优化的主要内容,如果未能解决你的问题,请参考以下文章