mybatis的collection查询问题以及使用原生解决方案的结果
Posted DGUT_FLY
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mybatis的collection查询问题以及使用原生解决方案的结果相关的知识,希望对你有一定的参考价值。
之前在springboot+mybatis环境的坑和sql语句简化技巧的第2点提到,数据库的一对多查询可以一次查询多级数据,并且把拿到的数据按id聚合,使父级表和子级表都有数据。
但是这种查询,必然要查询大量的重复父数据,如果不用这种方法,而是分级查询,效果会如何?
要知道这2种数据的查询效率如何,用Python可以简单查询到总时长。
首先用pip install mysql-python这条指令安装,至于出错解决方法就是https://www.cnblogs.com/superxuezhazha/p/6619036.html这篇文章的事了。
上代码:


import MySQLdb import json import uuid import random import traceback import time plan_id = \'assssss\' use_times = 0 def noSubUuid(namespace=None): global use_times if namespace == None: use_times = use_times + 1 return str(uuid.uuid3(uuid.NAMESPACE_DNS,str(use_times))).replace(\'-\',\'\') else: return str(uuid.uuid3(uuid.NAMESPACE_DNS,namespace)).replace(\'-\',\'\') # Add Sample Data.生成示例数据 def addData(cursor, db): try: start = 18 user_ids = [] user_number_id = 490 for _ in range(600): user_id = noSubUuid() insertUserSql = \'insert into user VALUES (%d,\\\'%s\\\',\\\'%s\\\',\\\'YWRtaW4=\\\',\\\'%s\\\',2,0,1,NULL,NULL,NULL,\\\'2018-08-21 07:20:13\\\',NULL,NULL,NULL,\\\'my_ass_bdpf\\\',\\\'MXQ2NWRhNDNXNmM0OWQ1dG9rZW5fc2FsdA==\\\',\\\'2bbf024395e84adf80e2e72c6330ea57\\\')\'%(user_number_id,user_id,noSubUuid()[20:],noSubUuid()) print(insertUserSql) cursor.execute(insertUserSql) user_ids.append(user_id) user_number_id = user_number_id+1 line_id = 490 man_num_id = 490 study_num_id = 590 limitNum = 450 for _ in range(400): start = 0 manage_id = noSubUuid() insertLineSql = \'insert into experiment_teaching_plan_resource_line values (%d,\\\'%s\\\',\\\'%s\\\',\\\'%s\\\')\'%(line_id,noSubUuid(),plan_id,manage_id) print(insertLineSql) cursor.execute(insertLineSql) line_id = line_id + 1 insertManaSql = \'insert into resource_management values (%d,\\\'%s\\\',\\\'%s\\\',\\\'%s\\\',\\\'%s\\\',\\\'%s\\\',\\\'%s\\\',\\\'20180109000000\\\',\\\'my_ass_bdpf\\\',4)\'%(man_num_id,noSubUuid(),noSubUuid(),noSubUuid(),manage_id,noSubUuid(),noSubUuid()) print(insertManaSql) man_num_id = man_num_id + 1 cursor.execute(insertManaSql) for user_id in user_ids: if(start >= limitNum): return if(random.randint(0, 2) == 1): insertStudSql = \'insert into course_resource_study values (%d,\\\'%s\\\',\\\'%s\\\',\\\'%s\\\',null,null,null)\'%(study_num_id,noSubUuid(),manage_id,noSubUuid()) print(insertStudSql) cursor.execute(insertStudSql) study_num_id = study_num_id + 1 start = start + 1 # db.commit() except Exception as e: print(traceback.format_exc()) db.rollback() # Rollback Sample Data.如果数据量过大对服务器造成影响,可以回滚示例数据 def rollbackData(cursor, db): try: cursor.execute(\'delete from course_resource_study where student_id in (select uid from user where user_col3 = \\\'my_ass_bdpf\\\')\') cursor.execute(\'delete from user where user_col3 = \\\'my_ass_bdpf\\\'\') cursor.execute(\'delete from experiment_teaching_plan_resource_line where resource_management_id in (select rm.resource_management_id COLLATE utf8_general_ci from resource_management rm where experimental_time = \\\'my_ass_bdpf\\\')\') cursor.execute(\'delete from resource_management where experimental_time = \\\'my_ass_bdpf\\\'\') db.commit() except Exception as e: print(traceback.format_exc()) db.rollback() # Query data like mybatis collection query.像Mybatis的collection查询一样查询数据 def SelectAtOnce(cursor, db): sql = \'select etp.*,rm.*,crs.* \'\\ + \'from experiment_teaching_plan etp \'\\ + \'JOIN experiment_teaching_plan_resource_line etpl ON etp.id=etpl.teaching_plan_id \'\\ + \'JOIN resource_management rm ON rm.resource_management_id=etpl.resource_management_id COLLATE utf8_general_ci \'\\ + \'JOIN course_resource_study crs ON rm.resource_management_id=crs.resource_management_id \'\\ + \'where etp.id=\\\'assssss\\\'\' cnt = cursor.execute(sql) # Query data step by step.分级查询数据 def SelectByStep(cursor, db): cursor.execute(\'select * from experiment_teaching_plan where id=\\\'assssss\\\'\') results = cursor.fetchall() plan_id = results[0][0] cursor.execute(\'select * from experiment_teaching_plan_resource_line where teaching_plan_id=\\\'%s\\\'\'%(plan_id,)) ids = \',\'.join(list(map(lambda a:"\'" + a[3] + "\'",cursor.fetchall()))) cursor.execute(\'select * from resource_management where resource_management_id in (%s)\'%ids) ids = \',\'.join(list(map(lambda a:"\'" + a[4] + "\'",cursor.fetchall()))) cursor.execute(\'select * from course_resource_study where resource_management_id in (%s)\'%ids) # if __name__ == \'__main__\': db = MySQLdb.connect("localhost", "root", "acmicpc", "my_ass_bdpf", charset=\'utf8\') cursor = db.cursor() addData(cursor, db) #rollbackData(cursor, db) start = time.time() SelectAtOnce(cursor, db) mid = time.time() print(mid - start) SelectByStep(cursor, db) print(time.time() - mid) cursor.close() db.close() #
mysql代码:
DROP TABLE IF EXISTS `resource_management`; CREATE TABLE `resource_management` ( `id` int(10) NOT NULL AUTO_INCREMENT COMMENT \'自增ID\', `course_structure_id` varchar(255) COLLATE utf8_unicode_ci NOT NULL COMMENT \'课程体系ID\', `course_classification_id` varchar(255) COLLATE utf8_unicode_ci NOT NULL COMMENT \'课程分类ID\', `course_content_id` varchar(32) COLLATE utf8_unicode_ci NOT NULL COMMENT \'课程内容ID\', `resource_management_id` varchar(32) COLLATE utf8_unicode_ci NOT NULL COMMENT \'实验主键ID\', `resource_management_name` varchar(100) COLLATE utf8_unicode_ci NOT NULL COMMENT \'实验名称\', `resource_management_desc` varchar(200) COLLATE utf8_unicode_ci DEFAULT NULL COMMENT \'描述\', `create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\', `experimental_time` varchar(255) COLLATE utf8_unicode_ci NOT NULL COMMENT \'实验时长\', `resource_order` int(255) NOT NULL COMMENT \'文档顺序\', PRIMARY KEY (`id`), UNIQUE KEY `UNIQUE_VIDEONAME` (`resource_management_name`,`course_content_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ci COMMENT=\'实验基本信息表\'; # # Data for table "experiment_teaching_plan" # INSERT INTO `experiment_teaching_plan` VALUES (\'27421b344b7242a980e139dd3c25f11e\',\'5b3fb1014c62492cb2193686bdf90d45\',\'ass\',\'assss\',\'2019-01-10 16:22:27\'),(\'assssss\',\'27adf7cee44347b4847943c1548887c4\',\'my_test\',\'my_test\',\'2019-04-05 11:23:42\'),(\'ferhh\',\'gfjtjtjtr\',\'在哪?\',\'deswrtyuio\',\'0000-00-00 00:00:00\'); DROP TABLE IF EXISTS `experiment_teaching_plan_resource_line`; CREATE TABLE `experiment_teaching_plan_resource_line` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT \'自增ID\', `resource_line_id` varchar(32) NOT NULL COMMENT \'中间表ID\', `teaching_plan_id` varchar(32) NOT NULL COMMENT \'课程教学计划表主键ID\', `resource_management_id` varchar(32) NOT NULL COMMENT \'课程资源表主键ID\', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT=\'课程教学计划和资料库关联\'; DROP TABLE IF EXISTS `course_resource_study`; CREATE TABLE `course_resource_study` ( `id` int(11) NOT NULL AUTO_INCREMENT, `student_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL COMMENT \'学生ID\', `resource_management_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL COMMENT \'实验ID\', `course_content_id` varchar(32) CHARACTER SET utf8 COLLATE utf8_unicode_ci NOT NULL COMMENT \'实验内容ID\', `experiment_summary` longtext COMMENT \'实验总结\', `create_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT \'创建时间\', `update_time` timestamp NULL DEFAULT NULL COMMENT \'更新时间\', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT=\'学生实验学习关系表\';
写好之后把这段mysql代码在mysql服务器上运行,之后用这段python代码查询。
结果如下:
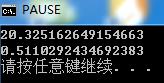
可以看到,包含大量重复父级数据的查询(这次数据量有80104条)会严重影响查询效率,如果数据量再大一些,或者查询级数再深一些,可能就会彻底堵死整个http请求,使某个客户端得不到回应。
如果考虑到mybatis的collection查询比分级查询快的情况,数据量事实上小得不值一提了(这个例子有80000条数据,稍微有点用的网站储存的数据可能都不止一点)
所以Mybatis的这种collection查询功能不是特别推荐(应该说凡是大数据量的系统都不应该用这种查询),分开查代码会麻烦一些,但是后期数据量上来的话性能占优。
以上是关于mybatis的collection查询问题以及使用原生解决方案的结果的主要内容,如果未能解决你的问题,请参考以下文章