Spark- JdbcRDD以及注意事项
Posted RZ_Lee
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark- JdbcRDD以及注意事项相关的知识,希望对你有一定的参考价值。
先上Demo
package com.rz.spark.base import java.sql.DriverManager import org.apache.spark.rdd.JdbcRDD import org.apache.spark.{SparkConf, SparkContext} object JdbcRDDDemo { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName(this.getClass.getSimpleName).setMaster("local[2]") val sc = new SparkContext(conf) val getConn=()=>{ DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=utf-8","root","root") } // 创建RDD,这个RDD会记录以后从MySQL中读取数据 val jdbcRDD: JdbcRDD[(Int, String, Int)] = new JdbcRDD(sc, getConn, "select * from logs where id >= ? and id <= ?", 1, 5, 2, //分区数量 rs => { val id = rs.getInt(1) val name = rs.getString(2) val age = rs.getInt(3) (id, name, age) //将数据库查询出来的数据集转成想要的数据格式 } ) val rs = jdbcRDD.collect() print(rs.toBuffer) } }
返回查询结果正确

现象
修改查询的SQL,返回的数据量不对。
"select * from logs where id >= ? and id < ?"
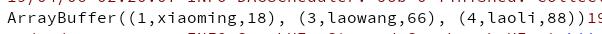
原因
在触发Action的时候,Task在每个分区上的业务逻辑是相同的(id >= ? and id < ?"),只是读取的数据和处理的数据不一样。RDD根据数据量和分区数据,均匀地分配每个分区Task读取数据的范围。
分区1读取[1,2)的数据,分区2读取[3,5)的数据。
使用相同的逻辑分区1丢掉了id=2的数据,这是为什么,id >= 1 and id < 5"只返回3条数据的原因,如果只有一个分区的时候能够读取到正确的数据量。
解决办法
为了避免出现丢数据,读取数据时,区间两端都包含。id >= 1 and id < =5。
以上是关于Spark- JdbcRDD以及注意事项的主要内容,如果未能解决你的问题,请参考以下文章
spark2.x由浅入深深到底系列六之RDD java api用JdbcRDD读取关系型数据库
spark关于join后有重复列的问题(org.apache.spark.sql.AnalysisException: Reference '*' is ambiguous)(代码片段