多类别分类任务(multi-class)中为何precision,recall和F1相等?
Posted JasonLiu1919
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多类别分类任务(multi-class)中为何precision,recall和F1相等?相关的知识,希望对你有一定的参考价值。
文章目录
更多、更及时内容欢迎微信公众号:小窗幽记机器学习 围观。
背景:
在 multi-class 分类任务中,如果使用 micro 类指标,那么 micro-precision, micro-recall和micro-F1值都是相等的。本文主要针对这个现象进行解释。
precision, recall和F1 score的定义
true positive(TP): 真实 positive,预测 positive
False positive(FP): 真实 negative,预测 positive
false negative(FN): 真实 positive,预测 negative
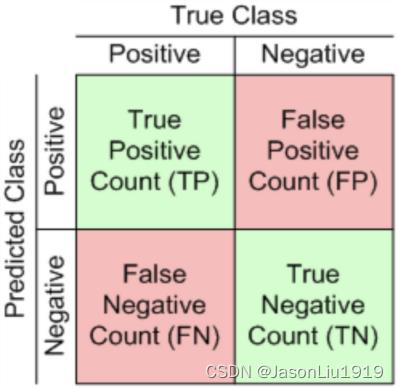
Precision 计算如下:
P
=
T
P
T
P
+
F
P
P = \\fracTPTP+FP
P=TP+FPTP
精确度可以直观地理解为分类器只将真正positive样本预测为正的能力。比如,在类别平衡的测试集(50%是positive的,50%是negative的)中,一个分类器将所有样本都分类为positive,那么该分类器的精确度为0.5。如果没有假阳性(false positives),即只将true positives 归为positives,则精确度为1.0。所以基本上,分类器给出的假阳性(false positives)越少,它的精度就越高。
Recall 计算如下:
R
=
T
P
T
P
+
F
N
R = \\fracTPTP+FN
R=TP+FNTP
召回可以理解为真正为positive测试样品的数量中实际被分类为positive的占比。如果一个分类器对每个样本都识别为positive ,而不管它是否真的是positive,那么该分类器的recall是1.0,但精度较低。
因此,精确度和召回率越高,分类器的性能就越好,因为它能检测到大部分的positive 样本(即高召回率), 而不检测到许多不应该检测到的样本(即高精度)。为了量化这一点,可以使用另一个称为F1评分的度量指标。
F1 score 计算如下:
F
1
=
2
P
∗
R
P
+
R
F1 = 2 \\fracP * RP + R
F1=2P+RP∗R
F1 score 是精确度和召回率之间的调和平均数。精度和召回率越高,F1得分越高。从该式子可以看出,如果
P
=
R
P=R
P=R,那么
F
1
=
P
=
R
F1=P=R
F1=P=R:
F
1
=
2
P
∗
R
P
+
R
=
2
P
∗
P
P
+
P
=
2
P
2
2
P
=
P
2
P
=
P
F1 = 2 \\fracP * RP + R = 2 \\fracP * PP + P = 2 \\fracP^22P = \\fracP^2P = P
F1=2P+RP∗R=2P+PP∗P=22PP2=PP2=P
所以这解释了如果精确度和召回率是一样,F1分数和精确度和召回率是一样。那为什么在multi-class任务中使用micro平均时, recall和 precision是一样的?下面具体举个实例说明。
micro averaging的计算及其示例
在multi-class任务中计算precision 和 recall,需要知道TP, FP和FN样本的数量。假设有3个类(1,2,3),每个样本恰好属于一个类,即multi-class任务。下表显示分类器对9个测试样本的预测以及它们的正确标签。
Label 1 2 3 2 3 3 1 2 2
Prediction 2 2 1 2 1 3 2 3 2

TP 是被预测有正确标签的样本数量。在本例中,TP = 4(均为绿色单元格)
FP 不应该获得的标签的但是获取了标签数量。例如,在第一列中应该被预测为1,但被预测为2。所以在这种情况下,类2出现一个 false positive。即,对于类别2来说,是FP。另一方面,如果预测是正确的(第2列),则不会被统计到FP。在本例中,FP = 5(均为红色单元格)
FN 是应该被预测但没有被预测的标签数量。再看第一列,1应该被预测到,但没有。所以在这种情况下,类1有一个FN。与FP情况一样,如果预测正确,则不计算FN(第2列)。即,对于类别1来说,是FN。在本例中,FP = 5(均为红色单元格)
换句话说,如果有false positive,也总会有false negative,反之亦然,因为总是有一类被预测。如果预测了A类,真标签是B,那么对于A类别就有FP,对于B类别就有FN。如果预测是正确的,即预测了A类,A也是真标签,那么既没有false positive,也没有false negative,只有true positive。 因此不存在只增加FP或FN而不同时增加两者的可能性。即,两者一定是同时变化的,那么一起增加,要么同时不增加。这就是为什么在使用micro平均方案时precision 和 recall总是相同。
micro precision 和 micro recall 计算如下:
micro precision
=
T
P
1
+
T
P
2
+
T
P
3
T
P
1
+
F
P
1
+
T
P
2
+
F
P
2
+
T
P
3
+
F
P
3
\\textmicro precision=\\fracTP_1+TP_2+TP_3TP_1+FP_1+TP_2+FP_2+TP_3+FP_3
micro precision=TP1+FP1+TP2+FP2+TP3+FP3TP1+TP2+TP3
micro recall
=
T
P
1
+
T
P
2
+
T
P
3
T
P
1
+
F
N
1
+
T
P
2
+
F
N
2
+
T
P
3
+
F
N
3
\\textmicro recall=\\fracTP_1+TP_2+TP_3TP_1+FN_1+TP_2+FN_2+TP_3+FN_3
micro recall=TP1+FN1+TP2+FN2+TP3+FN3TP1+TP2+TP3
简而言之,micro precision 分子是全部的TP,分母是全部类别的TP+FP;micro recall的分母是全部类别的TP+FN。
上述实例precision, recall 和 F1 score的计算如下:
Precision
P
=
4
4
+
5
=
4
9
=
0.4444
P = \\frac44+5 = \\frac49 = 0.4444
P=4+54=94=0.4444
Recall
R
=
4
4
+
5
=
4
9
=
0.4444
R = \\frac44+5 = \\frac49 = 0.4444
R=4+54=94=0.4444
F1 score
F
1
=
2
4
9
∗
4
9
4
9
+
4
9
=
4
9
2
4
9
=
4
9
=
0.4444
F1 = 2 \\frac\\frac49 * \\frac49\\frac49 + \\frac49 = \\frac\\frac49^2\\frac49 = \\frac49 = 0.4444
F1=294+9494∗94=94942=94=0.4444
注意:
由于micro平均不区分不同的类别,只是平均他们的度量分数,这种平均方案不容易由于测试集的不均匀分布(例如,3个类别,其中一个类别有98%的样本)而产生不准确的值。即,样本类别分布不均衡的场景,选用micro平均更适合。在不均匀分布的数据集的情况下,除了使用micro平均,也可以考虑加权平均,即weighted averaging。
macro averaging 和 weighted averaging
需要特别注意,上面的解释只适用于micro averaging(微平均)!当使用 macro averaging时,计算每个标签的指标,并找到它们的未加权平均值。所以macro averaging并没有考虑到各类标签样本的不平衡。
如果对上述micro averaging示例计算macro averaging,那么对于每个类1、2、3,分别计算精度、召回率和F1得分的值,然后取平均值,而不管它们在数据集中的出现频率如何。因此,如果两个类各只出现1%,第三个类出现98%,较大的类(类别3)总是被正确预测,但较小的类(类别1和类别2)经常出错,那么F1分数仍然会非常糟糕,而使用micro averaging or weighted averaging则会好很多。简而言之,macro averaging 给所有类别相同的权重,该方法能够平等看待每个类别,所以值会受稀有类别影响。
当使用 weighted averaging(加权平均)时, 在计算过程也会考虑各个类别出现的频率,这样F1 score 会很高(因为只有2%的样本预测主要是错误的)。这取决于你选择什么用例。如果较小的类非常重要,那么weighted averaging 可能是一个糟糕的选择,应该选择macro averaging。
macro averaging 示例
为了完整起见,这里将进一步展示使用macro averaging时如何计算精度、召回率和F1。在这种情况下,首先要分别为每一个类计算精度、召回率和F1。现在可以把每个类看作一个二进制标签(类预测是/否)。在前面micro averaging例子中(见上表),每个类的TP, FN, FP值和计算得到的精度§,召回率®和F1得分如下:
Class 1: TP = 0 ; FN = 2 ; FP = 2 => P = 0 ; R = 0 ; F1 = 0 以上是关于多类别分类任务(multi-class)中为何precision,recall和F1相等?的主要内容,如果未能解决你的问题,请参考以下文章
Class 2: TP = 3 ; FN = 1 ; FP = 2 => P =