Hibernate学习小结
Posted mabaoqing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hibernate学习小结相关的知识,希望对你有一定的参考价值。
1 Hibernate4.x 下获取SessionFactory
Configuration config = new Configuration().configure();
// 创建服务注册对象
ServiceRegistry serviceRegistry = new ServiceRegistryBuilder().applySettings(config.getProperties()).buildServiceRegistry();
// 创建sessionFactory对象
SessionFactory sessionFactory = config.buildSessionFactory(serviceRegistry);2 配置hibernate.cfg.xml文件
<hibernate-configuration>
<session-factory>
<!-- 连接数据库的基本信息 -->
<property name="connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="connection.url">jdbc:mysql://localhost/hibernate?useUnicode=true&characterEncoding=utf-8</property>
<property name="connection.username">root</property>
<property name="connection.password">root</property>
<!-- 指定数据库方言,hibernate对一些标准型数据库进行了默认的处理 -->
<property name="dialect">org.hibernate.dialect.MySQLDialect</property>
<property name="show_sql">true</property>
<property name="format_sql">true</property>
<!-- 是否自动建表create,update -->
<property name="hbm2ddl.auto">update</property>
<!-- 映射文件的路径或注解类,不支持包扫描 -->
<mapping resource="com/ma/hibernate/Student.hbm.xml"/>
<mapping class="com.ma.hibernate.Teacher"/>
</session-factory>
</hibernate-configuration>3 配置hibernate映射文件 .hbm.xml
<hibernate-mapping package="com.ma.entity">
<!-- 类名以及对应的数据库表名 -->
<class name="User" table="USER">
<!-- 属性对应的表的主键名 -->
<id name="id" column="id">
<!-- 主键生成策略 -->
<generator class="native"/>
</id>
<!-- 属性对应的表的一般属性 -->
<property name="username"/>
</class>
</hibernate-mapping>4 openSession与getCurrentSession
- open每次都获取一个新的session
- 前者需手动关闭,后者自动关闭
- current获取当前上下文中的session对象,将 session 与本地线程绑定,提交事务时自动刷新session缓存并关闭session,需要配置hibernate.cfg.xml文件
- 根据Id查询并修改对象信息时需要使用getCurrentSession(),在同一事务下
<!-- 与Spring整合时,不能配置此项,否则Spring不会自动开启事务 --><property name="current_session_context_class">thread/jpa(全局的)</property>5 get与load方法(装载对象)区别
- get立即发出select语句,load在使用返回的对象时才发出
- 对象不同:get得到的是实体类对象,load得到的是实体类的代理对象
- 查询结果不同:get未查到数据时返回空,load并使用该对象时会报ObjectNotFoundException,查到结果后在使用之前关闭了session会抛异常:LazyInitializationException
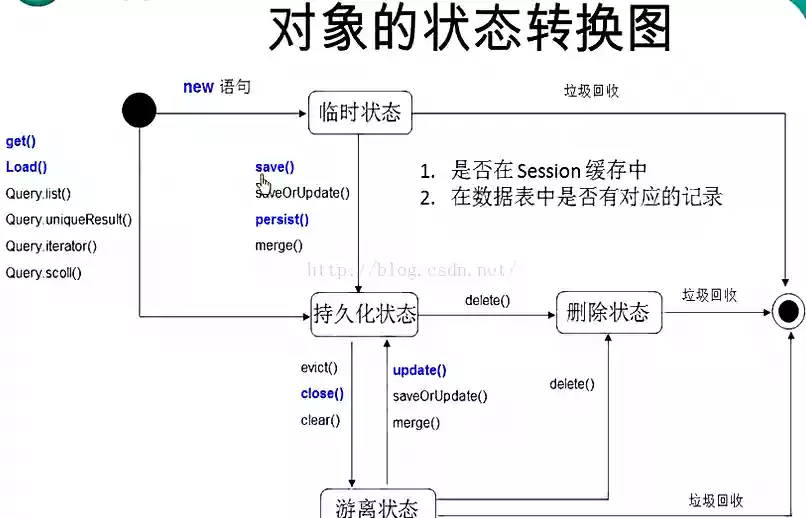
6 hibernate对象的几种状态
7 HQL
面向对象的sql语句,区分大小写
org.hibernate.query.Query query = session.createQuery("from Teacher t");
//from语句默认返回结果为一个List集合
List<Teacher> teachers = query.list();
query.uniqueResult(), 确保 HQL 语句只返回一个结果
// where:
// is null
// is [not] empty 在MySQL中会自动转换为 exists()
// 删除数据:最好是先通过id获取对象并删除而不是拼接sql语句通过id删除(能够使用级联删除)占位符?和 :param
- ?:query.setParameter(int index, Object obj); //index从0开始
- param:query.setParameter(Parameter param, Object obj)
投影查询:select语句
- 返回类型:默认为Object[], 只查询到一个数据时为Object
- 返回相应的结果类型:new list(), new map(), new Constructor(..)
- 去除重复值:使用distinct关键字,还可以通过将查到的List包装成一个HashSet(不允许重复)再包装成List
迫切内连接:inner,不返回左侧不满足条件的结果
多表连接查询:join
String hql = "select p from Product p join p.categorysecond cs join cs.category c where c.cid = ?";- 左外连接:left join
from Teacher t LEFT JOIN t.students
-- list()的 返回结果是个Object数组的集合,默认不会初始化右侧实体对象,使用distinct可以只查询到左侧对象- 迫切左外连接:left join fetch,左外连接且把集合属性初始化
// from Teacher t LEFT JOIN FETCH t.students
// list()的返回结果是存放着左侧实体对象的引用的集合,均被初始化(左侧所有和右侧满足条件的对象)
// 关闭延迟加载后直接查询Orders即可查询到Orderiten信息
String hql = "from Orders o where o.user.uid = ?";分页查询
//1. 使用query的两个方法
query.setFirstResult((pageNo - 1) * pageSize).setMaxResults(pageSize)
//2. 使用HibernateTemplate + Criteria实现
DetachedCriteria criteria = DetachedCriteria.forClass(Product.class);
criteria.add(Restrictions.eq("isHot", 1)).addOrder(Order.desc("pdate"));
List<Product> products = (List<Product>) this.getHibernateTemplate().findByCriteria(criteria, 0, 10);
//3. 使用HibernateTemplate分页的另一种写法
List<Product> list = this.getHibernateTemplate().execute(new PageHibernateCallback<>(hql, new Object[]{cid}, beginIndex, pageSize));
//PageHibernateCallback类
public class PageHibernateCallback<T> implements HibernateCallback<List<T>> {
private String hql;
private Object[] params;
private int startIndex;
private int pageSize;
public PageHibernateCallback(String hql, Object[] params,int startIndex, int pageSize) {
this.hql = hql;
this.params = params;
this.startIndex = startIndex;
this.pageSize = pageSize;
}
public List<T> doInHibernate(Session session) throws HibernateException {
//1 执行hql语句
Query query = session.createQuery(hql);
//2 实际参数
if(params != null){
for(int i = 0 ; i < params.length ; i ++){
query.setParameter(i, params[i]);
}
}
//3 分页
query.setFirstResult(startIndex);
query.setMaxResults(pageSize);
return query.list();
}
}自动生成字符串主键再添加对象到数据库
public String getNewSid() {
Session session = sessionFactory.getCurrentSession();
String hql = "select max(sid) from Student";
String strid = (String) session.createQuery(hql).uniqueResult();
if(strid == null || strid.equals("")) {
strid = "S0001";
} else {
String temp = strid.substring(1);
int id = Integer.parseInt(temp);
temp = String.valueOf(++id);
StringBuilder s = new StringBuilder();
s.append("S");
int length = temp.length();
for(int i=0; i<4-length; i++) {
s.append("0");
}
strid = s.append(temp).toString();
}
return strid;
}8 QBC
public void testQBC() {
Criteria c = session.createCriteria(User.class);
//添加查询条件Criterion,使用Restrictions
c.add(Restrictions.eq("id", 545));
// AND 使用Conjunction表示,实现了Criteria接口
Conjunction conjunction = Restrictions.conjunction();
conjunction.add(Restrictions.like("title", "tt", MatchMode.ANYWHERE));
// OR 使用Disjunction表示
Disjunction disjunction = Restrictions.disjunction();
c.add(conjunction).add(disjunction);
System.out.println(conjunction + "
" + disjunction);
// 统计查询,使用Projection
c.setProjection(Projections.max("id"));
// 排序
c.addOrder(Order.asc("id"));
//返回条件查询的结果集合
List list = c.list();
}调用本地SQL查询:(复杂SQL语句)
String sql = "select * from user";
SQLQuery sqlQuery = session.createSQLQuery(sql);
// 单表查询,指定结果类型
sqlQuery.addEntity(User.class);
// 多表查询,将查询结果类型转换为UserVO
sqlQuery.setResultTransformer(Transformers.aliasToBean(UserVO.class));
// 设置查询结果列的类型
addScalar("id",IntegerType.INSTANCE);
List list = sqlQuery.list();9 缓存策略:
一级缓存:Session级别的缓存,默认使用,不能关闭
flush(),检查缓存中的对象状态是否和数据库表记录一致,可能会发送sql语句以保证数据一致性,
- 提交事务时会自动调用,也可显式调用。
- 执行HQL或QBC查询时会先调用 flush() 方法,以获取最新数据
- 当底层数据库使用自增方式生成主键时,会在执行 save()方法时先生成sql语句,但不会执行插入操作,因为必须保证主键的值是存在的
refresh(),强制发送select语句,以保证缓存中的对象状态与数据库表中的记录一致,获取最新的对象信息。
- 需要修改mysql的事务隔离级别,可在hibernate.cfg.xml中添加Connection.isolation值为2
evict(obj)和clear()方法可以清除当前缓存
二级缓存(多个session可共同使用):
- 适用情形:不重要且很少被修改,允许出现偶尔的并发问题的数据
- query中的 list() 默认不使用缓存,iterate()使用二级缓存
- 导入 hibernate 文档 lib 目录下 optional 目录下的 ehcache 的所有 jar 包
- 导入 ehcache.xml 配置文件到当前WEB应用的src目录下
- 使用注解:在使用二级缓存的实体类上加注解:@Cache(usage=CacheConcurrencyStrategy.READ_WRITE)
- 使用xml:配置 hibernate.cfg.xml
<!-- 启用二级缓存 --> <property name="cache.use_second_level_cache">true</property> <!-- 配置二级缓存的工厂类,即二级缓存的提供商 --> <property name="hibernate.cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</property> <!-- 版本 4.x 后使用上述工厂类代替此配置 --> <property name="cache.provider_class">net.sf.ehcache.hibernate.EhCacheProvider</property> <!-- 此大顺序不能变 --> <mapping resource="com/ma/entity/Teacher.hbm.xml"/> <!-- 配置为哪个实体类使用二级缓存 --> <class-cache usage="read-only" class="com.ma.entity.Teacher"/> <!-- 也可在.hbm.xml 文件下的 class 标签下配置并可指定缓存策略--> <cache usage="read-only"/> <!-- 集合级别的二级缓存,也可在一方的 .hbm.xml 文件下的set标签下添加<cache usage="read-only"/> --> <class-cache usage="read-only" class="com.ma.entity.Teacher"/> <class-cache usage="read-only" class="com.ma.entity.Student"/> <collection-cache usage="read-only" collection="com.ma.entity.Teacher.students"/> <!-- 使用查询缓存,依赖于二级缓存--> <property name="cache.use_query_cache">true</property> <!-- session.createQuery("from User").setCacheable(true); -->
10 使用注解
配置hibernate.cfg.xml:
常用注解:
@Entity:映射实体类,对应数据库的表
@Table:配置对应表的信息
@Embeddable:可嵌入式的类
@Embedded:嵌入式类的对象(属性上的注解)
@Id: 主键生成策略:
- @GeneratedValue(generator = "my"),使用hibernate的主键策略生成器
- @GenericGenerator(name = "my", strategy = "native"),name值要和generator的值一样
@Column:数据库表字段注解
@Enumerated:枚举类型的注解
@Transient:映射时忽略此注解下的字段
@Temporal(TemporalType.TIMESTAMP):指定日期格式的类型
联合主键(不常用):
- 需要有个主键类,并实现序列化接口,重写equals和hashcode方法
- @EmbeddedId,常用
- @Id,@Embeddable,@IdClass(value=主键类)
11 关联映射关系
双向原则:
- 需指定控制方(通常为多方),inverse
- 需在程序中设定双向关联(为引用赋值)
XML:
一对多(多对一)双向映射:
- 保存时先保存一方,再保存多方,也可指定cascade属性
- 保存时生成的语句:单向多对一直接保存多方的外键;单向一对多先保存各自的信息,在更新多方的外键
- 获取到的对象:一方的引用是代理对象;多方的集合是hibernate内置的集合类型:具有延迟加载并存放代理对象的功能
<!-- 单向一对多关联:在一方定义一个多方的Set集合(需要初始化),name为该集合的属性名,table为要关联的多方对应的表,order-by对无序的set集合按照指定的列进行排序 --> <set name="students" table="student" inverse="true" order-by="gradeId" > <!-- 指定关联的多方对应数据库表中的外键列 --> <key column="gradeId"/> <!-- 指定关联的多方的类 --> <one-to-many class="Student"/> </set> <!-- 配置多对一关联关系,在多方定义一个一方的引用,name为当前持久化类的引用的属性名,class为一方的类名,column为多方对应表中的外键列名 --> <many-to-one name="grade" class="Grade" column="gradeId" />- 一对一双向外键:双方均持有对方的引用
<!-- 一方使用many-to-one配置,指定unique为true即为一对一 --> <many-to-one name="cardId" class="CardId" column="caedid" unique="true" /> <!-- 由于已指定unique,故另一方(没有外键)只使用配置 one-to-one 即可,使用 property-ref 属性指定使用被关联实体主键以外的字段作为关联字段 --> <one-to-one name="student" class="Student" property-ref="grade"/> <!-- 获取无外键的实体对象时默认使用左外连接获取到关联的对象,否则无法利用引用属性获取 -->- 一对一双向主键:双方均持有对方的引用
<!-- 主外键相同的一方 --> <id name="id" column="id"> <!-- 使用外键的方式来生成主键 --> <generator class="foreign"> <!-- property属性用来指定使用当前持久化类的哪个属性的主键作为外键 --> <param name="property">grade</param> </generator> </id> <!-- constrained 设为 true 表示为当前的主键添加外键约束 --> <one-to-one name="grade" class="Grade" constrained="true"/> <!-- 无外键的一方 --> <one-to-one name="student" class="Student"/>- 多对多双向映射:需要中间表,存放两张表的主键id,每个实体类的映射文件都需要进行如下配置,需要指定由谁控制(inverse)
<set name="students" table="student_grade" inverse="true"> <key column="rgradeid" /> <many-to-many class="Student" column="rstuid" /> </set>继承映射
- subclass:只有一张表,父类配置如下:
- 优点:只需要查询一张表
- 缺点:1. 使用了辨别者列;2.子类特有字段不能添加非空约束;3.层次多时表字段数太多
<!-- 配置辨别者列 --> <discriminator column="TYPE" type="string" /> <!-- 指定辨别者列的值,即class及subclass标签中discriminator-value属性的值,辨别者列的值由hibernate自动插入 --> <subclass name="Student" discriminator-value="STUDENT"> <property name="age"/> </subclass>- joined-subclass:每个子类一张表
- 插入子类对象需要插入到两张表中
- 优:没有辨别者列,可以添加约束,没有冗余字段
- 缺:需要添加外键约束,查询总是需要多表连接
<joined-subclass name="Student"table="STUDENT"> <key column="SID" /> <property name="age" /> </joined-subclass>- union-subclass:
- 父类需要使用子查询
- 存在冗余字段
- 更新父类信息麻烦
<union-subclass name="Student" table="STUDENT"> <property name="age"></property> </union-subclass>联合主键(不常用)
<!-- 需要有个主键类,并实现序列化接口,重写equals和hashcode方法 -->
<composite-id class="Order_User_PK" name="pk">
<key-property name="oid" />
<key-property name="uid" />
</composite-id>Annotation:注解在属性或getter方法上
一对一单向外键:
- 一方持有另一方的引用
- @OneToOne(cascade=CascadeType.ALL)
- @JoinColumn(name="card_id", unique=true)
一对一双向外键:
- 两方都需要持有对方的引用
- 一方参照一对一单向
- 另一方:@OneToOne(mappedBy="card"),必须指定mappedBy属性(控制方)
多对一单向外键:
- 多方持有一方的引用(外键)
- @ManyToOne(cascade={CascadeType.ALL}, fetch=FetchType.EAGER)
- @JoinColumn(name="sid") //name 为自定义为本表生成外键的列名称, referencedColumnName 为要关联表的列名称(可以不写,默认主键列)
一对多单向外键:
- 一方持有多方的Set集合(需初始化)
- @OneToMany(cascade={CascadeType.ALL}, fetch=FetchType.LAZY)
- @JoinColumn(name="sid"),不写此项的话会生成中间表
一对多(多对一)双向外键:
多方:持有一方的引用
- @ManyToOne(cascade={CascadeType.ALL}, fetch=FetchType.EAGER)
- @JoinColumn(name="user_id")
一方:持有多方的集合
- @OneToMany(mappedBy="user", cascade={CascadeType.ALL}, fetch=FetchType.LAZY),双向需要指定mappedBy属性,此时不能再使用@JoinColumn
多对多单向外键
- 需要一个中间表
- @ManyToMany
- @JoinTable(name="tea_stu", joinColumns={@JoinColumn(name="stuid")}, inverseJoinColumns={@JoinColumn(name="teaid")})
多对多双向外键
- @ManyToMany(mappedBy="teachers")
- 另一方:参照多对多单向外键关联
12 检索策略
类级别的检索策略
- 立即检索:修改 hbm.xml 文件中的class节点,添加lazy属性为false,默认为true,仅对load方法有效
- 延迟检索:load获取到的对象只保存OID属性,获取其他属性会发送SQL语句查询实例化实体对象
一对多或多对多的检索策略:
集合属性默认使用懒加载检索策略,修改set属性的lazy值(默认true/proxy),不建议改为false,可改为extra,增强的延迟检索(尽可能延迟集合初始化的时机)
set中的batch-size:设置一次性初始化set集合的数量
fetch:确定初始化集合的方式
- select:决定初始化集合的 sql 语句形式,subselect使用子查询方式初始化所有 set 集合,将忽略batch-size值
- join:决定初始化集合的时机,加载一方对象时使用迫切左外连接的方式检索n的一端的集合属性,将忽略lazy值
- 使用Query.list()查询会忽略join,而使用默认的延迟检索
13 hibernate乐观锁(级联保存报错)
以上是关于Hibernate学习小结的主要内容,如果未能解决你的问题,请参考以下文章
免费下载全套最新013Spring Struts hibernate整合项目视频教程+教学资料+学习课件+源代码+软件开发工具