Java并发:并发集合ConcurrentHashMap的源码分析
Posted 水獭同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java并发:并发集合ConcurrentHashMap的源码分析相关的知识,希望对你有一定的参考价值。
之前介绍了Java并发的基础知识和使用案例分析,接下来我们正式地进入Java并发的源码分析阶段,本文作为源码分析地开篇,源码参考JDK1.8
OverView:
JDK1.8源码中的注释提到:ConcurrentHashMap是一种提供完整的并发检索和对于并发更新有高预测性的散列表,遵循了与HashMap相同的功能性规格,并包含与HashTable每个方法都对应的方法.虽然所有操作都是线程安全的,但检索操作并不牵涉任何锁,不支持任何锁住整个散列表来保护所有的访问.
ConcurrentHashMap不会和HashTable一样,滥用synchronized关键字,从而令许多操作会锁住整个容器,而是采用分段锁技术,它的加锁粒度更细,并发访问环境下能获得更好高的吞吐量;
ConcurrentHashMap的数据结构如下图所示
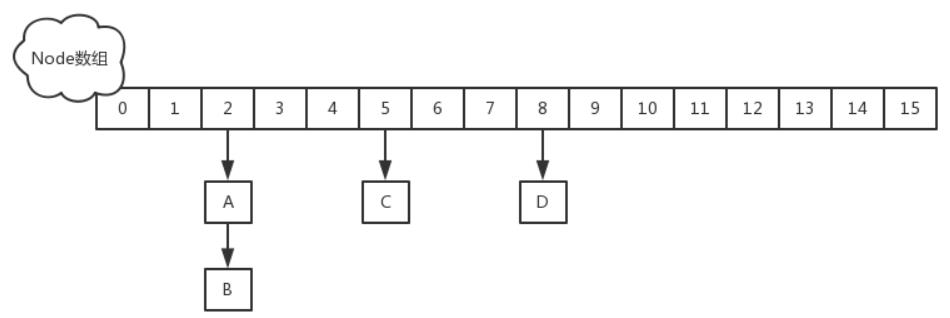
JDK1.8虽然已经摒弃Segment来存儲,但他仍然兼容Segment,只是它被用在序列化实现上了,直接用Node数组+链表(或红黑树)的数据结构来实现,并发控制使用Synchronized和CAS来实现;
部分核心源码分析:
构造器:
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) { //三个参数分别是:集合容量,负载因子,并发级别 //集合容量即预计的集合容量 //负载因子是指集合的密度,或者说是有效存儲占比 //并发级别即预估的并发修改集合的线程个数 if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0) throw new IllegalArgumentException(); if (initialCapacity < concurrencyLevel) initialCapacity = concurrencyLevel; //构造集合时,容量默认大于等于并发级别 long size = (long)(1.0 + (long)initialCapacity / loadFactor); //计算长度时要带上避免哈希冲突的链地址法产生的额外的存储空间再加1 int cap = (size >= (long)MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : tableSizeFor((int)size); //限制集合的最大长度 this.sizeCtl = cap; //sizeControl:扩容用的控制变量 }
putVal()方法:put()底层调用了putVal()用于插入键值对
final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); int hash = spread(key.hashCode());
//返回(h ^ (h >>> 16)) & HASH_BITS int binCount = 0; for (Node<K,V>[] tab = table;;) {
//遍历整个table数组,tab[i]即链表或红黑树的首节点 Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0) tab = initTable();
//如果整个table为空,就初始化这个table; else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//table不为空并且长度大于0,并且桶为空 if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null)))
//CompareAndSwap(CAS),如果tab[i]为空就将新的元素替换进去 break; // no lock when adding to empty bin } else if ((fh = f.hash) == MOVED)
//如果tab[i]的hash为MOVED,代表需要转移节点 tab = helpTransfer(tab, f); else { V oldVal = null; synchronized (f) {
//在每个tab上加私有锁,粒度更细 if (tabAt(tab, i) == f) { if (fh >= 0) {
//找到hash大于0的tab[i]节点 binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val;
//判断hash和key是否相等,相等就保存该点的值 if (!onlyIfAbsent) e.val = value;
//将指定值value保存到节点上 break; } Node<K,V> pred = e; if ((e = e.next) == null) {
//判断是否为bin的尾节点 pred.next = new Node<K,V>(hash, key, value, null); break;
//若是,就生成一个节点放在尾部,并跳出循环 } } } else if (f instanceof TreeBin) {
//如果tab[i]是TreeBin类型,说明这个Bin是红黑树结构,执行红黑树的插入操作 Node<K,V> p; binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i);
//当tab[i]下的元素大于等于预设阈值8时,就将整个bin转变为红黑树存儲 if (oldVal != null) return oldVal; break; } } } addCount(1L, binCount); return null; }
replaceNode方法:被remove()底层调用,用于删除节点
final V replaceNode(Object key, V value, Object cv) { // 计算key的hash值 int hash = spread(key.hashCode()); for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0 || (f = tabAt(tab, i = (n - 1) & hash)) == null)
// table为空或表长度为0或key对应的bin为空或长度为0,直接跳出循环 break; else if ((fh = f.hash) == MOVED) // bin中第一个结点的hash值为MOVED就转移节点 tab = helpTransfer(tab, f); else { V oldVal = null; boolean validated = false; synchronized (f) { if (tabAt(tab, i) == f) { if (fh >= 0) { // bin中首节点没有变化,结点hash值大于0 validated = true; for (Node<K,V> e = f, pred = null;;) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { // 结点的hash值与指定的hash值相等,并且key也相等 V ev = e.val; if (cv == null || cv == ev || (ev != null && cv.equals(ev))) { // cv为空或者与结点value相等或者不为空并且相等 // 保存该结点的val值 oldVal = ev; if (value != null) // value为null // 设置结点value值 e.val = value; else if (pred != null) // 前驱不为空 // 前驱的后继为e的后继,即删除了e结点 pred.next = e.next; else // 设置table表中下标为index的值为e.next setTabAt(tab, i, e.next); } break; } pred = e; if ((e = e.next) == null) break; } } else if (f instanceof TreeBin) { // 节点为红黑树结点类型 validated = true; // 类型转化 TreeBin<K,V> t = (TreeBin<K,V>)f; TreeNode<K,V> r, p; if ((r = t.root) != null && (p = r.findTreeNode(hash, key, null)) != null) { // 根节点不为空并且存在与指定hash和key相等的结点 // 保存p结点的value V pv = p.val; if (cv == null || cv == pv || (pv != null && cv.equals(pv))) { // cv为空或者与结点value相等或者不为空并且相等 oldVal = pv; if (value != null) p.val = value; else if (t.removeTreeNode(p)) // 移除p结点 setTabAt(tab, i, untreeify(t.first)); } } } } } if (validated) { if (oldVal != null) { if (value == null) addCount(-1L, -1); return oldVal; } break; } } } return null; }
get()方法:获取对应键的值
public V get(Object key) { Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek; int h = spread(key.hashCode()); if ((tab = table) != null && (n = tab.length) > 0 && (e = tabAt(tab, (n - 1) & h)) != null) {
//如果table不是空,且table的长度>0,且bin不为空 if ((eh = e.hash) == h) { if ((ek = e.key) == key || (ek != null && key.equals(ek)))
//若表中元素的hash和入参的hash相等,且两者的键一致,就返回该节点的值 return e.val; } else if (eh < 0)
//若表中节点的hash小于0,就在tab[i]的bin里找相同键的节点,若找到了就返回该节点的值,若没找到,就返回空 return (p = e.find(h, key)) != null ? p.val : null; while ((e = e.next) != null) { if (e.hash == h && ((ek = e.key) == key || (ek != null && key.equals(ek))))
//若表中节点的hash大于等于0,就遍历其所有后继节点并判断是否与存在相同的hash和键,有就返回节点的值 return e.val; } } return null; }
treeifyBin()方法:用于将链表转化成红黑树的数据结构,考虑到若一个散列桶(bin)中的节点太多,链表存儲的话查找节点的效率就会变成线性,所以在节点数大于一个阈值之后,会将之转化为红黑树,提升查找效率为O(logn)
private final void treeifyBin(Node<K,V>[] tab, int index) { Node<K,V> b; int n, sc; if (tab != null) { if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
//表不为空的条件下,表长小于阈值8,就对表进行扩容 tryPresize(n << 1); else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
//表不为空的条件下,bin中存在节点,并且节点的hash不小于0时,锁住该节点,并将对应链表转化为红黑树 synchronized (b) { if (tabAt(tab, index) == b) {
//判断首节点有没有变化 TreeNode<K,V> hd = null, tl = null; for (Node<K,V> e = b; e != null; e = e.next) {
//遍历bin中的所有节点 TreeNode<K,V> p = new TreeNode<K,V>(e.hash, e.key, e.val, null, null); if ((p.prev = tl) == null) hd = p;
//判断该节点是否是原链表的首节点,若是,就令其为红黑树的根 else tl.next = p;
//若该节点不是原链表的首节点,就作为红黑树的下一个节点 tl = p;
//更新临时节点变量tl } setTabAt(tab, index, new TreeBin<K,V>(hd));
//设置table表中的下标为hd } } } } }
size()方法:可以看到size()方法内并没有任何的同步机制,故size()所获得的值可能已经是过时的,因此只能仅仅作为一个估计值,尽管在并发环境下用处不大,但仍然可以作为我们权衡利弊的因素
public int size() { long n = sumCount(); return ((n < 0L) ? 0 : (n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int)n); }
小结:
JDK1.8的ConcurrentHashMap相比之前版本的ConcurrentHashMap有很了大的改进与不同,从源码中可以发现,每个同步代码块都是作为每个散列桶(bin)的私有锁来实现线程同步的,故每个bin之间的操作都是可以异步完成的,至于多线程的执行效率方面,就取决于散列桶的数量和散列函数的合理性(节点分配的均匀程度)了.
ConcurrentHashMap带来的结果是,在并发访问的环境下实现更高的系统吞吐量,在单线程环境下损失非常小的性能.并且,它的迭代器并不会抛出ConcurrentModifi-cationException,因此不需要再迭代的时候对容器加锁.
----Java并发编程实战
参考资料:
Java并发编程实战
https://www.cnblogs.com/lujiango/p/7580558.html
以上是关于Java并发:并发集合ConcurrentHashMap的源码分析的主要内容,如果未能解决你的问题,请参考以下文章