大数据之简单统计单词的案例在本地eclipse运行
Posted 头发浓密似羊毛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据之简单统计单词的案例在本地eclipse运行相关的知识,希望对你有一定的参考价值。
这是利用eclipse的线程代替linuxe的进程去执行
第一步:首先要将已经下载解压后的hadoop配置好相应的环境变量
第二步:
//创建配置文件对象
Configuration conf=new Configuration(true);
也就是下面的两行代码复制到创建配置文件对象的下面
//设置在本地运行的文件对象
conf.set("mapreduce.framework.name", "local");
// conf.set("fs.defaultFS", "hdfs://node01:9000");
conf.set("fs.defaultFS", "file:///");
第三步:
//指定joB的原始的输入输出路径,通过参数传入
FileInputFormat.setInputPaths(job, new Path("D://code//mr//wc//input//"));
FileOutputFormat.setOutputPath(job, new Path("D://code//mr//wc//output//"));
当然这里也可以利用主方法的run configurations来传入参数:下面给出一个验证的小案例
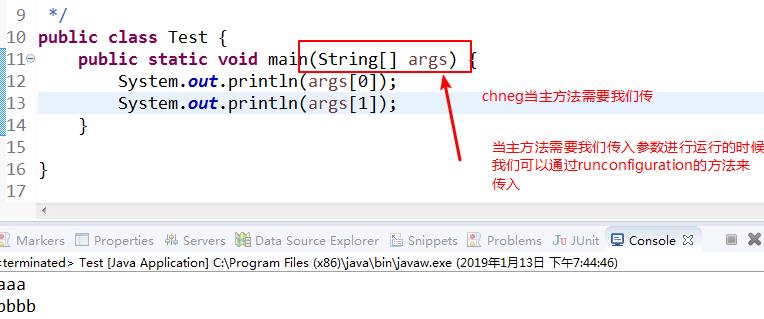
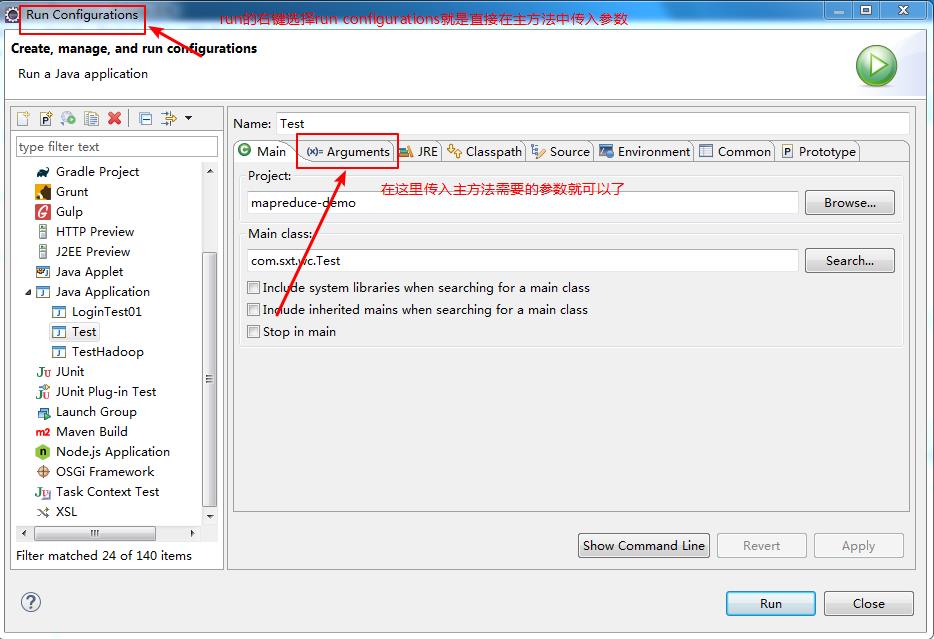
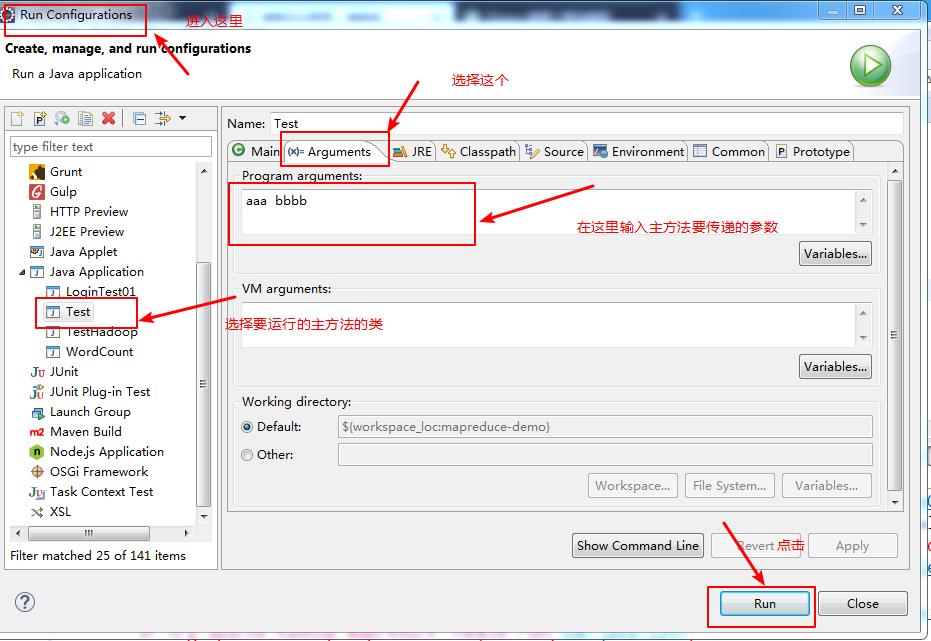

本案的设置如下:
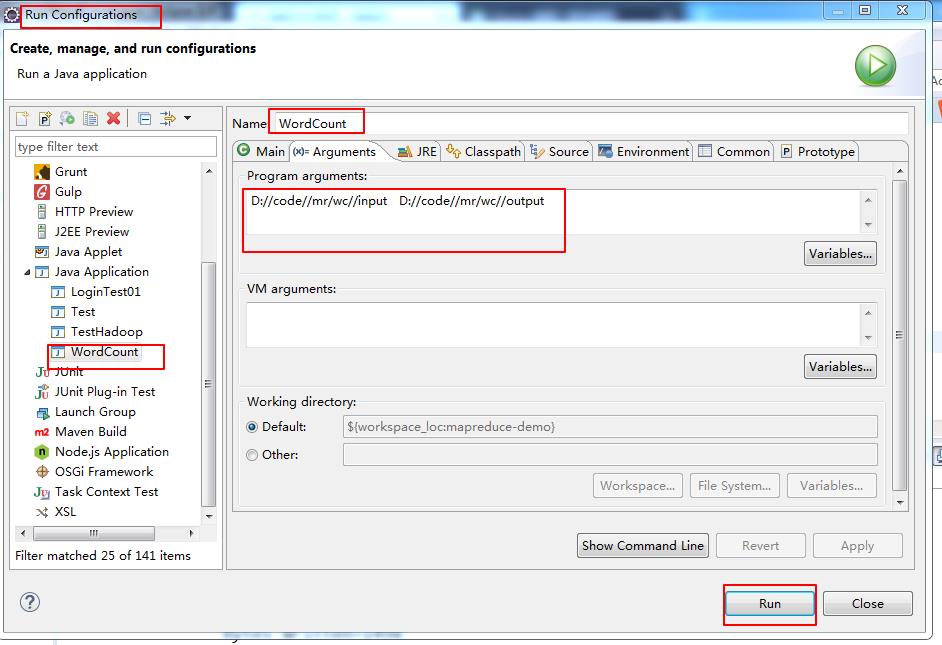
得到结果:
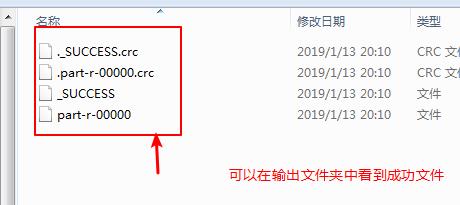
表名成功在本地的eclipse运行
以上是关于大数据之简单统计单词的案例在本地eclipse运行的主要内容,如果未能解决你的问题,请参考以下文章