KafkaConsumer 架构设计剖析和源码全流程详解
Posted 总要冲动一次
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KafkaConsumer 架构设计剖析和源码全流程详解相关的知识,希望对你有一定的参考价值。
Kafka 作为一个分布式事件暂存和中转系统,最重要的两个功能便是,往 Kafka 生产数据的生产者 KafkaProducer,和从 Kafka 拉取数据消费的消费者 KafkaConsumer。今天我们主要讲解消费者,KafkaConsumer。
我习惯从最朴素的问题开启对知识的探索:
1、我们的消费者从无到有,一定和 Kafka 服务端做了什么信息交互?来告诉服务端我来消费数据了。
2、我们都知道 Kafka 服务端一个 Topic 有多个分区来提高并行度,那么就存在多个消费者消费同一个 Topic 的情况,多个消费者是如何分配分区的呢?
这些问题都会在接下来的内容中给出答案,出发吧少年!
理论先行
从问题2我们并不难想到,Kafka 内部一定会提供一些组件来管理众多消费者和众多分区之间的映射关系,该组件在消费者端是:ConsumerCoordinator,在服务端是:GroupCoordinator。KafkaConsumer 初始化的时候主要就是这两个组件做网络请求,完成消费者的登记、分区消费策略制定等工作。
1、先上图,消费者及消费者组初始化流程
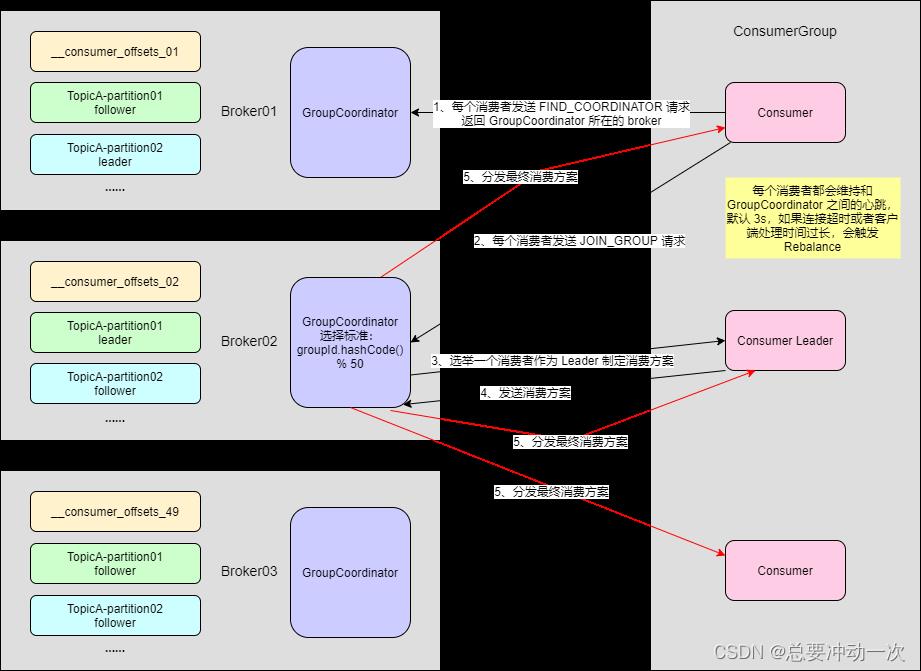
2、详细说明整体流程
- 每个 KafkaConsumer 刚启动的时候,并不知道整个组到底有多少个个体,所谓为了能让所有的个体都找到同一个 GroupCoodinator 报到,通过一次网络请求(发送 FIND_COORDINATOR 给我自己认为的负载最小的 Broker)找到目标 GroupCoodinator
- 每个 Consumer 启动的时候,内部会启动一个 ConsumerCoordinator 组件,负责和 Broker 中的 GroupCoodinator 打交道。比如发送 JOIN_GROUP 请求给目标 GroupCoodinator 用来请求加入 消费者组。
- Consumer 发送 JOIN_GROUP 给 Broker,Broker 上的 KafkaApis 会把请求转交给 GroupCoodinator 来处理。GroupCoodinator 处理完之后,会返回一个 JoinGroupResult 响应给 ConsumerCoordinator ,JoinGroupResult 会标识当前 Consumer 是否被选中为 Leader 了,如果为 Leader 的则负责制定该消费者组的消费方案。
- GroupCoodinator 返回要被消费的 Topic 的元数据给 Leader Consumer
- Leader Consumer 会为该 消费者组 制定消费方案,核心就是调用:PartitionAssignor 的 assign() 来完成消费方案的制定,最后生成一个 GroupAssignment
- Leader Consumer 会将最终制定的消费方案 List<SyncGroupRequestData.SyncGroupRequestAssignment> 通过发送 SYNC_GROUP 请求给发送给GroupCoordinator
- GroupCoodinator 接下来就会把收到的消费方案,发送给这个消费者组的各个 Consumer,这样子,每个消费者就清楚知道自己要去消费哪个分区了。
3、涉及到两个细节
-
同一个消费者组的所有消费者发送的 JONG_GROUP 请求,如何做到一致发给同一个 GroupCoordinator 的?
规则就是 按照消费者组 ID 的 hashCode 模除以 __consumer_offsets 的分区个数,计算得到 BrokerId ,那么该 Broker 上的 GroupCoordinator 负责为该费者组提供服务。
def partitionFor(groupId: String): Int = Utils.abs(groupId.hashCode) % groupMetadataTopicPartitionCount -
如果该消费者中有消费者实例宕机,那么就会导致有 Partition 不会被消费,应该怎么去做这个容错呢?
每个消费者实例的内部,都会专门启动一个 HeartbeatThread 心跳线程,负责每隔 heartbeat.interval.ms = 3000 发送 HEARTBEAT 请求给 GroupCoodinator。
如果该消费者和 Broker 的 Session 过了session.timeout.ms = 45000 过期了,则该消费者会被 GroupCoodinator 移除。从而触发 Rebalance。
如果消费者实例拉取数据超时,可以通过 max.poll.interval.ms = 300000 来进行配置,那么该消费者会被 GroupCoodinator 移除。从而触发 Rebalance。
4、涉及到的请求
整个机制中涉及到了4种请求
-
Consumer 启动的时候首先发送 FIND_COORDINATOR 请求给负载最小的 Broker,这个 Broker 会根据 group.id 计算得到为该 ConsumerGroup 提供服务的 GroupCoordinator 所在的 BrokerId,返回给 Consumer;
-
Consumer 经过第一次请求获取到目标 BrokerId 后,向 GroupCoordinator 发送 JONG_GROUP 请求登记入组;
-
Cosumer 制定消费方案完了之后,发送 SYNC_GROUP 将消费方案发送给 GroupCoodinator,然后 GroupCoodinator 会发送消费方案给每个消费者实例;
-
Consumer 内启动的 HeartbeatThread 会每隔 heartbeat.interval.ms = 3000 发送 HEARTBEAT 心跳请求给 GroupCoodinator。
问题一:我们的消费者从无到有,一定和 Kafka 服务端做了什么信息交互?来告诉服务端我来消费数据了。
上面四个请求就是该问题最好的回答
源码紧随
源码量比较大,下钻也非常深,以伪代码形式展示,并只展示核心代码,Kafka-3.1.0
1、入口
我们调用 KafkaConsumer 的API进行拉取数据时,调用了 KafkaConsumer.poll() 方法,该方法内部开始发请求注册自己以及加入组等:
public class KafkaConsumer<K, V> implements Consumer<K, V>
public ConsumerRecords<K, V> poll(final Duration timeout)
return poll(time.timer(timeout), true);
private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout)
do
// 消费者组的初始化
updateAssignmentMetadataIfNeeded(timer, false);
while (timer.notExpired());
return ConsumerRecords.empty();
在 poll 内部循环拉取数据,直到超出过期时间结束;我们关注 updateAssignmentMetadataIfNeeded(timer, false) 方法,内部实现消费者组的初始化工作。
boolean updateAssignmentMetadataIfNeeded(final Timer timer, final boolean waitForJoinGroup)
// TODO : 这里调用 ConsumerCoordinator 来继续处理
coordinator.poll(timer, waitForJoinGroup))
ensureActiveGroup(waitForJoinGroup ? timer : time.timer(0L))
// TODO : 1、发送 FIND_COORDINATOR 请求给 Broker,获取该消费者组对应的 Broker 服务节点
if (!ensureCoordinatorReady(timer))
return false;
// TODO : 2、启动发送心跳的线程,每隔3s 发送 HEARTBEAT 请求给 目标 GroupCoordinator 所在的 Broker
startHeartbeatThreadIfNeeded();
// TODO : 3、发送 JOIN_GROUP 请求给 FIND_COORDINATOR 请求返回的 Borker 节点加入到 消费者组 中
// TODO : 4、SYNC_GROUP 请求是在 JOIN_GROUP 回调处理器中发送,并且是只有当选 Leader 的消费者才发送
return joinGroupIfNeeded(timer);
ensureActiveGroup() 方法内部可以很清晰看到发送 FIND_COORDINATOR、HEARTBEAT、JOIN_GROUP 这三个请求的方法,其实 SYNC_GROUP 请求是在 joinGroupIfNeeded() 方法内部,在 JOIN_GROUP 请求发送成功后,回调函数内再次发送 SUNY_GROUP 请求。
2、发送第一个请求:FIND_COORDINATOR
protected synchronized boolean ensureCoordinatorReady(final Timer timer)
do
// TODO : 步骤1、将请求存入 ConsumerNetworkClient 内部的 unsent 队列中
// TODO : 此处设置请求类型 KafkaApis.FIND_COORDINATOR
final RequestFuture<Void> future = lookupCoordinator()
// TODO : 找一个最小负载节点作为询问协调者
Node node = this.client.leastLoadedNode();
if (node == null)
log.debug("No broker available to send FindCoordinator request");
return RequestFuture.noBrokersAvailable();
else
// TODO : 发送 FIND_COORDINATOR 请求,其实是将该请求放入未发送队列中 unsent
findCoordinatorFuture = sendFindCoordinatorRequest(node)
// TODO : 里面设置此次请求的类型:ApiKeys.FIND_COORDINATOR
FindCoordinatorRequest.Builder requestBuilder = new FindCoordinatorRequest.Builder(data);
// TODO : 此处 send,是将请求存储在一个 map(unsent) 中
// TODO : ConcurrentMap<Node, ConcurrentLinkedQueue<ClientRequest>> unsent;
return client.send(node, requestBuilder)
// 回调查看 FindCoordinatorResponseHandler 的实现
.compose(new FindCoordinatorResponseHandler());
// TODO : 步骤2、轮询所有可以发送的请求,真正的发送
// TODO : 此处获取到每一个请求 并打上 OP_WRITE 标签
client.poll(future, timer)
......
public void poll(Timer timer, PollCondition pollCondition, boolean disableWakeup)
// TODO : 发送我们现在可以发送的所有请求
long pollDelayMs = trySend(timer.currentTimeMs())
// TODO : 遍历 Broker 节点
for (Node node : unsent.nodes())
// TODO : 获取该节点的所有待发送的请求,是之前存储在 unsent Map 中的请求
Iterator<ClientRequest> iterator = unsent.requestIterator(node);
if (iterator.hasNext())
pollDelayMs = Math.min(pollDelayMs, client.pollDelayMs(node, now));
while (iterator.hasNext())
ClientRequest request = iterator.next();
if (client.ready(node, now))
// TODO : client 是 NetworkClient,涉及到 Kafka 网络通讯的内容,此处不做赘述,有兴趣可以再往里看看,会看到绑定 SelectionKey.OP_WRITE 事件
client.send(request, now);
iterator.remove();
while (coordinatorUnknown() && timer.notExpired());
步骤1 主要是构建 FIND_COORDINATOR 请求并暂存到 unsent 队列中,步骤2 主要是立刻轮询所有可发送的请求,在 channel 上标记 OP_WRITE 标签,服务端自然会获取到该请求。
步骤1 回调处理器 FindCoordinatorResponseHandler.onSuccess() 方法内部处理了 成功的响应,并将获取到得目标 GroupCoordinator 所在的节点信息,赋值给了 coordinator 属性,该属性是 ConsumerCoordinator 父类属性。
3、发送第二个请求:HEARTBEAT
看过了第一个请求的流程,KafkaConsumer 中所有的请求发送流程几乎一致,都是调用统一的接口进行处理,不同的是每次请求 ClientRequest 的实现不一样。
private synchronized void startHeartbeatThreadIfNeeded()
if (heartbeatThread == null)
heartbeatThread = new HeartbeatThread();
heartbeatThread.start();
查看 HeartbeatThread.run()
public void run()
log.debug("Heartbeat thread started");
while (true)
// TODO : 发送请求前的准备,更新时间,心跳间隔等
heartbeat.sentHeartbeat(now);
// TODO : 步骤1、HEARTBEAT 请求已就绪,存储在了 unsent 对列中
final RequestFuture<Void> heartbeatFuture = sendHeartbeatRequest()
// TODO : 看到这里,很熟悉的配方! 前面发送 FIND_COORDINATOR 也是类似处理
// TODO : 心跳请求类型:ApiKeys.HEARTBEAT
HeartbeatRequest.Builder requestBuilder =
new HeartbeatRequest.Builder(new HeartbeatRequestData()
.setGroupId(rebalanceConfig.groupId)
.setMemberId(this.generation.memberId)
.setGroupInstanceId(this.rebalanceConfig.groupInstanceId.orElse(null))
.setGenerationId(this.generation.generationId));
// TODO : 封装请求为 ClientRequest,在存入 unsent 对列中
// TODO : coordinator 是经过 FIND_COORDINATOR 请求获取到得目标 Broker 节点
return client.send(coordinator, requestBuilder)
.compose(new HeartbeatResponseHandler(generation));
仔细查看这个过程,相比第一个 FIND_COORDINATOR 请求少了个 client.poll() 轮询的方法,这也变相说明了在这些请求中 HEARTBEAT 没有 FIND_COORDINATOR 、JOIN_GROUP、SYNC_GROUP 要紧。
4、发送第三个请求:JOIN_GROUP
boolean joinGroupIfNeeded(final Timer timer)
// TODO : 步骤1、准备请求,准备 JOIN_GROUP 类型请求,存储到 unsent 队列中
final RequestFuture<ByteBuffer> future = initiateJoinGroup();
// TODO : 步骤2、发送请求,轮询处理待发送队列中的所有可发送的请求
client.poll(future, timer);
里面的流程和上线几乎一致,这里就不再粘出来了,有兴趣的自己到源码里点点看。
需要注意的是,JOIN_GROUP 请求回调处理器是 JoinGroupResponseHandler,他的 handle() 方法内部直接解析请求响应 JoinGroupResponse,判断出当前消费者是不是当选为 LeaderConsumer,如果是需要再多干一件事,制定分区分配策略,并发送 SYNC_GROUP 请求给 GROUP_COORDINATOR 所在的节点。
// TODO : 请求 JOIN_GROUP 的响应处理器
private class JoinGroupResponseHandler extends CoordinatorResponseHandler<JoinGroupResponse, ByteBuffer>
@Override
public void handle(JoinGroupResponse joinResponse, RequestFuture<ByteBuffer> future)
// TODO : 成功分支
log.debug("Received successful JoinGroup response: ", joinResponse);
sensors.joinSensor.record(response.requestLatencyMs());
synchronized (AbstractCoordinator.this)
// TODO : 修改状态,完成 再平衡
state = MemberState.COMPLETING_REBALANCE;
if (heartbeatThread != null)
heartbeatThread.enable();
AbstractCoordinator.this.generation = new Generation(
joinResponse.data().generationId(),
joinResponse.data().memberId(), joinResponse.data().protocolName());
// TODO : 判断自己是不是 leader
if (joinResponse.isLeader())
// TODO : 当选 leader,里面会指定分区分配策略,并再次发送 SYNC_GROUP 请求
onJoinLeader(joinResponse).chain(future);
else
onJoinFollower().chain(future);
onJoinLeader(joinResponse) 当选 Leader 后需要发送第四个请求 SYNC_GROUP。
5、发送第四个请求:SYNC_GROUP
private RequestFuture<ByteBuffer> onJoinLeader(JoinGroupResponse joinResponse)
// TODO : 步骤1、执行分配
Map<String, ByteBuffer> groupAssignment = performAssignment(joinResponse.data().leader(), joinResponse.data().protocolName(), joinResponse.data().members())
// TODO : Leadre Consumer 负责制定消费方案
// 完成 50 个 Conusmer 到 50 个 Partition 消费关系的映射
// RoundRobin, Range, Sticky, ....
Map<String, Assignment> assignments = assignor.assign(metadata.fetch(), new GroupSubscription(subscriptions)).groupAssignment();
List<SyncGroupRequestData.SyncGroupRequestAssignment> groupAssignmentList = new ArrayList<>();
for (Map.Entry<String, ByteBuffer> assignment : groupAssignment.entrySet())
groupAssignmentList.add(new SyncGroupRequestData.SyncGroupRequestAssignment()
.setMemberId(assignment.getKey())
.setAssignment(Utils.toArray(assignment.getValue()))
);
// TODO : ApiKeys.SYNC_GROUP 类型请求,给服务端发送制定完成的分区分配策略
SyncGroupRequest.Builder requestBuilder =
new SyncGroupRequest.Builder(
new SyncGroupRequestData()
.setGroupId(rebalanceConfig.groupId)
.setMemberId(generation.memberId)
.setProtocolType(protocolType())
.setProtocolName(generation.protocolName)
.setGroupInstanceId(this.rebalanceConfig.groupInstanceId.orElse(null))
.setGenerationId(generation.generationId)
.setAssignments(groupAssignmentList)
);
log.debug("Sending leader SyncGroup to coordinator at generation : ", this.coordinator, this.generation, requestBuilder);
// TODO : 步骤2、准备请求 存储到 unsent 队列
return sendSyncGroupRequest(requestBuilder);
步骤1 制定分区分配策略,Kafka默认使用 RangeAssignor分区策略;
Kafka 为我们提供的可选策略有:
org.apache.kafka.clients.consumer.RangeAssignor:按主题分配分区,一个主题按照分区数和消费者数范围分配,分配完该主题相同的策略再分配下一个主题。
org.apache.kafka.clients.consumer.RoundRobinAssignor:以循环方式将分区分配给消费者,按照TopicPartition轮训分配给每个消费了该主题的所有消费者。
org.apache.kafka.clients.consumer.StickyAssignor:保证分配是最大平衡的,同时保留尽可能多的现有分区分配。
org.apache.kafka.clients.consumer.CooperativeStickyAssignor:遵循相同的 StickyAssignor 逻辑,但允许合作再平衡。
这里便是问题二的答案了:
我们都知道 Kafka 服务端一个 Topic 有多个分区来提高并行度,那么就存在多个消费者消费同一个 Topic 的情况,多个消费者是如何分配分区的呢?
步骤2 主要就是发送 SYNC_GROUP 请求了,请求发送之后,每个消费者自然会在 第三个请求 JOIN_GROUP 的响应中获取到最终分配给自己的消费策略。
创作不易,希望对你有帮助,喜欢的话留个关注呗 >_<
以上是关于KafkaConsumer 架构设计剖析和源码全流程详解的主要内容,如果未能解决你的问题,请参考以下文章