本文的题目出自博客
http://www.54tianzhisheng.cn/2018/07/12/youzan/
但是作者没有给出答案,博主斗胆来制作答案版。
引言
说在前面的话:
本文适合人群:急等着换工作的人
我承认刷面试题很有用的,纵观几年来的JAVA面试题,你会发现每家都差不多。比如,你仔细观察,你会发现,HashMap的出现几率未免也太高了吧!连考察的知识点都一样,什么hash碰撞啊,并发问题啊!再比如JVM,无外乎考内存结构,GC算法等!因此,如果是为了面试,完全是有套路可以准备的!记住,基础再好,也架不住面试官天马行空的问,所以刷面试题还是很有必要的!
本文不适合人群:专攻JAVA某方面技术的人
因为这类人专攻JAVA某块技术,知识容易出现死角。贸然阅读本文,发现自己一堆题目都不会,会觉得有一种挫败感,发现自己连校招生都不如。然而,会点面试题不算什么,毕竟Homebrew作者也出现过解不出面试题,被Google拒绝,缘由就是,因为他不会翻转二叉树。难道你能说Homebrew的作者水平有问题!
正文
1、自我介绍
评注:这个地方答什么随意,大部分面试官不会听你介绍,这个时间都在看简历。如果是电话面,回答时间控制在40秒到1分钟左右就行。如果是现场面,那就好办了,你注意看面试官什么时候抬头看你,一般面试官放下简历,抬头看你的时候,赶紧收尾!
回答:我叫xx,毕业于xxx,兴趣xx,做过xx项目....
2、Map 的底层结构?(HashMap)
评注:老题目了,各位面试的人员必须熟记!
回答:Map是以键值对来存储对象的,它的底层实际上是数组和链表来组成的,经典的一张图如下(别人画的);
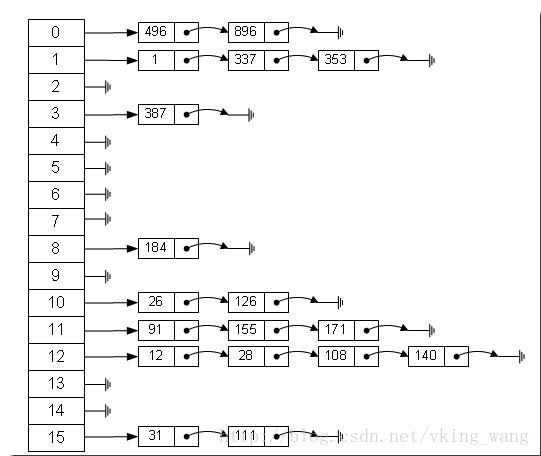
当使用put方法时,先查找出数组位置是否存在对象,通过key.hashcode对数组长度取余;存在,则把里面的链表拿出来,判断链表里面是否存在key值与传递过来的key值一样的对象,存在,则把传递过来的value取代链表key对应的value,不存在,则直接通过链表的add()方法加到链表后面;
当使用get方法时,先查找出数组位置是否存在对象,通过key.hashcode对数组长度取余;如果不存在,则返回为空,如果存在,则遍历链表,判断链表里面是否存在key值与传递过来的key值一样的对象,存在,则把key值对应的value取出返回,不存在,则返回为空;
3、线程安全的 Map (concurrentHashMap)简单的说了下这两 1.7 和 1.8的区别,本想问下要不要深入的讲下(源码级别),结果面试官说不用了。
评注:老题目了,如果有时间,再去了解一下,解决HashMap线程安全的各种方法,以及原理!此题只能大概回答一下结构的变化,因为其中的实现代码都变了,细说可以说很久,估计面试官也没时间听!
回答:
jdk1.7中采用 Segment + HashEntry的方式进行实现,结构如下:
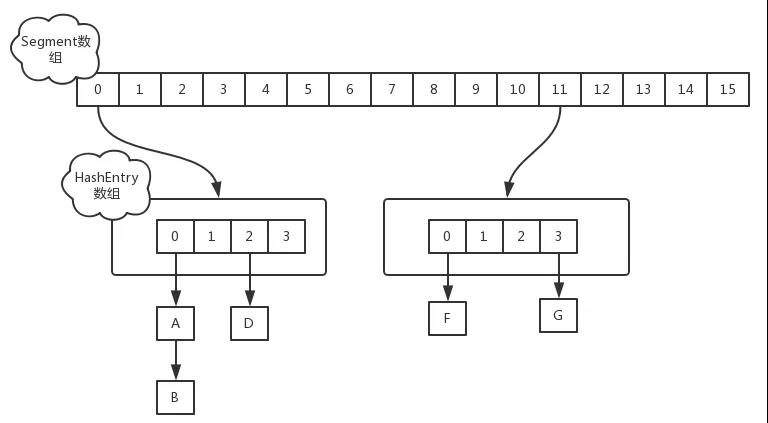
Segment数组的意义就是将一个大的table分割成多个小的table来进行加锁,而每一个Segment元素存储的是HashEntry数组+链表,这个和HashMap的数据存储结构一样
而jdk1.8中则
去除 Segment + HashEntry + Unsafe 的实现,
改为 Synchronized + CAS + Node + Unsafe 的实现
其结构图如下:
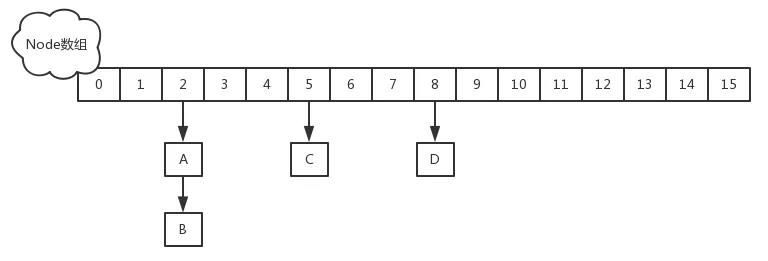
如上图所示,取消了Segment字段,数组中存储的就是Node。它与HashMap中的HashEntry定义很相似,但是有一些差别。它对value和next属性设置了volatile同步锁,它不允许调用setValue方法直接改变Node的value域。
另外,将原先table数组+单向链表的数据结构,变更为table数组+单向链表+红黑树的结构,在hash碰撞过多的情况下会将链表转化成红黑树。
4、项目 MySQL 的数据量和并发量有多大?
评注:此题为走向题,你的回答不同,后面问题走向就变了。
关于容量:单表行数超过 500 万行或者单表容量超过2GB,此时就要答分库分表的中间件了!那后面题目的走向就变为mycat、sharing-jdbc等分库分表中间件的底层原理了!
关于并发量:如果并发数过1200,此时就要答利用MQ或者redis等中间件,作为补偿措施,而不能直接操作数据库。那后面的题目走向就是redis、mq的原理了!
介于面试者还是一个应届生,我斗胆猜测面试者是这么答的
回答:数据量估计就三四百万吧,并发量就五六百左右!
5、你对数据库了解多少?
评注:因为你答的数据量和并发量不大,因此中间件这块没啥好问的。因此,题目走向变为数据库底层!另外,此题为引导题,面试官在给你机会引向你最擅长的方面!
回答:了解常见数据库调优方法,索引优化等!
6、你说下数据库的索引实现和非主键的二级索引
评注:这个问题是根据上面,你的回答而问出来的!记得引向自己最擅长的数据库基础知识!默认是回答mysql数据库的
回答:
从数据结构角度:
B-Tree索引,数据结构就是一颗B+树。
Hash索引,Hash索引比较的是进行Hash运算之后的Hash值,所以它只能用于等值的过滤,不能用于基于范围的过滤。基本不用!
R-Tree索引,仅支持geometry数据类型,也基本不用!
至于非主键的二级索引,这个实际上问的就是非聚簇索引!非聚簇索引本身就是一颗B+树,其根节点指向聚簇索引的B+树,具体的请看这篇文章《MySQL(Innodb)索引的原理》
7、项目用的是 SpringBoot ,你能说下 Spring Boot 与 Spring 的区别吗?
评注:基础题,会spring boot的,基本都答的上来。就算没准备过,当场思考下都可以回答的出来!也是属于引导题!
回答:
- Spring Boot可以建立独立的Spring应用程序;
- 内嵌了如Tomcat,Jetty和Undertow这样的容器,也就是说可以直接跑起来,用不着再做部署工作了。
- 无需再像Spring那样搞一堆繁琐的xml文件的配置;
- 可以自动配置Spring;
- 提供了一些现有的功能,如量度工具,表单数据验证以及一些外部配置这样的一些第三方功能;
- 提供的POM可以简化Maven的配置
8、SpringBoot 的自动配置是怎么做的?
评注:此题也是根据你的第七问,进一步提问而得出。
回答:
先答为什么需要自动配置?
顾名思义,自动配置的意义是利用这种模式代替了配置 XML 繁琐模式。以前使用 Spring MVC ,需要进行配置组件扫描、调度器、视图解析器等,使用 Spring Boot 自动配置后,只需要添加 MVC 组件即可自动配置所需要的 Bean。所有自动配置的实现都在 spring-boot-autoconfigure 依赖中,包括 Spring MVC 、Data 和其它框架的自动配置。
接着答spring-boot-autoconfigure 依赖的工作原理?
spring-boot-autoconfigure 依赖的工作原理很简单,通过 @EnableAutoConfiguration 核心注解初始化,并扫描 ClassPath 目录中自动配置类对应依赖。比如工程中有木有添加 Thymeleaf 的 Starter 组件依赖。如果有,就按按一定规则获取默认配置并自动初始化所需要的 Bean。
其实还能再继续答@EnableAutoConfiguration 注解的工作原理!不过篇幅太长,答到上面那个地步就够了!
9、MyBatis 定义的接口,怎么找到实现的?
评注:mybatis底层原理题,考察有没有看过mybatis的原理。博主刚好曾经自己写过一个mybatis,所以此题恰巧答的上来。
博主内心活动:"现在校招的都这么牛逼了么!"
回答:一共五步
- Mapper 接口在初始SqlSessionFactory 注册的。
- Mapper 接口注册在了名为 MapperRegistry 类的 HashMap中, key = Mapper class value = 创建当前Mapper的工厂。
- Mapper 注册之后,可以从SqlSession中get
- SqlSession.getMapper 运用了 JDK动态代理,产生了目标Mapper接口的代理对象。
- 动态代理的 代理类是 MapperProxy ,这里边最终完成了增删改查方法的调用。
10、Java 内存结构
评注:基础题,这个应该学JAVA的都会吧!送分题!如果博主没理解错应该是在问JVM的内存结构!
回答:JVM内存结构主要有三大块:堆内存、方法区和栈。堆内存是JVM中最大的一块由年轻代和老年代组成,而年轻代内存又被分成三部分,Eden空间、From Survivor空间、To Survivor空间,默认情况下年轻代按照8:1:1的比例来分配;
方法区存储类信息、常量、静态变量等数据,是线程共享的区域,为与Java堆区分,方法区还有一个别名Non-Heap(非堆);栈又分为java虚拟机栈和本地方法栈主要用于方法的执行。
11、对象是否可 GC?
评注:这个问题就是在问,JVM如何判断对象是否需要被回收!不用答引用计数法,答可达性分析算法就行。
回答:
这个算法的基本思路是通过一些列称为“GC Roots”的对象作为起始点,从这些点开始向下搜索,搜索走过的路径称为引用链,当一个对象到GC Roots没有任何引用链相连时,则证明对象需要被回收.
如图:
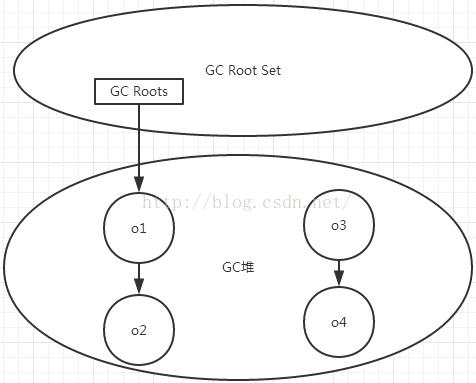
上图中o3,o4对象没有任何GC Roots可达到,所有这两个对象不可用了,需要被GC回收
Java可作为GC Roots的对象包括下面几种:
- 虚拟机栈中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中产量引用的对象
- 本地方法栈中JNI引用的对象
12、Minor GC 和 Full GC
评注:基础题,会JVM调优的,基本都会!我只是奇怪,怎么没问Major GC呢?我们还是把Major GC也给答了吧!
回答:
堆内存是JVM中最大的一块由年轻代和老年代组成。
那么,从年轻代空间(包括 Eden 和 Survivor 区域)回收内存被称为 Minor GC。
Major GC 是清理老年代。
Full GC 是清理整个堆空间—包括年轻代和老年代。
13、垃圾回收算法
评注:基础题,博主斗胆猜测,应该是在问垃圾回收算法有哪些。面试官应该没有耐心去听你一个个去背算法概念!
回答:
标记-清除算法、标记整理算法、复制算法、分代收集算法
14、垃圾回收器 G1
评注:上面的题目更深入的问法。JVM可以配置不同的回收器。比如Serial, Parallel和CMS几种垃圾回收器。以Serial Collector(串行回收器)为例,它在在年轻代是一个使用标记-复制算法的回收器。在老年代使用的是标记-清扫-整理算法。
另外,关于G1回收器可以问的点很多,此题作者没有描述清楚究竟问的是G1回收器的那个点,就满回答一下概念吧!
如果是我来问,我就直接给你场景,问你该用哪种回收器了。直接问回收器,那就比较容易了!
常用参数:
*-XX:+UseSerialGC:在新生代和老年代使用串行收集器
-XX:+UseParNewGC:在新生代使用并行收集器
//自己查询吧,太多了!
回答:
G1 GC是Jdk7的新特性之一、Jdk7+版本都可以自主配置G1作为JVM GC选项。 G1 将整个堆划分为一个个大小相等的小块(每一块称为一个region),每一块的内存是连续的,每个块也会充当 Eden、Survivor、Old三种角色,但是它们不是固定的,这使得内存使用更加地灵活。如下图所示

执行垃圾收集时,收集线程在标记阶段和应用程序线程并发执行,标记结束后,G1 也就知道哪些区块基本上是垃圾,存活对象极少,G1 会先从这些区块下手,因为从这些区块能很快释放得到很大的可用空间,这也是为什么 G1 被取名为 Garbage-First 的原因。
15、项目里用过 ElasticSearch 和 Hbase,有深入了解他们的调优技巧吗?
评注:一个应届生搭的ElasticSearch 和 Hbase,一般都只是demo级别的,懂基本的CRUD的使用即可!一般不会去深入了解调优技巧的!这个问题如果答深入了解过,是给自己挖坑!因为这个问题,答案太广了!
回答:并没有深入了解过!
16、Spring RestTemplate 的具体实现
评注:这题问的博主有点懵!如果是我来问,我会先问访问Rest服务的客户端这么多,为什么选Spring RestTemplate?然后才来原理。这个突然就冒出一个具体实现,我是有点懵啦!
回答:
其实RestTemplate和sl4fj这种门面框架很像,本质就是在Http的网络请求中增加一个马甲,本身并没有自己的实现。对此有疑问的,可以看我的另一篇
《架构师必备,带你弄清混乱的JAVA日志体系!》
底层可以支持多种httpclient的http访问,上层为ClientHttpRequestFactory接口为,底层如下所示:
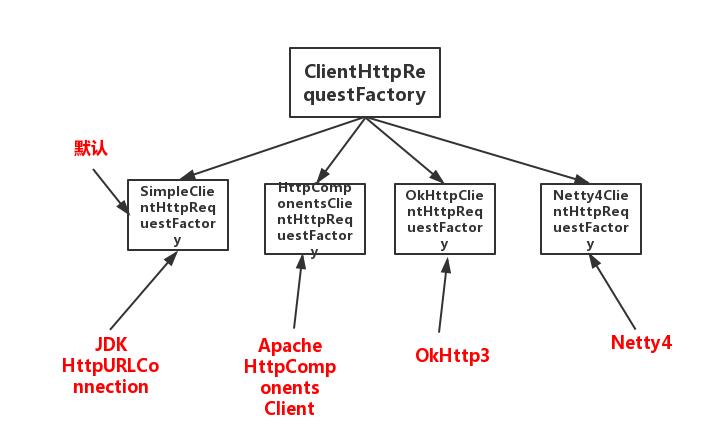
那么RestTemplate则封装了组装、发送 HTTP消息,以及解析响应的的底层细节。
答到这个份上可以了,难道你还要把类之间关系的引用图,画出来?太不现实了!
17、描述下网页一个 Http 请求,到后端的整个请求过程
评注:基础题,感觉属于常识题!必会!
回答:
利用DNS进行域名解析 --> 发起TCP的3次握手 --> 建立TCP连接后发起http请求 --> 服务器响应http请求,浏览器得到html代码 --> 浏览器解析html代码,并请求html代码中的资源(如js、css、图片等) --> 浏览器对页面进行渲染呈现给用户
18、多线程的常用方法和接口类及线程池的机制
评注:基础题,基本会点线程知识的,多多少少都会答点!但是这道题,我感觉范围有点大啊!可能是作者没表述清楚吧!
回答:
常用方法:
start,run,sleep,wait,notify,notifyAll,join,isAlive,currentThread,interrupt
常用接口类:
Runnable、Callable、Future、FutureTask
线程池的机制:
在面向对象编程中,创建和销毁对象是很费时间的,因为创建一个对象要获取内存资源或者其它更多资源。所以提高服务程序效率的一个手段就是尽可能减少创建和销毁对象的次数,所以出现了池化技术!。
简单的线程池包括如下四个组成部分即可:
- 线程池管理器(ThreadPoolManager):用于创建并管理线程池
- 工作线程(WorkThread): 线程池中线程
- 任务接口(Task):每个任务必须实现的接口,以供工作线程调度任务的执行
- 任务队列:用于存放没有处理的任务。提供一种缓冲机制
19、总结我的 Java 基础还是不错,但是一些主流的框架源码还是处在使用的状态,需要继续去看源码
评注:坦白说,我没看出来哪些问题体现出主流的框架还是处在使用的状态。
20、死锁
评注:牛客网原题!把原因一起答了吧!
回答:
死锁是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去,如果系统资源充足,进程的资源请求都能够得到满足,死锁出现的可能性就很低,否则就会因争夺有限的资源而陷入死锁。
产生死锁的原因主要是:
- (1) 因为系统资源不足。
- (2) 进程运行推进的顺序不合适。
- (3) 资源分配不当等。
21、自己研究比较新的技术,说下成果!
评注:嗯,凸显自己的潜力,大家自由发挥!
22、你有什么想问的?我就问了下公司那边的情况,这个自由发挥!
评注:问问工作内容即可,千万别问什么福利啊,加班情况啊!这种问题,不要在技术面的时候问!
总结
本文就对一面的题目做出了回答,二面的题目,哪天有时间再写吧!