Java基本数据类型转换
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java基本数据类型转换相关的知识,希望对你有一定的参考价值。
一:Java的基本数据类型和引用数据类型
1:基本数据类型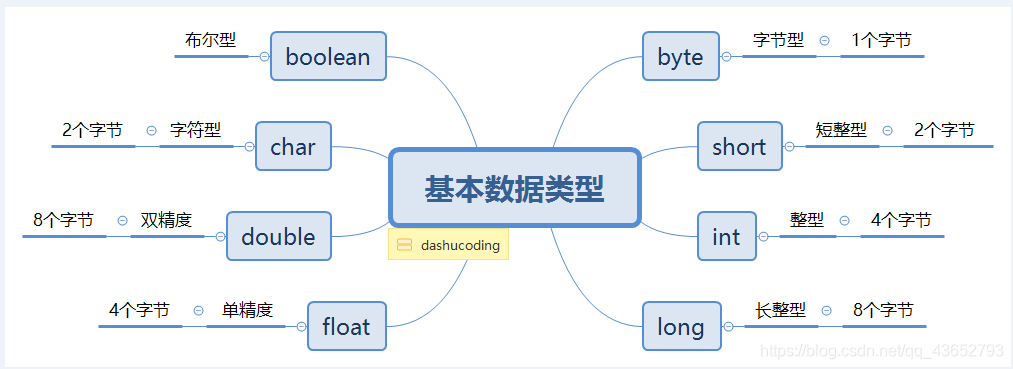
2:引用数据类型
二:基本数据的类型转换
基本数据类型中,布尔类型boolean占有一个字节,由于其本身所代码的特殊含义,boolean类型与其他基本类型不能进行类型的转换(既不能进行自动类型的提升,也不能强制类型转换), 否则,将编译出错。
1.基本数据类型中数值类型的自动类型提升
数值类型在内存中直接存储其本身的值,对于不同的数值类型,内存中会分配相应的大小去存储。如:byte类型的变量占用8位,int类型变量占用32位等。相应的,不同的数值类型会有与其存储空间相匹配的取值范围。具体如下所示: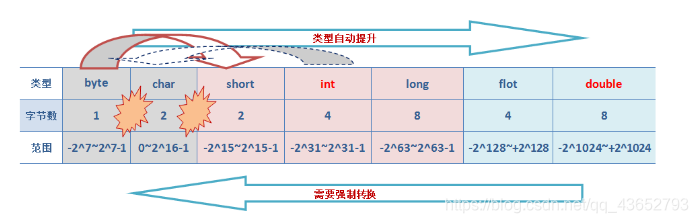
图中依次表示了各数值类型的字节数和相应的取值范围。在Java中,整数类型(byte/short/int/long)中,对于未声明数据类型的×××,其默认类型为int型。在浮点类型(float/double)中,对于未声明数据类型的浮点型,默认为double型。
接下来我们看看如下一个较为经典例子:
package com.corn.testcast;
public class TestCast {
public static void main(String[] args) {
byte a = 1000; // 编译出错 Type mismatch: cannot convert from int to byte
float b = 1.5; // 编译出错 Type mismatch: cannot convert from double to float
byte c = 3; // 编译正确
}
}是不是有点奇怪?按照上面的思路去理解,将一个int型的1000赋给一个byte型的变量a,编译出错,提示"cannot convert from int to byte"是对的,1.5默认是一个double型,将一个double类型的值赋给一个float类型,编译出错,这也是对的。但是最后一句:将一个int型的3赋给一个byte型的变量c,居然编译正确,这是为什么呢?
原因在于:jvm在编译过程中,对于默认为int类型的数值时,当赋给一个比int型数值范围小的数值类型变量(在此统一称为数值类型k,k可以是byte/char/short类型),会进行判断,如果此int型数值超过数值类型k,那么会直接编译出错。因为你将一个超过了范围的数值赋给类型为k的变量,k装不下嘛,你有没有进行强制类型转换,当然报错了。但是如果此int型数值尚在数值类型k范围内,jvm会自定进行一次隐式类型转换,将此int型数值转换成类型k。如图中的虚线箭头。这一点有点特别,需要稍微注意下。
在其他情况下,当将一个数值范围小的类型赋给一个数值范围大的数值型变量,jvm在编译过程中俊将此数值的类型进行了自动提升。在数值类型的自动类型提升过程中,数值精度至少不应该降低(整型保持不变,float->double精度将变高)。
package com.corn.testcast;
public class TestCast {
public static void main(String[] args) {
long a = 10000000000; //编译出错: The literal 10000000000 of type int is out of range
long b = 10000000000L; //编译正确
int c = 1000;
long d = c;
float e = 1.5F;
double f = e;
}
}如上:定义long类型的a变量时,将编译出错,原因在于10000000000默认是int类型,同时int类型的数值范围是-2^31 ~ 2^31-1,因此,10000000000已经超过此范围内的最大值,故而其自身已经编译出错,更谈不上赋值给long型变量a了。
此时,若想正确赋值,改变10000000000自身默认的类型即可,直接改成10000000000L即可将其自身类型定义为long型。此时再赋值编译正确。
将值为1000的int型变量c赋值给long型变量d,按照上文所述,此时直接发生了自动类型提升, 编译正确。同理,将e赋给f编译正确。
接下来,还有一个地方需要注意的是:char型其本身是unsigned型,同时具有两个字节,其数值范围是0 ~ 2^16-1,因为,这直接导致byte型不能自动类型提升到char,char和short直接也不会发生自动类型提升(因为负数的问题),同时,byte当然可以直接提升到short型。
2.基本数据类型中的数值类型强制转换
当我们需要将数值范围较大的数值类型赋给数值范围较小的数值类型变量时,由于此时可能会丢失精度(1讲到的从int到k型的隐式转换除外),因此,需要人为进行转换。我们称之为强制类型转换。
首先我们看一下如下的例子:
package com.corn.testcast;
public class TestCast {
public static void main(String[] args) {
byte p = 3; // 编译正确:int到byte编译过程中发生隐式类型转换
int a = 3;
byte b = a; // 编译出错:cannot convert from int to byte
byte c = (byte) a; // 编译正确
float d = (float) 4.0;
}
}byte p =3;编译正确在1中已经进行了解释。接下来将一个值为3的int型变量a赋值给byte型变量b,发生编译错误。这两种写法之间有什么区别呢?
区别在于前者3是直接量,编译期间可以直接进行判定,后者a为一变量,需要到运行期间才能确定,也就是说,编译期间为以防万一,当然不可能编译通过了。此时,需要进行强制类型转换。
强制类型转换所带来的结果是可能会丢失精度,如果此数值尚在范围较小的类型数值范围内,对于整型变量精度不变,但如果超出范围较小的类型数值范围内,很可能出现一些意外情况。
如下经典例子:
package com.corn.testcast;
public class TestCast {
public static void main(String[] args) {
int a = 233;
byte b = (byte) a;
System.out.println("b:" + b); // 输出:-23
}
}为什么结果是-23?需要从最根本的二进制存储考虑。
233的二进制表示为:24位0 + 11101001,byte型只有8位,于是从高位开始舍弃,截断后剩下:11101001,由于二进制最高位1表示负数,0表示正数,其相应的负数为-23。
3.进行数学运算时的数据类型自动提升与可能需要的强制类型转换
如下代码:
package com.corn.testcast;
public class TestCast {
public static void main(String[] args) {
byte a = 3 + 5; // 编译正常 编译成 3+5直接变为8
int b = 3, c = 5;
byte d = b + c; // 编译错误:cannot convert from int to byte
byte e = 10, f = 11;
byte g = e + f; // 编译错误 +直接将10和11类型提升为了int
byte h = (byte) (e + f); //编译正确
}
}当进行数学运算时,数据类型会自动发生提升到运算符左右之较大者,以此类推。当将最后的运算结果赋值给指定的数值类型时,可能需要进行强制类型转换。
最后感兴趣的朋友可以加群一起闲聊qq群947405150,一起交流技术群947405150.
以上是关于Java基本数据类型转换的主要内容,如果未能解决你的问题,请参考以下文章