调用链系列Zipkin搭建Spring-boot集承
Posted wangzhuxing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了调用链系列Zipkin搭建Spring-boot集承相关的知识,希望对你有一定的参考价值。
一、背景介绍
1、Zipkin是什么
Zipkin分布式跟踪系统;它可以帮助收集时间数据,解决在microservice架构下的延迟问题;它管理这些数据的收集和查找;Zipkin的设计是基于谷歌的Google Dapper论文。
每个应用程序向Zipkin报告定时数据,Zipkin UI呈现了一个依赖图表来展示多少跟踪请求经过了每个应用程序;如果想解决延迟问题,可以过滤或者排序所有的跟踪请求,并且可以查看每个跟踪请求占总跟踪时间的百分比。
2、为什么使用Zipkin
随着业务越来越复杂,系统也随之进行各种拆分,特别是随着微服务架构和容器技术的兴起,看似简单的一个应用,后台可能有几十个甚至几百个服务在支撑;一个前端的请求可能需要多次的服务调用最后才能完成;当请求变慢或者不可用时,我们无法得知是哪个后台服务引起的,这时就需要解决如何快速定位服务故障点,Zipkin分布式跟踪系统就能很好的解决这样的问题。
3、Zipkin下载和启动
官方提供了三种方式来启动,这里使用第二种方式来启动;
curl -sSL https://zipkin.io/quickstart.sh | bash -s java -jar zipkin.jar
访问localhost:9411
详细参考:https://zipkin.io/pages/quick...
二、Zipkin架构
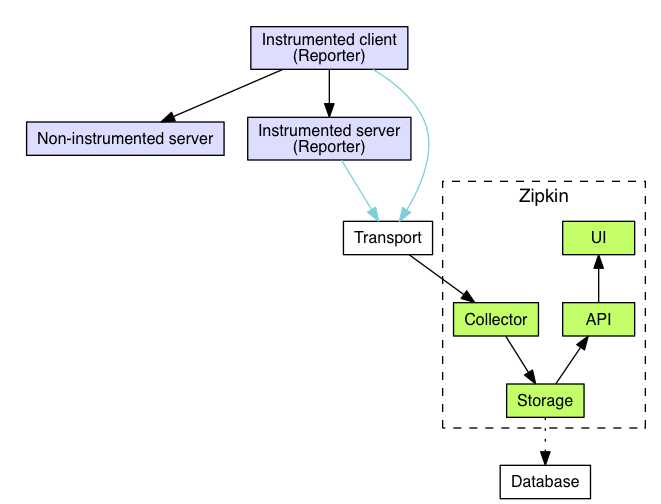
跟踪器(Tracer)位于你的应用程序中,并记录发生的操作的时间和元数据,提供了相应的类库,对用户的使用来说是透明的,收集的跟踪数据称为Span;
将数据发送到Zipkin的仪器化应用程序中的组件称为Reporter,Reporter通过几种传输方式之一将追踪数据发送到Zipkin收集器(collector),
然后将跟踪数据进行存储(storage),由API查询存储以向UI提供数据。
架构图如下:
1.Trace
Zipkin使用Trace结构表示对一次请求的跟踪,一次请求可能由后台的若干服务负责处理,每个服务的处理是一个Span,Span之间有依赖关系,Trace就是树结构的Span集合;
2.Span
每个服务的处理跟踪是一个Span,可以理解为一个基本的工作单元,包含了一些描述信息:id,parentId,name,timestamp,duration,annotations等,例如:
{ "traceId": "bd7a977555f6b982", "name": "get-traces", "id": "ebf33e1a81dc6f71", "parentId": "bd7a977555f6b982", "timestamp": 1458702548478000, "duration": 354374, "annotations": [ { "endpoint": { "serviceName": "zipkin-query", "ipv4": "192.168.1.2", "port": 9411 }, "timestamp": 1458702548786000, "value": "cs" } ], "binaryAnnotations": [ { "key": "lc", "value": "JDBCSpanStore", "endpoint": { "serviceName": "zipkin-query", "ipv4": "192.168.1.2", "port": 9411 } } ] }
traceId:标记一次请求的跟踪,相关的Spans都有相同的traceId;
id:span id;
name:span的名称,一般是接口方法的名称;
parentId:可选的id,当前Span的父Span id,通过parentId来保证Span之间的依赖关系,如果没有parentId,表示当前Span为根Span;
timestamp:Span创建时的时间戳,使用的单位是微秒(而不是毫秒),所有时间戳都有错误,包括主机之间的时钟偏差以及时间服务重新设置时钟的可能性,
出于这个原因,Span应尽可能记录其duration;
duration:持续时间使用的单位是微秒(而不是毫秒);
annotations:注释用于及时记录事件;有一组核心注释用于定义RPC请求的开始和结束;
cs:Client Send,客户端发起请求;
sr:Server Receive,服务器接受请求,开始处理;
ss:Server Send,服务器完成处理,给客户端应答;
cr:Client Receive,客户端接受应答从服务器;
binaryAnnotations:二进制注释,旨在提供有关RPC的额外信息。
3.Transport
收集的Spans必须从被追踪的服务运输到Zipkin collector,有三个主要的传输方式:HTTP, Kafka和Scribe;
4.Components
有4个组件组成Zipkin:collector,storage,search,web UI
- collector:一旦跟踪数据到达Zipkin collector守护进程,它将被验证,存储和索引,以供Zipkin收集器查找;
- storage:Zipkin最初数据存储在Cassandra上,因为Cassandra是可扩展的,具有灵活的模式,并在Twitter中大量使用;但是这个组件可插入,除了Cassandra之外,还支持ElasticSearch和mysql;
- search:一旦数据被存储和索引,我们需要一种方法来提取它。查询守护进程提供了一个简单的JSON API来查找和检索跟踪,主要给Web UI使用;
- web UI:创建了一个GUI,为查看痕迹提供了一个很好的界面;Web UI提供了一种基于服务,时间和注释查看跟踪的方法。
三、Spring-boot中集成Zipkin示例
以上是关于调用链系列Zipkin搭建Spring-boot集承的主要内容,如果未能解决你的问题,请参考以下文章
深入探究ZIPKIN调用链跟踪——拓扑Dependencies篇