JavaSE——转换流和缓冲流
Posted BU_L
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JavaSE——转换流和缓冲流相关的知识,希望对你有一定的参考价值。
转换流:
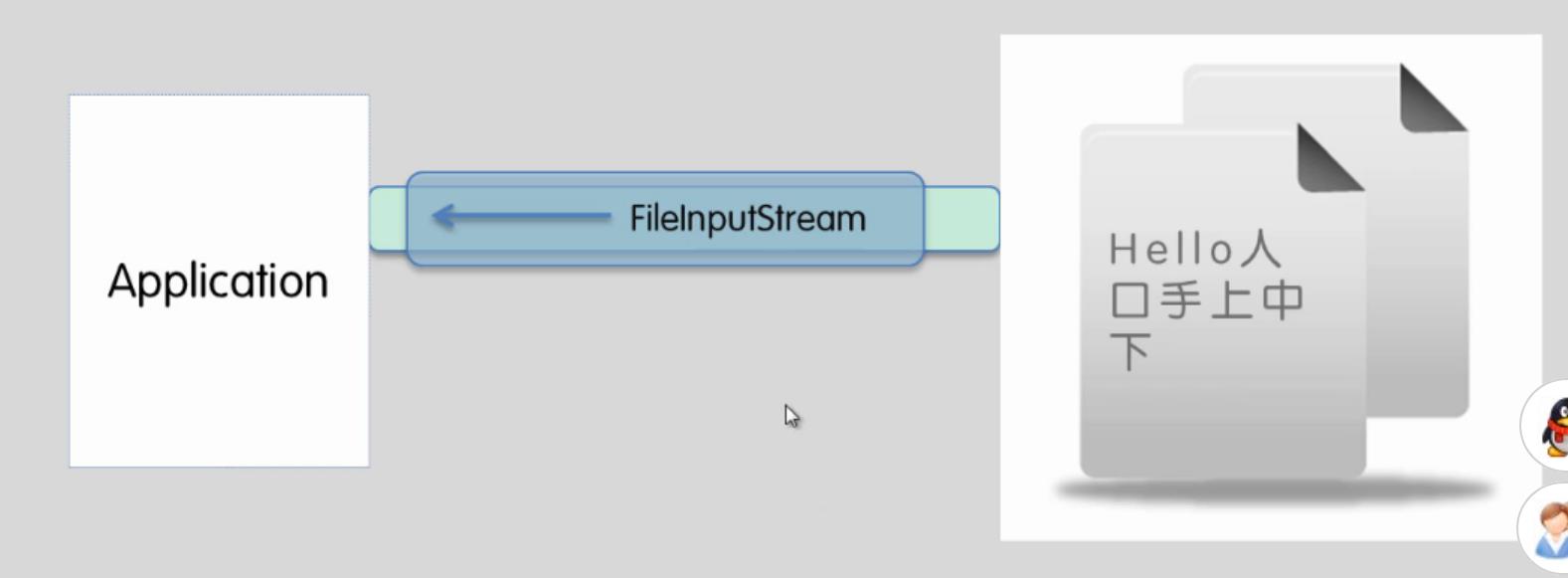
类 InputStreamReader(字符输入转换流):
InputStream 即读取字节流,Reader 为读取字符流。
InputStreamReader将字节流转换成字符流。便于一次读取更多字节。
InputStreamReader 是字节流通向字符流的桥梁:它使用指定的 charset
每次调用 InputStreamReader 中的一个 read() 方法都会导致从底层输入流读取一个或多个字节。要启用从字节到字符的有效转换,可以提前从底层流读取更多的字节,使其超过满足当前读取操作所需的字节。
为了达到最高效率,可要考虑在 BufferedReader 内包装 InputStreamReader。例如:
BufferedReader in = new BufferedReader(new InputStreamReader(System.in));

一些常用方法:
void |
close() 关闭该流并释放与之关联的所有资源。 |
String |
getEncoding() 返回此流使用的字符编码的名称。 |
int |
read() 读取单个字符。 |
int |
read(char[] cbuf, int offset, int length) 将字符读入数组中的某一部分。 |
boolean |
ready() 判断此流是否已经准备好用于读取。 |
缓冲流:

类 BufferdReader:
从字符输入流中读取文本,缓冲各个字符,从而实现字符、数组和行的高效读取。
可以指定缓冲区的大小,或者可使用默认的大小。大多数情况下,默认值就足够大了。

一些常用方法:
void |
close() 关闭该流并释放与之关联的所有资源。 |
void |
mark(int readAheadLimit) 标记流中的当前位置。 |
boolean |
markSupported() 判断此流是否支持 mark() 操作(它一定支持)。 |
int |
read() 读取单个字符。 |
int |
read(char[] cbuf, int off, int len) 将字符读入数组的某一部分。 |
String |
readLine() 读取一个文本行。 |
package xulieh; import java.io.BufferedWriter; import java.io.FileWriter; import java.io.IOException; public class Demo01 { public static void main(String[]args){ Person person = new Person("张三", 20, "火星"); String content = person.getName()+"-"+person.getAge()+"-"+person.getAddress(); BufferedWriter bw = null; try { bw = new BufferedWriter(new FileWriter("D:/person.dat")); bw.write(content); bw.flush(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); }finally{ try { bw.close(); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } } }
类 OutputStreamWriter:
字符输出转换流,即将字符流转换成字节流。

OutputStreamWriter 是字符流通向字节流的桥梁:可使用指定的 charset
每次调用 write() 方法都会导致在给定字符(或字符集)上调用编码转换器。在写入底层输出流之前,得到的这些字节将在缓冲区中累积。可以指定此缓冲区的大小,不过,默认的缓冲区对多数用途来说已足够大。注意,传递给 write() 方法的字符没有缓冲。
为了获得最高效率,可考虑将 OutputStreamWriter 包装到 BufferedWriter 中,以避免频繁调用转换器。例如:
Writer out = new BufferedWriter(new OutputStreamWriter(System.out));
类 BufferedWriter:
输出缓冲流。

将文本写入字符输出流,缓冲各个字符,从而提供单个字符、数组和字符串的高效写入。
可以指定缓冲区的大小,或者接受默认的大小。在大多数情况下,默认值就足够大了。
该类提供了 newLine() 方法,它使用平台自己的行分隔符概念,此概念由系统属性 line.separator 定义。并非所有平台都使用新行符 (\'\\n\') 来终止各行。因此调用此方法来终止每个输出行要优于直接写入新行符。
通常 Writer 将其输出立即发送到底层字符或字节流。除非要求提示输出,否则建议用 BufferedWriter 包装所有其 write() 操作可能开销很高的 Writer(如 FileWriters 和 OutputStreamWriters)。例如,
PrintWriter out
= new PrintWriter(new BufferedWriter(new FileWriter("foo.out")));
//将写入的字符流写入字符输出流缓冲各个字符,提供单个字符的高效写入。
将缓冲 PrintWriter(处理流,能对字节流和字符流处理) 对文件的输出。如果没有缓冲,则每次调用 print() 方法会导致将字符转换为字节,然后立即写入到文件,而这是极其低效的。
需要注意的是,Reader 即读,对于应用或者文件来说,表示的是输入,Writer则表示的是输出。
为什么要用转换流?
1. InputStream 和OutputStream,两个是为字节流设计的,主要用来处理字节或二进制对象,
2. Reader和 Writer.两个是为字符流(一个字符占两个字节)设计的,主要用来处理字符或字符串.
字符流处理的单元为2个字节的Unicode字符,分别操作字符、字符数组或字符串,而字节流处理单元为1个字节,操作字节和字节数组。所以字符流是由Java虚拟机将字节转化为2个字节的Unicode字符为单位的字符而成的,所以它对多国语言支持性比较好!如果是音频文件、图片、歌曲,就用字节流好点,如果是关系到中文(文本)的,用字符流好点
所有文件的储存是都是字节(byte)的储存,在磁盘上保留的并不是文件的字符而是先把字符编码成字节,再储存这些字节到磁盘。在读取文件(特别是文本文件)时,也是一个字节一个字节地读取以形成字节序列
字节流可用于任何类型的对象,包括二进制对象,而字符流只能处理字符或者字符串;
2,字节流提供了处理任何类型的IO操作的功能,但它不能直接处理Unicode字符,而字符流就可以
字节流是最基本的,所有的InputStrem和OutputStream的子类都是,主要用在处理二进制数据,它是按字节来处理的 但实际中很多的数据是文本,又提出了字符流的概念,它是按虚拟机的encode来处理,也就是要进行字符集的转化 这两个之间通过 InputStreamReader,OutputStreamWriter来关联,实际上是通过byte[]和String来关联 在实际开发中出现的汉字问题实际上都是在字符流和字节流之间转化不统一而造成的.
为什么要使用缓冲流?
我们用的InputStream类等是字节流,而FileReader等类都只是字符流,它们对数据操作时不会起到缓冲作用。这些类读写数据时,每进行一次操作都会去访问一次文件,这样效率自然就会很低。所谓缓冲其实就是,缓冲包装类会在你进行读写操作之前,读入一批数据。然后进行读写操作时直接从缓冲区取数据(访问缓冲区),当缓冲区的数据操作完毕时才再次读取文件。其实,缓冲类的作用就跟电脑内存条的作用是一样的。
流的读取和传输都需要时间,如果一次性读取一个字节或者字符就发送到服务器,必定没有一次读取多个字节和字符然后发送到服务器高效。
以上是关于JavaSE——转换流和缓冲流的主要内容,如果未能解决你的问题,请参考以下文章