mybatis 解析配置文件之XML的DOM解析方式
Posted 阿进的写字台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mybatis 解析配置文件之XML的DOM解析方式相关的知识,希望对你有一定的参考价值。
简介
在之前的文章《mybatis 初步使用(IDEA的Maven项目, 超详细)》中, 讲解了mybatis的初步使用, 并总结了以下mybatis的执行流程:
- 通过 Resources 工具类读取 mybatis-config.xml, 存入 Reader;
- SqlSessionFactoryBuilder使用上一步获得的reader创建SqlSessionFactory对象;
- 通过 sqlSessionFactory 对象获得SqlSession;
- SqlSession对象通过selectList方法找到对应的“selectAll”语句, 执行SQL查询。
- 底层通过 JDBC 查询后获得ResultSet, 对每一条记录, 根据resultMap的映射结果映射到Student中, 返回List。
- 最后记得关闭 SqlSession
本系列文章深入讲解第 2 步, 解析配置文件。
Java 中 XML 文件解析
mybatis是基于 XML 来进行配置的, 因此, 我们首先要知道在Java中, XML是如何解析的。
解析方式
XML 常见的解析方式有以下三种: DOM、 SAX 和 StAX。
1. DOM 方式
DOM 基于树形结构解析, 它会将整个文档读入内存并构建一个 DOM 树, 基于这棵树的结构对各个节点进行解析。
2. SAX 方式
SAX 是基于事件模型的 XML 解析方式, 它不需要将整个 XML 文档加载到内存中, 而只需要将一部分 XML 文档的一部分加载到内存中, 即可开始解析。
3. StAX 方式
StAX 与 SAX 类似, 也是把 XML 文档作为一个事件流进行处理, 但不同之处在于 StAX 采用的是“拉模式”, 即应用程序通过调用解析器推进解析的过程。
DOM 解析 XML
在加载 mybatis-config.xml 配置文件与映射文件时, 使用的是 DOM 解析方式, 并配合使用 XPath 解析 XML 配置文件。
XPath 之于 XML 就好比 SQL 之于数据库。
所谓DOM, 是 Document Object Model 的缩写, 翻译过来就是文档对象模型。
下面我们就来展示一下该过程。
新建 XML 文件
<CATALOG>
<CD id="1">
<TITLE>Empire Burlesque</TITLE>
<ARTIST>Bob Dylan</ARTIST>
<COUNTRY>USA</COUNTRY>
<COMPANY>Columbia</COMPANY>
<PRICE>10.90</PRICE>
<YEAR>1985</YEAR>
</CD>
<CD id="2">
<TITLE>Hide your heart</TITLE>
<ARTIST>Bonnie Tyler</ARTIST>
<COUNTRY>UK</COUNTRY>
<COMPANY>CBS Records</COMPANY>
<PRICE>9.90</PRICE>
<YEAR>1988</YEAR>
</CD>
<CD id="3">
<TITLE>Greatest Hits</TITLE>
<ARTIST>Dolly Parton</ARTIST>
<COUNTRY>USA</COUNTRY>
<COMPANY>RCA</COMPANY>
<PRICE>9.90</PRICE>
<YEAR>1982</YEAR>
</CD>
<CD id="4">
<TITLE>Still got the blues</TITLE>
<ARTIST>Gary Moore</ARTIST>
<COUNTRY>UK</COUNTRY>
<COMPANY>Virgin records</COMPANY>
<PRICE>10.20</PRICE>
<YEAR>1990</YEAR>
</CD>
<CD id="5">
<TITLE>Eros</TITLE>
<ARTIST>Eros Ramazzotti</ARTIST>
<COUNTRY>EU</COUNTRY>
<COMPANY>BMG</COMPANY>
<PRICE>9.90</PRICE>
<YEAR>1997</YEAR>
</CD>
</CATALOG>在CATALOG中, 有很多CD, CD有着自己的子节点。
DOM 操作相关类
以上的XML, 其对应的树形结构如下:
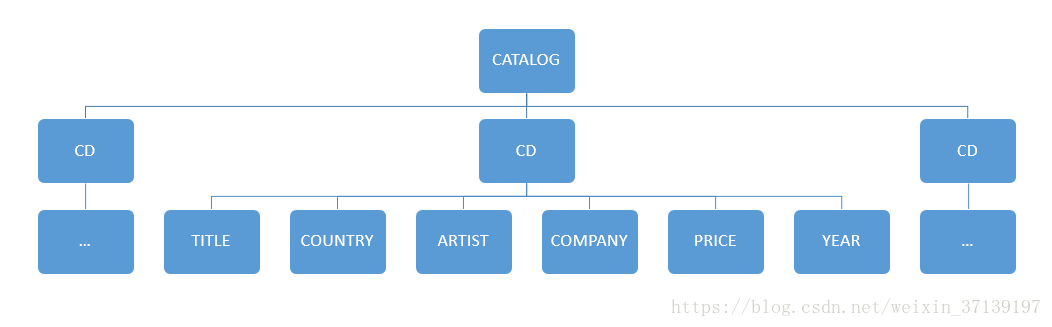
而在Java中, 有很节点类型, 以下有几个主要的接口对应着XML中的各个属性。
- Node : DOM最基本的数据类型。 表示文档树中的单个节点
- Element:常见的元素节点
- Attr:代表元素的属性
- Text:元素或者Att的值(内容)
- Document:代表整个XML文档
Java 读取 XML 文件
public static void main(String[] args) throws ParserConfigurationException, IOException, SAXException, XPathExpressionException {
// 获取 DocumentBuilderFactory
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
builderFactory.setValidating(false);
builderFactory.setNamespaceAware(false);
builderFactory.setIgnoringComments(true);
builderFactory.setIgnoringElementContentWhitespace(false);
builderFactory.setCoalescing(false);
builderFactory.setExpandEntityReferences(true);
// 通过 DocumentBuilderFactory 获取 DocumentBuilder
DocumentBuilder builder = builderFactory.newDocumentBuilder();
builder.setErrorHandler(new ErrorHandler() {
@Override
public void warning(SAXParseException exception) throws SAXException {
System.out.println("warning:"+exception.getMessage());
}
@Override
public void error(SAXParseException exception) throws SAXException {
System.out.println("error:"+exception.getMessage());
}
@Override
public void fatalError(SAXParseException exception) throws SAXException {
System.out.println("fatalError:"+exception.getMessage());
}
});
// 得到Document文件, 就是XML在JVM中的化身
InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("xml/cds.xml");
Document document = builder.parse(is);
// 以下通过 XPath 来获取对应的信息
XPathFactory xPathFactory = XPathFactory.newInstance();
XPath xPath = xPathFactory.newXPath();
// 解析 //CD//TITLE//text() , 就是获取所有CD节点下TITLE子节点的文字内容
XPathExpression expression = xPath.compile("//CD//TITLE//text()");
Object result = expression.evaluate(document, XPathConstants.NODESET);
NodeList nodeList = (NodeList)result;
for (int i = 0; i < nodeList.getLength(); i++) {
System.out.println(nodeList.item(i).getNodeValue());
}
}其主要步骤:
- 创建
DocumentBuilderFactory对象; - 通过
DocumentBuilderFactory创建DocumentBuilder对象; - 通过
DocumentBuilder, 从文件或流中创建通过Document对象; - 创建
XPathFactory对象, 并通过XPathFactory创建XPath对象; - 通过
XPath解析出XPathExpression对象; - 使用
XPathExpression在文档中搜索出相应的节点。
输出结果如下:

也可以调用相应的 API 进行获取和设置各个属性, 再次就不过多的进行深入。
以上是关于mybatis 解析配置文件之XML的DOM解析方式的主要内容,如果未能解决你的问题,请参考以下文章