java基础71 XML解析相关知识点(网页知识)
Posted DSHORE
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java基础71 XML解析相关知识点(网页知识)相关的知识,希望对你有一定的参考价值。
本文知识点(目录):本文下面的“实例及附录”全是DOM解析的相关内容
1、xml解析的含义
2、XML的解析方式
3、xml的解析工具
4、XML的解析原理
5、实例
6、附录1(获取xml中的所有节点、根标签、根标签下的子标签、子标签中的文本内容)
7、附录2(获取xml中的所有节点、根标签、根标签下的子标签、子标签中的文本内容)
8、附录3(把xml文档中的信息封装到对象中)
1、xml解析的含义
xml文件除了给开发者看,更多情况下是使用程序读取xml文件中的内容
2、XML的解析方式
DOM解析
SAX解析
3、xml的解析工具
3.1、DOM解析工具
1.JAXP(oracle-Sun公司官方)
2.JDOM工具(非官方)
3.Dom4j工具(非官方的)。 三大框架(默认读取xml的工具就是DOM4j)
3.2、SAX解析工具
1.Sax解析工具(oracle-Sun公司官方)
4、XML的解析原理
4.1、DOM解析的原理
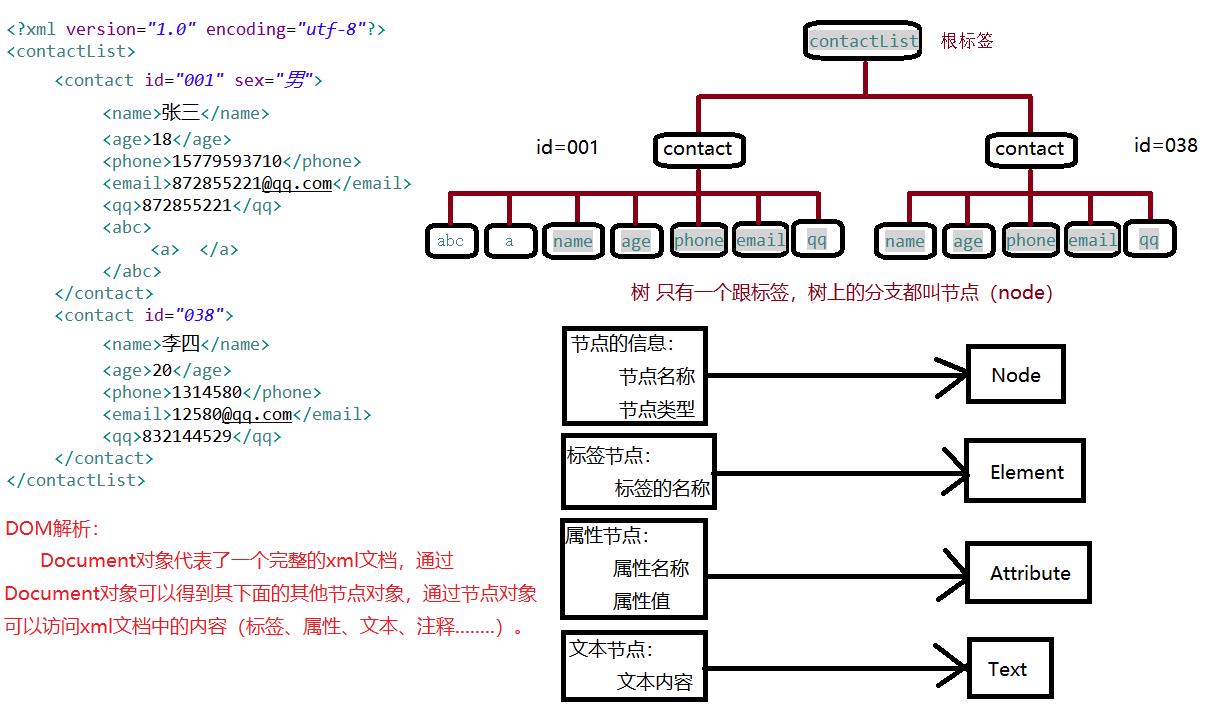
xml解析器一次性把整个xml文档加载进内存,然后在内存中构建一个Document的对象树,通过document对象,得到树上的节点对象,通过节点对象访问(操作)到xml文档的内容.
缺点:内存消耗大
优点:文档增删改查比较容易
4.2、SAX解析的原理
从上往下读,读一行处理一行。 DOM与SAX解析的区别 SAX解析原理
优点:内存消耗小,适合读
缺点:不适合增删改
5、实例
例1:
1 package com.bw.test; 2 3 import org.dom4j.Document; 4 import org.dom4j.DocumentException; 5 import org.dom4j.io.SAXReader; 6 7 public class Demo1 { 8 /* 9 * 第一个Dom4j读取xml文档的例子 10 * 11 * */ 12 public static void main(String[] args) { 13 try { 14 //1.创建一个xml解析器对象 15 SAXReader reader = new SAXReader(); 16 //2.读取xml文档,返回Document对象 17 Document doc= reader.read("./src/contact.xml"); 18 System.out.println(doc); 19 } catch (DocumentException e) { 20 // TODO Auto-generated catch block 21 e.printStackTrace(); 22 } 23 } 24 }
contact.xml文件
1 <?xml version="1.0" encoding="utf-8"?> 2 <contactList> 3 <contact id="001" sex="男"> 4 <name>张三</name> 5 <age>18</age> 6 <phone>15779593710</phone> 7 <email>872855221@qq.com</email> 8 <qq>872855221</qq> 9 <abc> 10 <a><b></b></a> 11 </abc> 12 </contact> 13 <contact id="038"> 14 <name>李四</name> 15 <age>20</age> 16 <phone>1314580</phone> 17 <email>12580@qq.com</email> 18 <qq>832144529</qq> 19 </contact> 20 </contactList>
例2:
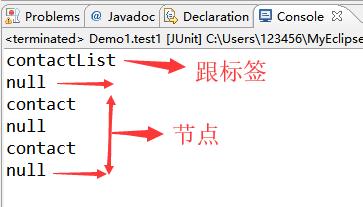
1 package com.shore.test; 2 3 import java.io.File; 4 import java.util.Iterator; 5 import java.util.List; 6 7 import org.dom4j.Document; 8 import org.dom4j.DocumentException; 9 import org.dom4j.Element; 10 import org.dom4j.Node; 11 import org.dom4j.io.SAXReader; 12 import org.junit.Test; 13 14 /** 15 * @author DSHORE / 2018-8-29 16 * 17 */ 18 public class Demo1 { 19 @Test 20 public void test1() throws DocumentException{ 21 //1.读取xml文档,返回一个document对象 22 SAXReader reader=new SAXReader(); 23 Document doc=reader.read(new File("./src/contact.xml")); 24 //nodeIterator:得到当前节点下的所有子节点对象(不包含孙以及孙以下的节点) 25 Iterator<Node> it=doc.nodeIterator(); 26 while(it.hasNext()){//判断是否有下一位元素 27 Node node=it.next(); 28 System.out.println(node.getName()); 29 //继续获取下面的子节点 30 //只有标签有子节点 31 //判断当前节点是否为标签节点 32 if(node instanceof Element){ 33 Element elem=(Element)node; 34 Iterator<Node> it2=elem.nodeIterator(); 35 while(it2.hasNext()){ 36 Node n2=it2.next(); 37 System.out.println(n2.getName()); 38 } 39 } 40 } 41 } 42 }
实例结果图
附录1
1 package com.shore.test; 2 3 import java.io.File; 4 import java.util.Iterator; 5 import java.util.List; 6 7 import org.dom4j.Attribute; 8 import org.dom4j.Document; 9 import org.dom4j.DocumentException; 10 import org.dom4j.Element; 11 import org.dom4j.Node; 12 import org.dom4j.io.SAXReader; 13 import org.junit.Test; 14 15 /** 16 * @author DSHORE / 2018-8-29 17 * 18 */ 19 /* 20 * 第二个dom4j读取的xml文件内容 21 * 节点 22 * 标签 23 * 属性 24 * 文本 25 * */ 26 public class Demo1 { 27 @Test 28 public void test1() throws DocumentException{ 29 //1.读取xml文档,返回一个document对象 30 SAXReader reader=new SAXReader(); 31 Document doc=reader.read(new File("./src/contact.xml")); 32 //nodeIterator:得到当前节点下的所有子节点对象(不包含孙以及孙以下的节点) 33 Iterator<Node> it=doc.nodeIterator(); 34 while(it.hasNext()){//判断是否有下一位元素 35 Node node=it.next(); 36 System.out.println(node.getName()); 37 //继续获取下面的子节点 38 //只有标签有子节点 39 //判断当前节点是否为标签节点 40 if(node instanceof Element){ 41 Element elem=(Element)node; 42 Iterator<Node> it2=elem.nodeIterator(); 43 while(it2.hasNext()){ 44 Node n2=it2.next(); 45 System.out.println(n2.getName()); 46 } 47 } 48 } 49 } 50 /* 51 * 遍历xml文件的所有节点 52 * */ 53 @Test 54 public void test2() throws DocumentException{ 55 //1.读取xml文档获取Document对象 56 SAXReader reader=new SAXReader(); 57 Document doc=reader.read(new File("./src/contact.xml")); 58 //得到跟标签 59 Element rootEls=doc.getRootElement(); 60 getChildNodes(rootEls); 61 } 62 /* 63 * 获取传入标签下的所有子标签 64 * */ 65 private void getChildNodes(Element rootEls) { 66 if(rootEls instanceof Element){ 67 System.out.println(rootEls.getName()); 68 } 69 //得到子节点 70 Iterator<Node> it=rootEls.nodeIterator(); 71 while(it.hasNext()){ 72 Node node=it.next(); 73 //判断是否是标签节点 74 if(node instanceof Element){ 75 Element el=(Element)node; 76 //递归 77 getChildNodes(el); 78 } 79 } 80 } 81 /* 82 * 获取标签 83 * */ 84 @Test 85 public void test3() throws DocumentException{ 86 //1.读取xml文档,返回Document对象 87 SAXReader reader=new SAXReader(); 88 Document doc=reader.read(new File("./src/contact.xml")); 89 //得到跟标签 90 Element elt=doc.getRootElement(); 91 //得到标签名称 92 String name=elt.getName(); 93 System.out.println(name);//返回值:contactList 94 95 //方法1:得到当前标签下指定的名称的第一个子标签 96 Element contactElem=elt.element("contact"); 97 String name1=contactElem.getName(); 98 System.out.println(name1);//返回值:contact 99 100 //方法2:得到当前根标签下的所有下一级子标签 101 List<Element> list=elt.elements(); 102 //遍历list 103 //1).传统的for循环 2).增强for循环 3).迭代器 104 for(int i=0;i<list.size();i++){ 105 Element e=list.get(i); 106 System.out.println(e.getName());//返回值:contact 注意:这里的返回值是有两个contact,因为contact.xml文件中有两个根标签的下一级标签contact(两个contact是同一级) 107 } 108 for (Element e : list) {//增强for循环 109 System.out.println(e.getName());//返回值:contact 同上 110 } 111 Iterator<Element> it=list.iterator(); 112 while(it.hasNext()){//迭代器 113 Element e=it.next(); 114 System.out.println(e.getName());//返回值:contact 同上 115 } 116 117 //方法3:获取更深层次标签(方法只能一层层地获取) 118 Element element=doc.getRootElement().element("contact").element("name"); 119 System.out.println(element.getName());//返回值:name 120 } 121 /* 122 * 获取属性值 123 * */ 124 @Test 125 public void test4() throws DocumentException{ 126 //1.读取xml文档,返回一个Document对象 127 SAXReader reader=new SAXReader(); 128 Document doc=reader.read(new File("./src/contact.xml")); 129 //获取属性(先获取标签对象,然后在获取属性) 130 //获得标签对象 131 Element contactElt=doc.getRootElement().element("contact"); 132 //获取属性,得到指定名称属性值 133 String idValue=contactElt.attributeValue("id"); 134 System.out.println(idValue);//返回值:001 135 //得到指定属性名称的属性对象 136 Attribute idAttr=contactElt.attribute("id"); 137 //getName()属性名 getValue属性值 138 System.out.println(idAttr.getName()+"/"+idAttr.getValue());//返回值:id/001 139 } 140 }
结果图
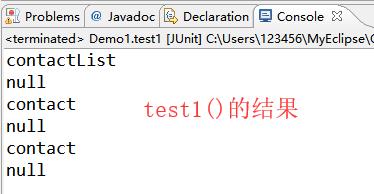
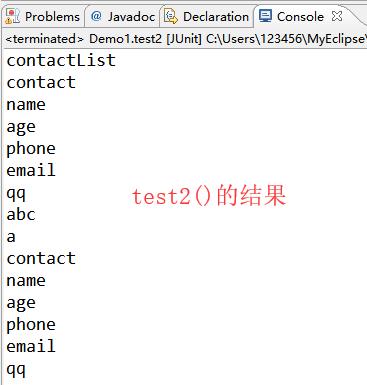
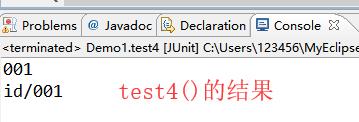
注:test3()的结果,看代码中的注释
附录2
1 package com.shore.test; 2 3 import java.io.File; 4 import java.util.Iterator; 5 import java.util.List; 6 7 import org.dom4j.Attribute; 8 import org.dom4j.Document; 9 import org.dom4j.DocumentException; 10 import org.dom4j.Element; 11 import org.dom4j.io.SAXReader; 12 import org.junit.Test; 13 /** 14 * @author DSHORE / 2018-8-29 15 * 16 */ 17 18 public class Demo2 { 19 /* 20 * 获取属性 21 * */ 22 @Test 23 public void test() throws DocumentException{ 24 //1.解析xml文档,返回一个document对象 25 Document doc=new SAXReader().read(new File("./src/contact.xml")); 26 //获取属性:(先获取属性所在标签对象,然后才能获取属性值) 27 //2.得到标签 28 Element elt=doc.getRootElement().element("contact"); 29 //3.得到属性 30 //得到指定名称的属性值 31 String idValue=elt.attributeValue("id"); 32 System.out.println(idValue);//返回值:001 33 //得到指定名称的属性对象 34 Attribute aib=elt.attribute("id"); 35 //getName() 属性名称 getValue()属性值 36 System.out.println("属性名称:"+aib.getName()+"/"+"属性值:"+aib.getValue());//返回值:属性名称:id/属性值:001 37 38 //方式1:得到所有属性对象,返回一个list() 39 List<Attribute> list=elt.attributes(); 40 for (Attribute attr: list) { 41 System.out.println(attr.getName());//返回值:id/001 sex/男 42 } 43 44 //方式2:得到所有属性对象,返回一个迭代器 45 Iterator<Attribute> attr2=elt.attributeIterator(); 46 while(attr2.hasNext()){ 47 Attribute a=attr2.next(); 48 System.out.println(a.getName()+"/"+a.getValue());//返回值:id/001 sex/男 49 } 50 } 51 /* 52 * 获取文本内容 53 * */ 54 @Test 55 public void test2() throws DocumentException{ 56 //1.解析xml文档,返回一个document对象 57 Document doc=new SAXReader().read(new File("./src/contact.xml")); 58 /* 59 * 注意:空格和换行也是xml的内容 60 * */ 61 String content=doc.getRootElement().getText(); 62 //获取文本内容(先获取标签,在获取标签上的内容) 63 Element elt=doc.getRootElement().element("contact").element("name"); 64 //方式1:得到文本内容 65 String test=elt.getText(); 66 System.out.println(test);//返回值:张三 67 68 //方式2:得到指定标签的文本内容 69 String test2=doc.getRootElement().element("contact").elementText("phone"); 70 System.out.println(test2); //返回值:15779593710 71 } 72 }
附录3
contact.xml文件
1 <?xml version="1.0" encoding="utf-8"?> 2 <contactList> 3 <contact id="001" sex="男"> 4 <name>张三</name> 5 <age>18</age> 6 <phone>15779593710</phone> 7 <email>872855221@qq.com</email> 8 <qq>872855221</qq> 9 <abc> 10 <a> </a> 11 </abc> 12 </contact> 13 <contact id="038"> 14 <name>李四</name> 15 <age>20</age> 16 <phone>1314580</phone> 17 <email>12580@qq.com</email> 18 <qq>832144529</qq> 19 </contact> 20 </contactList>
Contact实体(模型)
1 package com.shore.test; 2 3 /** 4 * @author DSHORE / 2018-8-29 5 * 6 */ 7 public class Contact { 8 private String id; 9 private String name; 10 private String age; 11 private String phone; 12 private String email; 13 private String qq; 14 15 public以上是关于java基础71 XML解析相关知识点(网页知识)的主要内容,如果未能解决你的问题,请参考以下文章