Java ExecutorService四种线程池的简单使用
Posted Qiao_Zhi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java ExecutorService四种线程池的简单使用相关的知识,希望对你有一定的参考价值。
我们都知道创建一个线程可以继承Thread类或者实现Runnable接口,实际Thread类就是实现了Runnable接口。
到今天才明白后端线程的作用:我们可以开启线程去执行一些比较耗时的操作,类似于前台的ajax异步操作,比如说用户上传一个大的文件,我们可以获取到文件之后开启一个线程去操作该文件,但是可以提前将结果返回去,如果同步处理有可能太耗时,影响系统可用性。
1、new Thread的弊端
原生的开启线程执行异步任务的方式:
new Thread(new Runnable() { @Override public void run() { // TODO Auto-generated method stub } }).start();
弊端如下:
- 线程生命周期的开销非常高。创建线程都会需要时间,延迟处理的请求,并且需要JVM和操作系统提供一些辅助操作。
- 资源消耗。活跃的线程会消耗系统资源,尤其是内存。如果可运行的线程数量多于可用处理器的数量,那么有些线程将会闲置。大量空闲的线程会占用许多内存,给GC带来压力,而且大量线程在竞争CPU资源时会产生其他的性能开销。
- 稳定性。在可创建线程的数量上存在一个限制,这个限制受多个因素的制约,包括JVM的启动参数、Thread构造函数中请求栈的大小以及底层操作系统的限制。如果破坏了这些限制,很可能抛出 outOfMemoryError异常。
也就是说在一定的范围内增加线程的数量可以提高系统的吞吐率,但是如果超出了这个范围,再创建更多的线程只会降低程序的执行效率甚至导致系统的崩溃。
例如:
使用线程池:可以了解线程池的用法以及线程池的正确的关闭方法:shutdown之后马上调用awaitTermination阻塞等待实现同步关闭。
package cn.qlq.thread.twenty; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.TimeUnit; import java.util.concurrent.atomic.AtomicInteger; public class Demo1 { private static ExecutorService executorService = Executors.newFixedThreadPool(20); private static volatile AtomicInteger atomicInteger = new AtomicInteger(0); public static void main(String[] args) { long startTime = System.currentTimeMillis(); for (int i = 0; i < 2000; i++) { executorService.execute(new Runnable() { @Override public void run() { atomicInteger.incrementAndGet(); } }); } executorService.shutdown(); try { executorService.awaitTermination(1, TimeUnit.DAYS); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(System.currentTimeMillis() - startTime); System.out.println(atomicInteger); } }
结果:
14
2000
package cn.qlq.thread.twenty; import java.util.concurrent.atomic.AtomicInteger; public class Demo2 { private static volatile AtomicInteger atomicInteger = new AtomicInteger(0); public static void main(String[] args) { long startTime = System.currentTimeMillis(); for (int i = 0; i < 2000; i++) { Thread t = new Thread(new Runnable() { @Override public void run() { atomicInteger.incrementAndGet(); } }); t.start(); try { t.join(); } catch (InterruptedException e) { e.printStackTrace(); } } System.out.println(System.currentTimeMillis() - startTime); System.out.println(atomicInteger); } }
结果:
257
2000
不使用线程池话费的时间比使用线程池长了好几倍,也看出了效率问题。
2.核心类结构如下:

1、Executor是一个顶级接口,它提供了一种标准的方法将任务的提交过程与执行过程解耦开来,并用Runnable来表示任务。
2、ExecutorService扩展了Executor。添加了一些用于生命周期管理的方法(同时还提供一些用于任务提交的便利方法
3、下面两个分支,AbstractExecutorService分支就是普通的线程池分支,ScheduledExecutorService是用来创建定时任务的。
3.Executor介绍
线程池简化了线程的管理工作。在Java类库中,任务执行的主要抽象不是Thread,而是Executor,如下:
public interface Executor { void execute(Runnable command); }
Executor是个简单的接口,它提供了一种标准的方法将任务的提交过程与执行过程解耦开来,并用Runnable来表示任务。Executor还提供了对生命周期的支持,以及统计信息收集、应用程序管理机制和性能监视机制。
Executor基于"生产者-消费者"模式,提交任务的操作相当于生产者,执行任务的则相当于消费者。
生命周期:
Executor的实现通常会创建线程来执行任务。但JVM只有在所有非守护线程全部终止才会退出。因此,如果无法正确的关闭Executor,那么JVM将无法结束。ExecutorService扩展了Executor接口,添加了一些用于生命周期管理的方法(同时还提供一些用于任务提交的便利方法
package java.util.concurrent; import java.util.List; import java.util.Collection; import java.security.PrivilegedAction; import java.security.PrivilegedExceptionAction; public interface ExecutorService extends Executor { void shutdown(); List<Runnable> shutdownNow(); boolean isShutdown(); boolean isTerminated(); boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException; <T> Future<T> submit(Callable<T> task); <T> Future<T> submit(Runnable task, T result); Future<?> submit(Runnable task); <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException; <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException; <T> T invokeAny(Collection<? extends Callable<T>> tasks) throws InterruptedException, ExecutionException; <T> T invokeAny(Collection<? extends Callable<T>> tasks, long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException; }
ExecutorService的生命周期有三种:运行、关闭和已终止。ExecutorService在创建时处于运行状态。shutdown方法将执行平缓的关闭过程:不再接受新的任务,同时等待已经提交的任务执行完毕----包括还没开始的任务,这种属于正常关闭。shutdownNow方法将执行粗暴的关闭过程:它将取消所有运行中的任务,并且不再启动队列中尚未开始的任务,这种属于强行关闭(关闭当前正在执行的任务,然后返回所有尚未启动的任务清单)。
在ExecutorService关闭后提交的任务将由"拒绝执行处理器"来处理,它会抛弃任务,或者使得execute方法抛出一个RejectedExecutionException。等所有任务执行完成后,ExecutorService将转入终止状态。可以调用awaitTermination来等待ExecutorService到达终止状态,或者通过isTerminated来轮询ExecutorService是否已经终止。通常在调用shutdown之后会立即调用awaitTermination阻塞等待,从而产生同步地关闭ExecutorService的效果。
4.线程池--ThreadPoolExecutor
线程池,从字面意义上看,是指管理一组同构工作线程的资源池。线程池是与工作队列(work queue)密切相关的,其中在工作队列保存了所有等待执行的任务。工作者线程的任务很简单:从工作队列中获取一个任务并执行任务,然后返回线程池等待下一个任务。(线程池启动初期线程不会启动,有任务提交(调用execute或submit)才会启动,直到到达最大数量就不再创建而是进入阻塞队列)。
"在线程池中执行任务"比"为每一个任务分配一个线程"优势更多。通过重用现有的线程而不是创建新线程,可以处理多个请求时分摊在创建线程和销毁过程中产生的巨大开销。另外一个额外的好处是,当请求到达时,工作线程通常已经存在,因此不会由于创建线程而延迟任务的执行,从而提高了性能。
ThreadPoolExecutor为Executor提供了一些基本实现。ThreadPoolExecutor是一个灵活的、稳定的线程池,允许各种允许机制。ThreadPoolExecutor定义了很多构造函数,最常见的是下面这个:
/** * Creates a new {@code ThreadPoolExecutor} with the given initial * parameters. * * @param corePoolSize the number of threads to keep in the pool, even * if they are idle, unless {@code allowCoreThreadTimeOut} is set * @param maximumPoolSize the maximum number of threads to allow in the * pool * @param keepAliveTime when the number of threads is greater than * the core, this is the maximum time that excess idle threads * will wait for new tasks before terminating. * @param unit the time unit for the {@code keepAliveTime} argument * @param workQueue the queue to use for holding tasks before they are * executed. This queue will hold only the {@code Runnable} * tasks submitted by the {@code execute} method. * @param threadFactory the factory to use when the executor * creates a new thread * @param handler the handler to use when execution is blocked * because the thread bounds and queue capacities are reached * @throws IllegalArgumentException if one of the following holds:<br> * {@code corePoolSize < 0}<br> * {@code keepAliveTime < 0}<br> * {@code maximumPoolSize <= 0}<br> * {@code maximumPoolSize < corePoolSize} * @throws NullPointerException if {@code workQueue} * or {@code threadFactory} or {@code handler} is null */ public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null) throw new NullPointerException(); this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); this.threadFactory = threadFactory; this.handler = handler; }
1、corePoolSize
核心池的大小。在创建了线程池之后,默认情况下,线程池中没有任何线程,而是等待有任务到来才创建线程去执行任务。默认情况下,在创建了线程池之后,线程池钟的线程数为0,当有任务到来后就会创建一个线程去执行任务。只有在工作队列满了的情况下才会创建超出这个数量的线程。考虑到keepAliveTime和allowCoreThreadTimeOut超时参数的影响,所以没有任务需要执行的时候,线程池的大小不一定是corePoolSize。
2、maximumPoolSize
池中允许的最大线程数,这个参数表示了线程池中最多能创建的线程数量,当任务数量比corePoolSize大时,任务添加到workQueue,当workQueue满了,并且当前线程个数小于maximumPoolSize,将继续创建线程以处理任务,maximumPoolSize表示的就是wordQueue满了,线程池中最多可以创建的线程数量。
3、keepAliveTime
只有当线程池中的线程数大于corePoolSize时,这个参数才会起作用。当线程数大于corePoolSize时,终止前多余的空闲线程等待新任务的最长时间。
4、unit
keepAliveTime时间单位
5、workQueue
存储还没来得及执行的任务
6、threadFactory
执行程序创建新线程时使用的线程工厂
7、handler
由于超出线程范围和队列容量而使执行被阻塞时所使用的处理程序(拒绝执行处理器)
拒绝执行处理器实际上是定义了拒绝执行线程的行为:实际上也是一种饱和策略,当有界队列被填满后,饱和队列开始发挥作用。
public interface RejectedExecutionHandler { void rejectedExecution(Runnable r, ThreadPoolExecutor executor); }
在类库中定义了四种实现:
1. AbortPolicy-终止策略
直接抛出一个RejectedExecutionException,也是JDK默认的拒绝策略
public static class AbortPolicy implements RejectedExecutionHandler { public AbortPolicy() { } public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { throw new RejectedExecutionException("Task " + r.toString() + " rejected from " + e.toString()); } }
2.CallerRunsPolicy-调运者运行策略
如果线程池没有被关闭,就尝试执行任务。
public static class CallerRunsPolicy implements RejectedExecutionHandler { public CallerRunsPolicy() { } public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { if (!e.isShutdown()) { r.run(); } } }
3.DiscardOldestPolicy-抛弃最旧的策略
如果线程池没有关闭,就移除队列中最先进入的任务,并且尝试执行任务。
public static class DiscardOldestPolicy implements RejectedExecutionHandler { public DiscardOldestPolicy() { } public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { if (!e.isShutdown()) { e.getQueue().poll(); e.execute(r); } } }
4. DiscardPolicy-抛弃策略
什么也不做,安静的丢弃任务
public static class DiscardPolicy implements RejectedExecutionHandler { public DiscardPolicy() { } public void rejectedExecution(Runnable r, ThreadPoolExecutor e) { } }
补充:
线程池还有一个getPoolSize()方法,获取线程池中当前线程的数量,当该值为0的时候,意味着没有任何线程,线程池会终止;同一时刻,poolSize不会超过maximumPoolSize。源码如下:
/** * Returns the current number of threads in the pool. * * @return the number of threads */ public int getPoolSize() { final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { // Remove rare and surprising possibility of // isTerminated() && getPoolSize() > 0 return runStateAtLeast(ctl.get(), TIDYING) ? 0 : workers.size(); } finally { mainLock.unlock(); } }
新提交一个任务时的处理流程很明显:
1、如果当前线程池的线程数还没有达到基本大小(poolSize < corePoolSize),无论是否有空闲的线程新增一个线程处理新提交的任务;
2、如果当前线程池的线程数大于或等于基本大小(poolSize >= corePoolSize) 且任务队列未满时,就将新提交的任务提交到阻塞队列排队,等候处理workQueue.offer(command);
3、如果当前线程池的线程数大于或等于基本大小(poolSize >= corePoolSize) 且任务队列满时;
3.1、当前poolSize<maximumPoolSize,那么就新增线程来处理任务;
3.2、当前poolSize=maximumPoolSize,那么意味着线程池的处理能力已经达到了极限,此时需要拒绝新增加的任务。至于如何拒绝处理新增的任务,取决于线程池的饱和策略RejectedExecutionHandler。
补充:一个很好的例子解释
核心线程数10,最大线程数30,keepAliveTime是3秒
随着任务数量不断上升,线程池会不断的创建线程,直到到达核心线程数10,就不创建线程了,这时多余的任务通过加入阻塞队列来运行,当超出阻塞队列长度+核心线程数时,这时不得不扩大线程个数来满足当前任务的运行,这时就需要创建新的线程了(最大线程数起作用),上限是最大线程数30
那么超出核心线程数10并小于最大线程数30的可能新创建的这20个线程相当于是“借”的,如果这20个线程空闲时间超过keepAliveTime,就会被退出。
1、线程为什么会空闲
没有任务时线程就会空闲下来,在线程池中任务是任务(Runnale)线程是线程(Worker)
2、线程为什么要退出
通常超出核心线程的线程是“借”的,也就是说超出核心线程的情况算是一种能够预见的异常情况,并且这种情况并不常常发生(如果常常发生,那我想你应该调整你的核心线程数了),所以这种不经常发生而创建的线程为了避免资源浪费就应该要退出
另外,需要注意,keepAliveTime设置为0时是空闲线程直接退出
自己的测试例子如下:
package com.zd.bx; import java.util.concurrent.CountDownLatch; import java.util.concurrent.Executors; import java.util.concurrent.LinkedBlockingQueue; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.ThreadPoolExecutor.AbortPolicy; import java.util.concurrent.TimeUnit; public class PlainTest { private static volatile LinkedBlockingQueue<Runnable> linkedBlockingQueue = new LinkedBlockingQueue<Runnable>(5); public static void main(String[] args) throws InterruptedException { CountDownLatch countDownLatch = new CountDownLatch(1); final ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(2, 5, 2L, TimeUnit.MILLISECONDS, linkedBlockingQueue, Executors.defaultThreadFactory(), new AbortPolicy()); for (int i = 0; i < 16; i++) { Thread.sleep((1) * 1000); threadPoolExecutor.execute(new Runnable() { @Override public void run() { try { Thread.sleep(200 * 1000); System.out.println("threadName: " + Thread.currentThread().getName() + "\\t" + Thread.currentThread().isDaemon()); } catch (InterruptedException e) { e.printStackTrace(); } } }); int poolSize = threadPoolExecutor.getPoolSize(); int size = linkedBlockingQueue.size(); System.out.println("i:" + i + "\\tpoolSize:" + poolSize + "\\tlinkedBlockingQueueSize:" + size); } countDownLatch.await(); } }
结果:
i:0 poolSize:1 linkedBlockingQueueSize:0 i:1 poolSize:2 linkedBlockingQueueSize:0 i:2 poolSize:2 linkedBlockingQueueSize:1 i:3 poolSize:2 linkedBlockingQueueSize:2 i:4 poolSize:2 linkedBlockingQueueSize:3 i:5 poolSize:2 linkedBlockingQueueSize:4 i:6 poolSize:2 linkedBlockingQueueSize:5 i:7 poolSize:3 linkedBlockingQueueSize:5 i:8 poolSize:4 linkedBlockingQueueSize:5 i:9 poolSize:5 linkedBlockingQueueSize:5 Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task com.zd.bx.PlainTest$1@182decdb rejected from java.util.concurrent.ThreadPoolExecutor@2401f4c3[Running, pool size = 5, active threads = 5, queued tasks = 5, completed tasks = 0] at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063) at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830) at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379) at com.zd.bx.PlainTest.main(PlainTest.java:22)
可以看到: corePoolSize是2;maximumPoolSize是5;任务队列的大小是5。每个任务处理用时200s。
(1) i从0-1,是创建了两个线程,两个线程处理两个对应的任务,此时任务队列的任务数量为0
(2)i从2-6,这时候任务再次进来是添加到队列中,此时i=6之后队列刚满
(3)i从7-9.这是任务再进来,由于任务队列已满,并且poolSize < maximumPoolSize,所以说会继续创建线程数处理任务。此时线程数增加,队列中任务数不变。
(4)i从10开始继续加任务,此时队列已满,并且poolSize = maximumPoolSize,这时候会执行拒绝策略。默认的拒绝策略就是抛出一个拒绝处理异常。
5.Executors
5.1ThreadFactory
在将这个之前先介绍一下ThreadFactory。每当线程池需要一个线程时,都是通过线程工厂创建的线程。默认的线程工厂方法将创建一个新的、非守护的线程,并且不包含特殊的线程信息。当然可以通过线程工厂定制线程的信息。此工厂也有好多实现:
public interface ThreadFactory { /** * Constructs a new {@code Thread}. Implementations may also initialize * priority, name, daemon status, {@code ThreadGroup}, etc. * * @param r a runnable to be executed by new thread instance * @return constructed thread, or {@code null} if the request to * create a thread is rejected */ Thread newThread(Runnable r); }
其实现类:
5.2Executors
可以通过Executors中的静态工厂方法之一创建一个线程池。Executors的静态工厂可以创建常用的四种线程池:
newFixedThreadPool(采用LinkedBlockingQueue队列--基于链表的阻塞队列)
创建一个定长线程池,每当提交一个任务时就创建一个线程,直到线程池的最大数量,这时线程池的规模将不再变化(如果由于某个线程由于发生了未预期的exception而结束,那么线程池会补充一个新的线程)。
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }
newCachedThreadPool(使用SynchronousQueue同步队列)
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。线程池的规模不受限。
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
newScheduledThreadPool(使用DelayedWorkQueue延迟队列)
创建一个定长线程池,支持定时及周期性任务执行。类似于Timer。
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) { return new ScheduledThreadPoolExecutor(corePoolSize); }
public ScheduledThreadPoolExecutor(int corePoolSize) { super(corePoolSize, Integer.MAX_VALUE, 0, TimeUnit.NANOSECONDS, new DelayedWorkQueue()); }
newSingleThreadExecutor(采用LinkedBlockingQueue队列--基于链表的阻塞队列)
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。如果这个线程异常结束会创建一个新的线程来替代。
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }
newFixedThreadPool和newCachedThreadPool这两个工厂方法返回通用的ThreadPoolExecutor实例,这些实例可以直接用来构造专门用途的execotor。另外上面创建的时候都有一个可以指定线程工厂的方法:
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>(), threadFactory); }
关于workqueue的选择: DelayQueue 可以实现有序加延迟的效果。 SynchronousQueue 同步队列,实际上它不是一个真正的队列,因为它不会维护队列中元素的存储空间,与其他队列不同的是,它维护一组线程,这些线程在等待把元素加入或移除队列。LinkedBlockingQueue 类似于LinkedList,基于链表的阻塞队列。此队列如果不指定容量大小,默认采用Integer.MAX_VALUE(可以理解为无限队列)。
关于队列的使用参考:https://www.cnblogs.com/qlqwjy/p/10175201.html
6.Java线程池的使用
下面所有的测试都是基于Myrunnale进行测试
package cn.qlq.thread.twenty; import org.slf4j.Logger; import org.slf4j.LoggerFactory; public class MyRunnable implements Runnable { private static final Logger log = LoggerFactory.getLogger(MyRunnable.class); @Override public void run() { for (int i = 0; i < 5; i++) { log.info("threadName -> {},i->{} ", Thread.currentThread().getName(), i); try { Thread.sleep(1 * 1000); } catch (InterruptedException e) { e.printStackTrace(); } } } }
1.FixedThreadPool的用法
创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。在创建的时候并不会马上创建2个线程,而是在提交任务的时候才创建线程。
创建方法:
/** * 参数是初始化线程池子的大小 */ private static final ExecutorService batchTaskPool = Executors.newFixedThreadPool(2);
查看源码:(使用了阻塞队列,超过池子容量的线程会在队列中等待)

测试代码:
package cn.qlq.thread.twenty; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class Demo3 { /** * 参数是初始化线程池子的大小 */ private static final ExecutorService batchTaskPool = Executors.newFixedThreadPool(2); public static void main(String[] args) { for (int i = 0; i < 3; i++) { batchTaskPool.execute(new MyRunnable()); } } }
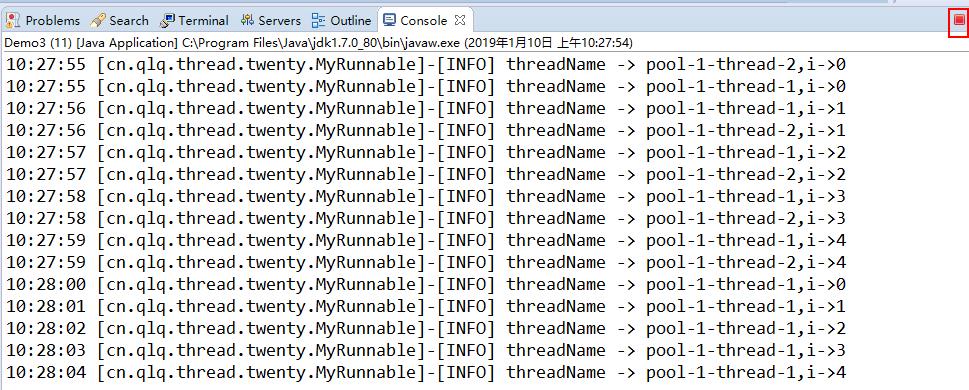
结果:(执行完线程并没有销毁)
解释:
池子容量大小是2,所以前两个先被执行,第三个runable只是暂时的加到等待队列,前两个执行完成之后线程 pool-1-thread-1空闲之后从等待队列获取runnable进行执行。
定长线程池的大小最好根据系统资源进行设置。如Runtime.getRuntime().availableProcessors()
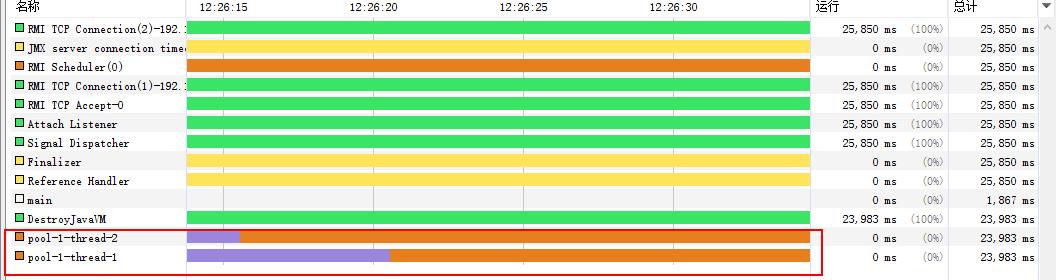
并且上面程序执行完毕之后JVM并没有结束,因此线程池创建的线程默认是非守护线程:
2.CachedThreadPool
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
创建方法:
private static final ExecutorService batchTaskPool = Executors.newCachedThreadPool();
查看源码:(使用了同步队列)

测试代码:
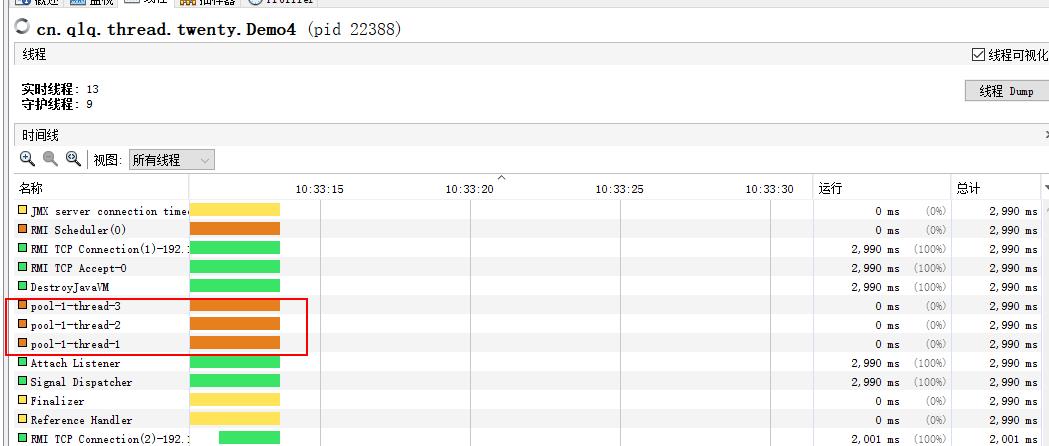
package cn.qlq.thread.twenty; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class Demo4 { /** * 参数是初始化线程池子的大小 */ private static final ExecutorService batchTaskPool = Executors.newCachedThreadPool(); public static void main(String[] args) { for (int i = 0; i < 3; i++) { batchTaskPool.execute(new MyRunnable()); } } }
结果:
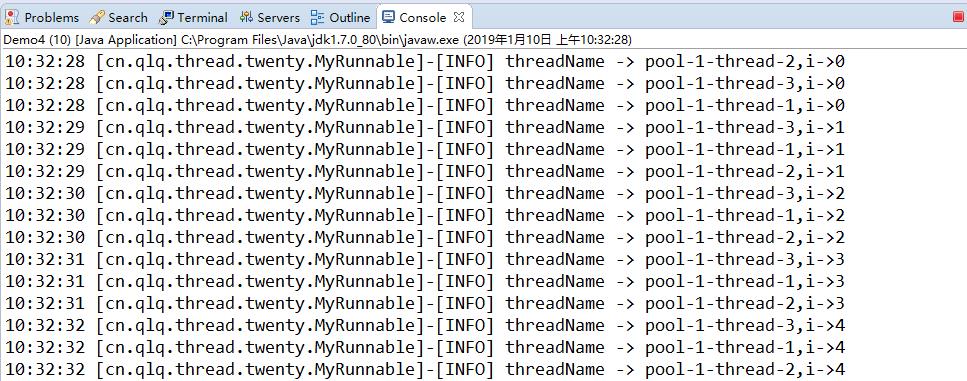
执行完成执行线程并没有结束
3.SingleThreadExecutor用法
创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。类似于单线程执行的效果一样。
创建方法:
private static final ExecutorService batchTaskPool = Executors.newSingleThreadExecutor();
查看源码;使用的阻塞队列

测试代码:
package cn.qlq.thread.twenty; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class Demo5 { private static final ExecutorService batchTaskPool = Executors.newSingleThreadExecutor(); public static void main(String[] args) { for (int i = 0; i < 3; i++) { batchTaskPool.execute(new MyRunnable()); } } }
结果:
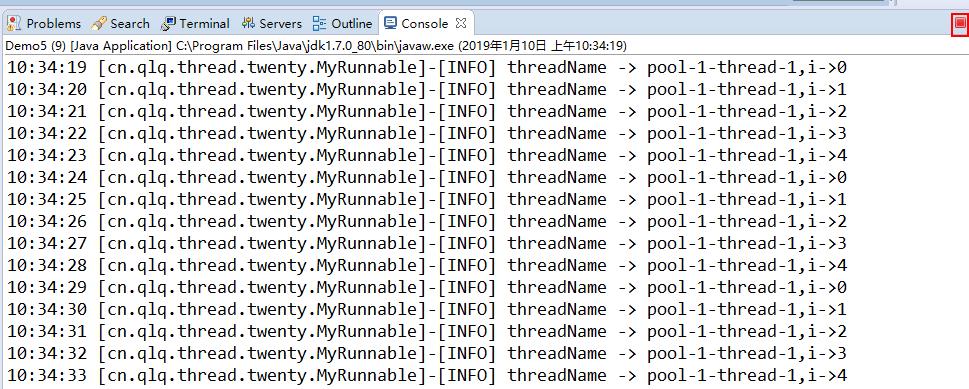
只有一个线程在执行任务:

4.ScheduledThreadPool用法------可以实现任务调度功能
创建一个定长线程池(会指定容量初始化大小),支持定时及周期性任务执行。可以实现一次性的执行延迟任务,也可以实现周期性的执行任务。
创建方法:
private static final ScheduledExecutorService batchTaskPool = Executors.newScheduledThreadPool(2);
查看源码:(使用了延迟队列)


测试代码:
package cn.qlq.thread.twenty; import java.util.concurrent.Executors; import java.util.concurrent.ScheduledExecutorService; import java.util.concurrent.TimeUnit; public class Demo6 { private static final ScheduledExecutorService batchTaskPool = Executors.newScheduledThreadPool(2); public static void main(String[] args) { for (int i = 0; i < 3; i++) { // 第一次执行是在3s后执行(延迟任务) batchTaskPool.schedule(new MyRunnable(), 3, TimeUnit.SECONDS); // 第一个参数是需要执行的任务,第二个参数是第一次的延迟时间,第三个参数是两次执行的时间间隔,第四个参数是时间的单位 batchTaskPool.scheduleAtFixedRate(new MyRunnable(), 3, 7, TimeUnit.SECONDS); // 第一个参数是需要执行的任务,第二个参数是第一次的延迟时间,第三个参数是两次执行的时间间隔,第四个参数是时间的单位 batchTaskPool.scheduleWithFixedDelay(new MyRunnable(), 3, 5, TimeUnit.SECONDS); } } }
schedule是一次性的任务,可以指定延迟的时间。
scheduleAtFixedRate已固定的频率来执行某项计划(任务)
scheduleWithFixedDelay相对固定的延迟后,执行某项计划 (这个就是第一个任务执行完5s后再次执行,一般用这个方法任务调度)
如果延迟时间传入的是负数会立即执行,不会报非法参数错误。
关于二者的区别:
scheduleAtFixedRate :这个是按照固定的时间来执行,简单来说:到点执行
scheduleWithFixedDelay:这个呢,是等上一个任务结束后,在等固定的时间,然后执行。简单来说:执行完上一个任务后再执行
举例子
scheduledThreadPool.scheduleAtFixedRate(new TaskTest("执行调度任务3"),0, 1, TimeUnit.SECONDS); //这个就是每隔1秒,开启一个新线程
scheduledThreadPool.scheduleWithFixedDelay(new TaskTest("第四个"),0, 3, TimeUnit.SECONDS); //这个就是上一个任务执行完,3秒后开启一个新线程
补充:比如想要实现在某一个时钟定时晚上11点执行任务,并且每天都执行
long curDateSecneds = 0; try { String time = "21:00:00"; DateFormat dateFormat = new SimpleDateFormat("yy-MM-dd HH:mm:ss"); DateFormat dayFormat = new SimpleDateFormat("yy-MM-dd"