Spring Boot 慕课网爬虫
Posted just Coding
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring Boot 慕课网爬虫相关的知识,希望对你有一定的参考价值。
一、项目简介(Demo简介)
慕课网。。。打了三个字,还是不介绍了避免广告。一个简单爬虫该网站的demo。
地址:https://www.imooc.com/course/list?c=springboot
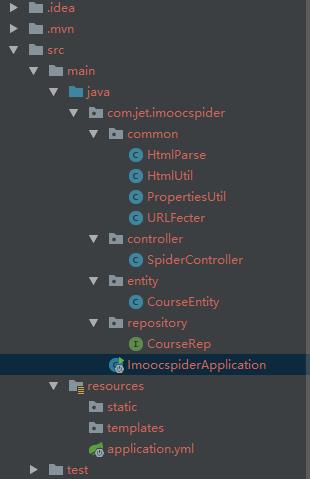
二、项目结构
项目多层架构:common层,controller层,entity层,repository层,由于Demo比较简单就没有细分那么多了(偷懒)。
三、项目说明
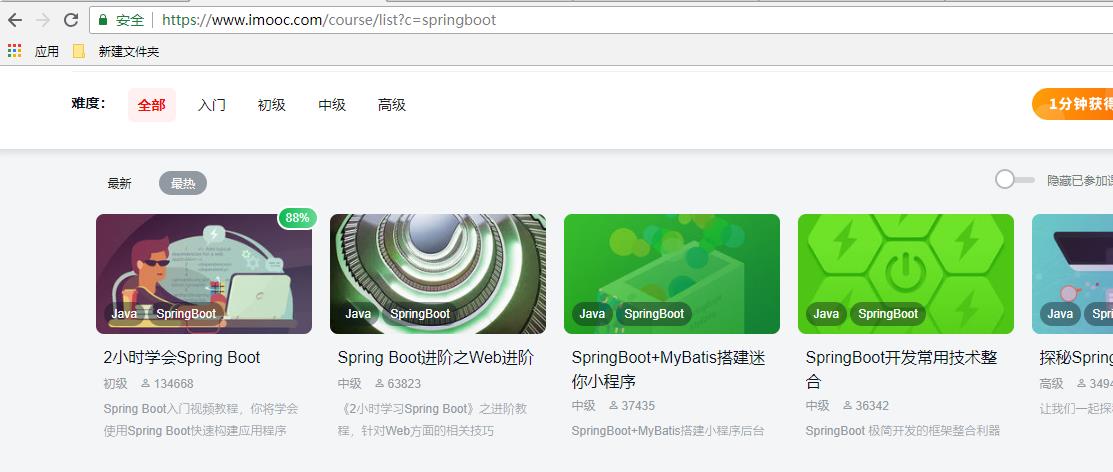
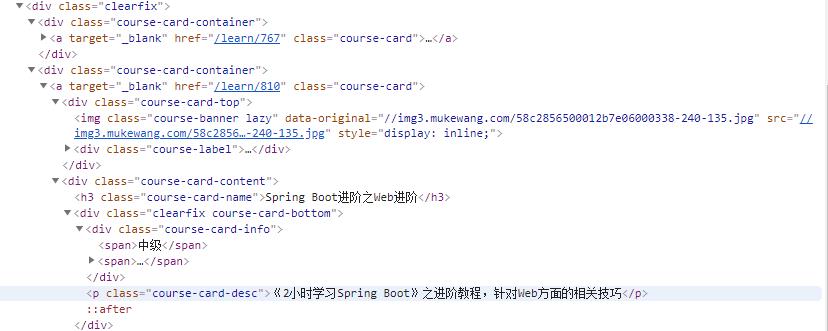
F12 查看页面html结构,发现如下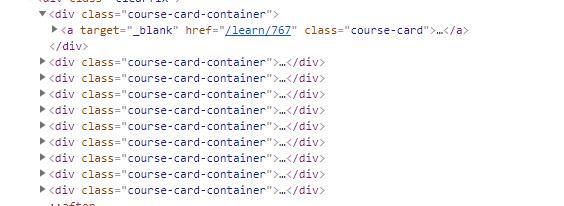
本次我只抽取了 课程名称,url,等级,描述四个字段。
- 数据库,创建imooc_spider数据库,表course。
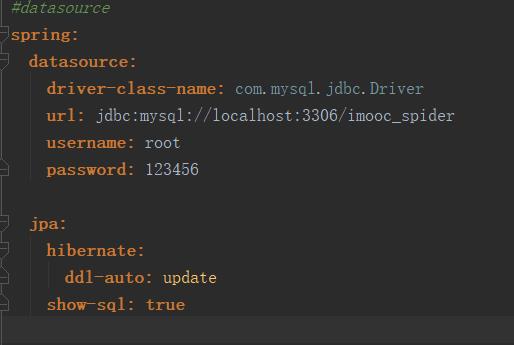
- JPA,这里我结合Spring boot JPA,application.yml配置如下。创建对应的CourseEntiy
-
@Entity @Table(name = "course") public class CourseEntity { @Id @GeneratedValue private Integer id; private String name; private String url; private String desc; private String level; } - 解析html。http请求这里就不介绍了,重点就是解析html,采用Jsoup,当然也可以使用正则,但是我觉得Jsoup比较直观方便操作。解析的代码要结合页面上的html。
-
div[class=clearfix] 代表页面 <div class="clearfix">如果直接<div class="clearfix"> 会提示找不到改节点 -
package com.jet.imoocspider.common; import java.util.ArrayList; import java.util.List; import com.jet.imoocspider.entity.CourseEntity; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class HtmlParse { public static List<CourseEntity> getData (String html) throws Exception{ //获取的数据,存放在集合中 List<CourseEntity> data = new ArrayList<CourseEntity>(); //采用Jsoup解析 Document doc = Jsoup.parse(html); //获取html标签中的内容 Elements elements=doc.select("div[class=clearfix]").select("div[class=course-card-container]").select("a[class=course-card]"); for (Element ele:elements) { String url="https://www.imooc.com".concat(ele.attr("href")); String name=ele.select("div[class=courseEntity-card-content]").select("h3[class=courseEntity-card-name]").html(); Elements elementLevelParent=ele.select("div[class=courseEntity-card-content]").select("div[class=clearfix courseEntity-card-bottom]"); String level=elementLevelParent.select("div[class=courseEntity-card-info]").tagName("span").first().text(); String desc=elementLevelParent .select("p[class=courseEntity-card-desc]").text(); CourseEntity courseEntity =new CourseEntity(); courseEntity.setDesc(desc); courseEntity.setUrl(url); courseEntity.setName(name); courseEntity.setLevel(level); //将每一个对象的值,保存到List集合中 data.add(courseEntity); } //返回数据 return data; } } -
以上是关于Spring Boot 慕课网爬虫的主要内容,如果未能解决你的问题,请参考以下文章