万字避坑指南!C++的缺陷与思考(下)
Posted 程序员编程指南
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了万字避坑指南!C++的缺陷与思考(下)相关的知识,希望对你有一定的参考价值。
导读 | 在万字避坑指南!C++的缺陷与思考(上)一文中,微信后台开发工程师胡博豪,分享了C++的发展历史、右值引用与移动语义、类型说明符等内容,深受广大开发者喜爱!此篇,我们邀请作者继续总结其在C++开发过程中对一些奇怪、复杂的语法的理解和思考,分享C++开发的避坑指南。

static
我在前面章节吐槽了const这个命名,也吐槽了“右值引用”这个命名。那么static就是笔者下一个要重点吐槽的命名了。static这个词本身没有什么问题,其主要的槽点就在于“一词多用”,也就是说,这个词在不同场景下表示的是完全不同的含义。(作者可能是出于节省关键词的目的吧,明明是不同的含义,却没有用不同的关键词)。
第一,在局部变量前的static,限定的是变量的生命周期。
第二,在全局变量/函数前的static,限定的是变量/函数的作用域。
第三,在成员变量前的static,限定的是成员变量的生命周期。
第四在成员函数前的static,限定的是成员函数的调用方(或隐藏参数)。
上面是static关键字的4种不同含义,接下来我会逐一解释。
1)静态局部变量
当用static修饰局部变量时,static表示其生命周期:
void f()
static int count = 0;
count++;
上述例子中,count是一个局部变量,既然已经是“局部变量”了,那么它的作用域很明显,就是f函数内部,而这里的static表示的是其生命周期。普通的全局变量在其所在函数(或代码块)结束时会被释放,而用static修饰的则不会,我们将其称为“静态局部变量”。静态局部变量会在首次执行到定义语句时初始化,在主函数执行结束后释放,在程序执行过程中遇到定义(和初始化)语句时会被忽略。
void f()
static int count = 0;
count++;
std::cout << count << std::endl;
int main(int argc, const char *argv[])
f(); // 第一次执行时count被定义,并且初始化为0,执行后count值为1,并且不会释放
f(); // 第二次执行时由于count已经存在,因此初始化语句会无视,执行后count值为2,并且不会释放
f(); // 同上,执行后count值为3,不会释放
// 主函数执行结束后会释放f中的count例如上面例程的输出结果会是:
1
2
32)内部全局变量/函数
当static修饰全局变量或函数时,用于限定其作用域为“当前文件内”。同理,由于已经是“全局”变量了,生命周期一定是符合全局的,也就是“主函数执行前构造,主函数执行结束后释放”。至于全局函数就不用说了,函数都是全局生命周期的。因此,这时候的static不会再对生命周期有影响,而是限定了其作用域。与之对应的是extern。用extern修饰的全局变量/函数作用于整个程序内,换句话说,就是可以跨文件。
// a1.cc
int g_val = 4; // 定义全局变量
// a2.cc
extern int g_val; // 声明全局变量
void Demo()
std::cout << g_val << std::endl; // 使用了在另一个文件中定义的全局变量
而用static修饰的全局变量/函数则只能在当前文件中使用,不同文件间的static全局变量/函数可以同名,并且互相独立。
// a1.cc
static int s_val1 = 1; // 定义内部全局变量
static int s_val2 = 2; // 定义内部全局变量
static void f1() // 定义内部函数
// a2.cc
static int s_val1 = 6; // 定义内部全局变量,与a1.cc中的互不影响
static int s_val2; // 这里会视为定义了新的内部全局变量,而不会视为“声明”
static void f1(); // 声明了一个内部函数
void Demo()
std::cout << s_val1 << std::endl; // 输出6,与a1.cc中的s_val1没有关系
std::cout << s_val2 << std::endl; // 输出0,同样不会访问到a1.cc中的s_val2
f1(); // ERR,这里链接会报错,因为在a2.cc中没有找到f1的定义,并不会链接到a1.cc中的f1
所以我们发现,在这种场景下,static并不表示“静态”的含义,而是表示“内部”的含义,所以,为什么不再引入个类似于inner的关键字呢?这里很容易让程序员造成迷惑。
3)静态成员变量
静态成员变量指的是用static修饰的成员变量。普通的成员变量其生命周期是跟其所属对象绑定的。构造对象时构造成员变量,析构对象时释放成员变量。
struct Test
int a; // 普通成员变量
;
int main(int argc, const char *argv[])
Test t; // 同时构造t.a
auto t2 = new Test; // 同时构造t2->a
delete t2; // t2所指对象析构,同时释放t2->a
// t析构,同时释放t.a而用static修饰后,其声明周期变为全局,也就是“主函数执行前构造,主函数执行结束后释放”,并且不再跟随对象,而是全局一份。
struct Test
static int a; // 静态成员变量(基本等同于声明全局变量)
;
int Test::a = 5; // 初始化静态成员变量(主函数前执行,基本等同于初始化全局变量)
int main(int argc, const char *argv[])
std::cout << Test::a << std::endl; // 直接访问静态成员变量
Test t;
std::cout << t.a << std::endl; // 通过任意对象实例访问静态成员变量
// 主函数结束时释放Test::a所以静态成员变量基本就相当于一个全局变量,而这时的类更像一个命名空间了。唯一的区别在于,通过类的实例(对象)也可以访问到这个静态成员变量,就像上面的t.a和Test::a完全等价。
4)静态成员函数
static关键字修饰在成员函数前面,称为“静态成员函数”。我们知道普通的成员函数要以对象为主调方,对象本身其实是函数的一个隐藏参数(this指针):
struct Test
int a;
void f(); // 非静态成员函数
;
void Test::f()
std::cout << this->a << std::endl;
void Demo()
Test t;
t.f(); // 用对象主调成员函数
上面其实等价于:
struct Test
int a;
;
void f(Test *this)
std::cout << this->a << std::endl;
void Demo()
Test t;
f(&t); // 其实对象就是函数的隐藏参数
也就是说,obj.f(arg)本质上就是f(&obj, arg),并且这个参数强制叫做this。这个特性在Go语言中尤为明显,Go不支持封装到类内的成员函数,也不会自动添加隐藏参数,这些行为都是显式的:
type Test struct
a int
func(t *Test) f()
fmt.Println(t.a)
func Demo()
t := new(Test)
t.f()
回到C++的静态成员函数这里来。用static修饰的成员函数表示“不需要对象作为主调方”,也就是说没有那个隐藏的this参数。
struct Test
int a;
static void f(); // 静态成员函数
;
void Test::f()
// 没有this,没有对象,只能做对象无关操作
// 也可以操作静态成员变量和其他静态成员函数
可以看出,这时的静态成员函数,其实就相当于一个普通函数而已。这时的类同样相当于一个命名空间,而区别在于,如果这个函数传入了同类型的参数时,可以访问私有成员,例如:
class Test
public:
static void f(const Test &t1, const Test &t2); // 静态成员函数
private:
int a; // 私有成员
;
void Test::f(const Test &t1, const Test &t2)
// t1和t2是通过参数传进来的,但因为是Test类型,因此可以访问其私有成员
std::cout << t1.a + t2.a << std::endl;
或者我们可以把静态成员函数理解为一个友元函数,只不过从设计角度上来说,与这个类型的关联度应该是更高的。但是从语法层面来解释,基本相当于“写在类里的普通函数”。
5)小结
其实C++中static造成的迷惑,同样也是因为C中的缺陷被放大导致的。毕竟在C中不存在构造、析构和引用链的问题。说到这个引用链,其实C++中的静态成员变量、静态局部变量和全局变量还存在一个链路顺序问题,可能会导致内存重复释放、访问野指针等情况的发生。这部分的内容详见后面“平凡、标准布局”的章节。总之,我们需要了解static关键字有多义性,了解其在不同场景下的不同含义,更有助于我们理解C++语言,防止踩坑。

平凡、标准布局
前阵子我和一个同事对这样一个问题进行了非常激烈的讨论:
到底应不应该定义std::string类型的全局变量
这个问题乍一看好像没什么值得讨论的地方,我相信很多程序员都在不经意间写过类似的代码,并且确实没有发现什么执行上的问题,所以可能从来没有意识到,这件事还有可能出什么问题。我们和我同事之所以激烈讨论这个问题,一切的根源来源于谷歌的C++编程规范,其中有一条是:
Static or global variables of class type are forbidden: they cause hard-to-find bugs due to indeterminate order of construction and destruction.
Objects with static storage duration, including global variables, static variables, static class member variables, and function static variables, must be Plain Old Data (POD): only ints, chars, floats, or pointers, or arrays/structs of POD.大致翻译一下就是说:不允许非POD类型的全局变量、静态全局变量、静态成员变量和静态局部变量,因为可能会导致难以定位的bug。而std::string是非POD类型的,自然,按照规范,也不允许std::string类型的全局变量。(公司编程规范中并没有直接限制POD类型,而是限制了非平凡析构,它确实会比谷歌规范中用POD一刀砍会合理得多,但笔者仍然觉得其实限制仍然可以继续再放开些。可以参考公司C++编程规范第3.5条)
但是如果我们真的写了,貌似也从来没有遇到过什么问题,程序也不会出现任何bug或者异常,甚至下面的几种写法都是在日常开发中经常遇到的,但都不符合这谷歌的这条代码规范。
全局字符串
const std::string ip = "127.0.0.1";
const uint16_t port = 80;
void Demo()
// 开启某个网络连接
SocketSvr svrip, port;
// 记录日志
WriteLog("net linked: ip:port=%s:%hu", ip.c_str(), port);
静态映射表
std::string GetDesc(int code)
static const std::unordered_map<int, std::string> ma
0, "SUCCESS",
1, "DATA_NOT_FOUND",
2, "STYLE_ILLEGEL",
-1, "SYSTEM_ERR"
;
if (auto res = ma.find(code); res != ma.end())
return res->second;
return "UNKNOWN";
单例模式
class SingleObj
public:
SingleObj &GetInstance();
SingleObj(const SingleObj &) = delete;
SingleObj &operator =(const SingleObj &) = delete;
private:
SingleObj();
~SingleObj();
;
SingleObj &SingleObj::GetInstance()
static SingleObj single_obj;
return single_obj;
上面的几个例子都存在“非POD类型全局或静态变量”的情况。
1)全局、静态的生命周期问题
既然谷歌规范中禁止这种情况,那一定意味着,这种写法存在潜在风险,我们需要搞明白风险点在哪里。首先明确变量生命周期的问题:
第一,全局变量和静态成员变量在主函数执行前构造,在主函数执行结束后释放;
第二,静态局部变量在第一次执行到定义位置时构造,在主函数执行后释放。
这件事如果在C语言中,并没有什么问题,设计也很合理。但是C++就是这样悲催,很多C当中合理的问题在C++中会变得不合理,并且缺陷会被放大。
由于C当中的变量仅仅是数据,因此,它的“构造”和“释放”都没有什么副作用。但在C++当中,“构造”是要调用构造函数来完成的,“释放”之前也是要先调用析构函数。这就是问题所在!照理说,主函数应该是程序入口,那么在主函数之前不应该调用任何自定义的函数才对。但这件事放到C++当中就不一定成立了,我们看一下下面例程:
class Test
public:
Test();
~Test();
;
Test::Test()
std::cout << "create" << std::endl;
Test::~Test()
std::cout << "destroy" << std::endl;
Test g_test; // 全局变量
int main(int argc, const char *argv[])
std::cout << "main function" << std::endl;
return 0;
运行上面程序会得到以下输出:
create
main function
destroy也就是说,Test的构造函数在主函数前被调用了。解释起来也很简单,因为“全局变量在主函数执行之前构造,主函数执行结束后释放”,而因为Test类型是类类型,“构造”时要调用构造函数,“释放”时要调用析构函数。所以上面的现象也就不奇怪了。
这种单一个的全局变量其实并不会出现什么问题,但如果有多变量的依赖,这件事就不可控了,比如下面例程:
test.h
struct Test1
int a;
;
extern Test1 g_test1; // 声明全局变量test.cc
Test1 g_test1 4; // 定义全局变量main.cc
#include "test.h"
class Test2
public:
Test2(const Test1 &test1); // 传Test1类型参数
private:
int m_;
;
Test2::Test2(const Test1 &test1): m_(test1.a)
Test2 g_test2g_test1; // 用一个全局变量来初始化另一个全局变量
int main(int argc, const char *argv)
return 0;
上面这种情况,程序编译、链接都是没问题的,但运行时会概率性出错,问题
就在于,g_test1和g_test2都是全局变量,并且是在不同文件中定义的,并且
由于全局变量构造在主函数前,因此其初始化顺序是随机的。
假如g_test1在g_test2之前初始化,那么整个程序不会出现任何问题,但如果g_test2在g_test1前初始化,那么在Test2的构造函数中,得到的就是一个未初始化的test1引用,这时候访问test1.a就是操作野指针了。
这时我们就能发现,全局变量出问题的根源在于全局变量的初始化顺序不可控,是随机的,因此,如果出现依赖,则会导致问题。同理,析构发生在主函数后,那么析构顺序也是随机的,可能出问题,比如:
struct Test1
int count;
;
class Test2
public:
Test2(Test1 *test1);
~Test2();
private:
Test1 *test1_;
;
Test2::Test2(Test1 *test1): test1_(test1)
test1_->count++;
Test2::~Test2()
test1_->count--;
Test1 g_test1 0; // 全局变量
void Demo()
static Test2 t2&g_test1; // 静态局部变量
int main(int argc, const char *argv[])
Demo(); // 构造了t2
return 0;
在上面示例中,构造t2的时候使用了g_test1,由于t2是静态局部变量,因此是在第一个调用时(主函数中调用Demo时)构造。这时已经是主函数执行过程中了,因此g_test1已经构造完毕的,所以构造时不会出现问题。
但是,静态成员变量是在主函数执行完成后析构,这和全局变量相同,因此,t2和g_test1的析构顺序无法控制。如果t2比g_test1先析构,那么不会出现任何问题。但如果g_test1比t2先析构,那么在析构t2时,对test1_访问count成员这一步,就会访问野指针。因为test1_所指向的g_test1已经先行析构了。
那么这个时候我们就可以确定,全局变量、静态变量之间不能出现依赖关系,否则,由于其构造、析构顺序不可控,因此可能会出现问题。
2)谷歌标准中的规定
回到我们刚才提到的谷歌标准,这里标准的制定者正是因为担心这样的问题发生,才禁止了非POD类型的全局或静态变量。但我们分析后得知,也并不是说所有的类类型全局或静态变量都会出现问题。
而且,谷歌规范中的“POD类型”的限定也过于广泛了。所谓“POD类型”指的是“平凡”+“标准内存布局”,这里我来解释一下这两种性质,并且分析分析为什么谷歌标准允许POD类型的全局或静态变量。
3)平凡
“平凡(trivial)”指的是:
拥有默认无参构造函数;
拥有默认析构函数;
拥有默认拷贝构造函数;
拥有默认移动构造函数;
拥有默认拷贝赋值函数;
拥有默认移动赋值函数。
换句话说,六大特殊函数都是默认的。这里要区分2个概念,我们要的是“语法上的平凡”还是“实际意义上的平凡”。语法上的平凡就是说能够被编译期识别、认可的平凡。而实际意义上的平凡就是说里面没有额外操作。比如说:
class Test1
public:
Test1() = default; // 默认无参构造函数
Test1(const Test1 &) = default; // 默认拷贝构造函数
Test &operator =(const Test1 &) = default; // 默认拷贝赋值函数
~Test1() = default; // 默认析构函数
;
class Test2
public:
Test2() // 自定义无参构造函数,但实际内容为空
~Test2() std::printf("destory\\n"); // 自定义析构函数,但实际内容只有打印
;上面的例子中,Test1就是个真正意义上的平凡类型,语法上是平凡的,因此编译器也会认为其是平凡的。我们可以用STL中的工具来判断一个类型是否是平凡的:
bool is_test1_tri = std::is_trivial_v<Test1>; // true但这里的Test2,由于我们自定义了其无参构造函数和析构函数,那么对编译器来说,它就是非平凡的,我们用std::is_trivial来判断也会得到false_value。但其实内部并没有什么外链操作,所以其实我们把Test2类型定义全局变量时也不会出现任何问题,这就是所谓“实际意义上的平凡”。
C++对“平凡”的定义比较严格,但实际上我们看看如果要做全局变量或静态变量的时候,是不需要这样严格定义的。对于全局变量来说,只要定义全局变量时,使用的是“实际意义上平凡”的构造函数,并且拥有“实际意义上平凡”的析构函数,那这个全局变量定义就不会有任何问题。而对于静态局部变量来说,只要拥有“实际意义上平凡”的析构函数的就一定不会出问题。
4)标准内存布局
标准内存布局的定义是:
所有成员拥有相同的权限(比如说都public,或都protected,或都private);
不含虚基类、虚函数;
如果含有基类,基类必须都是标准内存布局;
如果函数成员变量,成员的类型也必须是标准内存布局。
我们同样可以用STL中的std::is_standard_layout来判断一个类型是否是标准内存布局的。这里的定义比较简单,不在赘述。
POD(Plain Old Data)类型
所谓POD类型就是同时符合“平凡”和“标准内存布局”的类型。符合这个类型的基本就是基本数据类型,加上一个普通C语言的结构体。换句话说,符合“旧类型(C语言中的类型)行为的类型”,它不存在虚函数指针、不存在虚表,可以视为普通二进制来操作的。
因此,在C++中,只有POD类型可以用memcpy这种二进制方法来复制而不会产生副作用,其他类型的都必须用用调用拷贝构造。
以前有人向笔者提出疑问,为何vector扩容时不直接用类似于memcpy的方式来复制,而是要以此调用拷贝构造。原因正是在此,对于非POD类型的对象,其中可能会包含虚表、虚函数指针等数据,复制时这些内容可能会重置,并且内部可能会含有一些类似于“计数”这样操作其他引用对象的行为,因为一定要用拷贝构造函数来保证这些行为是正常的,而不能简单粗暴地用二进制方式进行拷贝。
STL中可以用std::is_pod来判断是个类型是否是POD的。
小结
我们再回到谷歌规范中,POD的限制比较多,因此,确实POD类型的全局/静态变量是肯定不会出问题的,但直接将非POD类型的一棍子打死,笔者个人认为有点过了,没必要。
所以,笔者认为更加精确的限定应该是:对于全局变量、静态成员变量来说,初始化时必须调用的是平凡的构造函数,并且其应当拥有平凡的析构函数,而且这里的“平凡”是指实际意义上的平凡,也就是说可以自定义,但是在内部没有对任何其他的对象进行操作;对于静态局部变量来说,其应当拥有平凡的析构函数,同样指的是实际意义上的平凡,也就是它的析构函数中没有对任何其他的对象进行操作。
最后举几个例子:
class Test1
public:
Test1(int a): m_(a)
void show() const std::printf("%d\\n", m_);
private:
int m_;
;
class Test2
public:
Test2(Test1 *t): m_(t)
Test2(int a): m_(nullptr)
~Test2()
private:
Test1 *m_;
;
class Test3
public:
Test3(const Test1 &t): m_(&t)
~Test3() m_->show();
private:
Test1 *m_;
;
class Test4
public:
Test4(int a): m_(a)
~Test4() = default;
private:
Test1 m_;
;Test1是非平凡的(因为无参构造函数没有定义),但它仍然可以定义全局/静态变量,因为Test1(int)构造函数是“实际意义上平凡”的。
Test2是非平凡的,并且Test2(Test1 *)构造函数需要引用其他类型,因此它不能通过Test2(Test1 *)定义全局变量或静态成员变量,但可以通过Test2(int)来定义全局变量或静态成员变量,因为这是一个“实际意义上平凡”的构造函数。而且因为它的析构函数是“实际意义上平凡”的,因此Test2类型可以定义静态局部变量。
Test3是非平凡的,构造函数对Test1有引用,并且析构函数中调用了Test1::show方法,因此Test3类型不能用来定义局部/静态变量。
Test4也是非平凡的,并且内部存在同样非平凡的Test1类型成员,但是因为m1_不是引用或指针,一定会随着Test4类型的对象的构造而构造,析构而析构,不存在顺序依赖问题,因此Test4可以用来定义全局/静态变量。
所以全局std::string变量到底可以不可以?
最后回到这个问题上,笔者认为定义一个全局的std::string类型的变量并不会出现什么问题,在std::string的内部,数据空间是通过new的方式申请的,并且一般情况下都不会被其他全局变量所引用,在std::string对象析构时,对这片空间会进行delete,所以并不会出现析构顺序问题。
但是,如果你用的不是默认的内存分配器,而是自定义了内存分配器的话,那确实要考虑构造析构顺序的问题了,你要保证在对象构造前,内存分配器是存在的,并且内存分配器的析构要在所有对象之后。
当然了,如果你仅仅是想给字符串常量起个别名的话,有一种更好的方式:
constexpr const char *ip = "127.0.0.1";毕竟指针一定是平凡类型,而且用constexpr修饰后可以变为编译期常量。这里详情可以在后面“constexpr”的章节了解。
而至于其他类型的静态局部变量(比如说单例模式,或者局部内的map之类的映射表),只要让它不被析构就好了,所以可以用堆空间的方式:
static Test &Test::GetInstance()
static Test &inst = *new Test;
return inst;
std::string GetDesc(int code)
static const auto &desc = *new std::map<int, std::string>
1, "desc1",
2, "desc2",
;
auto iter = desc.find(code);
return iter == desc.end() ? "no_desc" : iter->second;
5)非平凡析构类型的移动语义
在讨论完平凡类型后,我们发现平凡析构其实是更加值得关注的场景。这里就引申出非平凡析构的移动语义问题,请看例程:
class Buffer
public:
Buffer(size_t size): buf(new int[size]), size(size)
~Buffer() delete [] buf;
Buffer(const Buffer &ob): buf(new int[ob.size]), size(ob.size)
Buffer(Buffer &&ob): buf(ob.buf), size(ob.size)
private:
int *buf;
size_t size;
;
void Demo()
Buffer buf16;
Buffer nb = std::move(buf);
// 这里会报错还是这个简单的缓冲区的例子,如果我们调用Demo函数,那么结束时会报重复释放内存的异常。
那么在上面例子中,buf和nb中的buf指向的是同一片空间,当Demo函数结束时,buf销毁会触发一次Buffer的析构,nb析构时也会触发一次Buffer的析构。而析构函数中是delete操作,所以堆空间会被释放两次,导致报错。
这也就是说,对于非平凡析构类型,其发生移动语义后,应当放弃对原始空间的控制。
如果我们修改一下代码,那么这种问题就不会发生:
class Buffer
public:
Buffer(size_t size): buf(new int[size]), size(size)
~Buffer();
Buffer(const Buffer &ob): buf(new int[ob.size]), size(ob.size)
Buffer(Buffer &&ob): buf(ob.buf), size(ob.size) ob.buf = nullptr; // 重点在这里
private:
int *buf;
;
Buffer::~Buffer()
if (buf != nullptr)
delete [] buf;
void Demo()
Buffer buf16;
Buffer nb = std::move(buf);
// OK,没有问题由于移动构造函数和移动赋值函数是我们可以自定义的,因此,可以把重复析构产生的问题在这个里面考虑好。例如上面的把对应指针置空,而析构时再进行判空即可。
因此,我们得出的结论是并不是说非平凡析构的类型就不可以使用移动语义,而是非平凡析构类型进行移动构造或移动赋值时,要考虑引用权释放问题。

私有继承和多继承
1)C++是多范式语言
在讲解私有继承和多继承之前,笔者要先澄清一件事:C++不是单纯的面相对象的语言。同样地,它也不是单纯的面向过程的语言,也不是函数式语言,也不是接口型语言……
真的要说,C++是一个多范式语言,也就是说它并不是为了某种编程范式来创建的。C++的语法体系完整且庞大,很多范式都可以用C++来展现。因此,不要试图用任一一种语言范式来解释C++语法,不然你总能找到各种漏洞和奇怪的地方。
举例来说,C++中的“继承”指的是一种语法现象,而面向对象理论中的“继承”指的是一种类之间的关系。这二者是有本质区别的,请读者一定一定要区分清楚。
以面向对象为例,C++当然可以面向对象编程(OOP),但由于C++并不是专为OOP创建的语言,自然就有OOP理论解释不了的语法现象。比如说多继承,比如说私有继承。
C++与java不同,java是完全按照OOP理论来创建的,因此所谓“抽象类”,“接口(协议)类”的语义是明确可以和OOP对应上的,并且,在OOP理论中,“继承”关系应当是"A is a B"的关系,所以不会存在A既是B又是C的这种情况,自然也就不会出现“多继承”这样的语法。
但是在C++中,考虑的是对象的布局,而不是OOP的理论,所以出现私有继承、多继承等这样的语法也就不奇怪了。
笔者曾经听有人持有下面这样类似的观点:
虚函数都应该是纯虚的;
含有虚函数的类不应当支持实例化(创建对象);
能实例化的类不应当被继承,有子类的类不应当被实例化;
一个类至多有一个“属性父类”,但可以有多个“协议父类”。
等等这些观点,它们其实都有一个共同的前提,那就是“我要用C++来支持OOP范式”。如果我们用OOP范式来约束C++,那么上面这些观点都是非常正确的,否则将不符合OOP的理论,例如:
class Pet ;
class Cat : public Pet ;
class Dog : public Pet ;
void Demo()
Pet pet; // 一个不属于猫、狗等具体类型,仅仅属于“宠物”的实例,显然不合理
Pet既然作为一个抽象概念存在,自然就不应当有实体。同理,如果一个类含有未完全实现的虚函数,就证明这个类属于某种抽象,它就不应该允许创建实例。而可以创建实例的类,一定就是最“具象”的定义了,它就不应当再被继承。
在OOP的理论下,多继承也是不合理的:
class Cat ;
class Dog ;
class SomeProperty : public Cat, public Dog ; // 啥玩意会既是猫也是狗?但如果是“协议父类”的多继承就是合理的:
class Pet // 协议类
public:
virtual void Feed() = 0; // 定义了喂养方式就可以成为宠物
;
class Animal ;
class Cat : public Animal, public Pet // 遵守协议,实现其需方法
public:
void Feed() override; // 实现协议方法
;上面例子中,Cat虽然有2个父类,但Animal才是真正意义上的父类,也就是Cat is a (kind of) Animal的关系,而Pet是协议父类,也就是Cat could be a Pet,只要一个类型可以完成某些行为,那么它就可以“作为”这样一种类型。
在java中,这两种类型是被严格区分开的:
interface Pet // 接口类
public void Feed();
abstract class Animal // 抽象类,不可创建实例
class Cat extends Animal implements Pet
public void Feed()
子类与父类的关系叫“继承”,与协议(或者叫接口)的关系叫“实现”。
与C++同源的Objective-C同样是C的超集,但从名称上就可看出,这是“面向对象的C”,语法自然也是针对OOP理论的,所以OC仍然只支持单继承链,但可以定义协议类(类似于java中的接口类),“继承”和“遵守(类似于java中的实现语义)”仍然是两个分离的概念:
@protocol Pet <NSObject> // 定义协议
- (void)Feed;
@end
@interface Animal : NSObject
@end
@interface Cat : Animal<Pet> // 继承自Animal类,遵守Pet协议
- (void)Feed;
@end
@implementation Cat
- (void)Feed
// 实现协议接口
@end相比,C++只能说“可以”用做OOP编程,但OOP并不是其唯一范式,也就不会针对于OOP理论来限制其语法。这一点,希望读者一定要明白。
2)私有继承与EBO
私有继承本质不是「继承」
在此强调,这个标题中,第一个“继承”指的是一种C++语法,也就是class A : B ;这种写法。而第二个“继承”指的是OOP(面向对象编程)的理论,也就是A is a B的抽象关系,类似于“狗”继承自“动物”的这种关系。
所以我们说,私有继承本质是表示组合的,而不是继承关系,要验证这个说法,只需要做一个小实验即可。我们知道最能体现继承关系的应该就是多态了,如果父类指针能够指向子类对象,那么即可实现多态效应。请看下面的例程:
class Base ;
class A : public Base ;
class B : private Base ;
class C : protected Base ;
void Demo()
A a;
B b;
C c;
Base *p = &a; // OK
p = &b; // ERR
p = &c; // ERR
这里我们给Base类分别编写了A、B、C三个子类,分别是public、private和protected继承。然后用Base *类型的指针去分别指向a、b、c。发现只有public继承的a对象可以用p直接指向,而b和c都会报这样的错:
Cannot cast 'B' to its private base class 'Base'
Cannot cast 'C' to its protected base class 'Base'也就是说,私有继承是不支持多态的,那么也就印证了,他并不是OOP理论中的“继承关系”,但是,由于私有继承会继承成员变量,也就是可以通过b和c去使用a的成员,那么其实这是一种组合关系。或者,大家可以理解为,把b.a.member改写成了b.A::member而已。
那么私有继承既然是用来表示组合关系的,那我们为什么不直接用成员对象呢?为什么要使用私有继承?这是因为用成员对象在某种情况下是有缺陷的。
空类大小
在解释私有继承的意义之前,我们先来看一个问题,请看下面例程
class T ;
// sizeof(T) = ?T是一个空类,里面什么都没有,那么这时T的大小是多少?照理说,空类的大小就是应该是0,但如果真的设置为0的话,会有很严重的副作用,请看例程:
class T ;
void Demo()
T arr[10];
sizeof(arr); // 0
T *p = arr + 5;
// 此时p==arr
p++; // ++其实无效
发现了吗?假如T的大小是0,那么T指针的偏移量就永远是0,T类型的数组大小也将是0,而如果它成为了一个成员的话,问题会更严重:
struct Test
T t;
int a;
;
// t和a首地址相同由于T是0大小,那么此时Test结构体中,t和a就会在同一首地址。所以,为了避免这种0长的问题,编译器会针对于空类自动补一个字节的大小,也就是说其实sizeof(T)是1,而不是0。
这里需要注意的是,不仅是绝对的空类会有这样的问题,只要是不含有非静态成员变量的类都有同样的问题,例如下面例程中的几个类都可以认为是空类:
class A ;
class B
static int m1;
static int f();
;
class C
public:
C();
~C();
void f1();
double f2(int arg) const;
;有了自动补1字节,T的长度变成了1,那么T*的偏移量也会变成1,就不会出现0长的问题。但是,这么做就会引入另一个问题,请看例程:
class Empty ;
class Test
Empty m1;
long m2;
;
// sizeof(Test)==16由于Empty是空类,编译器补了1字节,所以此时m1是1字节,而m2是8字节,m1之后要进行字节对齐,因此Test变成了16字节。如果Test中出现了很多空类成员,这种问题就会被继续放大。
这就是用成员对象来表示组合关系时,可能会出现的问题,而私有继承就是为了解决这个问题的。
空基类成员压缩(EBO,Empty Base Class Optimization)
在上一节最后的历程中,为了让m1不再占用空间,但又能让Test中继承Empty类的其他内容(例如函数、类型重定义等),我们考虑将其改为继承来实现,EBO就是说,当父类为空类的时候,子类中不会再去分配父类的空间,也就是说这种情况下编译器不会再去补那1字节了,节省了空间。但如果使用public继承会怎么样?
class Empty ;
class Test : public Empty
long m2;
;
// 假如这里有一个函数让传Empty类对象
void f(const Empty &obj)
// 那么下面的调用将会合法
void Demo()
Test t;
f(t); // OK
Test由于是Empty的子类,所以会触发多态性,t会当做Empty类型传入f中。这显然问题很大呀!如果用这个例子看不出问题的话,我们换一个例子:class Alloc
public:
void *Create();
void Destroy();
;
class Vector : public Alloc
;
// 这个函数用来创建buffer
void CreateBuffer(const Alloc &alloc)
void *buffer = alloc.Create(); // 调用分配器的Create方法创建空间
void Demo()
Vector ve; // 这是一个容器
CreateBuffer(ve); // 语法上是可以通过的,但是显然不合理
内存分配器往往就是个空类,因为它只提供一些方法,不提供具体成员。Vector是一个容器,如果这里用public继承,那么容器将成为分配器的一种,然后调用CreateBuffer的时候可以传一个容器进去,这显然很不合理呀!那么此时,用私有继承就可以完美解决这个问题了
class Alloc
public:
void *Create();
void Destroy();
;
class Vector : private Alloc
private:
void *buffer;
size_t size;
// ...
;
// 这个函数用来创建buffer
void CreateBuffer(const Alloc &alloc)
void *buffer = alloc.Create(); // 调用分配器的Create方法创建空间
void Demo()
Vector ve; // 这是一个容器
CreateBuffer(ve); // ERR,会报错,私有继承关系不可触发多态
此时,由于私有继承不可触发多态,那么Vector就并不是Alloc的一种,也就是说,从OOP理论上来说,他们并不是继承关系。而由于有了私有继承,在Vector中可以调用Alloc里的方法以及类型重命名,所以这其实是一种组合关系。而又因为EBO,所以也不用担心Alloc占用Vector的成员空间的问题。
谷歌规范中规定了继承必须是public的,这主要还是在贴近OOP理论。另一方面就是说,虽然使用私有继承是为了压缩空间,但一定程度上也是牺牲了代码的可读性,让我们不太容易看得出两种类型之间的关系,因此在绝大多数情况下,还是应当使用public继承。不过笔者仍然持有“万事皆不可一棒子打死”的观点,如果我们确实需要EBO的特性否则会大幅度牺牲性能的话,那么还是应当允许使用私有继承。
3)多继承
与私有继承类似,C++的多继承同样是“语法上”的继承,而实际意义上可能并不是OOP中的“继承”关系。再以前面章节的Pet为例:
class Pet
public:
virtual void Feed() = 0;
;
class Animal ;
class Cat : public Animal, public Pet
public:
void Feed() override;
;从形式上来说,Cat同时继承自Anmial和Pet,但从OOP理论上来说,Cat和Animal是继承关系,而和Pet是实现关系,前面章节已经介绍得很详细了,这里不再赘述。
但由于C++并不是完全针对OOP的,因此支持真正意义上的多继承,也就是说,即便父类不是这种纯虚类,也同样支持集成,从语义上来说,类似于“交叉分类”。请看示例:
class Organic // 有机物
;
class Inorganic // 无机物
;
class Acid // 酸
;
class Salt // 盐
;
class AceticAcid : public Organic, public Acid // 乙酸
;
class HydrochloricAcid : public Inorganic, public Acid // 盐酸
;
class SodiumCarbonate : public Inorganic, public Salt // 碳酸钠
;上面就是一个交叉分类法的例子,使用多继承语法合情合理。如果换做其他OOP语言,可能会强行把“酸”或者“有机物”定义为协议类,然后用继承+实现的方式来完成。但如果从化学分类上来看,无论是“酸碱盐”还是“有机物无机物”,都是一种强分类,比如说“碳酸钠”,它就是一种“无机物”,也是一种“盐”,你并不能用类似于“猫是一种动物,可以作为宠物”的理论来解释,不能说“碳酸钠是一种盐,可以作为一种无机物”。
因此C++中的多继承是哪种具体意义,取决于父类本身是什么。如果父类是个协议类,那这里就是“实现”语义,而如果父类本身就是个实际类,那这里就是“继承”语义。当然了,像私有继承的话表示是“组合”语义。不过C++本身并不在意这种语义,有时为了方便,我们也可能用公有继承来表示组合语义,比如说:
class Point
public:
double x, y;
;
class Circle : public Point
public:
double r; // 半径
;这里Circle继承了Point,但显然不是说“圆是一个点”,这里想表达的就是圆类“包含了”点类的成员,所以只是为了复用。从意义上来说,Circle类中继承来的x和y显然表达的是圆心的坐标。不过这样写并不符合设计规范,但笔者用这个例子希望解释的是C++并不在意类之间实际是什么关系,它在意的是数据复用,因此我们更需要了解一下多继承体系中的内存布局。
对于一个普通的类来说,内存布局就是按照成员的声明顺序来布局的,与C语言中结构体布局相同,例如:
class Test1
public:
char a;
int b;
short c;
;那么Test1的内存布局就是
字节编号 | 内容 |
0 | a |
1~3 | 内存对齐保留字节 |
4~7 | b |
8~9 | c |
9~11 | 内存对齐保留字节 |
但如果类中含有虚函数,那么还会在末尾添加虚函数表的指针,例如:
class Test1
public:
char a;
int b;
short c;
virtual void f()
;字节编号 | 内容 |
0 | a |
1~3 | 内存对齐保留字节 |
4~7 | b |
8~9 | c |
9~15 | 内存对齐保留字节 |
16~23 | 虚函数表指针 |
多继承时,第一父类的虚函数表会与本类合并,其他父类的虚函数表单独存在,并排列在本类成员的后面。
4)菱形继承与虚拟继承
C++由于支持“普适意义上的多继承”,那么就会有一种特殊情况——菱形继承,请看例程:
struct A
int a1, a2;
;
struct B : A
int b1, b2;
;
struct C : A
int c1, c2;
;
struct D : B, C
int d1, d2;
;根据内存布局原则,D类首先是B类的元素,然后D类自己的元素,最后是C类元素:
字节序号 | 意义 |
0~15 | B类元素 |
16~19 | d1 |
20~23 | d2 |
24~31 | C类元素 |
如果再展开,会变成这样:
字节序号 | 意义 |
0~3 | a1(B类继承自A类的) |
4~7 | a2(B类继承自A类的) |
8~11 | b1 |
12~15 | b2 |
16~19 | d1 |
20~23 | d2 |
24~27 | a1(C类继承自A类的) |
28~31 | a2(C类继承自A类的) |
32~35 | c1 |
36~39 | c2 |
可以发现,A类的成员出现了2份,这就是所谓“菱形继承”产生的副作用。这也是C++的内存布局当中的一种缺陷,多继承时第一个父类作为主父类合并,而其余父类则是直接向后扩写,这个过程中没有去重的逻辑(详情参考上一节)。这样的话不仅浪费空间,还会出现二义性问题,例如d.a1到底是指从B继承来的a1还是从C里继承来的呢?
C++引入虚拟继承的概念就是为了解决这一问题。但怎么说呢,C++的复杂性往往都是因为为了解决一种缺陷而引入了另一种缺陷,虚拟继承就是非常典型的例子,如果你直接去解释虚拟继承(比如说和普通继承的区别)你一定会觉得莫名其妙,为什么要引入一种这样奇怪的继承方式。所以这里需要我们了解到,它是为了解决菱形继承时空间爆炸的问题而不得不引入的。
首先我们来看一下普通的继承和虚拟继承的区别:普通继承:
struct A
int a1, a2;
;
struct B : A
int b1, b2;
;B的对象模型应该是这样的:
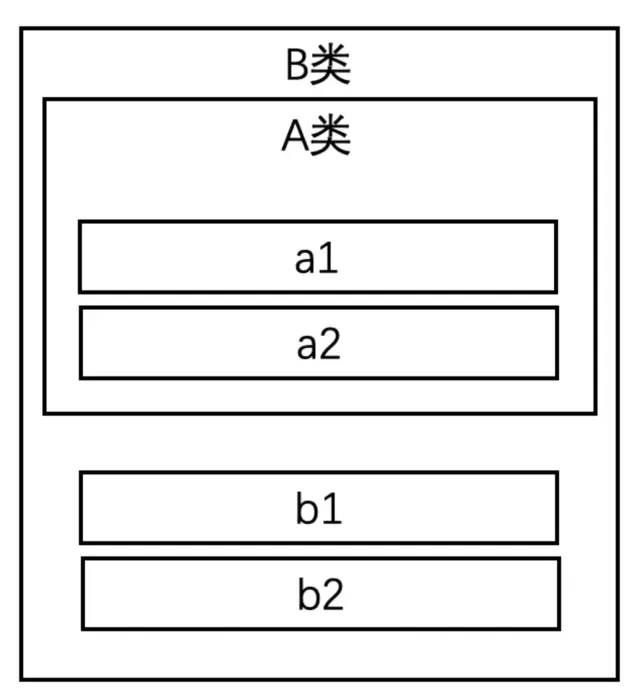
而如果使用虚拟继承:
struct A
int a1, a2;
;
struct B : virtual A
int b1, b2;
;对象模型是这样的:
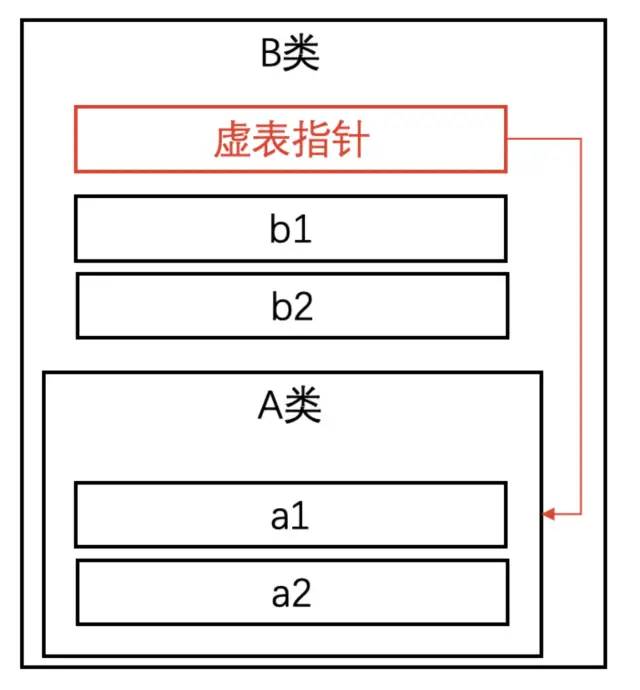
虚拟继承的排布方式就类似于虚函数的排布,子类对象会自动生成一个虚基表来指向虚基类成员的首地址。
就像刚才说的那样,单纯的虚拟继承看上去很离谱,因为完全没有必要强行更换这样的内存布局,所以绝大多数情况下我们是不会用虚拟继承的。但是菱形继承的情况,就不一样了,普通的菱形继承会这样:
struct A
int a1, a2;
;
struct B : A
int b1, b2;
;
struct C : A
int c1, c2;
;
struct D : B, C
int d1, d2;
;D的对象模型:
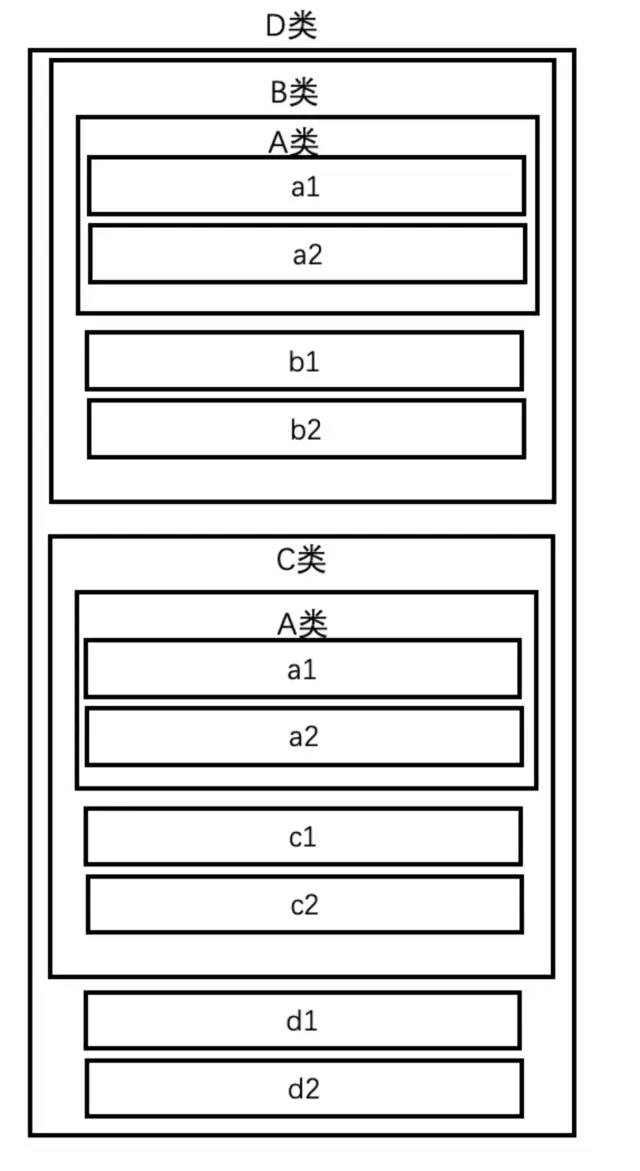
但如果使用虚拟继承,则可以把每个类单独的东西抽出来,重复的内容则用指针来指向:
struct A
int a1, a2;
;
struct B : virtual A
int b1, b2;
;
struct C : virtual A
int c1, c2;
;
struct D : B, C
int d1, d2;
;D的对象模型将会变成:
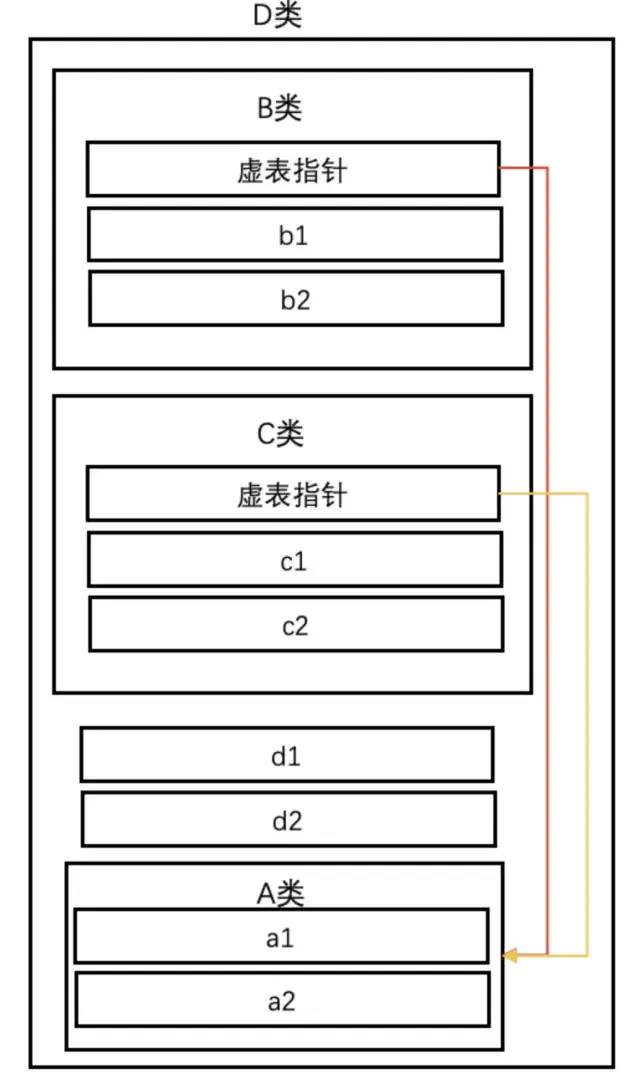
也就是说此时,共有的虚基类只会保存一份,这样就不会有二义性,同时也节省了空间。
但需要注意的是,D继承自B和C时是普通继承,如果用了虚拟继承,则会在D内部又额外添加一份虚基表指针。要虚拟继承的是B和C对A的继承,这也是虚拟继承语法非常迷惑的地方,也就是说,菱形继承的分支处要用虚拟继承,而汇聚处要用普通继承。所以我们还是要明白其底层原理,以及引入这个语法的原因(针对解决的问题),才能更好的使用这个语法,避免出错。

隐式构造
隐式构造指的就是隐式调用构造函数。换句话说,我们不用写出类型名,而是仅仅给出构造参数,编译期就会自动用它来构造对象。举例来说:
class Test
public:
Test(int a, int b)
;
void f(const Test &t)
void Demo()
f(1, 2); // 隐式构造Test临时对象,相当于f(Testa, b)
上面例子中,f需要接受的是Test类型的对象,然而我们在调用时仅仅使用了构造参数,并没有指定类型,但编译器会进行隐式构造。
尤其,当构造参数只有1个的时候,可以省略大括号:
class Test
public:
Test(int a)
Test(int a, int b)
;
void f(const Test &t)
void Demo()
f(1); // 隐式构造Test1,单参时可以省略大括号
f(2); // 隐式构造Test2
f(1, 2); // 隐式构造Test1, 2
这样做的好处显而易见,就是可以让代码简化,尤其是在构造string或者vector的时候更加明显:
void f1(const std::string &str)
void f2(const std::vector<int> &ve)
void Demo()
f1("123"); // 隐式构造std::string"123",注意字符串常量是const char *类型
f2(1, 2, 3); // 隐式构造std::vector,注意这里是initialize_list构造
当然,如果遇到函数重载,原类型的优先级大于隐式构造,例如:
class Test
public:
Test(int a)
;
void f(const Test &t)
std::cout << 1 << std::endl;
void f(int a)
std::cout << 2 << std::endl;
void Demo()
f(5); // 会输出2
但如果有多种类型的隐式构造则会报二义性错误:
class Test1
public:
Test1(int a)
;
class Test2
public:
Test2(int a)
;
void f(const Test1 &t)
std::cout << 1 << std::endl;
void f(const Test2 &t)
std::cout << 2 << std::endl;
void Demo()
f(5); // ERR,二义性错误
在返回值场景也支持隐式构造,例如:
struct err_t
int err_code;
const char *err_msg;
;
err_t f()
return 0, "success"; // 隐式构造err_t
但隐式构造有时会让代码含义模糊,导致意义不清晰的问题(尤其是单参的构造函数),例如:
class System
public:
System(int version);
;
void Operate(const System &sys, int cmd)
void Demo()
Operate(1, 2); // 意义不明确,不容易让人意识到隐式构造
上例中,System表示一个系统,其构造参数是这个系统的版本号。那么这时用版本号的隐式构造就显得很突兀,而且只通过Operate(1, 2)这种调用很难让人想到第一个参数竟然是System类型的。因此,是否应当隐式构造,取决于隐式构造的场景,例如我们用const char *来构造std::string就很自然,用一组数据来构造一个std::vector也很自然,或者说,代码的阅读者非常直观地能反应出来这里发生了隐式构造,那么这里就适合隐式构造,否则,这里就应当限定必须显式构造。用explicit关键字限定的构造函数不支持隐式构造:
class Test
public:
explicit Test(int a);
explicit Test(int a, int b);
Test(int *p);
;
void f(const Test &t)
void Demo()
f(1); // ERR,f不存在int参数重载,Test的隐式构造不允许用(因为有explicit限定),所以匹配失败
f(Test1); // OK,显式构造
f(1, 2); // ERR,同理,f不存在int, int参数重载,Test隐式构造不许用(因为有explicit限定),匹配失败
f(Test1, 2); // OK,显式构造
int a;
f(&a); // OK,隐式构造,调用Test(int *)构造函数
还有一种情况就是,对于变参的构造函数来说,更要优先考虑要不要加explicit,因为变参包括了单参,并且默认情况下所有类型的构造(模板的所有实例,任意类型、任意个数)都会支持隐式构造,例如:
class Test
public:
template <typename... Args>
Test(Args&&... args);
;
void f(const Test &t)
void Demo()
f(1); // 隐式构造Test1
f(1, 2); // 隐式构造Test1, 2
f("abc"); // 隐式构造Test"abc"
f(0, "abc"); // 隐式构造Test0, "abc"
所以避免爆炸(生成很多不可控的隐式构造),对于变参构造最好还是加上
explicit,如果不加的话一定要慎重考虑其可能实例化的每一种情况。在谷歌规范中,单参数构造函数必须用explicit限定(公司规范中也是这样的,可以参考公司C++编程规范第4.2条),但笔者认为这个规范并不完全合理,在个别情况隐式构造意义非常明确的时候,还是应当允许使用隐式构造。另外,即便是多参数的构造函数,如果当隐式构造意义不明确时,同样也应当用explicit来限定。所以还是要视情况而定。C++支持隐式构造,自然考虑的是一些场景下代码更简洁,但归根结底在于C++主要靠STL来扩展功能,而不是语法。举例来说,在Swift中,原生语法支持数组、map、字符串等:
let arr = [1, 2, 3] // 数组
let map = [1 : "abc", 25 : "hhh", -1 : "fail"] // map
let str = "123abc" // 字符串因此,它并不需要所谓隐式构造的场景,因为语法本身已经表明了它的类型。
而C++不同,C++并没有原生支持std::vector、std::map、std::string等的语法,这就会让我们在使用这些基础工具的时候很头疼,因此引入隐式构造来简化语法。所以归根结底,C++语言本身考虑的是语法层面的功能,而数据逻辑层面靠STL来解决,二者并不耦合。但又希望程序员能够更加方便地使用STL,因此引入了一些语言层面的功能,但它却像全体类型开放了。
举例来说,Swift中,[1, 2, 3]的语法强绑定Array类型,[k1:v1, k2,v2]的语法强绑定Map类型,因此这里的“语言”和“工具”是耦合的。但C++并不和STL耦合,他的思路是x, y, z就是构造参数,哪种类型都可以用,你交给vector时就是表示数组,你交给map时就是表示kv对,并不会将“语法”和“类型”做任何强绑定。因此把隐式构造和explicit都提供出来,交给开发者自行处理是否支持。
这是我们需要体会的C++设计理念,当然,也可以算是C++的缺
以上是关于万字避坑指南!C++的缺陷与思考(下)的主要内容,如果未能解决你的问题,请参考以下文章