07.Spring Bean 解析 - BeanDefinitionDocumentReader
Posted 沫小淘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了07.Spring Bean 解析 - BeanDefinitionDocumentReader相关的知识,希望对你有一定的参考价值。
基本概念
BeanDefinitionDocumentReader ,该类的作用有两个,完成 BeanDefinition 的解析和注册 。
-
解析:其实是解析 Ddocument 的内容并将其添加到 BeanDefinition 实例的过程。
-
注册:就是将 BeanDefinition 添加进 BeanDefinitionHolder 的过程,这样做的目的是保存它的信息。
下面来看它的接口定义,该接口只定义了一个方法负责完成解析和注册的工作:
public interface BeanDefinitionDocumentReader {
void registerBeanDefinitions(Document doc, XmlReaderContext readerContext)throws BeanDefinitionStoreException;
}再来看它的继承关系,默认只有一个实现类:

源码分析
接下来来看 DefaultBeanDefinitionDocumentReader 类中的 registerBeanDefinitions 方法。
首先来看该方法的入参:
-
Document:代指 Spring 的配置文件信息,通过 BeanDefinitionReader 解析 Resrouce 实例得到。
-
XmlReaderContext :主要包含了 BeanDefinitionReader 和 Resrouce 。
再来看它的具体流程:
public void registerBeanDefinitions(Document doc, XmlReaderContext readerContext) {
this.readerContext = readerContext;
// 日志输出...
// 取得根元素,即 XML 文件中的 <beans> 标签
Element root = doc.getDocumentElement();
// 关键 -> 继续 Document 的解析
doRegisterBeanDefinitions(root);
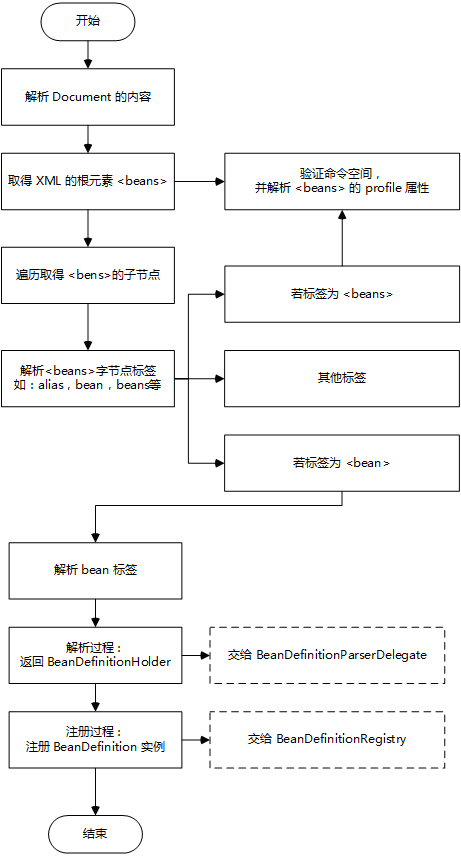
}关于 doRegisterBeanDefinitions,该方法的主要作用有:
-
创建 BeanDefinitionParserDelegate 对象,用于将 Document 的内容转成 BeanDefinition 实例,也就是上面提到的解析过程,BeanDefinitionDocumentReader 本身不具备该功能而是交给了该类来完成。
-
取得 beans 标签中 profile 的属性内容,该标签主要用于环境的切换。例如开发过程中,一般存在测试环境和正式环境,两者之间可能存在不同的数据源。若想要实现环境的快速切换,就可以利用 profile 来配置。具体实现这里暂不探究。
protected void doRegisterBeanDefinitions(Element root) {
// 创建 delegate 对象
BeanDefinitionParserDelegate parent = this.delegate;
this.delegate = createDelegate(getReaderContext(), root, parent);
// 验证 XML 文件的命名空间,即判断是否含有 xmlns="http://www.springframework.org/schema/beans"
if (this.delegate.isDefaultNamespace(root)) {
// 解析 profile
String profileSpec = root.getAttribute(PROFILE_ATTRIBUTE);
if (StringUtils.hasText(profileSpec)) {
String[] specifiedProfiles = StringUtils.tokenizeToStringArray(profileSpec,
BeanDefinitionParserDelegate.MULTI_VALUE_ATTRIBUTE_DELIMITERS);
if (!getReaderContext().getEnvironment().acceptsProfiles(specifiedProfiles)) {
return;
}
}
}
// 空方法
preProcessXml(root);
// 关键 -> 开始解析 Bean 定义
parseBeanDefinitions(root, this.delegate);
// 空方法
postProcessXml(root);
this.delegate = parent;
}下面开始通过遍历取得 beans 元素的所有子节点。
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) {
// 验证 XML 文件的命名空间
if (delegate.isDefaultNamespace(root)) {
// 取得 <beans> 的所有子节点
NodeList nl = root.getChildNodes();
// 遍历 <beans> 的子节点
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
// 判断节点是不是 Element 类型
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
// 关键 -> 解析 <beans> 子节点的内容
parseDefaultElement(ele, delegate);
}else {
// 解析自定义元素,暂不探究
delegate.parseCustomElement(ele);
}
}
}
}else {
delegate.parseCustomElement(root);
}
}在拿到了子节点后,开始解析 beans 标签的子节点,常见的标签有 import,alias,bean,beans 等。
private void parseDefaultElement(Element ele, BeanDefinitionParserDelegate delegate) {
// 处理 <import> 标签,将资源进行合并再统一解析
if (delegate.nodeNameEquals(ele, IMPORT_ELEMENT)) {
importBeanDefinitionResource(ele);
}
// 处理 <alias> 标签
else if (delegate.nodeNameEquals(ele, ALIAS_ELEMENT)) {
processAliasRegistration(ele);
}
// 关键-> 处理 <bean> 标签
else if (delegate.nodeNameEquals(ele, BEAN_ELEMENT)) {
processBeanDefinition(ele, delegate);
}
// 处理 <beans> 标签,回到开始解析 document 的地方
else if (delegate.nodeNameEquals(ele, NESTED_BEANS_ELEMENT)) {
// recurse
doRegisterBeanDefinitions(ele);
}
}这里关键来探究下 bean 的解析过程:
-
上面提到 bean 标签的具体解析工作交给 BeanDefinitionParserDelegate 类来完成。
-
在完成解析取得 BeanDefinition(被添加进了 BeanDefinitionHolder ) 对象之后利用 BeanDefinitionRegistry 完成注册过程。
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
// 关键 -> ①交给委托类 delegate 来完成解析过程 ,并返回 BeanDefinitionHolder 对象
// 该对象存储了 BeanDefinition 的基本信息
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
// 交给委托类 delegate 来完成修饰过程,这里暂不探究
if (bdHolder != null) {
bdHolder = delegate.decorateBeanDefinitionIfRequired(ele, bdHolder);
try {
// 关键 -> ②注册最后的装饰实例
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}catch (BeanDefinitionStoreException ex) {
//错误输出...
}
// Send registration event.
getReaderContext().fireComponentRegistered(new BeanComponentDefinition(bdHolder));
}
}观察上述代码,发现 DefaultBeanDefinitionDocumentReader 的主要职责是解析 Document ,取得配置文件(这里指 xml )中定义的标签内容;而解析标签的过程交给 BeanDefinitionParserDelegate 类完成;注册过程交给了 BeanDefinitionRegistry 接口来完成。
1.BeanDefinition 解析
在 DefaultBeanDefinitionDocumentReader 关于 bean 标签的解析方法如下:
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);- 1
下面来看下 BeanDefinitionParserDelegate 的 parseBeanDefinitionElement 方法。
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele) {
return parseBeanDefinitionElement(ele, null);
}
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, BeanDefinition containingBean) {
// 取得 <bean> 标签的 id 属性
String id = ele.getAttribute(ID_ATTRIBUTE);
// 取得 <bean> 标签的 name 属性
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
// 创建 List 用于存方法 alsas(别名)集合
List<String> aliases = new ArrayList<String>();
if (StringUtils.hasLength(nameAttr)) {
// 将 nameArr 按照(,)或(;)分割成数组
String[] nameArr = StringUtils.tokenizeToStringArray(nameAttr, MULTI_VALUE_ATTRIBUTE_DELIMITERS);
// 添加进行别名集合
aliases.addAll(Arrays.asList(nameArr));
}
// 判断 id 是否为空,若为空则取别名集合的第一个元素当作 id ,并将其从别名集合当中移除
String beanName = id;
if (!StringUtils.hasText(beanName) && !aliases.isEmpty()) {
beanName = aliases.remove(0);
// 日志输出...
}
// 检查 id(标识)和 alias(名别)是否唯一
if (containingBean == null) {
checkNameUniqueness(beanName, aliases, ele);
}
// 关键 -> 解析 <bean> 标签的 class 属性 以及相关特性标签,并将其添加进 beanDefinition 返回
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);
if (beanDefinition != null) {
// 判断是否存在 beanName(id)
if (!StringUtils.hasText(beanName)) {
try {
if (containingBean != null) {
beanName = BeanDefinitionReaderUtils.generateBeanName(beanDefinition, this.readerContext.getRegistry(), true);
}else {
// 由 Spring 自动生成 beanName(id)
beanName = this.readerContext.generateBeanName(beanDefinition);
// 取得 bean 的 完整类名可用
String beanClassName = beanDefinition.getBeanClassName();
// 将 beanName 添加进 alais 集合
if (beanClassName != null &&
beanName.startsWith(beanClassName) &&
beanName.length() > beanClassName.length() &&
!this.readerContext.getRegistry().isBeanNameInUse(beanClassName)) {
aliases.add(beanClassName);
}
}
// 日志输出...
}catch (Exception ex) {
error(ex.getMessage(), ele);
return null;
}
}
// 将 aliases 集合数组化
String[] aliasesArray = StringUtils.toStringArray(aliases);
// 关键 -> 返回一个 BeanDefinitionHolder 实例,用于存储信息
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
return null;
}再来看解析 bean 标签的 class 属性以及相关特性标签,并将其添加进 beanDefinition 返回的具体过程:
public AbstractBeanDefinition parseBeanDefinitionElement(Element ele, String beanName, BeanDefinition containingBean) {
// 入栈操作,往 parseState 中添加一个 新建的 BeanEntry
this.parseState.push(new BeanEntry(beanName));
// 取得 <bean> 标签的 class 属性
String className = null;
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
try {
// 取得 <bean> 标签的 parent 属性
String parent = null;
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE);
}
// 根据 class,parent 的属性值创建一个 BeanDefinition
AbstractBeanDefinition bd = createBeanDefinition(className, parent);
// 取得 <bean> 标签的其他特性属性,并添加进 BeanDefinition 。如:
// scope、
// lazy-init
// autowire
// primary、autowire-candidate
// depends-on、dependency-check
// init-method、destroy-method
// factory-method、factory-bean
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
bd.setDescription(DomUtils.getChildElementValueByTagName(ele, DESCRIPTION_ELEMENT));
// 解析 <mate> 标签
parseMetaElements(ele, bd);
// 解析 <lookup-method> 标签
parseLookupOverrideSubElements(ele, bd.getMethodOverrides());
// 解析 <replaced-method> 标签
parseReplacedMethodSubElements(ele, bd.getMethodOverrides());
// 解析 <constructor-arg> 标签
parseConstructorArgElements(ele, bd);
// 解析 <property> 标签
parsePropertyElements(ele, bd);
// 解析 <qualifier> 标签
parseQualifierElements(ele, bd);
bd.setResource(this.readerContext.getResource());
bd.setSource(extractSource(ele));
return bd;
}catch (ClassNotFoundException ex) {
// 错误输出...
}catch (NoClassDefFoundError err) {
// 错误输出...
}catch (Throwable ex) {
// 错误输出...
}finally {
// 出栈操作
this.parseState.pop();
}
return null;
}2.Beandefinition 注册
在 DefaultBeanDefinitionDocumentReader 关于 bean 标签的注册方法如下:
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());- 1
下面来看 BeanDefinitionReaderUtils 的 registerBeanDefinition 方法。该方法的主要作用是调用注册器完成注册过程。
public static void registerBeanDefinition(BeanDefinitionHolder definitionHolder, BeanDefinitionRegistry registry)
throws BeanDefinitionStoreException {
// 取得 BeanDefinition 实例的标识
String beanName = definitionHolder.getBeanName();
// 关键 -> 调用注册器实现注册过程
registry.registerBeanDefinition(beanName, definitionHolder.getBeanDefinition());
// 取得 BeanDefinition 实例的所有别名
String[] aliases = definitionHolder.getAliases();
if (aliases != null) {
for (String alias : aliases) {
// 往注册器的 aliasMap 添加 alias 的过程
registry.registerAlias(beanName, alias);
}
}
}
以上是关于07.Spring Bean 解析 - BeanDefinitionDocumentReader的主要内容,如果未能解决你的问题,请参考以下文章