两行代码轻松让 Java 实现大文本并行计算
Posted xmilu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了两行代码轻松让 Java 实现大文本并行计算相关的知识,希望对你有一定的参考价值。
简单提高文本读取效率,使用BufferedReader是个不错的选择。速度最快的方法是MappedByteBuffer,但是,相比BufferedReader而言,效果不是非常明显。也就是说,后者虽然快,但也快的有限(不要抱有性能提升几倍的幻想)。
对于大文本的读取,性能瓶颈主要在IO,read占时间多是正常的,硬盘本身就不快,读入内存后还要转成对象,都比较耗时间。
想要提速应当用并行的办法,用多线程同时读取和处理数据,但Java写多线程程序很麻烦,并行分段读同一个文件时还要考虑调整边界,也比较麻烦。
比如要这么个场景:分组汇总每个客户的销售额,部分源数据如下:
|
O_ORDERKEY O_CUSTKEY O_ORDERDATE O_TOTALPRICE 10262 RATTC 1996-07-22 14487.0 10263 ERNSH 1996-07-23 43818.0 10264 FOLKO 2007-07-24 1101.0 10265 BLONP 1996-07-25 5528.0 10266 WARTH 1996-07-26 7719.0 10267 FRANK 1996-07-29 20858.0 10268 GROSR 1996-07-30 19887.0 10269 WHITC 1996-07-31 456.0 10270 WARTH 1996-08-01 13654.0 ... |
期望的结果:
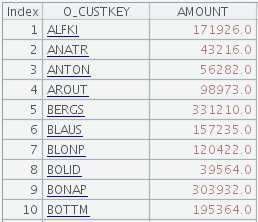
Java部分多线程代码大概要写成这样:
|
... final int DOWN_THREAD_NUM = 8; CountDownLatch doneSignal = new CountDownLatch(DOWN_THREAD_NUM); RandomAccessFile[] outArr = new RandomAccessFile[DOWN_THREAD_NUM]; try{ long length = new File(OUT_FILE_NAME).length(); long numPerThred = length / DOWN_THREAD_NUM; long left = length % DOWN_THREAD_NUM; for (int i = 0; i < DOWN_THREAD_NUM; i++) { outArr[i] = new RandomAccessFile(OUT_FILE_NAME, "rw"); ... if (i == DOWN_THREAD_NUM - 1) { new ReadThread(i * numPerThred, (i + 1) * numPerThred + left, outArr[i],keywords,doneSignal).start(); ... } else { new ReadThread(i * numPerThred, (i + 1) * numPerThred,outArr[i],keywords,doneSignal).start(); ... } } } ... |
如果有集算器就简单多了,它对Java的多线程进行了封装,提供了对大文件分段并行的功能,写起来容易多了,对人员要求也低。比如上面问题,2行就搞定了(集算器内置了并行选项@m,不设置并行数,默认按核数做为并行数):
|
|
A |
|
1 |
=file("/workspace/orders.txt").cursor@mt() |
|
2 |
=A1.groups(O_CUSTKEY;sum(O_TOTALPRICE):AMOUNT) |
其实还有很多情况用Java并行处理大文本很麻烦,甚至大文本分组、排序、关联计算等需求,但用集算器SPL却很简单,感兴趣可以参考:
集算器还很容易嵌入到Java应用程序中,Java如何调用SPL脚本有使用和获得它的方法。
关于集算器安装使用、获得免费授权和相关技术资料,可以参见如何使用集算器。
以上是关于两行代码轻松让 Java 实现大文本并行计算的主要内容,如果未能解决你的问题,请参考以下文章