原创Java并发编程系列26 | ConcurrentHashMap(上)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了原创Java并发编程系列26 | ConcurrentHashMap(上)相关的知识,希望对你有一定的参考价值。
【原创】Java并发编程系列26 | ConcurrentHashMap(上)
收录于话题
#进阶架构师 | 并发编程专题
12个点击上方“java进阶架构师”,选择右上角“置顶公众号”
20大进阶架构专题每日送达

终于轮到ConcurrentHashMap了,并发编程必备,也是面试必备。先说明两点:
本篇文章篇幅较长,考虑到阅读体验,分为上下两篇;
所有源码基于 JDK1.8。
本篇是ConcurrentHashMap上篇,主要介绍HashMap:
为什么先讲 HashMap
HashMap 数据结构
put()方法
get()方法
扩容
面试必备细节
1. 为什么讲 HashMap?
本来是讲解ConcurrentHashMap的文章,为什么要单独一篇介绍 HashMap 呢?
我们先来弄清楚为什么需要用到ConcurrentHashMap。HashMap 作为使用最频繁的集合之一,在多线程环境下是不能用的,因为 HashMap 的设计上就没有考虑并发环境,极易导致线程安全问题。为了解决该问题,提供了 Hashtable 和 Collections.synchronizedMap(hashMap)两种解决方案,但是这两种方案都是对读写加独占锁,一个线程在读时其他线程必须等待,吞吐量和性能都较低。故而 Doug Lea 大神给我们提供了高性能的线程安全 HashMap:ConcurrentHashMap。
所以,ConcurrentHashMap是为了解决 HashMap 的线程安全问题的,我们要先了解 HashMap 到底有什么问题才能理解ConcurrentHashMap是如何解决这些问题的。此外,ConcurrentHashMap和HashMap有相同的数据结构,在理解HashMap的基础上学习ConcurrentHashMap就可以把重点放在解决并发问题上。
2. 数据结构
HashMap 采用“数组+链表+红黑树”的数据结构,如下图: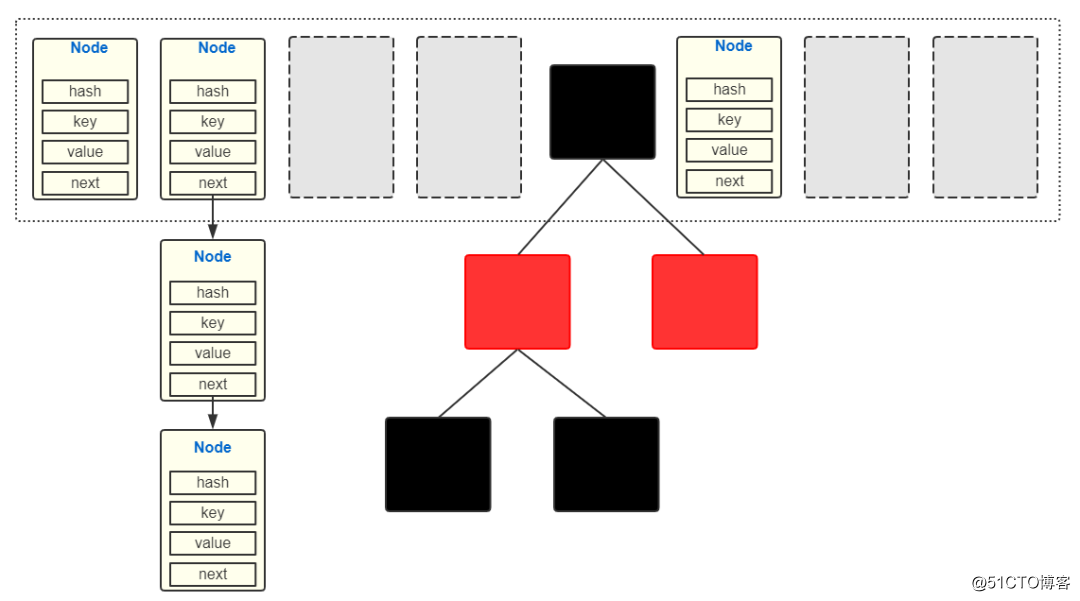
对应源码:
Node<K,V>[] table;// table数组存储结点
/**
* 结点
*/
Node {
int hash;
K key;
V value;
Node<K,V> next;
}3. put()方法
数组下标没有对应 hash 值,直接 newNode()添加
数组下标有对应 hash 值,添加到链表最后
链表超过最大长度(8),将链表改为红黑树再添加元素
结点在 table 数组中的位置计算:table[(length - 1) & hash] 。
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 如果table为空则扩容,扩容在下面单独讲解
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// table数组中hash值对应位置为空,直接构造成结点放入该位置
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
// table数组中hash值对应位置有数据
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// hash值对应位置结点为TreeNode,调用红黑树的插值方法,本文不展开说红黑树
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// hash值对应位置结点为Node,将数据插入链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果链表结点数达到8个,将链表转换为红黑树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 如果size超过了阈值,扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}多线程环境下,put()方法会有是什么问题呢?
tab[i] = newNode(hash, key, value, null);,首当其冲的就是这种赋值操作,很容易丢数据。如因为没有锁,线程 A 线程 B 可以同时检查得到tab[1]==null,然后线程 A 设置了tab[1]=Node(A),马上线程 B 又设置tab[1]=Node(B),那么线程 A 设置的数据就丢失了,而正确的操作应该是将 Node(B)插入链表中Node(A).next=Node(B)。
类似的赋值操作p.next = newNode(hash, key, value, null);,也有同样的问题。
++size,普通变量 size 没有可见性保证,++操作也没有保证原子性,这个计算在多线程环境下一定是有问题的。
在一个线程 put()过程中,可能有其他线程有 put 和 remove,导致当前线程 put 失败。
4. get()方法
先从数组中取,取到 hash 值相等且 equals 的,直接返回
取到 hash 值相等且!equals,到链表/红黑树中取
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) { // 取出数组中hash值对应的Node
// 先检查第一个Node是不是要找的Node,如果是就返回
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 第一个Node不是要找的Node,到后面的链表/红黑树中找
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 遍历后面的链表,找到key值和hash值都相同的Node返回
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}多线程环境下,get()方法有什么问题?
由于 table 数组没有保证内存可见性,在一个线程删除/添加某个结点后并不能及时刷新到主内存中,另一个线程通过 get()方法获取该结点就会出错。
5. 扩容 resize()
newTab = new Node[2*length],创建一个两倍于原来数组 oldTab 的新数组 newTab,遍历 oldTable,将 oldTab 中的结点转移到 newTab 中。
如果桶中 oldTab[i]只有一个元素 node,直接将 node 放入 newTab[node.hash & (newCap - 1)]中。
如果桶中 oldTab[i]是链表,分成两个链表分别放入 newTab[i]和 newTab[i+oldTab.length]。
如果桶中 oldTab[i]是树,树打散成两颗树插入到新桶中去。
扩容操作问题 1:如果桶中 oldTab[i]只有一个元素 node,直接将 node 放入 newTab[j]中,此时 newTab[j]中没有值吗?如果有值,原来的数据不就丢了?
此时 newTab[j]一定为空。oldTab[i]桶中只有 node 一个值说明 node 是没有 hash 冲突的,也就是不会有其他结点的 hash 值与 node.hash 相等,所以放入 newTab[j]也只会有 node 这一个结点。
扩容操作问题 2:如果桶中 oldTab[i]是链表,为什么要分成两个链表,这两个链表是如何分的?
同一个链表中的结点是因为哈希冲突导致的。看下这种情况:
oldTab.length=16 oldTab.length-1=15=0000 1111
node1.hash=1111 1001 node1.hash&(length-1)=1001=9
node2.hash=1110 1001 node1.hash&(length-1)=1001=9
所以node1和node2是在table[9]桶中的同一个链表里的。扩容后 node1 和 node2 在 newTab 中的位置和原来可能不一样。因为 node1.hash 和 node2.hash 第 5 位(也就是 oldTab.length 最高位)不同,在 newTable 中计算的位置也就不同。
计算node1在newTab中的位置:
node1.hash&(newTab.length-1)=(1111 1001 & 0001 1111)=0001 1001=25=9+16 (高位)
计算node2在newTab中的位置:
node2.hash&(newTab.length-1)=(1110 1001 & 0001 1111)=0000 1001=9 还是原来的位置(低位)扩容时,根据(node.hash & oldTab.length)是否为 0 来区分 node 应该在哪个链表,其实就是根据 node 的第 5 位(也就是 oldTab.length 最高位)是 0/1 来区分。
newTab.length=32 newTab.length-1=0001 1111
(node.hash & oldTab.length) == 0 加入低位链表
(node.hash & oldTab.length) != 0 加入高位链表
来看下源码:final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) { // 对应数组扩容
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 将数组大小扩大一倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// 将阈值扩大一倍
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // 对应使用 new HashMap(int initialCapacity) 初始化后,第一次 put 的时候
newCap = oldThr;
else {// 对应使用 new HashMap() 初始化后,第一次 put 的时候
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
// 用新的数组大小初始化新的数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab; // 如果是初始化数组,到这里就结束了,返回 newTab 即可
if (oldTab != null) {
// 开始遍历原数组,进行数据迁移。
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
// 如果该数组位置上只有单个元素,直接迁移这个元素
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
// 红黑树
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else {
// 这块是处理链表的情况,
// 需要将此链表拆成两个链表,放到新的数组中,并且保留原来的先后顺序
// loHead、loTail 对应一条链表,hiHead、hiTail 对应另一条链表,代码还是比较简单的
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
// 第一条链表
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
// 第二条链表的新的位置是 j + oldCap
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;}
> 多线程环境下,因为 resize()方法更复杂,调用更多,所以它的线程安全问题也更多。同样是因为操作共享数据时没有加锁,table、size 的操作内存不可见等。
# 6. 一些细节
-----
HashMap 源码中还有一些细节需要注意,对于我们编码能力的提升以及面试都很有好处。
6.1 计算 table 中的位置
hash&(table.length-1)
为了保证 hash 值能在 table 中找到位置,常用取余的方式hash%(table.length-1)。JDK 源码肯定是非常注重效率的,所以用位运算代替除法运算,所以hash&(table.length-1)。
为了保证hash&(table.length-1)得到的结果在 table 的范围内,就需要保证 table.length 始终是 2 的次幂。源码中通过 tableSizeFor()方法保证 table.length 始终是 2 的次幂:static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
6.2 hash 值计算
int hash = (h = key.hashCode()) ^ (h >>> 16);
hash 为什么不直接用key.hashCode()呢?计算 hash 值时,考虑的最重要问题就是减少 hash 冲突。让 key.hashCode()的高 16 位更多的参与到 hash 值的计算中,可以减少哈希冲突。
所以,哈希冲突(hash&(table.length-1)相等)两种情况:①hash 值相等 ②hash 值不相等 但 hash&(table.length-1)相等
6.3 装载因子阀值为什么用 0.75
这是权衡时间复杂度和空间复杂度的结果。
* 阈值高,空间利用率好,哈希冲突多执行效率低。
* 阈值低,哈希冲突少执行效率高,空间利用率低。
6.4 红黑树扫盲
近似平衡的二叉查找树
① 根结点是黑色的 ② 每个叶子结点都是黑色的空结点(NIL),也就是说,叶子结点不存储数据;③ 任何相邻的结点都不能同时为红色,也就是说,红色结点是被黑色结点隔开的;④ 每个结点,从该结点到达其可达叶子结点的所有路径,都包含相同数目的黑色结点;
查找时间复杂度:O(logn)
插入、删除操作都需要做平衡,平衡时有可能会改变根结点的位置,颜色转换,左旋,右旋等。
6.5 为什么 hashmap 不直接采用红黑树,而是当大于 8 个的时候才转换红黑树?
当结点小于 8 时,直接遍历链表效率并不低,而红黑树结构复杂维护成本高
6.6 为什么链表长度为 8 时转为红黑树,而树结点数为 6 时才转为链表?
假设一下,如果设计成链表个数超过 8 则链表转换成树结构,链表个数小于 8 则树结构转换成链表。当一个 HashMap 不停的插入、删除元素,链表个数在 8 左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
# 7. 总结
-----
HashMap 采用“数组+链表+红黑树”的数据结构。
HashMap 的设计上就没有考虑并发环境,极易导致线程安全问题。
table 数组、size 等共享数据都没有保证内存可见性,其操作也没有保证原子性,会导致线程安全问题。
散列桶中的结点、链表、红黑树的读写操作并没有加锁保证同步,同样会导致线程安全问题。
为了解决 HashMap 的并发问题,JDK 提供了高性能的线程安全 HashMap:ConcurrentHashMap。
# 并发系列文章汇总
-----
【原创】01|开篇获奖感言
【原创】02|并发编程三大核心问题
【原创】03|重排序-可见性和有序性问题根源
【原创】04|Java 内存模型详解
【原创】05|深入理解 volatile
【原创】06|你不知道的 final
【原创】07|synchronized 原理
【原创】08|synchronized 锁优化
【原创】09|基础干货
【原创】10|线程状态
【原创】11|线程调度
【原创】12|揭秘 CAS
【原创】13|LockSupport
【原创】14|AQS 源码分析
【原创】15|重入锁 ReentrantLock
【原创】16|公平锁与非公平锁
【原创】17|读写锁八讲(上)
【原创】18|读写锁八讲(下)
【原创】19|JDK8新增锁StampedLock
【原创】20|StampedLock源码解析
【原创】21|Condition-Lock的等待通知
【原创】22|倒计时器CountDownLatch
【原创】22|倒计时器CountDownLatch
【原创】23|循环屏障CyclicBarrier
【原创】24|信号量Semaphore
之前,给大家发过四份Java面试宝典,这次新增了更全面的资料,相信在跳槽前准备准备,基本没大问题。
《java基础:设计模式等》(初中级)
《JVM:整理BAT最新题库》《并发编程》(中高级)
《分布式微服务架构》《架构|软技能》(资深)
《一线互联网公司面试指南》(资深)
学习视频包含深入运行时数据区、垃圾回收、详解类装载过程及类加载机制、手写Spring-IOC容器、redis入门到高性能缓存组件等等

获取方式:点“在看”,在公众号后台打开,回复 【666】即可领取,资料持续更新。
看到这里,证明有所收获
必须点个在看支持呀,喵以上是关于原创Java并发编程系列26 | ConcurrentHashMap(上)的主要内容,如果未能解决你的问题,请参考以下文章
原创Java并发编程系列27 | ConcurrentHashMap(下)