JAVA基础
Posted 英飞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JAVA基础相关的知识,希望对你有一定的参考价值。
JAVA 基础
- JAVA 基础
- 一 基本语法
- 二 变量
- 三 面向对象
- 四 集合
- 五 字符串
- 六 其他API
- 七 JDBC
- 八 IO 输入输出
- 九 多线程
- 十网络编程
一 基本语法
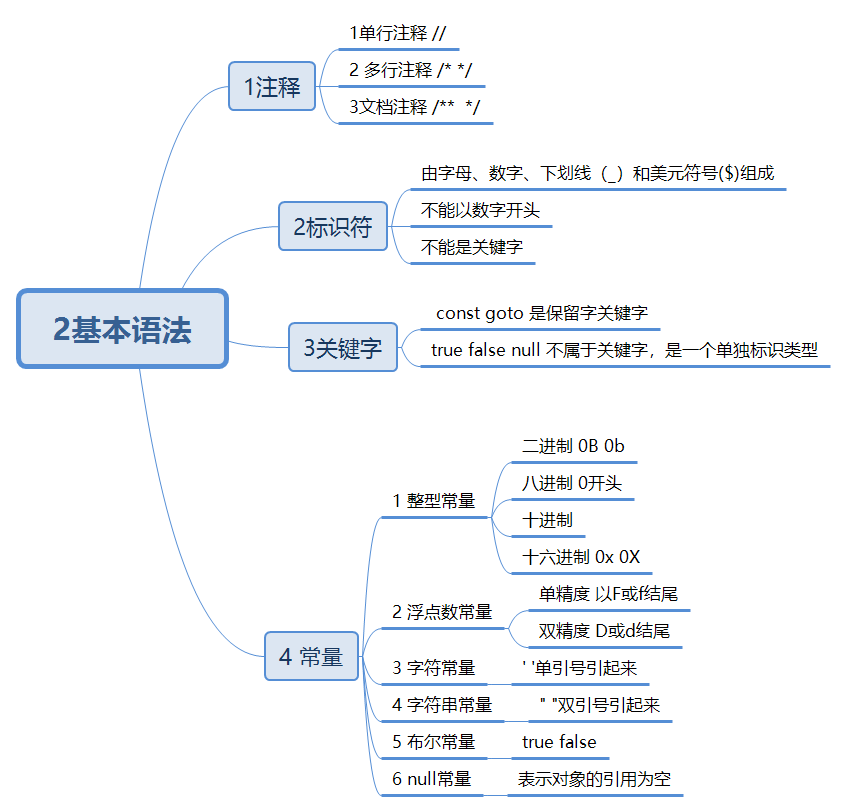
注释
标识符
- 由字母、数字、下划线(_)和美元符号($)组成
- 不能以数字开头
- 不能是关键字
关键字
- const goto 是保留关键字
- true false null 不属于关键字,是一个单独的标识类型
运算符
常量
- 整型常量
- 二进制 0B 0b
- 八进制 0开头
- 十进制
- 十六进制 0x 0X
- 浮点型常量
- 单精度 以F或f结尾
- 双精度 以D或d结尾
- 字符常量
- 单引号‘ ’括起来
- 字符串常量
- 双引号“”引起来
- 布尔常量
- true
- false
- null 常量
- 表示对象的引用为空
选择结构
循环结构
九九乘法表
for (int i=1;i<=9;i++){
for(int j=1;j<=9;j++) {
if (i >= j) {
System.out.print(j + "*" + i +" = " + i * j + " ");
}
}
System.out.println();
}
打印三角形
//打印等边三角形 参数 n是行数
int n=4;
for(int i=1;i<=n;i++){
for (int k=1; k <=n-i; k++) {
System.out.print(" ");
}
for (int k =1; k <= 2*i-1 ; k++) {
System.out.print("*");
}
System.out.println();
}
打印正方形
//打印正方形 参数 n
n=4;
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++){
if(i==1 || i==n ) {//第一行和最后一行打印星号
System.out.print("*");
}else if(j==1 || j==n ){//第一列和最后一列打印星号
System.out.print("*");
}else{
System.out.print(" ");
}
}
System.out.println();
}
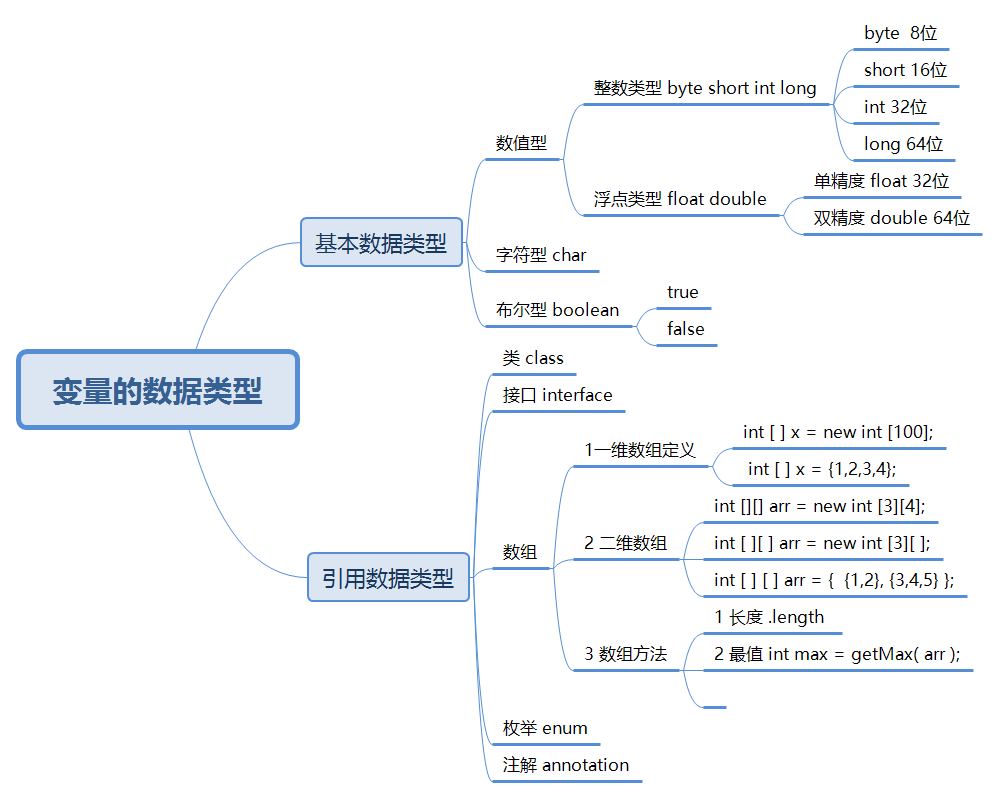
二 变量
变量的数据类型
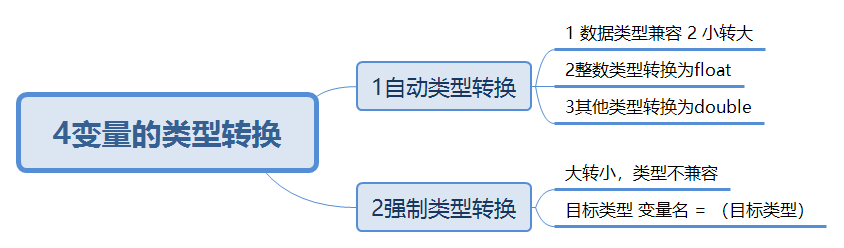
变量的类型转换
变量和常量的区别
三 面向对象
面向对象的特征(继承,封装,多态)。
面向对象是把构成问题的事务按一定规则划分为多个对象,然后通过调用对象的方法解决问题。
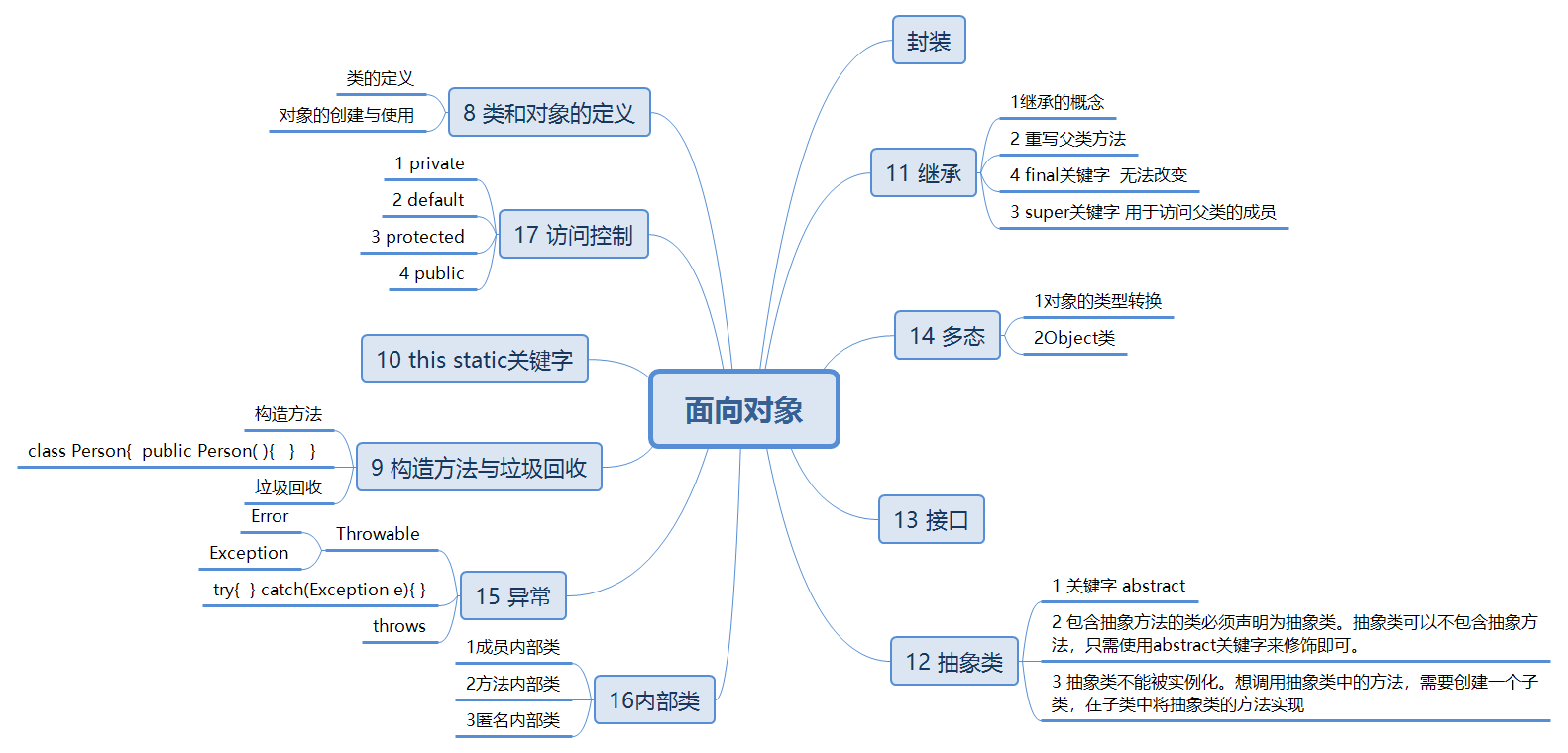
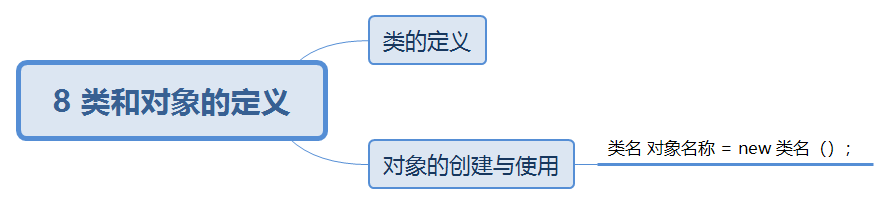
类与对象
类是对象的抽象,用于描述一组对象的共同特征和行为。其中成员变量用于描述对象的特征,也称为属性;成员方法用于描述对象的行为,简称为方法。
对象是类的实例。
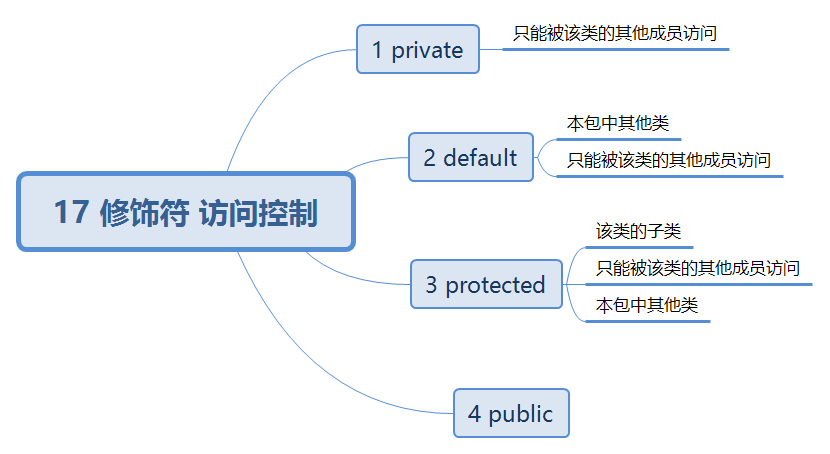
作用域——访问控制
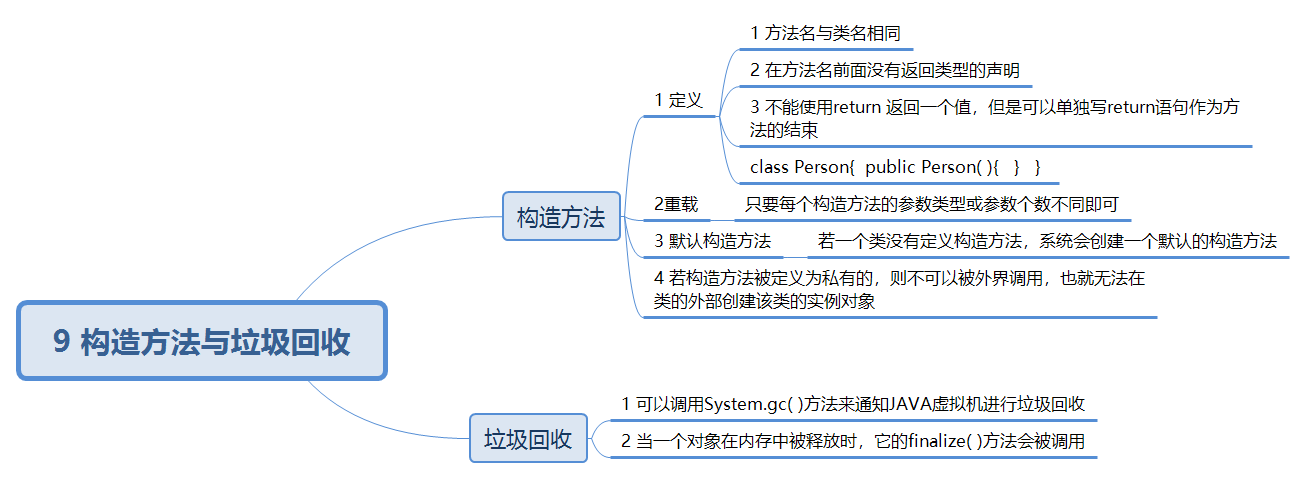
构造方法与垃圾回收
this static 关键字

继承

抽象类

抽象类除了不能实例化对象之外,类的其它功能依然存在,成员变量、成员方法和构造方法的访问方式和普通类一样。
由于抽象类不能实例化对象,所以抽象类必须被继承,才能被使用
接口
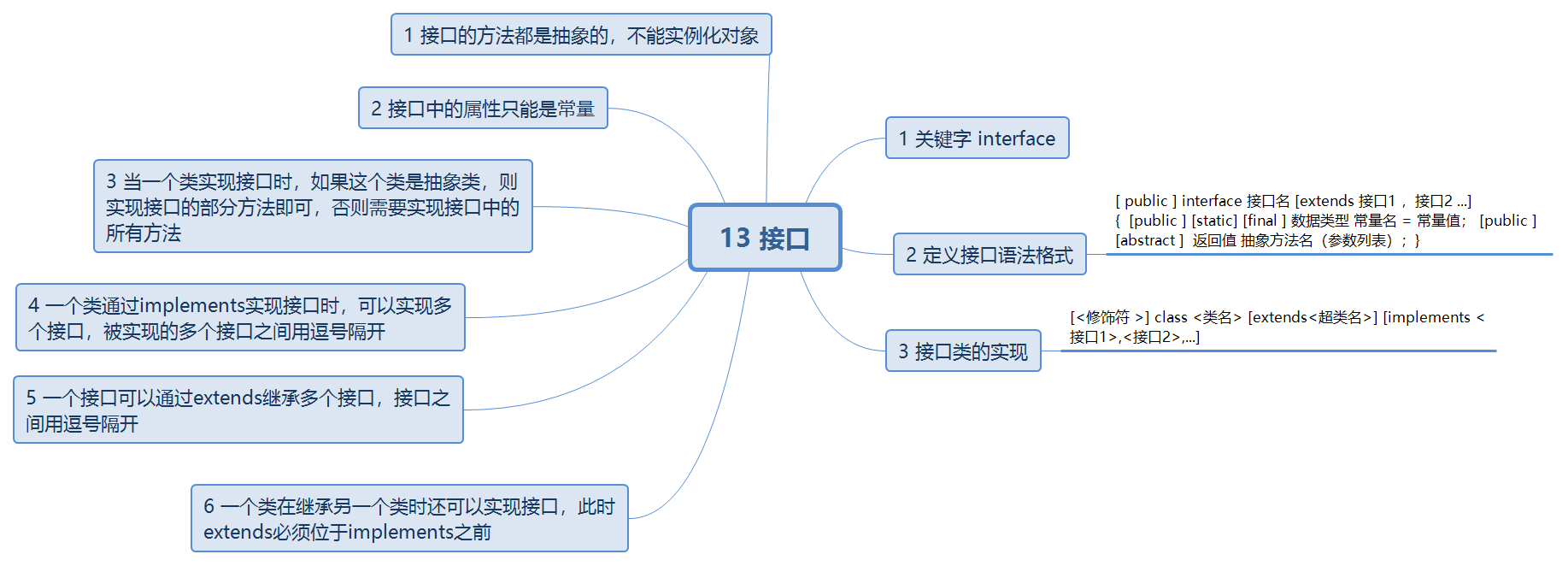
注意
- 接口的方法都是抽象的,不能实例化对象
- 接口中的属性只能是常量
- 当一个类实现接口时,如果这个类是抽象类,则实现接口的部分方法即可,否则需要实现接口中的所有方法
- 一个类通过implements实现接口时,可以实现多个接口,被实现的多个接口之间用逗号隔开
- 一个接口可以通过extends继承多个接口,接口之间用逗号隔开
多态

多态是同一个行为具有多个不同表现形式或形态的能力。多态就是同一个接口,使用不同的实例而执行不同操作。
多态的优点
消除类型之间的耦合关系;可替换性; 可扩充性;接口性;灵活性;简化性
多态存在的三个必要条件
- 继承
- 重写
- 父类引用指向子类对象:Parent p = new Child();
多态的实现方式
-
重写:
-
重写(Override)
重写是子类对父类的允许访问的方法的实现过程进行重新编写, 返回值和形参都不能改变。即外壳不变,核心重写!重写的好处在于子类可以根据需要,定义特定于自己的行为。 也就是说子类能够根据需要实现父类的方法。
-
重载(Overload)
重载(overloading) 是在一个类里面,方法名字相同,而参数不同。返回类型可以相同也可以不同。每个重载的方法(或者构造函数)都必须有一个独一无二的参数类型列表。最常用的地方就是构造器的重载。
-
-
接口:
接口(Interface),在JAVA编程语言中是一个抽象类型,是抽象方法的集合,接口通常以interface来声明。一个类通过继承接口的方式,从而来继承接口的抽象方法。
-
抽象类和抽象方法
在面向对象的概念中,所有的对象都是通过类来描绘的,但是反过来,并不是所有的类都是用来描绘对象的,如果一个类中没有包含足够的信息来描绘一个具体的对象,这样的类就是抽象类。在Java中抽象类表示的是一种继承关系,一个类只能继承一个抽象类,而一个类却可以实现多个接口
异常

四 集合
java集合框架图
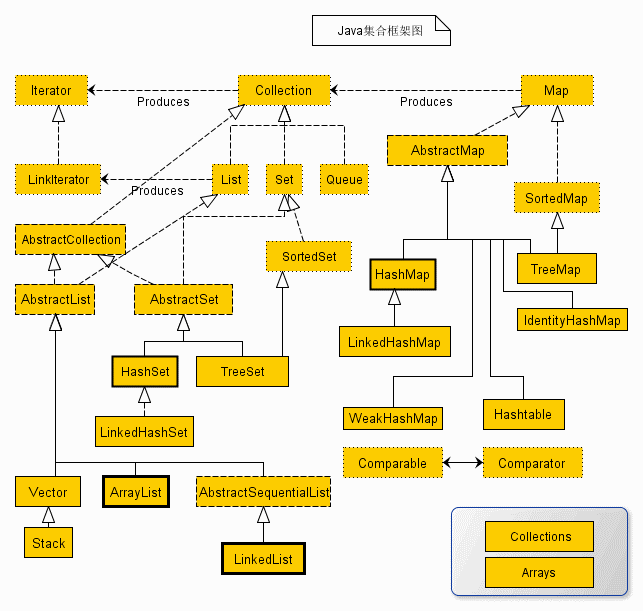
从上面的集合框架图可以看到,
Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射。
Collection 接口又有 3 种子类型,List、Set 和 Queue,再下面是一些抽象类,最后是具体实现类,常用的有 ArrayList、LinkedList、HashSet、LinkedHashSet、HashMap、LinkedHashMap 等等。
集合框架是一个用来代表和操纵集合的统一架构。所有的集合框架都包含如下内容:
- 接口:是代表集合的抽象数据类型。例如 Collection、List、Set、Map 等。之所以定义多个接口,是为了以不同的方式操作集合对象
- 实现(类):是集合接口的具体实现。从本质上讲,它们是可重复使用的数据结构,例如:ArrayList、LinkedList、HashSet、HashMap。
- 算法:是实现集合接口的对象里的方法执行的一些有用的计算,例如:搜索和排序。这些算法被称为多态,那是因为相同的方法可以在相似的接口上有着不同的实现。
除了集合,该框架也定义了几个 Map 接口和类。Map 里存储的是键/值对。尽管 Map 不是集合,但是它们完全整合在集合中。
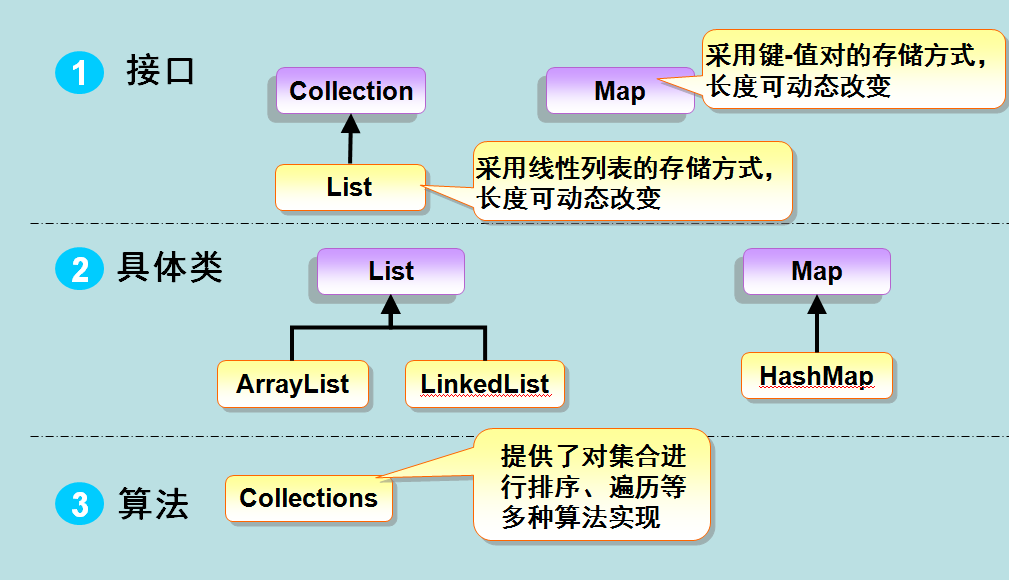
Java 集合框架提供了一套性能优良,使用方便的接口和类,java集合框架位于java.util包中, 所以当使用集合框架的时候需要进行导包。
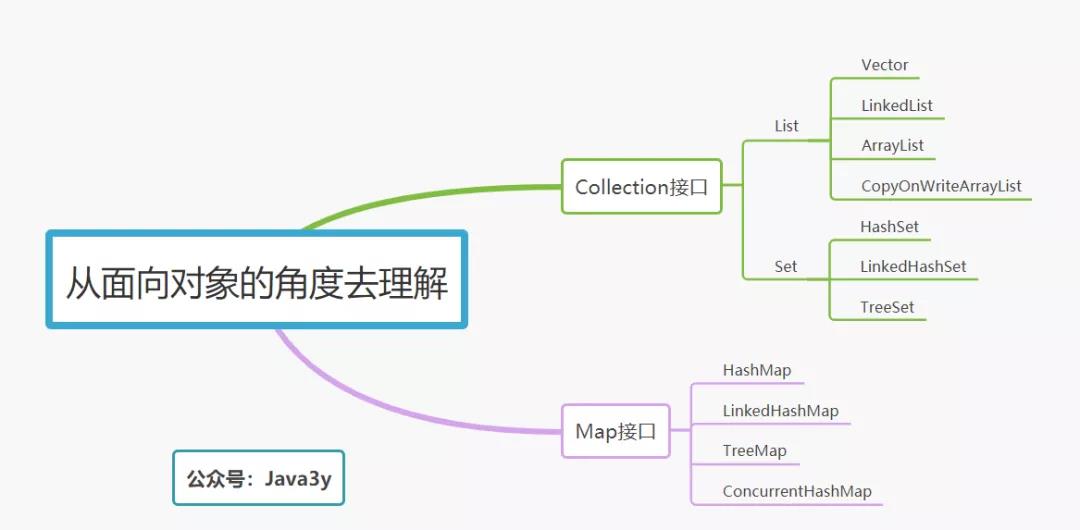
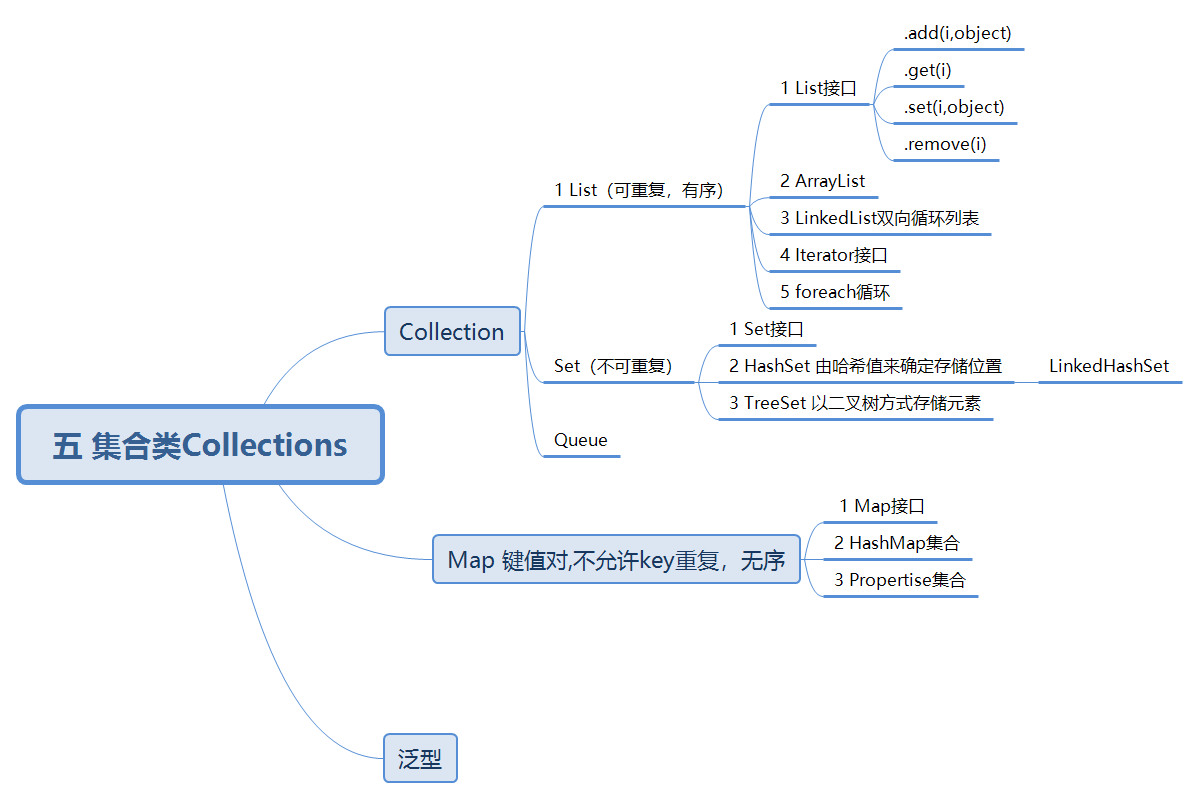
结论
-
如果是集合类型,有List和Set供我们选择。
List的特点是插入有序的,元素是可重复的。Set的特点是插入无序的,元素不可重复的。
至于选择哪个实现类来作为我们的存储容器,我们就得看具体的应用场景。是希望可重复的就得用List,选择List下常见的子类。是希望不可重复,选择Set下常见的子类。
-
如果是
Key-Value型,那我们会选择Map。如果要保持插入顺序的,我们可以选择LinkedHashMap,如果不需要则选择HashMap,如果要排序则选择TreeMap。
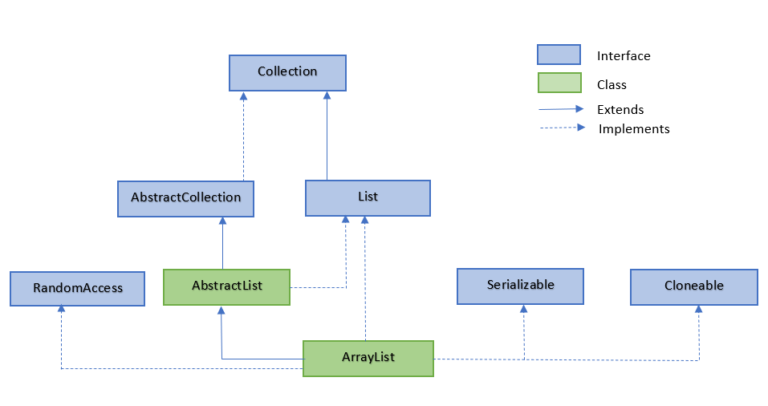
List
2 ArrayList
ArrayList 类是一个可以动态修改的数组,与普通数组的区别就是它是没有固定大小的限制,我们可以添加或删除元素。
ArrayList 继承了 AbstractList ,并实现了 List 接口。
ArrayList 类位于 java.util 包中,使用前需要引入它,语法格式如下:
import java.util.ArrayList; // 引入 ArrayList 类
ArrayList<E> objectName =new ArrayList<>(); // 初始化
- E: 泛型数据类型,用于设置 objectName 的数据类型,只能为引用数据类型。
ArrayList的创建
面试官:“那我们本身就有数组了,为什么要用ArrayList呢?”
三歪:“原生的数组会有一个特点:你在使用的时候必须要为它创建大小,而ArrayList不用”
面试官:“那你说说ArrayList是怎么实现的吧,为什么ArrayList就不用创建大小呢?”
三歪:“其实是这样的,我看过源码。当我们new ArrayList()的时候,默认会有一个空的Object数组,大小为0。当我们第一次add添加数据的时候,会给这个数组初始化一个大小,这个大小默认值为10”
private static final int DEFAULT_CAPACITY = 10;
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;
面试官:“嗯”
ArrayList存取元素
ArrayList集合中的大部分方法是从父类Collection和List继承过来的,其中add()和get()方法用于元素的存取。
- 使用ArrayList在每一次
add的时候,它都会先去计算这个数组够不够空间,如果空间是够的,那直接追加上去就好了。如果不够,那就得扩容”
// Positional Access Operations
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
/**
* Returns the element at the specified position in this list.
*
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
/**
* Checks if the given index is in range. If not, throws an appropriate
* runtime exception. This method does *not* check if the index is
* negative: It is always used immediately prior to an array access,
* which throws an ArrayIndexOutOfBoundsException if index is negative.
*/
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
- get()方法,首先查看下标是否越界,如果越界会抛出IndexOutOfBoundsException异常,根据索引取出对应元素。
ArrayList 动态扩容的实现
面试官:“那它是怎么实现的呢?”
三歪:“使用ArrayList在每一次add的时候,它都会先去计算这个数组够不够空间,如果空间是够的,那直接追加上去就好了。如果不够,那就得扩容”
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return <tt>true</tt> (as specified by {@link Collection#add})
*/
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
面试官:“那怎么扩容?一次扩多少?”
三歪:“在源码里边,有个grow方法,每一次扩原来的1.5倍。比如说,初始化的值是10嘛。现在我第11个元素要进来了,发现这个数组的空间不够了,所以会扩到15”
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
三歪:“空间扩完容之后,会调用arraycopy来对数组进行拷贝”
面试官:“哦,可以的。那为什么你在前面提到,在日常开发中用得最多的是ArrayList呢?”
三歪:“是由底层的数据结构来决定的,在日常开发中,遍历的需求比增删要多,即便是增删也是往往在List的尾部添加就OK了。像在尾部添加元素,ArrayList的时间复杂度也就O(1)”
三歪:“另外的是,ArrayList的增删底层调用的copyOf()被优化过,现代CPU对内存可以块操作,ArrayList的增删一点儿也不会比LinkedList慢”
3 Vector
面试官:“Vector你了解吗?”
三歪:“嗯,Vector是底层结构是数组,一般现在我们已经很少用了。相对于ArrayList,它是线程安全的,在扩容的时候它是直接扩容两倍的,比如现在有10个元素,要扩容的时候,就会将数组的大小增长到20”。
Vector 类实现了一个动态数组。和 ArrayList 很相似,但是两者是不同的:
- Vector 是同步访问的。
- Vector 包含了许多传统的方法,这些方法不属于集合框架。
Vector 主要用在事先不知道数组的大小,或者只是需要一个可以改变大小的数组的情况。
public class Vector<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
Vector与ArrayList的比较
https://blog.csdn.net/qq_37113604/article/details/80836025
ArrayList出现于jdk1.2,vector出现于1.0.
相同点
- 两者底层的数据存储都使用的Object数组实现,因为是数组实现,所以具有查找快(因为数组的每个元素的首地址是可以得到的,数组是0序的,所以: 被访问元素的首地址=首地址+元素类型字节数*下标 ),增删慢(因为往数组中间增删元素时,会导致后面所有元素地址的改变)的特点
- 继承的类实现的接口都是一样的,都继承了AbstractList类(继承后可以使用迭代器遍历),实现了RandomAccess(标记接口,标明实现该接口的list支持快速随机访问),cloneable接口(标识接口,合法调用clone方法),serializable(序列化标识接口)
- 当两者容量不够时,都会进行对Object数组的扩容
不同点
-
ArrayList的默认构造方法,会默认分配长度为10的内存空间,这里的分配不是在创建对象时分配,而是在增加第一条数据的过程中分配,这样防止了内存的浪费),然后进行Arrays.copyOf 。如果再次扩容的话,扩容到当前容量的1.5倍。arraylist默认增长1.5倍;vector可以自定义若不自定义,则增长2倍,若定义则新长度=之前的长度+增长因子。
-
线程的安全性不同,vector是线程安全的,在vector的大多数方法都使用synchronized关键字修饰,arrayList是线程不安全的(可以通过Collections.synchronizedList()实现线程安全)
-
性能上的差别,由于vector的方法都有同步锁,在方法执行时需要加锁、解锁,所以在执行过程中效率会低于ArrayList,另外,性能上的差别还体现在底层的Object数组上
vector:
arrayList:
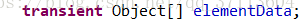
可以看出来,arrayList多了一个transient关键字,这个关键字的作用是防止序列化,然后在ArrayList中重写了了readObject和writeObject方法,这样是为了在传输时提高效率,
4 CopyOnWriteArrayList
面试官:“嗯,那如果我们不用Vector,线程安全的List还有什么?”
三歪:“首先,我们也可以用Collections来将ArrayList来包装一下,变成线程安全。但这肯定不是你想听的,对吧。在java.util.concurrent包下还有一个类,叫做CopyOnWriteArrayList”
面试官:“嗯,你继续说”
三歪:“要讲CopyOnWriteArrayList之前,我还是想说说copy-on-write这个意思,下面我会简称为cow。比如说在Linux中,我们知道所有的进程都是init进程fork出来的,除了进程号之外,fork出来的进程,默认跟父进程一模一样的。在fork之后exec之前,两个进程用的是相同的内存空间的,这意味着子进程的代码段、数据段、堆栈都是指向父进程的物理空间”
面试官:“嗯”
三歪:“当父子进程中有更改的行为发生时,再为子进程分配相应物理空间。这样做的好处就是,等到真正发生修改的时候,才去分配资源,可以减少分配或者复制大量资源时带来的瞬间延时。简单来说,就可以理解为我们的懒加载,或者说单例模式的懒汉式。等真正用到的时候再分配”
面试官:“嗯”
三歪:“在文件系统中,其实也有cow的机制。文件系统的cow就是在修改数据的时候,不会直接在原来的数据位置上进行操作,而是重新找个位置修改。比如说:要修改数据块A的内容,先把A读出来,写到B块里面去。如果这时候断电了,原来A的内容还在。这样做的好处就是可以保证数据的完整性,瞬间挂掉了容易恢复。
三歪:“再回头来看CopyOnWriteArrayList吧,CopyOnWriteArrayList是一个线程安全的List,底层是通过复制数组的方式来实现的。
三歪:“我来说说它 的add()方法的实现吧”
面试官:“好”
三歪:“在add()方法其实他会加lock锁,然后会复制出一个新的数组,往新的数组里边add真正的元素,最后把array的指向改变为新的数组”
三歪:“其实get()方法又或是size()方法只是获取array所指向的数组的元素或者大小。读不加锁,写加锁”
三歪:“可以发现的是,CopyOnWriteArrayList跟文件系统的COW机制是很像的”
面试官:“那你能说说CopyOnWriteArrayList有什么缺点吗?”
三歪:“很显然,CopyOnWriteArrayList是很耗费内存的,每次set()/add()都会复制一个数组出来,另外就是CopyOnWriteArrayList只能保证数据的最终一致性,不能保证数据的实时一致性。假设两个线程,线程A去读取CopyOnWriteArrayList的数据,还没读完,现在线程B把这个List给清空了,线程A此时还是可以把剩余的数据给读出来。”
5 LinkedList
Java LinkedList(链表) 类似于 ArrayList,是一种常用的数据容器。
该集合内部维护了一个双向循环链表。与 ArrayList 相比,LinkedList 的增加和删除对操作效率更高,而查找和修改的操作效率较低。
以下情况使用 ArrayList :
- 频繁访问列表中的某一个元素。
- 只需要在列表末尾进行添加和删除元素操作。
以下情况使用 LinkedList :
- 你需要通过循环迭代来访问列表中的某些元素。
- 需要频繁的在列表开头、中间、末尾等位置进行添加和删除元素操作。
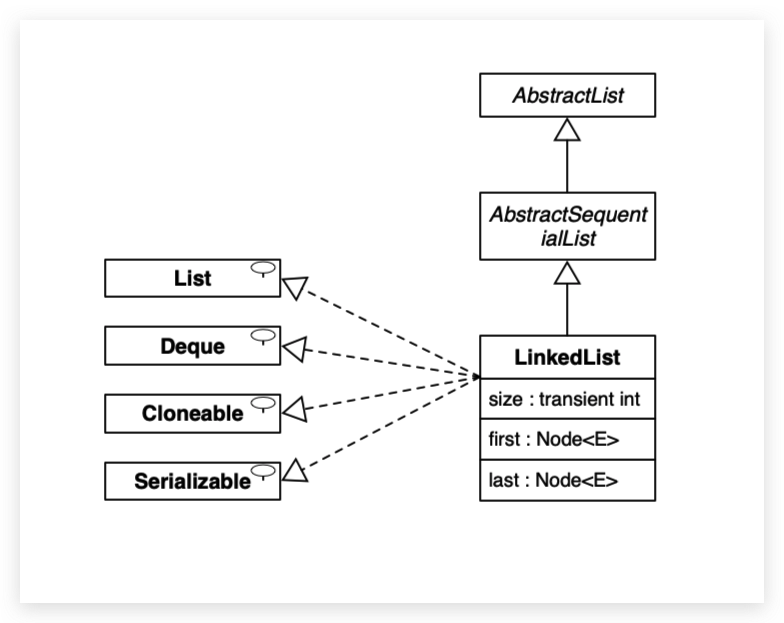
LinkedList 继承了 AbstractSequentialList 类。LinkedList 实现了 Queue 接口,可作为队列使用。
LinkedList 实现了 List 接口,可进行列表的相关操作。LinkedList 实现了 Deque 接口,可作为队列使用。
LinkedList 实现了 Cloneable 接口,可实现克隆。LinkedList 实现了 java.io.Serializable 接口,即可支持序列化,能通过序列化去传输
Set
与List不同Set接口中的元素无序,并且都会以某种规则保证存入的元素不会重复。
Set接口中主要有两个实现类,分别是HahSet和TreeSet。其中 根据对象的哈希值来确定元素在集合中的存储位置,因此具有良好的存取和查找性能。TreeSet则是以二叉树的实行来存储元素,他可以实现对集合中的元素进行排序。
HashSet
HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合。
HashSet 允许有 null 值。
HashSet 是无序的,即不会记录插入的顺序。
HashSet 不是线程安全的, 如果多个线程尝试同时修改 HashSet,则最终结果是不确定的。 您必须在多线程访问时显式同步对 HashSet 的并发访问。
HashSet 实现了 Set 接口。
HashSet如何保证不出现重复元素
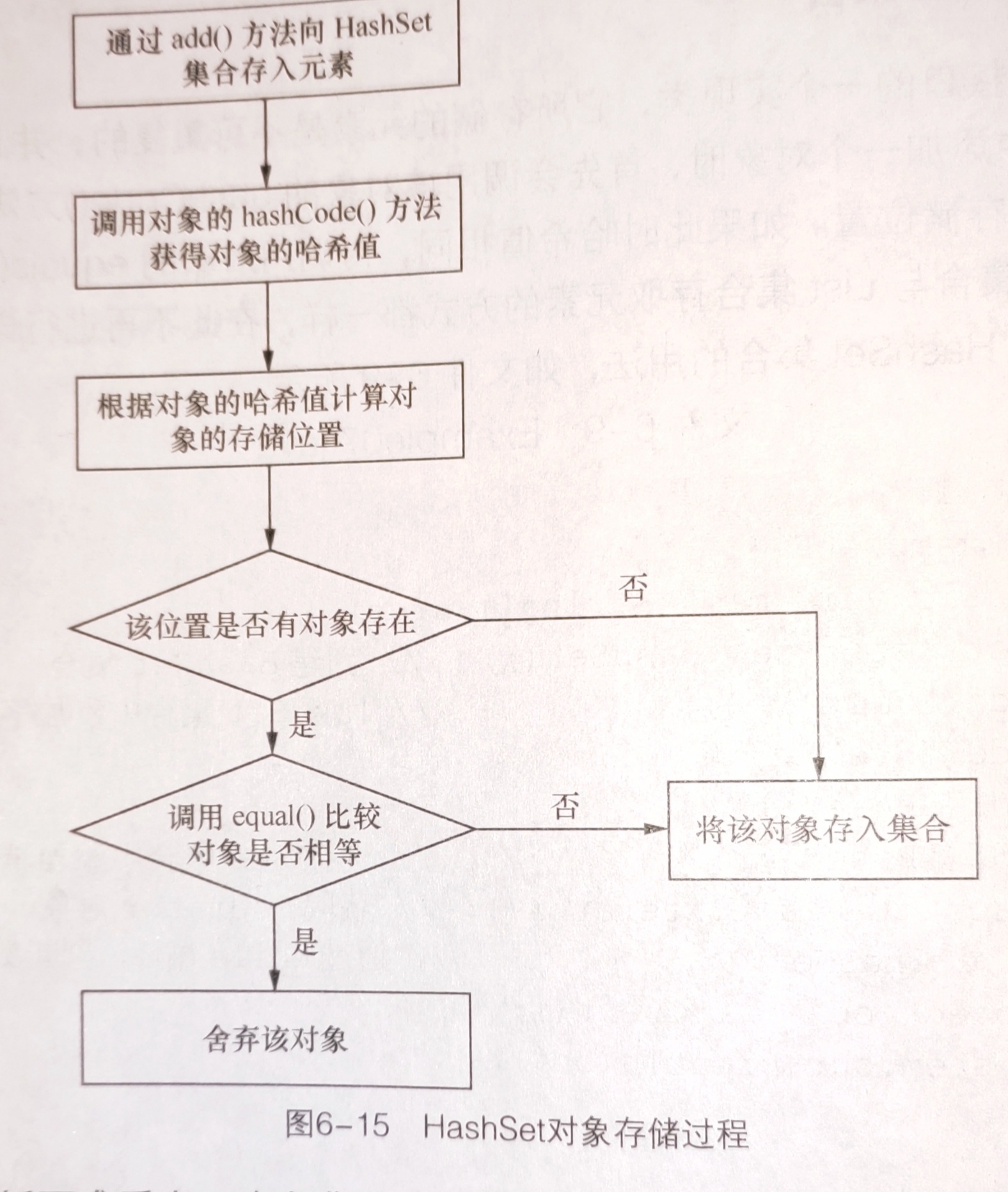
**
* Adds the specified element to this set if it is not already present.
* More formally, adds the specified element <tt>e</tt> to this set if
* this set contains no element <tt>e2</tt> such that
* <tt>(e==null ? e2==null : e.equals(e2))</tt>.
* If this set already contains the element, the call leaves the set
* unchanged and returns <tt>false</tt>.
*
* @param e element to be added to this set
* @return <tt>true</tt> if this set did not already contain the specified
* element
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}java
HashSet和HashMap的区别
| HashMap | HashSet |
|---|---|
| HashMap实现了Map接口 | HashSet实现了Set接口 |
| HashMap储存键值对 | HashSet仅仅存储对象 |
| 使用put()方法将元素放入map中 | 使用add()方法将元素放入set中 |
| HashMap中使用键对象来计算hashcode值 | HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false |
| HashMap比较快,因为是使用唯一的键来获取对象 | HashSet较HashMap来说比较慢 |
Map
Map接口是一种双列集合,每个元素都包含一个键对象Key和一个值对象Value,键和值对象之间存在一种对应关系,称为映射。
“Map在Java里边是一个接口,常见的实现类有HashMap、LinkedHashMap、TreeMap和ConcurrentHashMap”
Map的数据结构
在Java里边,
哈希表的结构是数组+链表的方式。
HashMap底层数据机构是数组+链表/红黑树、
LinkedHashMap底层数据结构是数组+链表+双向链表、
TreeMap底层数据结构是红黑树,
而ConcurrentHashMap底层数据结构也是数组+链表/红黑树”
Map集合常用方法表
| 方法声明 | 功能描述 |
|---|---|
| boolean containsKey(Object key); | Returns true if this map contains a mapping for the specified key. |
| boolean containsValue(Object value); | Returns true if this map maps one or more keys to the specified value. |
| V get(Object key); | Returns the value to which the specified key is mapped, or {@code null} if this map contains no mapping for the key. |
| V put(K key, V value); | Associates the specified value with the specified key in this map (optional operation). If the map previously contained a mapping for the key, the old value is replaced by the specified value. |
| V remove(Object key); | Removes the mapping for a key from this map if it is present (optional operation). |
| void clear(); | Removes all of the mappings from this map (optional operation). The map will be empty after this call returns. |
| Set |
Return a set view of the keys contained in this map |
| Collection |
Return a collection view of the values contained in this map |
| Set<Map.Entry<K, V>> entrySet(); | Return a set view of the mappings contained in this map |
HashMap
HashMap的实现与存储结构
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 实现了 Map 接口,根据键的 HashCode 值存储数据,具有很快的访问速度,最多允许一条记录的键为 null,不支持线程同步。
HashMap 是无序的,即不会记录插入的顺序。
HashMap 继承于AbstractMap,实现了 Map、Cloneable、java.io.Serializable 接口。HashMap 实现了 Serializable 接口,因此它支持序列化,实现了 Cloneable 接口,能被克隆。
HashMap 是非线程安全的,只是用于单线程环境下,多线程环境下可以采用 concurrent 并发包下的 concurrentHashMap
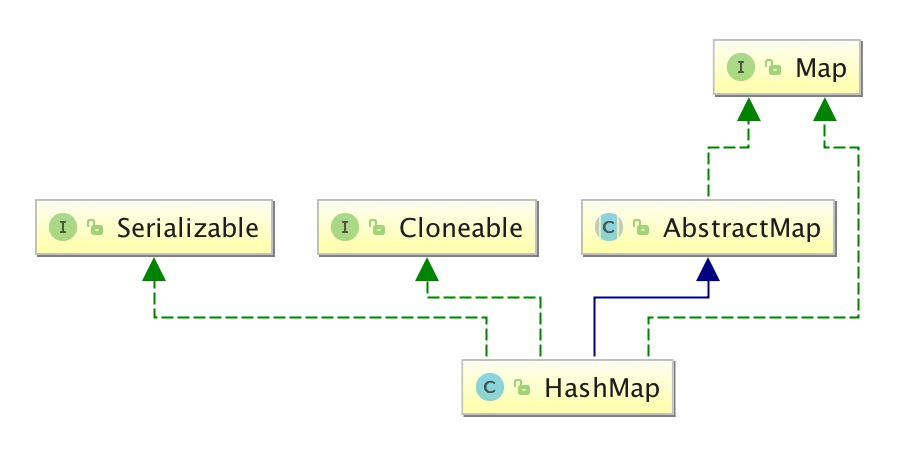
HashMap的存储结构
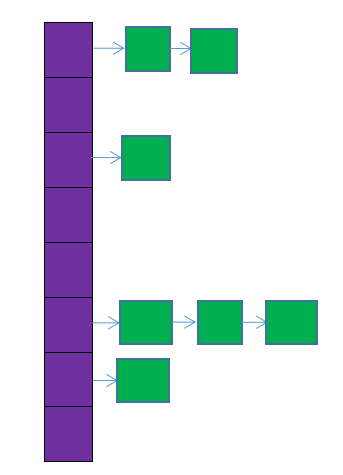
图中,紫色部分即代表哈希表,也称为哈希数组,数组的每个元素都是一个单链表的头节点,链表是用来解决冲突的,如果不同的 key 映射到了数组的同一位置处,就将其放入单链表中。
HashMap 内存储数据的 Entry 数组默认是 16,如果没有对 Entry 扩容机制的话,当存储的数据一多,Entry 内部的链表会很长,这就失去了 HashMap 的存储意义了。所以 HasnMap 内部有自己的扩容机制
1 HashMap的创建
面试官:“我们先以HashMap开始吧,你能讲讲当你new一个HashMap的时候,会发生什么吗?”
三歪:“HashMap有几个构造方法,但最主要的就是指定初始值大小和负载因子的大小。如果我们不指定,默认HashMap的大小为16,负载因子的大小为0.75”
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
三歪:“HashMap的大小只能是2次幂的,假设你传一个10进去,实际上最终HashMap的大小是16,你传一个7进去,HashMap最终的大小是8,具体的实现在tableSizeFor可以看到。我们把元素放进HashMap的时候,需要算出这个元素所在的位置(hash)。在HashMap里用的是位运算来代替取模,能够更加高效地算出该元素所在的位置。为什么HashMap的大小只能是2次幂,因为只有大小为2次幂时,才能合理用位运算替代取模。”
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
三歪:“而负载因子的大小决定着哈希表的扩容和哈希冲突。比如现在我默认的HashMap大小为16,负载因子为0.75,这意味着数组最多只能放12个元素,一旦超过12个元素,则哈希表需要扩容。怎么算出是12呢?很简单,就是16*0.75。每次put元素进去的时候,都会检查HashMap的大小有没有超过这个阈值,如果有,则需要扩容。”
三歪:“鉴于上面的说法(HashMap的大小只能是2次幂),所以扩容的时候时候默认是扩原来的2倍”
三歪:“显然扩容这个操作肯定是耗时的,那我能不能把负载因子调高一点,比如我要调至为1,那我的HashMap就等到16个元素的时候才扩容呢。显然是可以的,但是不推荐。负载因子调高了,这意味着哈希冲突的概率会增高,哈希冲突概率增高,同样会耗时(因为查找的速度变慢了)”
3 哈希值的计算
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
三歪:“实现就在hash方法上,可以发现的是,它是先算出正常的哈希值,然后与高16位做异或运算,产生最终的哈希值。这样做的好处可以增加了随机性,减少了碰撞冲突的可能性。”
4 hashMap的 put/get 的方法实现
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
三歪:”在put的时候,首先对key做hash运算,计算出该key所在的index。如果没碰撞,直接放到数组中,如果碰撞了,需要判断目前数据结构是链表还是红黑树,根据不同的情况来进行插入。假设key是相同的,则替换到原来的值。最后判断哈希表是否满了(当前哈希表大小*负载因子),如果满了,则扩容“
三歪:”在get的时候,还是对key做hash运算,计算出该key所在的index,然后判断是否有hash冲突,假设没有直接返回,假设有则判断当前数据结构是链表还是红黑树,分别从不同的数据结构中取出。“
5 在HashMap中,怎么判断一个元素是否相同
ublic final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
三歪:”首先会比较hash值,随后会用==运算符和equals()来判断该元素是否相同。说白了就是:如果只有hash值相同,那说明该元素哈希冲突了,如果hash值和equals() || == 都相同,那说明该元素是同一个。“
6 HashMap 使用红黑树的情况
三歪:”当数组的大小大于64且链表的大小大于8的时候才会将链表改为红黑树,当红黑树大小为6时,会退化为链表。这里转红黑树退化为链表的操作主要出于查询和插入时对性能的考量。链表查询时间复杂度O(N),插入时间复杂度O(1),红黑树查询和插入时间复杂度O(logN)“
7 HashMap为什么是线程不安全
HashMap 底层是一个 Entry 数组,当发生 hash 冲突的时候,hashmap 是采用链表的方式来解决的,在对应的数组位置存放链表的头结点。对链表而言,新加入的节点会从头结点加入。
我们来分析一下多线程访问:
(1)在hashmap做put操作的时候会调用下面方法:
// 新增Entry。将“key-value”插入指定位置,bucketIndex是位置索引。
void addEntry(int hash, K key, V value, int bucketIndex) {
// 保存“bucketIndex”位置的值到“e”中
Entry<K,V> e = table[bucketIndex];
// 设置“bucketIndex”位置的元素为“新Entry”,
// 设置“e”为“新Entry的下一个节点”
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
// 若HashMap的实际大小 不小于 “阈值”,则调整HashMap的大小
if (size++ >= threshold)
resize(2 * table.length);
}
在hashmap做put操作的时候会调用到以上的方法。现在假如A线程和B线程同时对同一个数组位置调用addEntry,两个线程会同时得到现在的头结点,然后A写入新的头结点之后,B也写入新的头结点,那B的写入操作就会覆盖A的写入操作造成A的写入操作丢失
( 2)删除键值对的代码
final Entry<K,V> removeEntryForKey(Object key) {
// 获取哈希值。若key为null,则哈希值为0;否则调用hash()进行计算
int hash = (key == null) ? 0 : hash(key.hashCode());
int i = indexFor(hash, table.length);
Entry<K,V> prev = table[i];
Entry<K,V> e = prev;
// 删除链表中“键为key”的元素
// 本质是“删除单向链表中的节点”
while (e != null) {
Entry<K,V> next = e.next;
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k)))) {
modCount++;
size--;
if (prev == e)
table[i] = next;
else
prev.next = next;
e.recordRemoval(this);
return e;
}
prev = e;
e = next;
}
return e;
}
当多个线程同时操作同一个数组位置的时候,也都会先取得现在状态下该位置存储的头结点,然后各自去进行计算操作,之后再把结果写会到该数组位置去,其实写回的时候可能其他的线程已经就把这个位置给修改过了,就会覆盖其他线程的修改
(3)addEntry中当加入新的键值对后键值对总数量超过门限值的时候会调用一个resize操作,代码如下:
// 重新调整HashMap的大小,newCapacity是调整后的容量
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
//如果就容量已经达到了最大值,则不能再扩容,直接返回
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 新建一个HashMap,将“旧HashMap”的全部元素添加到“新HashMap”中,
// 然后,将“新HashMap”赋值给“旧HashMap”。
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
这个操作会新生成一个新的容量的数组,然后对原数组的所有键值对重新进行计算和写入新的数组,之后指向新生成的数组。
当多个线程同时检测到总数量超过门限值的时候就会同时调用resize操作,各自生成新的数组并rehash后赋给该map底层的数组table,结果最终只有最后一个线程生成的新数组被赋给table变量,其他线程的均会丢失。而且当某些线程已经完成赋值而其他线程刚开始的时候,就会用已经被赋值的table作为原始数组,这样也会有问题。
三 LinkedMap
三歪:“其实在日常开发中LinkedHashMap用得不多。在前面也提到了,LinkedHashMap底层结构是数组+链表+双向链表”,实际上它继承了HashMap,在HashMap的基础上维护了一个双向链表。有了这个双向链表,我们的插入可以是“有序”的,这里的有序不是指大小有序,而是插入有序。
三歪:“LinkedHashMap在遍历的时候实际用的是双向链表来遍历的,所以LinkedHashMap的大小不会影响到遍历的性能”
四 TreeMap
三歪:“TreeMap在现实开发中用得也不多,TreeMap的底层数据结构是红黑树,TreeMap的key不能为null(如果为null,那还怎么排序呢),TreeMap有序是通过Comparator来进行比较的,如果comparator为null,那么就使用自然顺序”
五 进程安全的Map
三歪:“HashMap不是线程安全的,在多线程环境下,HashMap有可能会有数据丢失和获取不了最新数据的问题,比如说:线程Aput进去了,线程Bget不出来。我们想要线程安全,可以使用ConcurrentHashMap”
六 ConcurrentHashMap
三歪:“ConcurrentHashMap是线程安全的Map实现类,它在juc包下的。线程安全的Map实现类除了ConcurrentHashMap还有一个叫做Hashtable。当然了,也可以使用Collections来包装出一个线程安全的Map。但无论是Hashtable还是Collections包装出来的都比较低效(因为是直接在外层套synchronize),所以我们一般有线程安全问题考量的,都使用ConcurrentHashMap”
三歪:“ConcurrentHashMap的底层数据结构是数组+链表/红黑树,它能支持高并发的访问和更新,是线程安全的。ConcurrentHashMap通过在部分加锁和利用CAS算法来实现同步,在get的时候没有加锁,Node都用了volatile给修饰。在扩容时,会给每个线程分配对应的区间,并且为了防止putVal导致数据不一致,会给线程的所负责的区间加锁”
HashTable
HashTable与HashMap的区别
-
继承的父类不同
Hashtable继承自Dictionary类,而HashMap继承自AbstractMap类。但二者都实现了Map接口。
-
线程安全性不同
Hashtable 中的方法是Synchronize的,而HashMap中的方法在缺省情况下是非Synchronize的。在多线程并发的环境下,可以直接使用Hashtable,不需要自己为它的方法实现同步,但使用HashMap时就必须要自己增加同步处理。(结构上的修改是指添加或删除一个或多个映射关系的任何操作;仅改变与实例已经包含的键关联的值不是结构上的修改。)这一般通过对自然封装该映射的对象进行同步操作来完成。如果不存在这样的对象,则应该使用 Collections.synchronizedMap 方法来“包装”该映射
12、SynchronizedMap和ConcurrentHashMap有什么区别?
SynchronizedMap()和Hashtable一样,实现上在调用map所有方法时,都对整个map进行同步。而ConcurrentHashMap的实现却更加精细,它对map中的所有桶加了锁。所以,只要有一个线程访问map,其他线程就无法进入map,而如果一个线程在访ConcurrentHashMap某个桶时,其他线程,仍然可以对map执行某些操作。
所以,ConcurrentHashMap在性能以及安全性方面,明显比Collections.synchronizedMap()更加有优势。同时,同步操作精确控制到桶,这样,即使在遍历map时,如果其他线程试图对map进行数据修改,也不会抛出ConcurrentModificationException
五 字符串
String
StringBuffer
 S
S
0.String是最基本的数据类型吗?
Java中基本数据类型包括byte,int,char,long,float,double,boolean,short一共八个;String是定义在 java.lang 包下的一个类。它不是基本数据类型。
1.String是否可以被继承?
不可以,因为String类似final类。
2.为什么字符串是不可变的?
因为String类似final类。
3.什么是String常量池?
字符串池是一个特殊的内存区域,与存储这些字符串常量的常规堆内存分开。这些对象在应用程序的生命周期中被称为字符串变量。
如:双引号直接创建的字串,String a = "abc",会将"abc"存储在该区域。
String类中,字符串长度是否有限制?
可以看字符串类的源码,字符串使用char数组存放字符,该字符数组为定义最大长度,故,理论上来说String是没有长度限制的,限制的是你的内存有多大。
4.String类中intern()的作用?
作用:返回字符串对象的规范表示。
调用该方法时,如果池已包含String与equals(Object)方法确定的此对象相等的字符串,则返回池中的字符串。否则,将此String对象添加到池中,并String返回对此对象的引用。
它遵循对于任何两个字符串s和t,s.intern()==t.intern()是true当且仅当s.equals(t)是true。意味着如果s和t都是不同的字符串对象并且具有相同的字符序列,则在两者上调用intern()将导致由两个变量引用的单个字符串池文字。
典型考题:
String s1 = new String("ab") + new String("c");
s1.intern();因为此时常量池没有"abc",会将s3指向常量"abc"
String s2 = "abc";
System.out.println(s1 == s2);//true
String s3 = new String("de") + new String("f");
String s4 = "def";
s3.intern();// 因为此时常量池有"def",不会将s3指向常量"def"
System.out.println(s3 == s4);// false
String s5 = "ghi";
String s6 = new String("ghi");
s6.intern();// 因为此时常量池有"ghi",不会将s6指向常量"ghi"
System.out.println(s5 == s6);//false
判断字符串是否相等
1.使用equals和‘==‘进行字符串比较的差异?
字串中equals是重写的一个方法,比较字符串中value字符数组中字符是否一致,即比较的是字符串的值,==不仅比较字符串的值,而且还比较两个字符串所在内存地址是否相同。
2.如何判断两个String是否相等?
有两种方式判断字符串是否相等,使用""或者使用equals方法。当使用""操作符时,不仅比较字符串的值,还会比较引用的内存地址。大多数情况下,我们只需要判断值是否相等,此时用equals方法比较即可。
还有一个equalsIgnoreCase可以用来忽略大小写进行字符串值比较。
- ==
- equals
- compareTo() 方法 compareTo() 方法用于两种方式的比较:
- 字符串与对象进行比较。按字典顺序比较两个字符串。
- 返回值是整型,它是先比较对应字符的大小(ASCII码顺序),如果第一个字符和参数的第一个字符不等,结束比较,返回他们之间的差值,如果第一个字符和参数的第一个字符相等,则以第二个字符和参数的第二个字符做比较,以此类推,直至比较的字符或被比较的字符有一方结束。
- 如果参数字符串等于此字符串,则返回值 0;
- 如果此字符串小于字符串参数,则返回一个小于 0 的值;
- 如果此字符串大于字符串参数,则返回一个大于 0 的值。
- equalsIgnoreCase(String) 比较字符串到另一个字符串,忽略大小写因素
String 类下equals方法源码解析
String 类下的equals源码方法
/**
* Compares this string to the specified object. The result is {@code
* true} if and only if the argument is not {@code null} and is a {@code
* String} object that represents the same sequence of characters as this
* object.
*
* @param anObject
* The object to compare this {@code String} against
*
* @return {@code true} if the given object represents a {@code String}
* equivalent to this string, {@code false} otherwise
*
* @see #compareTo(String)
* @see #equalsIgnoreCase(String)
*/
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
String类对equals方法进行了重写,可以看出在String类中equals方法不仅可以用==判断对象的内存地址是否相等,相等则返回true。如果前面的判断不成立,接着判断括号内的对象上是否是String类型,接着判断两个字符串对象的的长度是否相等,最后判断内容是否相等,如果相等则返回true。
1.判定定义为String类型的st1和st2是否相等,为什么
package string;
public class Demo2_String {
public static void main(String[] args) {
String st1 = "abc";
String st2 = "abc";
System.out.println(st1 == st2);
System.out.println(st1.equals(st2));
}
}
输出结果:
第一行:true
第二行:true
分析:
? 先看第一个打印语句,在Java中这个符号是比较运算符,它可以基本数据类型和引用数据类型是否相等,如果是基本数据类型,比较的是值是否相等,如果是引用数据类型,比较的是两个对象的内存地址是否相等。字符串不属于8中基本数据类型,字符串对象属于引用数据类型,在上面把“abc”同时赋值给了st1和st2两个字符串对象,指向的都是同一个地址,所以第一个打印语句中的比较输出结果是 true
? 然后我们看第二个打印语句中的equals的比较,我们知道,equals是Object这个父类的方法,在String类中重写了这个equals方法,在JDK API 1.6文档中找到String类下的equals方法,点击进去可以看大这么一句话“将此字符串与指定的对象比较。当且仅当该参数不为null,并且是与此对象表示相同字符序列的 String 对象时,结果才为 true。” 注意这个相同字符序列,在后面介绍的比较两个数组,列表,字典是否相等,都是这个逻辑去写代码实现。由于st1和st2的值都是“abc”,两者指向同一个对象,当前字符序列相同,所以第二行打印结果也为true。
下面我们来画一个内存图来表示上面的代码,看起来更加有说服力。
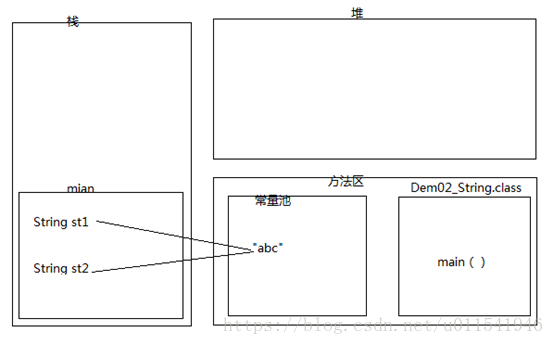
内存过程大致如下:
1)运行先编译,然后当前类Demo2_String.class文件加载进入内存的方法区
2)第二步,main方法压入栈内存
3)常量池创建一个“abc”对象,产生一个内存地址
4)然后把“abc”内存地址赋值给main方法里的成员变量st1,这个时候st1根据内存地址,指向了常量池中的“abc”。
5)前面一篇提到,常量池有这个特点,如果发现已经存在,就不在创建重复的对象
6)运行到代码 Stringst2 =”abc”, 由于常量池存在“abc”,所以不会再创建,直接把“abc”内存地址赋值给了st2
7)最后st1和st2都指向了内存中同一个地址,所以两者是完全相同的。
使用字符串初始化代码:String a = new String("abc");创建多少个对象?
2.Java中的String a = "abc"和String a = new String("abc")的区别?
String a = "abc" 使用常量进行初始化,初始化后内存存储在String常量池中
String a = new String("abc") 创建字符串对象,JVM创建字符串对象但不存储于字符串池。
上面一行代码将会创建1或2个字符串。如果在字符串常量池中已经有一个字符串“abc”,那么就只会创建一个“abc”字符串。如果字符串常量池中没有“abc”,那么首先会在字符串池中创建,然后才在堆内存中创建,这种情况就会创建2个对象了。
String st1 = new String(“abc”);
答案是:在内存中创建两个对象,一个在堆内存,一个在常量池,堆内存对象是常量池对象的一个拷贝副本。
分析:
我们下面直接来一个内存图。
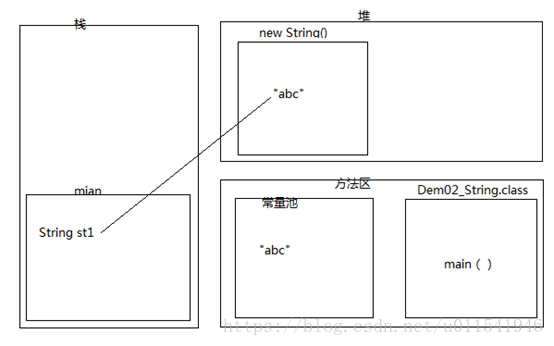
? 当我们看到了new这个关键字,就要想到,new出来的对象都是存储在堆内存。然后我们来解释堆中对象为什么是常量池的对象的拷贝副本。“abc”属于字符串,字符串属于常量,所以应该在常量池中创建,所以第一个创建的对象就是在常量池里的“abc”。第二个对象在堆内存为啥是一个拷贝的副本呢,这个就需要在JDK API 1.6找到String(String original)这个构造方法的注释:初始化一个新创建的 String 对象,使其表示一个与参数相同的字符序列;换句话说,新创建的字符串是该参数字符串的副本。所以,答案就出来了,两个对象。
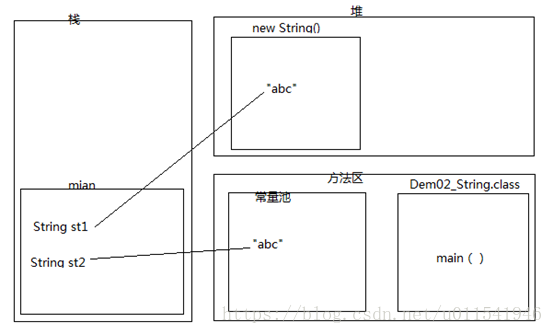
3.判定以下定义为String类型的st1和st2是否相等
package string;
public class Demo2_String {
public static void main(String[] args) {
String st1 = new String("abc");
String st2 = "abc";
System.out.println(st1 == st2);
System.out.println(st1.equals(st2));
}
}
答案:false 和 true
? 由于有前面两道提内存分析的经验和理论,所以,我能快速得出上面的答案。比较的st1和st2对象的内存地址,由于st1指向的是堆内存的地址,st2看到“abc”已经在常量池存在,就不会再新建,所以st2指向了常量池的内存地址,所以判断结果输出false,两者不相等。第二个equals比较,比较是两个字符串序列是否相等,由于就一个“abc”,所以完全相等。内存图如下
String,StringBuffer以及StringBuilder之间的区别?
| String | StringBuffer | StringBuilder |
|---|---|---|
| String的值是不可变的,这就导致每次对String的操作都会生成新的String对象,不仅效率低下,而且浪费大量优先的内存空间 | StringBuffer是可变类,和线程安全的字符串操作类,任何对它指向的字符串的操作都不会产生新的对象。每个StringBuffer对象都有一定的缓冲区容量,当字符串大小没有超过容量时,不会分配新的容量,当字符串大小超过容量时,会自动增加容量 | 可变类,速度更快 |
| 不可变 | 可变 | 可变 |
| 线程安全 | 线程不安全 | |
| 多线程操作字符串 | 单线程操作字符串 |
String是值不可变类,每次在String对象上的操作都会生成一个新的对象;
StringBuffer和StringBuilder则允许在原来对象上进行操作,而不用每次增加对象;
StringBuffer是线程安全的,但效率较低,而StringBuilder效率最高,但非线程安全。
String 是不可变的对象, 因此在每次对 String 类型进行改变的时候其实都等同于生成了一个新的 String 对象,然后将指针指向新的 String 对象,这样不仅效率低下,而且大量浪费有限的内存空间,所以经常改变内容的字符串最好不要用 String 。因为每次生成对象都会对系统性能产生影响,特别当内存中无引用对象多了以后, JVM 的 GC 就会开始工作,那速度是一定会相当慢的。
我们来看一下这张对String操作时内存变化的图:
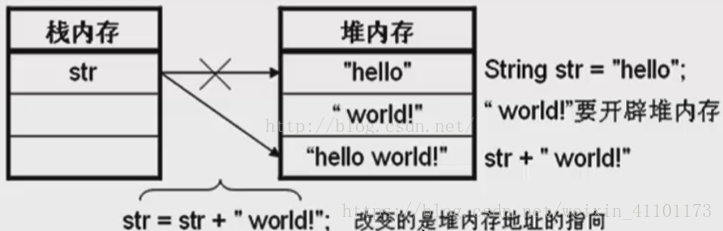
我们可以看到,初始String值为“hello”,然后在这个字符串后面加上新的字符串“world”,这个过程是需要重新在栈堆内存中开辟内存空间的,最终得到了“hello world”字符串也相应的需要开辟内存空间,这样短短的两个字符串,却需要开辟三次内存空间,不得不说这是对内存空间的极大浪费。为了应对经常性的字符串相关的操作,就需要使用Java提供的其他两个操作字符串的类——StringBuffer类和StringBuild类来对此种变化字符串进行处理。
三者的继承结构
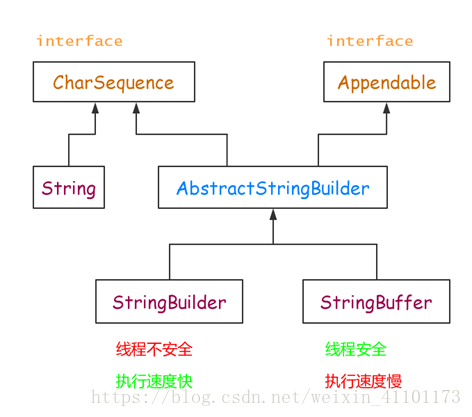
三者的区别:

(1)字符修改上的区别(主要,见上面分析)
(2)初始化上的区别,String可以空赋值,后者不行,报错
①String
String s = null;
String s = “abc”;
②StringBuffer
StringBuffer s = null; //结果警告:Null pointer access: The variable result can only be null at this location
StringBuffer s = new StringBuffer();//StringBuffer对象是一个空的对象
StringBuffer s = new StringBuffer(“abc”);//创建带有内容的StringBuffer对象,对象的内容就是字符串”
小结:(1)如果要操作少量的数据用 String;
(2)多线程操作字符串缓冲区下操作大量数据 StringBuffer;
(3)单线程操作字符串缓冲区下操作大量数据 StringBuilder。
符串拼接
如何连接多个字符串。
String:通过解读Java API,可以知道Java为字符串连接运算提供特殊支持。 字符串连接是通过StringBuilder (或StringBuffer )类及其append方法实现的。
StringBuffer:使用append实现
StringBuilder:使用append实现。
Java String “+”连接符拼接字符串原理?
String字符串拼接通过StringBuilder走中间过程,通过append方法实现。
程序有大量字符串拼接时,建议直接StringBuilder实现,就不需要底层new很多临时String对象了。注意null参与拼接时会变成字符串"null"。
1 package cn.itcast_02;
2
3 /*
4 * 看程序写结果
5 * 字符串如果是变量相加,先开空间,在拼接。
6 * 字符串如果是常量相加,是先加,然后在常量池找,如果有就直接返回,否则,就创建。
7 */
8 public class StringDemo4 {
9 public static void main(String[] args) {
10 String s1 = "hello";
11 String s2 = "world";
12 String s3 = "helloworld";
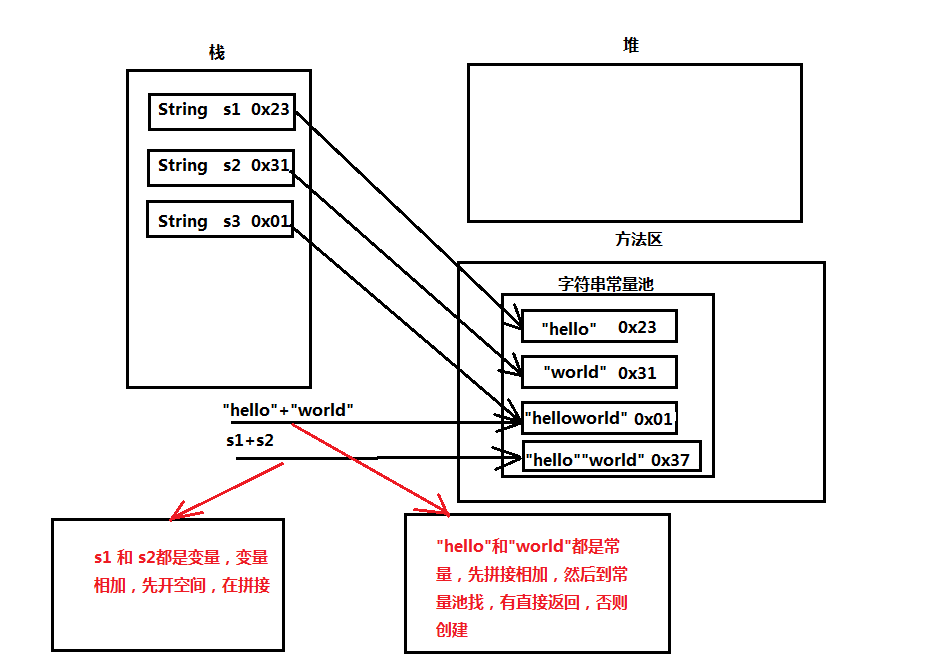
13 System.out.println(s3 == s1 + s2);// false ,另外单独开了一个空间(地址不详),然后在这个空间中进行字符串拼接。
14 System.out.println(s3.equals((s1 + s2)));// true
15
16 System.out.println(s3 == "hello" + "world");//这个我们错了,应该是true,因为之前s3 = "helloworld",已经存在"helloworld"直接返回这个
17 System.out.println(s3.equals("hello" + "world"));// true
18
19 // 通过反编译看源码,我们知道这里已经做好了处理。
20 // System.out.println(s3 == "helloworld");
21 // System.out.println(s3.equals("helloworld"));
22 }
23 }
程序理解示意图:
判定以下定义为String类型的st1和st2是否相等
package string;
public class Demo2_String {
public static void main(String[] args) {
String st1 = "a" + "b" + "c";
String st2 = "abc";
System.out.println(st1 == st2);
System.out.println(st1.equals(st2));
}
}
答案是:true 和 true
分析:
“a”,”b”,”c”三个本来就是字符串常量,进行+符号拼接之后变成了“abc”,“abc”本身就是字符串常量(Java中有常量优化机制),所以常量池立马会创建一个“abc”的字符串常量对象,在进行st2=”abc”,这个时候,常量池存在“abc”,所以不再创建。所以,不管比较内存地址还是比较字符串序列,都相等。
判断以下st2和st3是否相等
package string;
public class Demo2_String {
public static void main(String[] args) {
String st1 = "ab";
String st2 = "abc";
String st3 = st1 + "c";
System.out.println(st2 == st3);
System.out.println(st2.equals(st3));
}
}
答案:false 和 true
分析:
上面的答案第一个是false,第二个是true,第二个是true我们很好理解,因为比较一个是“abc”,另外一个是拼接得到的“abc”,所以equals比较,这个是输出true,我们很好理解。那么第一个判断为什么是false,我们很疑惑。同样,下面我们用API的注释说明和内存图来解释这个为什么不相等。
首先,打开JDK API 1.6中String的介绍,找到下面图片这句话。
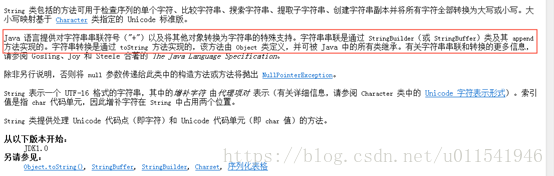
? 关键点就在红圈这句话,我们知道任何数据和字符串进行加号(+)运算,最终得到是一个拼接的新的字符串。上面注释说明了这个拼接的原理是由StringBuilder或者StringBuffer类和里面的append方法实现拼接,然后调用toString()把拼接的对象转换成字符串对象,最后把得到字符串对象的地址赋值给变量。结合这个理解,我们下面画一个内存图来分析。
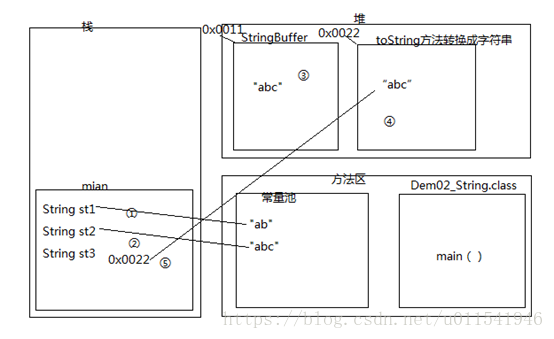
大致内存过程
1)常量池创建“ab”对象,并赋值给st1,所以st1指向了“ab”
2)常量池创建“abc”对象,并赋值给st2,所以st2指向了“abc”
3)由于这里走的+的拼接方法,所以第三步是使用StringBuffer类的append方法,得到了“abc”,这个时候内存0x0011表示的是一个StringBuffer对象,注意不是String对象。
4)调用了Object的toString方法把StringBuffer对象装换成了String对象。
5)把String对象(0x0022)赋值给st3
所以,st3和st2进行==判断结果是不相等,因为两个对象内存地址不同。
字符串切割
如何分割一个String?
-
可以使用字串分隔函数:public String[] split(String regex),根据传入的正则字符串进行分割,注意,如果最后一位刚好有传入的字符,返回数组最后一位不会有空字符串。
-
使用效率较高的StringTokenizer类分割字符串,StringTokenizer类是JDK中提供的专门用来处理字符串分割子串的工具类。它的构造函数如下:
public StringTokenizer(String str,String delim)str是要分割处理的字符串,delim是分割符号,当一个StringTokenizer对象生成后,通过它的nextToken()方法便可以得到下一个分割的字符串,再通过hasMoreTokens()方法可以知道是否有更多的子字符串需要处理。这种方法的效率比第一种高。
-
使用String的两个方法—indexOf()和subString(),subString()是采用了时间换取空间技术,因此它的执行效率相对会很快,只要处理好内存溢出问题,但可大胆使用。而indexOf()函数是一个执行速度非常快的方法。public String substring(int beginIndex, int endIndex)这个方法截取的字符串从beginIndex开始,到字符串索引的endIndex - 1结束,即截取的字符串不包括endIndex这个索引对应的字符,所以endIndex的最大值为整个字符串的长度,所以使用这个方法的时候需要特别注意容易发生字符串截取越界的问题
六 其他API
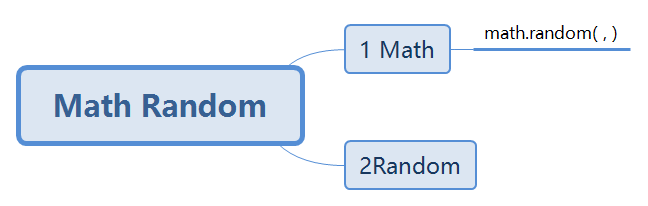
Math
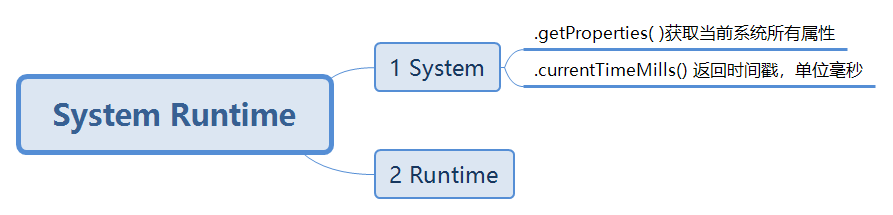
SystemRuntime
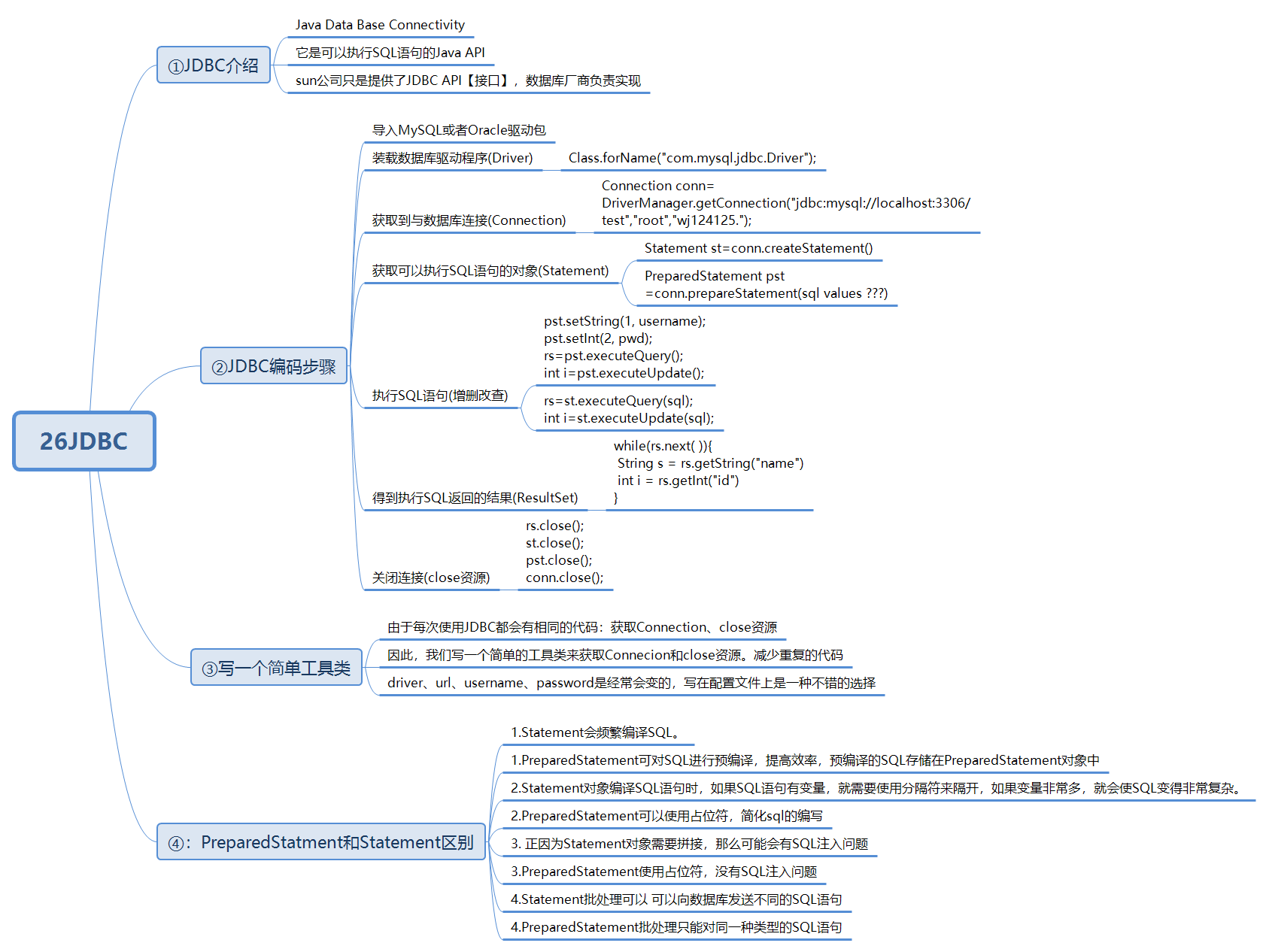
七 JDBC
八 IO 输入输出
IO常见的类
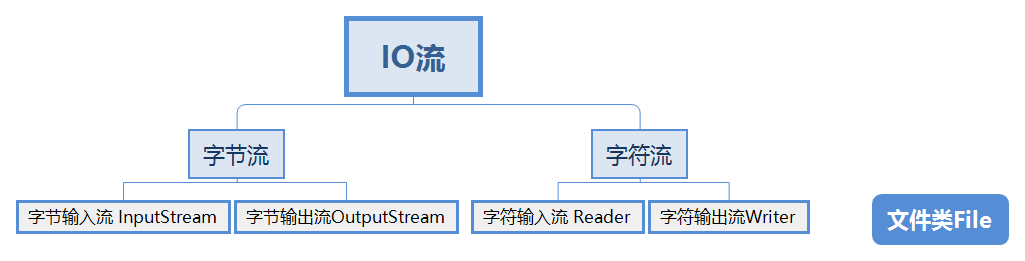
IO流类结构
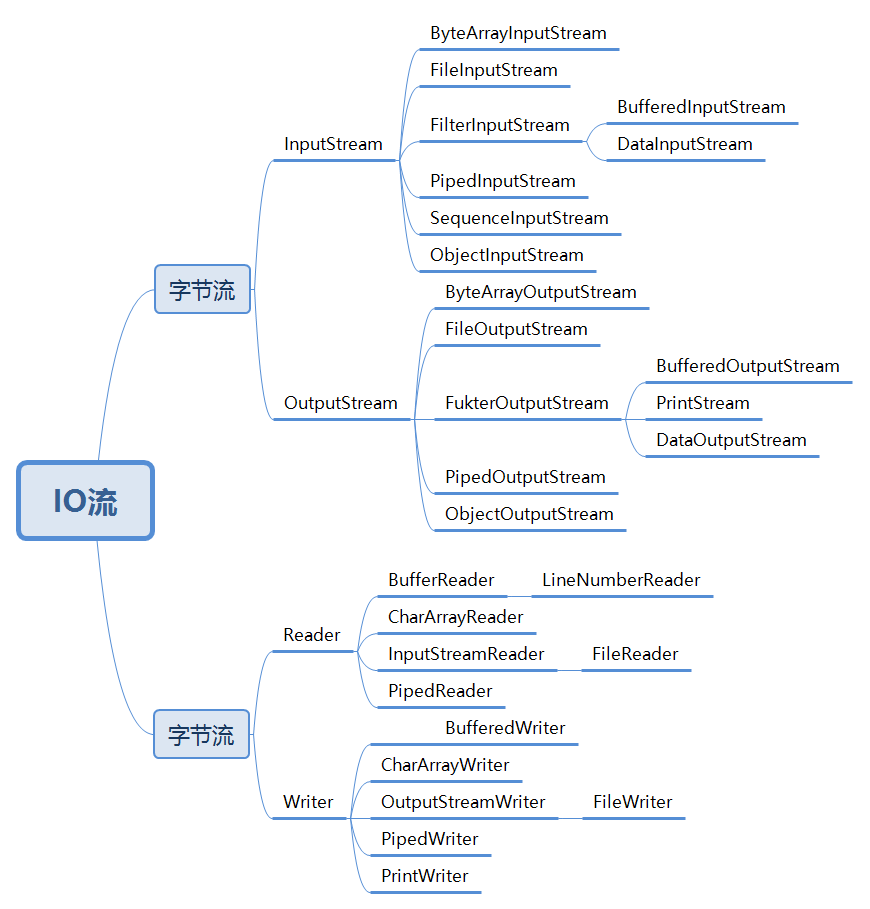
1、流的概念和作用
流:代表任何有能力产出数据的数据源对象或者是有能力接受数据的接收端对象
流的本质:数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。
流的作用:为数据源和目的地建立一个输送通道。
Java中将输入输出抽象称为流,就好像水管,将两个容器连接起来。流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。即数据在两设备间的传输称为流.
2、Java IO所采用的模型
Java的IO模型设计非常优秀,它使用Decorator(装饰者)模式,按功能划分Stream,您可以动态装配这些Stream,以便获得您需要的功能。例如,您需要一个具有缓冲的文件输入流,则应当组合使用FileInputStream和BufferedInputStream。
3、IO流的分类
· 根据处理数据类型的不同分为:字符流和字节流
· 根据数据流向不同分为:输入流和输出流
· 按数据来源(去向)分类:
? 1、File(文件): FileInputStream, FileOutputStream, FileReader, FileWriter
? 2、byte[]:ByteArrayInputStream, ByteArrayOutputStream
? 3、Char[]: CharArrayReader,CharArrayWriter
? 4、String:StringBufferInputStream, StringReader, StringWriter
? 5、网络数据流:InputStream,OutputStream, Reader, Writer
字符流和字节流
流序列中的数据既可以是未经加工的原始二进制数据,也可以是经一定编码处理后符合某种格式规定的特定数据。因此Java中的流分为两种:
1) 字节流:数据流中最小的数据单元是字节
2) 字符流:数据流中最小的数据单元是字符, Java中的字符是Unicode编码,一个字符占用两个字节。
字符流的由来: Java中字符是采用Unicode标准,一个字符是16位,即一个字符使用两个字节来表示。为此,JAVA中引入了处理字符的流。因为数据编码的不同,而有了对字符进行高效操作的流对象。本质其实就是基于字节流读取时,去查了指定的码表。
输入流和输出流
根据数据的输入、输出方向的不同对而将流分为输入流和输出流。
1) 输入流
程序从输入流读取数据源。数据源包括外界(键盘、文件、网络…),即是将数据源读入到程序的通信通道
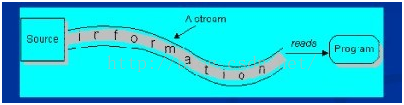
2) 输出流
程序向输出流写入数据。将程序中的数据输出到外界(显示器、打印机、文件、网络…)的通信通道。
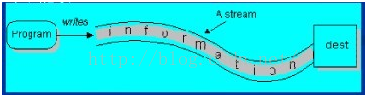
?
采用数据流的目的就是使得输出输入独立于设备。
输入流( Input Stream )不关心数据源来自何种设备(键盘,文件,网络)。
输出流( Output Stream )不关心数据的目的是何种设备(键盘,文件,网络)。
3)特性
相对于程序来说,输出流是往存储介质或数据通道写入数据,而输入流是从存储介质或数据通道中读取数据,一般来说关于流的特性有下面几点:
- 先进先出,最先写入输出流的数据最先被输入流读取到。
- 顺序存取,可以一个接一个地往流中写入一串字节,读出时也将按写入顺序读取一串字节,不能随机访问中间的数据。(RandomAccessFile可以从文件的任意位置进行存取(输入输出)操作)
- 只读或只写,每个流只能是输入流或输出流的一种,不能同时具备两个功能,输入流只能进行读操作,对输出流只能进行写操作。在一个数据传输通道中,如果既要写入数据,又要读取数据,则要分别提供两个流。
字节流
1.输入字节流InputStream
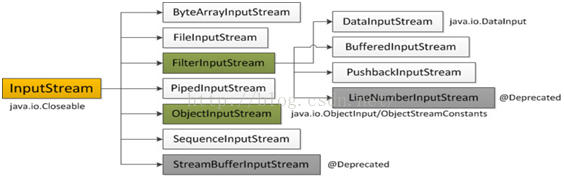
IO 中输入字节流的继承图可见上图,可以看出:
-
InputStream是所有的输入字节流的父类,它是一个抽象类。
-
ByteArrayInputStream、StringBufferInputStream(上图的StreamBufferInputStream)、FileInputStream是三种基本的介质流,它们分别从Byte数组、StringBuffer、和本地文件中读取数据。
-
PipedInputStream是从与其它线程共用的管道中读取数据.
-
ObjectInputStream和所有FilterInputStream的子类都是装饰流(装饰器模式的主角)。
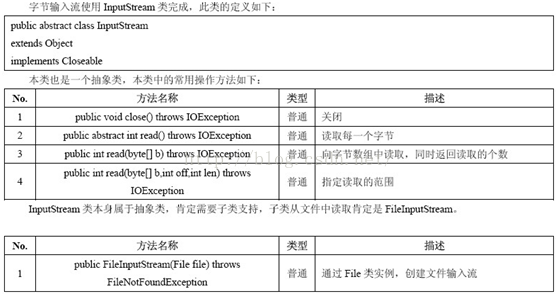
InputStream中的三个基本的读方法
- abstract int read() :读取一个字节数据,并返回读到的数据,如果返回-1,表示读到了输入流的末尾。
- intread(byte[]?b) :将数据读入一个字节数组,同时返回实际读取的字节数。如果返回-1,表示读到了输入流的末尾。
- intread(byte[]?b, int?off, int?len) :将数据读入一个字节数组,同时返回实际读取的字节数。如果返回-1,表示读到了输入流的末尾。off指定在数组b中存放数据的起始偏移位置;len指定读取的最大字节数。
流结束的判断:
- 方法read()的返回值为-1时;
- readLine()的返回值为null时。
其它方法
- long skip(long?n):在输入流中跳过n个字节,并返回实际跳过的字节数。
- int available() :返回在不发生阻塞的情况下,可读取的字节数。
- void close() :关闭输入流,释放和这个流相关的系统资源
- voidmark(int?readlimit) :在输入流的当前位置放置一个标记,如果读取的字节数多于readlimit设置的值,则流忽略这个标记。
- void reset() :返回到上一个标记。
- booleanmarkSupported() :测试当前流是否支持mark和reset方法。如果支持,返回true,否则返回false。
2.输出字节流OutputStream
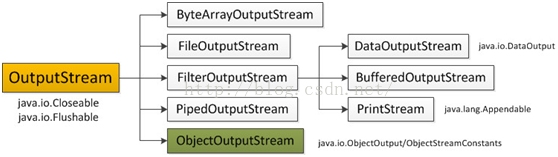
IO 中输出字节流的继承图可见上图,可以看出:
-
OutputStream是所有的输出字节流的父类,它是一个抽象类。
-
ByteArrayOutputStream、FileOutputStream是两种基本的介质流,它们分别向Byte数组、和本地文件中写入数据。PipedOutputStream是向与其它线程共用的管道中写入数据。
-
ObjectOutputStream和所有FilterOutputStream的子类都是装饰流。
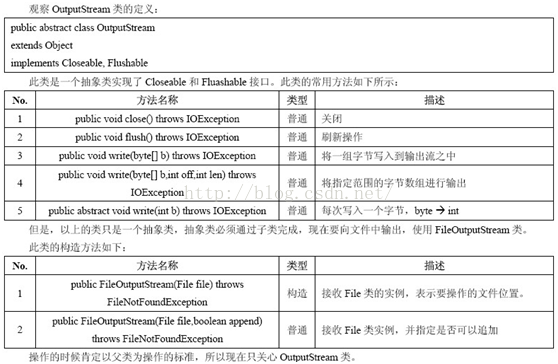
outputStream中的三个基本的写方法
- abstract void write(int?b):往输出流中写入一个字节。
- void write(byte[]?b) :往输出流中写入数组b中的所有字节。
- void write(byte[]?b, int?off, int?len) :往输出流中写入数组b中从偏移量off开始的len个字节的数据。
其它方法
- void flush() :刷新输出流,强制缓冲区中的输出字节被写出。
- void close() :关闭输出流,释放和这个流相关的系统资源。
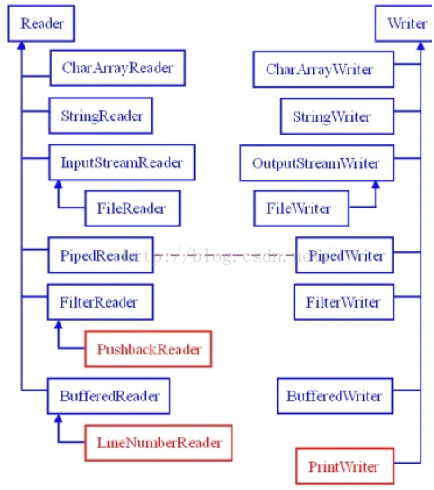
3.字节流的输入与输出的对应
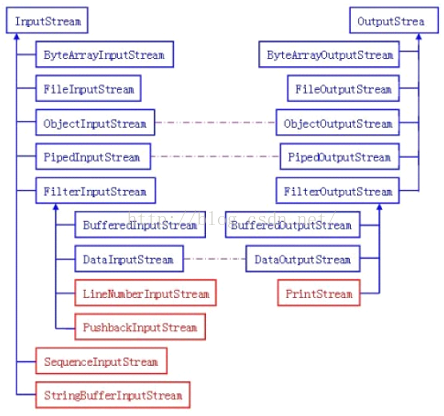
图中蓝色的为主要的对应部分,红色的部分就是不对应部分。从上面的图中可以看出JavaIO中的字节流是极其对称的。“存在及合理”我们看看这些字节流中不太对称的几个类吧!
-
LineNumberInputStream主要完成从流中读取数据时,会得到相应的行号,至于什么时候分行、在哪里分行是由改类主动确定的,并不是在原始中有这样一个行号。在输出部分没有对应的部分,我们完全可以自己建立一个LineNumberOutputStream,在最初写入时会有一个基准的行号,以后每次遇到换行时会在下一行添加一个行号,看起来也是可以的。好像更不入流了。
-
PushbackInputStream的功能是查看最后一个字节,不满意就放入缓冲区。主要用在编译器的语法、词法分析部分。输出部分的BufferedOutputStream几乎实现相近的功能。
-
StringBufferInputStream已经被Deprecated,本身就不应该出现在InputStream部分,主要因为String应该属于字符流的范围。已经被废弃了,当然输出部分也没有必要需要它了!还允许它存在只是为了保持版本的向下兼容而已。
-
SequenceInputStream可以认为是一个工具类,将两个或者多个输入流当成一个输入流依次读取。完全可以从IO包中去除,还完全不影响IO包的结构,却让其更“纯洁”――纯洁的Decorator模式。
-
PrintStream也可以认为是一个辅助工具。主要可以向其他输出流,或者FileInputStream写入数据,本身内部实现还是带缓冲的。本质上是对其它流的综合运用的一个工具而已。一样可以踢出IO包!System.out和System.out就是PrintStream的实例!
4.缓冲流
缓冲流目的是提高程序读取和写出的性能。缓冲流也分为字节缓冲流和字符缓冲流。
使用缓冲流的好处是能够更高效的读写信息,原理是先将数据缓冲起来,然后一起写入或者读取出来。

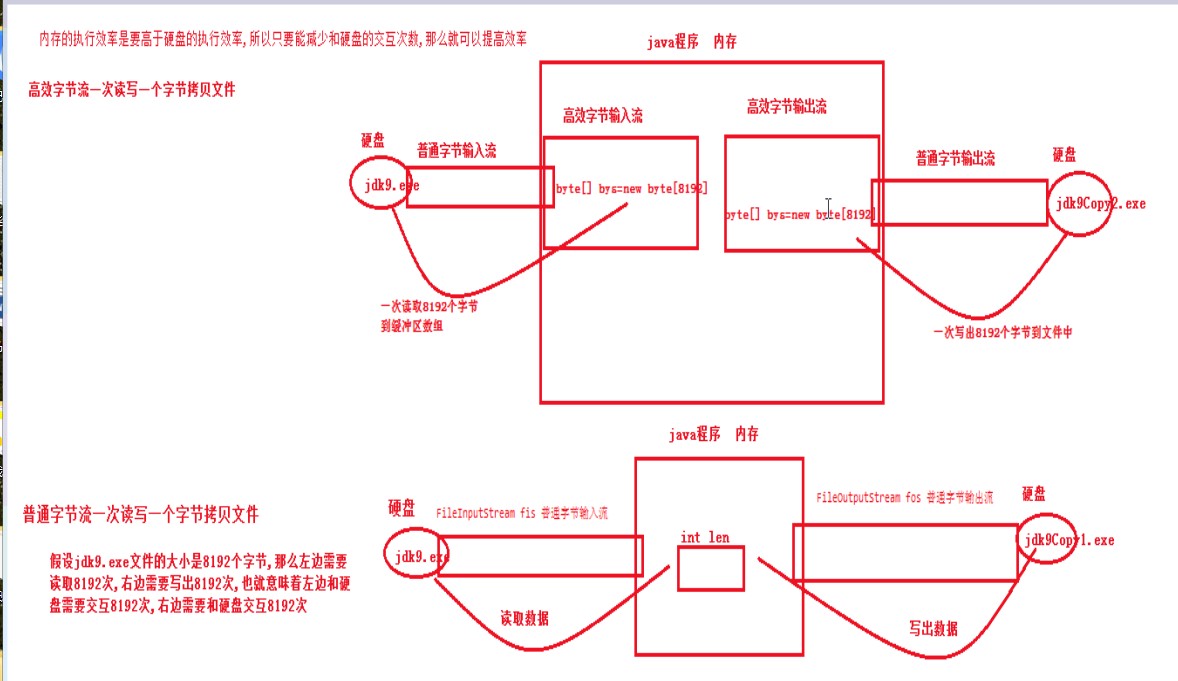
字符流
字节流是最基本的,所有的InputStream和OutputStream的子类都是,主要用在处理二进制数据,它是按字节来处理的。但实际中很多的数据是文本,又提出了字符流的概念,它是按虚拟机的encode来处理,也就是要进行字符集的转化。这两个之间通过 InputStreamReader,OutputStreamWriter来关联,实际上是通过byte[]和String来关联
在实际开发中出现的汉字问题实际上都是在字符流和字节流之间转化不统一而造成的
5.字符输入流Reader
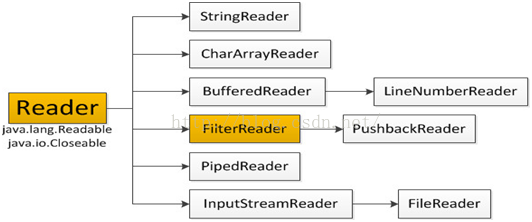
在上面的继承关系图中可以看出:
-
Reader是所有的输入字符流的父类,它是一个抽象类。
-
CharReader、StringReader是两种基本的介质流,它们分别将Char数组、String中读取数据。PipedReader是从与其它线程共用的管道中读取数据。
-
BufferedReader很明显就是一个装饰器,它和其子类负责装饰其它Reader对象。
-
FilterReader是所有自定义具体装饰流的父类,其子类PushbackReader对Reader对象进行装饰,会增加一个行号。
-
InputStreamReader是一个连接字节流和字符流的桥梁,它将字节流转变为字符流。FileReader可以说是一个达到此功能、常用的工具类,在其源代码中明显使用了将FileInputStream转变为Reader的方法。我们可以从这个类中得到一定的技巧。Reader中各个类的用途和使用方法基本和InputStream中的类使用一致。后面会有Reader与InputStream的对应关系。
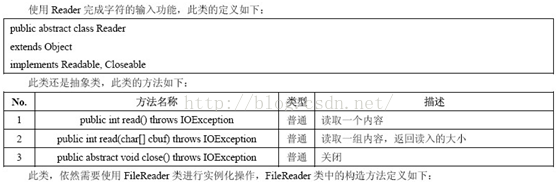
主要方法:
(1) public int read() throws IOException; //读取一个字符,返回值为读取的字符
(2) public int read(char cbuf[]) throws IOException; /读取一系列字符到数组cbuf[]中,返回值为实际读取的字符的数量/
(3) public abstract int read(char cbuf[],int off,int len) throws IOException; /读取len个字符,从数组cbuf[]的下标off处开始存放,返回值为实际读取的字符数量,该方法必须由子类实现/
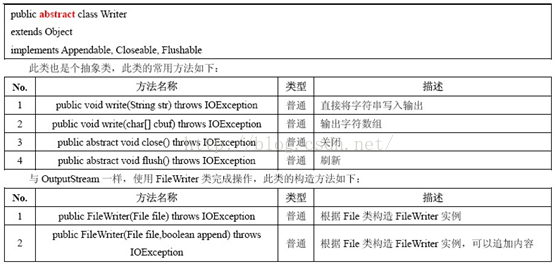
6.字符输出流Writer
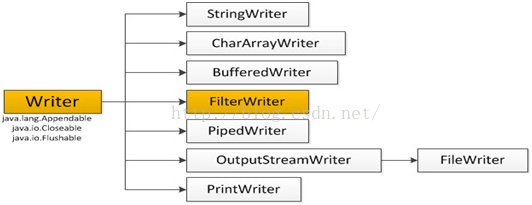
在上面的关系图中可以看出:
-
Writer是所有的输出字符流的父类,它是一个抽象类。
-
CharArrayWriter、StringWriter是两种基本的介质流,它们分别向Char数组、String中写入数据。PipedWriter是向与其它线程共用的管道中写入数据,
-
BufferedWriter是一个装饰器为Writer提供缓冲功能。
-
PrintWriter和PrintStream极其类似,功能和使用也非常相似。
-
OutputStreamWriter是OutputStream到Writer转换的桥梁,它的子类FileWriter其实就是一个实现此功能的具体类(具体可以研究一SourceCode)。功能和使用和OutputStream极其类似.
主要方法:
(1) public void write(int c) throws IOException; //将整型值c的低16位写入输出流
(2) public void write(char cbuf[]) throws IOException; //将字符数组cbuf[]写入输出流
(3) public abstract void write(char cbuf[],int off,int len) throws IOException; //将字符数组cbuf[]中的从索引为off的位置处开始的len个字符写入输出流
(4) public void write(String str) throws IOException; //将字符串str中的字符写入输出流
(5) public void write(String str,int off,int len) throws IOException; //将字符串str 中从索引off开始处的len个字符写入输出流
7.字符流的输入与输出的对应
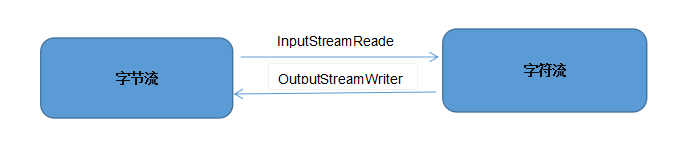
转换流
8.字符流与字节流转换
转换流的特点:
-
其是字符流和字节流之间的桥梁
-
可对读取到的字节数据经过指定编码转换成字符
-
可对读取到的字符数据经过指定编码转换成字节
何时使用转换流?
-
当字节和字符之间有转换动作时;
-
流操作的数据需要编码或解码时。
具体的对象体现:
转换流:在IO中还存在一类是转换流,将字节流转换为字符流,同时可以将字符流转化为字节流。
- InputStreamReader:字节到字符的桥梁。InputStreamReader(InputStream in):将字节流以字符流输入。
- OutputStreamWriter:字符到字节的桥梁。OutputStreamWriter(OutStreamout):将字节流以字符流输出。
这两个流对象是字符体系中的成员,它们有转换作用,本身又是字符流,所以在构造的时候需要传入字节流对象进来。
9.字节流和字符流的区别(重点)
字节流和字符流的区别:(详细可以参见http://blog.csdn.net/qq_25184739/article/details/51203733)
实际上字节流在操作时本身不会用到缓冲区(内存),是文件本身直接操作的,而字符流在操作时使用了缓冲区,通过缓冲区再操作文件,如下图所示。
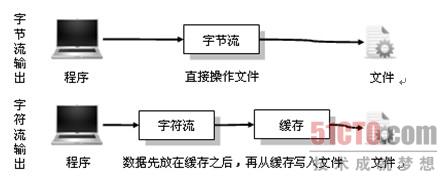
? 节流没有缓冲区,是直接输出的,而字符流是输出到缓冲区的。因此在输出时,字节流不调用colse()方法时,信息已经输出了,而字符流只有在调用close()方法关闭缓冲区时,信息才输出。要想字符流在未关闭时输出信息,则需要手动调用flush()方法。
· 读写单位不同:字节流以字节(8bit)为单位,字符流以字符为单位,根据码表映射字符,一次可能读多个字节。
· 处理对象不同:字节流能处理所有类型的数据(如图片、avi等),而字符流只能处理字符类型的数据。
结论:只要是处理纯文本数据,就优先考虑使用字符流。除此之外都使用字节流。
File类
File类是对文件系统中文件以及文件夹进行封装的对象,可以通过对象的思想来操作文件和文件夹。File类保存文件或目录的各种元数据信息,包括文件名、文件长度、最后修改时间、是否可读、获取当前文件的路径名,判断指定文件是否存在、获得当前目录中的文件列表,创建、删除文件和目录等方法。

从定义看,File类是Object的直接子类,同时它继承了Comparable接口可以进行数组的排序。
常用方法
File类的操作包括文件的创建、删除、重命名、得到路径、创建时间等,以下是文件操作常用的函数。
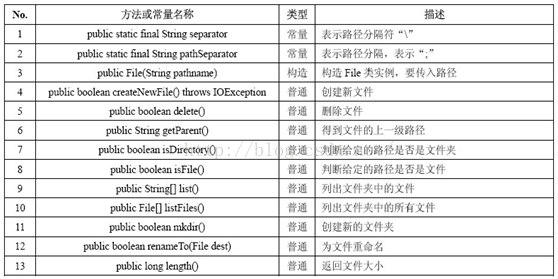
File类共提供了三个不同的构造函数,以不同的参数形式灵活地接收文件和目录名信息。
构造函数:
1)File (String pathname)
例:File f1=new File("FileTest1.txt"); //创建文件对象f1,f1所指的文件是在当前目录下创建的FileTest1.txt
2)File (String parent , String child)
例:File f2=new File(“D:dir1","FileTest2.txt") ;// 注意:D:dir1目录事先必须存在,否则异常
3)File (File parent , String child)
例:File f4=new File("dir3");
File f5=new File(f4,"FileTest5.txt"); //在如果 dir3目录不存在使用f4.mkdir()先创建
? 一个对应于某磁盘文件或目录的File对象一经创建, 就可以通过调用它的方法来获得文件或目录的属性。
? 1)public boolean exists( ) 判断文件或目录是否存在
? 2)public boolean isFile( ) 判断是文件还是目录
? 3)public boolean isDirectory( ) 判断是文件还是目录
? 4)public String getName( ) 返回文件名或目录名
? 5)public String getPath( ) 返回文件或目录的路径。
? 6)public long length( ) 获取文件的长度
? 7)public String[ ] list ( ) 将目录中所有文件名保存在字符串数组中返回。
? File类中还定义了一些对文件或目录进行管理、操作的方法,常用的方法有:
? 1) public boolean renameTo( File newFile ); 重命名文件
? 2) public void delete( ); 删除文件
? 3) public boolean mkdir( ); 创建目录
System类对IO的支持

针对一些频繁的设备交互,Java语言系统预定了3个可以直接使用的流对象,分别是:
· System.in(标准输入),通常代表键盘输入。
· System.out(标准输出):通常写往显示器。
· System.err(标准错误输出):通常写往显示器。
标准I/O
Java程序可通过命令行参数与外界进行简短的信息交换,同时,也规定了与标准输入、输出设备,如键盘、显示器进行信息交换的方式。而通过文件可以与外界进行任意数据形式的信息交换。
遍历目录下的文件
list( )
将目录中所有文件名保存在字符串数组中返回
package com.java.test;
import java.io.File;
public class testFile {
public static void main(String [] args) throws Exception{
//创建File对象
File file = new File("C:\Users\19781\Documents\Tencent Files\1978192989\FileRecv");
if(file.isDirectory()){//判断File对象对应的目录是否存在
String [] names =file.list(); //获得目录下的所有文件的文件名
for(String name: names){
System.out.println(name);
}
}
}
}
文件过滤 filter
//创建File对象
File file = new File("C:\Users\19781\Documents\Tencent Files\1978192989\FileRecv");
//创建过滤器对象
FilenameFilter filter = new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
File currentFile = new File(dir,name);
//如果文件名以.pdf结尾返回true,否则返回false
if(currentFile.isFile() && name.endsWith(".pdf")){
return true;
}else {
return false;
}
}
};
if (file.exists()){//判断File对象对应的目录是否存在
String[] lists = file.list(filter);//获得过滤后的所有文件名数组
for(String name : lists){
System.out.println(name);
}
}
递归遍历
listFiles( )返回一个File对象数组
public static void fileDir(File dir){
File [ ] files = dir.listFiles(); // 获得表示目录下所有文件的数组
for(File file : files){ //遍历所有的子目录和文件
if(file.isDirectory()){
fileDir(file); //如果是目录,递归调用FileDir()
}
System.out.println(file.getAbsolutePath());
}
}
删除文件及目录
delete
delete方法只能删除一个指定的文件
递归删除目录及文件
public static void deleteDir( File dir){
if(dir.exists()){//判断传入的File对象是否存在
File[] files = dir.listFiles(); // 得到File数组
for( File file :files){ //遍历所有的子目录和文件
if(file.isDirectory()){
deleteDir(file); //如果是目录,递归调用deleteDir
}else{
file.delete(); //是文件,直接删除
}
}
//删除完一个目录里的所有文件后,就删除这个目录
dir.delete();
}
}
注意,在java中目录的删除直接从虚拟机直接删除而不走回收站,文件一旦删除就无法恢复
九 多线程
15、Java线程池中submit() 和 execute()方法有什么区别?
两个方法都可以向线程池提交任务,execute()方法的返回类型是void,它定义在Executor接口中, 而
submit()方法可以返回持有计算结果的Future对象,它定义在ExecutorService接口中,它扩展了
Executor接口,其它线程池类像ThreadPoolExecutor和ScheduledThreadPoolExecutor都有这些方
法。
20、常用的线程池有哪些?
newSingleThreadExecutor:创建一个单线程的线程池,此线程池保证所有任务的执行顺序按照
任务的提交顺序执行。
newFixedThreadPool:创建固定大小的线程池,每次提交一个任务就创建一个线程,直到线程达
到线程池的最大大小。
newCachedThreadPool:创建一个可缓存的线程池,此线程池不会对线程池大小做限制,线程池
大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
newScheduledThreadPool:创建一个大小无限的线程池,此线程池支持定时以及周期性执行任
务的需求。
newSingleThreadExecutor:创建一个单线程的线程池。此线程池支持定时以及周期性执行任务
的需求。
21、简述一下你对线程池的理解
(如果问到了这样的问题,可以展开的说一下线程池如何用、线程池的好处、线程池的启动策略)合理
利用线程池能够带来三个好处。
第一:降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
第二:提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
第三:提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系
统的稳定性,使用线程池可以进行统一的分配,调优和监控。
22、Java程序是如何执行的
我们日常的工作中都使用开发工具(IntelliJ IDEA 或 Eclipse 等)可以很方便的调试程序,或者是通过打
包工具把项目打包成 jar 包或者 war 包,放入 Tomcat 等 Web 容器中就可以正常运行了,但你有没有
想过 Java 程序内部是如何执行的?其实不论是在开发工具中运行还是在 Tomcat 中运行,Java 程序的
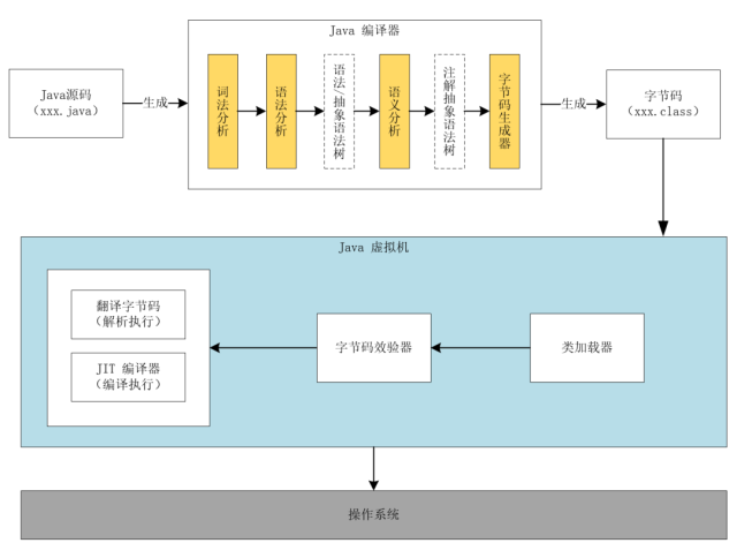
执行流程基本都是相同的,它的执行流程如下:
- 先把 Java 代码编译成字节码,也就是把 .java 类型的文件编译成 .class 类型的文件。这个过程的大致执行流程:Java 源代码 -> 词法分析器 -> 语法分析器 -> 语义分析器 -> 字符码生成器 -> 最终生成字节码,其中任何一个节点执行失败就会造成编译失败;
- 把 class 文件放置到 Java 虚拟机,这个虚拟机通常指的是 Oracle 官方自带的 Hotspot JVM;
Java 虚拟机使用类加载器(Class Loader)装载 class 文件; - 类加载完成之后,会进行字节码效验,字节码效验通过之后 JVM 解释器会把字节码翻译成机器码交由操作系统执行。但不是所有代码都是解释执行的,JVM 对此做了优化,比如,以 Hotspot 虚拟机来说,它本身提供了 JIT(Just In Time)也就是我们通常所说的动态编译器,它能够在运行时将热点代码编译为机器码,这个时候字节码就变成了编译执行。Java 程序执行流程图如下:
一 线程的概述
1 进程和线程的区别
面试官:“首先你来讲讲进程和线程的区别吧?”
三歪:“进程是系统进行资源分配和调度的独立单位,每一个进程都有它自己的内存空间和系统资源。进程实现多处理机环境下的进程调度,分派,切换时,都需要花费较大的时间和空间开销。为了提高系统的执行效率,减少处理机的空转时间和调度切换的时间,以及便于系统管理,所以有了线程,线程取代了进程了调度的基本功能”
三歪:“简单来说:进程作为资源分配的基本单位,线程作为资源调度的基本单位”
2 什么要用多线程
面试官:“那我们为什么要用多线程呢?你平时工作中用得多吗?”
三歪:“使用多线程最主要的原因是提高系统的资源利用率。现在CPU基本都是多核的,如果你只用单线程,那就是只用到了一个核心,其他的核心就相当于空闲在那里了。
三歪:“在平时工作中多线程是随时都可见的。比如说,我们系统Web服务器用的是Tomcat,Tomcat处理每一个请求都会从线程连接池里边用一个线程去处理。又比如说,我们用连接数据库会用对应的连接池,比如Druid/C3P0/DBCP等等,这些都用了多线程的。”
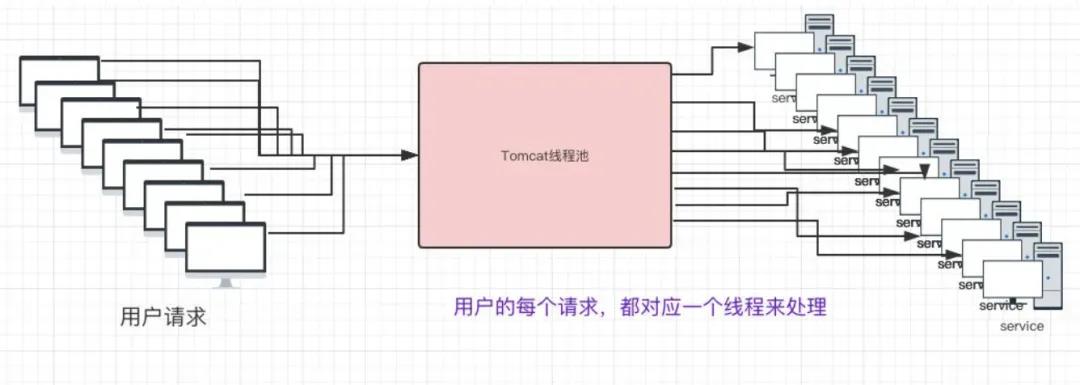
三歪:“除了上面这些框架已经帮我们屏蔽掉「手写」多线程的问题,在我本身的系统也会用到多线程的。比如说:现在要跑一个定时任务,该任务的链路执行时间和过程都非常长,我们这边就用一个线程池将该定时任务的请求进行处理,这样做的好处就是可以及时返回结果给调用方,能够提高系统的吞吐量。“
// 请求直接交给线程池来处理
public void push(PushParam pushParam) {
try {
pushServiceThreadExecutor.submit(() -> {
handler(pushParam);
});
} catch (Exception e) {
logger.error("pushServiceThreadExecutor error, exception{}:", e);
}
}
三歪:”还有就是我的系统中用了很多生产者与消费者模式,会用多个线程去消费队列的消息,来提高并发度“
面试官:”要不你来讲讲什么是线程安全?“
二 线程的创建
1.Java中实现多线程有几种方法
继承Thread类; 通过继承Thread类,重写Thread的run()方法,将线程运行的逻辑放在其中
实现Runnable接口; 通过实现Runnable接口,实例化Thread类
实现Callable接口通过FutureTask包装器来创建Thread线程;
使用ExecutorService、Callable、Future实现有返回结果的多线程(也就是使用了ExecutorService来 管理前面的三种方式)。
2继承Thread类和实现Runnable接口的区别
-
一个是多个线程分别完成自己的任务,一个是多个线程共同完成一个任务。
继承Thread类的,我们相当于拿出三件事即三个卖票10张的任务分别分给三个窗口,他们各做各的事各卖各的票各完成各的任务,因为MyThread继承Thread类,所以在new MyThread的时候在创建三个对象的同时创建了三个线程;
实现Runnable的, 相当于是拿出一个卖票10张得任务给三个人去共同完成,new MyThread相当于创建一个任务,然后实例化三个Thread,创建三个线程即安排三个窗口去执行。Runable适合多个相同的程序代码的线程去处理同一个资源,把线程与程序代码、数据分离,体现了面向对象的设计思想
-
避免java单继承带来的局限性
大部分的多线程会用Runable接口
三 线程的生命周期及状态
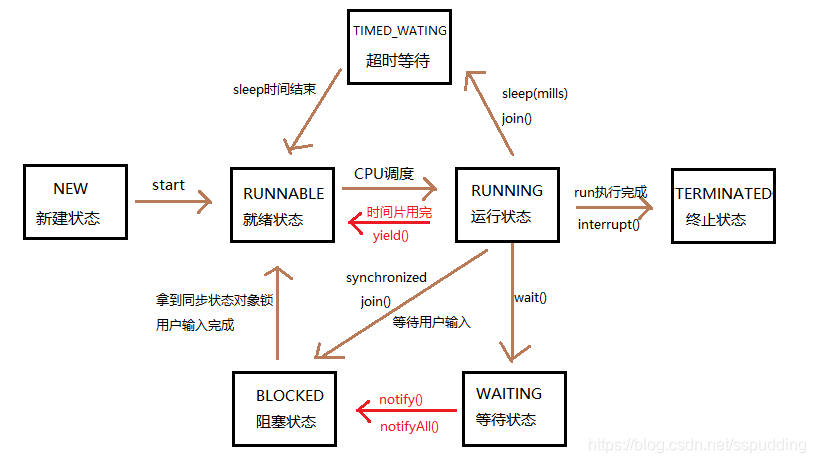
-
新建状态(New):
用new语句创建的线程处于新建状态,此时它和其他Java对象一样,仅仅在堆区中被分配了内存。 -
就绪状态(Runnable):
当一个线程对象创建后,其他线程调用它的start()方法,该线程就进入就绪状态,Java虚拟机会为它创建方法调用栈和程序计数器。处于这个状态的线程位于可运行池中,等待获得CPU的使用权。 -
运行状态(Running):
处于这个状态的线程占用CPU,执行程序代码。只有处于就绪状态的线程才有机会转到运行状态。 -
阻塞状态(Blocked):
阻塞状态是指线程因为某些原因放弃CPU,暂时停止运行。当线程处于阻塞状态时,Java虚拟机不会给线程分配CPU。直到线程重新进入就绪状态,它才有机会转到运行状态。
- 阻塞状态可分为以下3种:
- 位于对象等待池中的阻塞状态(Blocked in object’s wait pool):
当线程处于运行状态时,如果执行了某个对象的wait()方法,Java虚拟机就会把线程放到这个对象的等待池中,这涉及到“线程通信”的内容。 - 位于对象锁池中的阻塞状态(Blocked in object’s lock pool):
当线程处于运行状态时,试图获得某个对象的同步锁时,如果该对象的同步锁已经被其他线程占用,Java虚拟机就会把这个线程放到这个对象的锁池中,这涉及到“线程同步”的内容。 - 其他阻塞状态(Otherwise Blocked):
当前线程执行了sleep()方法,或者调用了其他线程的join()方法,或者发出了I/O请求时,就会进入这个状态。
- 位于对象等待池中的阻塞状态(Blocked in object’s wait pool):
- 阻塞状态可分为以下3种:
-
死亡状态(Dead):
当线程退出run()方法时,就进入死亡状态,该线程结束生命周期。
6、Thread 类中的start() 和 run() 方法有什么区别?
start()方法被用来启动新创建的线程,而且start()内部调用了run()方法,这和直接调用run()方法的效果
不一样。当你调用run()方法的时候,只会是在原来的线程中调用,没有新的线程启动,start()方法才会
启动新线程。
线程休眠 sleep
如果希望人为控制线程,使正在执行的线程暂停,将CPU转给其他线程可以使用静态方法sleep(long millis),该方法可以将正在执行的线程暂停,进入休眠等待状态。
sleep()和wait() 有什么区别?
对于sleep()方法,我们首先要知道该方法是属于Thread类中的。而wait()方法,则是属于Object类中的。
sleep()方法导致了程序暂停执行指定的时间,让出cpu该其他线程,但是他的监控状态依然保持者,当指定的时间到了又会自动恢复运行状态。在调用sleep()方法的过程中,线程不会释放对象锁。
当调用wait()方法的时候,线程会放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象调用notify()方法后本线程才进入对象锁定池准备,获取对象锁进入运行状态。
线程让步yiled
14、Thread类中的yield方法有什么作用?
Yield方法可以暂停当前正在执行的线程对象,让其它有相同优先级的线程执行。它是一个静态方法而且
只保证当前线程放弃CPU占用而不能保证使其它线程一定能占用CPU,执行yield()的线程有可能在进入
到暂停状态后马上又被执行。
yiled与sleep的区别
yiled和sleep都会让当前执行的线程暂停。区别是yiled()方法不会阻塞该线程,只是将线程转为就绪状态,
线程插队 join
11、有三个线程T1,T2,T3,如何保证顺序执行?
当在某个线程中调用其他线程的join()方法,调用的线程会被阻塞,直到被join()的线程执行完才会继续。
在多线程中有多种方法让线程按特定顺序执行,你可以用线程类的join()方法在一个线程中启动另一个
线程,另外一个线程完成该线程继续执行。为了确保三个线程的顺序你应该先启动最后一个(T3调用
T2,T2调用T1),这样T1就会先完成而T3最后完成。
实际上先启动三个线程中哪一个都行,
因为在每个线程的run方法中用join方法限定了三个线程的执行顺序。
public class JoinTest2 {
// 1.现在有T1、T2、T3三个线程,你怎样保证T2在T1执行完后执行,T3在T2执行完后执行
public static void main(String[] args) {
final Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
System.out.println("t1");
}
});
final Thread t2 = new Thread(new Runnable() {
@Override
public void run() {
try {
// 引用t1线程,等待t1线程执行完
t1.join();
} catch (InterruptedException e) {
e.printStackTrace();
} System.out.println("t2");
}
});
Thread t3 = new Thread(new Runnable() {
@Override
public void run() {
try {
// 引用t2线程,等待t2线程执行完
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
} System.out.println("t3");
}
});
t3.start();//这里三个线程的启动顺序可以任意,大家可以试下!
t2.start();
t1.start();
}
}
如何停止一个正在运行的线程
1、使用退出标志,使线程正常退出,也就是当run方法完成后线程终止。
2、使用stop方法强行终止,但是不推荐这个方法,因为stop和suspend及resume一样都是过期作废的
方法。
3、使用interrupt方法中断线程。
class MyThread extends Thread {
volatile boolean stop = false;
public void run() {
while (!stop) {
System.out.println(getName() + " is running");
try {
sleep(1000);
} catch (InterruptedException e) {
System.out.println("week up from blcok...");
stop = true; // 在异常处理代码中修改共享变量的状态
}
}
System.out.println(getName() + " is exiting...");
}
}
class InterruptThreadDemo3 {
public static void main(String[] args) throws InterruptedException {
MyThread m1 = new MyThread();
System.out.println("Starting thread...");
m1.start();
Thread.sleep(3000);
System.out.println("Interrupt thread...: " + m1.getName());
m1.stop = true; // 设置共享变量为true
m1.interrupt(); // 阻塞时退出阻塞状态
Thread.sleep(3000); // 主线程休眠3秒以便观察线程m1的中断情况
System.out.println("Stopping application...");
}
}
3、notify()和notifyAll()有什么区别?
notify可能会导致死锁,而notifyAll则不会
任何时候只有一个线程可以获得锁,也就是说只有一个线程可以运行synchronized 中的代码
使用notifyall,可以唤醒所有处于wait状态的线程,使其重新进入锁的争夺队列中,而notify只能唤醒一个。
wait() 应配合while循环使用,不应使用if,务必在wait()调用前后都检查条件,如果不满足,必须调用
notify()唤醒另外的线程来处理,自己继续wait()直至条件满足再往下执行。
notify() 是对notifyAll()的一个优化,但它有很精确的应用场景,并且要求正确使用。不然可能导致死
锁。正确的场景应该是 WaitSet中等待的是相同的条件,唤醒任一个都能正确处理接下来的事项,如果
唤醒的线程无法正确处理,务必确保继续notify()下一个线程,并且自身需要重新回到WaitSet中.
7、为什么wait, notify 和 notifyAll这些方法不在thread类里面?
明显的原因是JAVA提供的锁是对象级的而不是线程级的,每个对象都有锁,通过线程获得。如果线程需
要等待某些锁那么调用对象中的wait()方法就有意义了。如果wait()方法定义在Thread类中,线程正在
等待的是哪个锁就不明显了。简单的说,由于wait,notify和notifyAll都是锁级别的操作,所以把他们
定义在Object类中因为锁属于对象。
8、为什么wait和notify方法要在同步块中调用?
-
只有在调用线程拥有某个对象的独占锁时,才能够调用该对象的wait(),notify()和notifyAll()方法。
-
如果你不这么做,你的代码会抛出IllegalMonitorStateException异常。
-
还有一个原因是为了避免wait和notify之间产生竞态条件。
wait()方法强制当前线程释放对象锁。这意味着在调用某对象的wait()方法之前,当前线程必须已经获得
该对象的锁。因此,线程必须在某个对象的同步方法或同步代码块中才能调用该对象的wait()方法。
在调用对象的notify()和notifyAll()方法之前,调用线程必须已经得到该对象的锁。因此,必须在某个对
象的同步方法或同步代码块中才能调用该对象的notify()或notifyAll()方法。
调用wait()方法的原因通常是,调用线程希望某个特殊的状态(或变量)被设置之后再继续执行。调用notify()或notifyAll()方法的原因通常是,调用线程希望告诉其他等待中的线程:"特殊状态已经被设置"。
这个状态作为线程间通信的通道,它必须是一个可变的共享状态(或变量)。
9、Java中interrupted 和 isInterruptedd方法的区别?
interrupted() 和 isInterrupted()的主要区别是前者会将中断状态清除而后者不会。Java多线程的中断机
制是用内部标识来实现的,调用Thread.interrupt()来中断一个线程就会设置中断标识为true。当中断线
程调用静态方法Thread.interrupted()来检查中断状态时,中断状态会被清零。而非静态方法
isInterrupted()用来查询其它线程的中断状态且不会改变中断状态标识。简单的说就是任何抛出
InterruptedException异常的方法都会将中断状态清零。无论如何,一个线程的中断状态有有可能被其
它线程调用中断来改变。
四 线程安全
3 线程安全
三歪:”在我的理解下,在Java世界里边,所谓线程安全就是多个线程去执行某类,这个类始终能表现出正确的行为,那么这个类就是线程安全的。比如我有一个count变量,在service方法不断的累加这个count变量。
public class UnsafeCountingServlet extends GenericServlet implements Servlet {
private long count = 0;
public long getCount() {
return count;
}
public void service(ServletRequest servletRequest, ServletResponse servletResponse) throws ServletException, IOException {
++count;
// To something else...
}
}
三歪:”假设相同的条件下,count变量每次执行的结果都是相同,那我们就可以说是线程安全的。显然上面的代码肯定不是线程安全的。“
三歪:”只要用到多线程,我们肯定得考虑线程安全的问题。“
面试官:”那你是怎么解决线程安全问题的呢?“
三歪:”其实大部分时间我们在代码里边都没有显式去处理线程安全问题,因为这大部分都由框架所做了。正如上面提到的Tomcat、Druid、SpringMVC等等。“
三歪:”很多时候,我们判断是否要处理线程安全问题,就看有没有多个线程同时访问一个共享变量。像SpringMVC这种,我们日常开发时,不涉及到操作同一个成员变量,那我们就很少需要考虑线程安全问题。我个人解决线程安全问题的思路有以下:“
-
能不能保证操作的原子性,考虑atomic包下的类够不够我们使用。
-
能不能保证操作的可见性,考虑
volatile关键字够不够我们使用volatile是java虚拟机提供的轻量级的同步机制,volatile三个特性。
- 保证可见性
- 不保证原子性
- 禁止指令重排
-
如果涉及到对线程的控制(比如一次能使用多少个线程,当前线程触发的条件是否依赖其他线程的结果),考虑CountDownLatch/Semaphore等等。
-
如果是集合,考虑
java.util.concurrent包下的集合类。 -
如果synchronized无法满足,考虑lock包下的类
-
....
三歪:”总的来说,就是先判断有没有线程安全问题,如果存在则根据具体的情况去判断使用什么方式去处理线程安全的问题。虽然synchronized很牛逼,但无脑使用synchronized会影响我们程序的性能的。“
13、什么是线程安全
线程安全就是说多线程访问同一代码,不会产生不确定的结果。
在多线程环境中,当各线程不共享数据的时候,即都是私有(private)成员,那么一定是线程安全的。
但这种情况并不多见,在多数情况下需要共享数据,这时就需要进行适当的同步控制了。
线程安全一般都涉及到synchronized, 就是一段代码同时只能有一个线程来操作 不然中间过程可能会
产生不可预制的结果。
如果你的代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运
行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
19、 volatile关键字的作用?
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语
义:
保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他
线程来说是立即可见的。
禁止进行指令重排序。
volatile本质是在告诉jvm当前变量在寄存器(工作内存)中的值是不确定的,需要从主存中读取;synchronized则是锁定当前变量,只有当前线程可以访问该变量,其他线程被阻塞住。
volatile仅能使用在变量级别;synchronized则可以使用在变量、方法、和类级别的。
volatile仅能实现变量的修改可见性,并不能保证原子性;synchronized则可以保证变量的修改可见性和原子性。
volatile不会造成线程的阻塞;synchronized可能会造成线程的阻塞。
volatile标记的变量不会被编译器优化;synchronized标记的变量可以被编译器优化。
5、volatile 是什么?可以保证有序性吗?
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语
义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他
线程来说是立即可见的,volatile关键字会强制将修改的值立即写入主存。
2)禁止进行指令重排序。
volatile 不是原子性操作
什么叫保证部分有序性?
当程序执行到volatile变量的读操作或者写操作时,在其前面的操作的更改肯定全部已经进行,且结果
已经对后面的操作可见;在其后面的操作肯定还没有进行;
x = 2; //语句1
y = 0; //语句2
flag = true; //语句3
x = 4; //语句4
y = -1; //语句5
由于flag变量为volatile变量,那么在进行指令重排序的过程的时候,不会将语句3放到语句1、语句2前面,也不会讲语句3放到语句4、语句5后面。但是要注意语句1和语句2的顺序、语句4和语句5的顺序是不作任何保证的。
使用 Volatile 一般用于 状态标记量 和 单例模式的双检锁.
同步代码块 synchronized 同步方法 synchronized
6、说一说自己对于 synchronized 关键字的了解
synchronized关键字解决的是多个线程之间访问资源的同步性,synchronized关键字可以保证被它修
饰的方法或者代码块在任意时刻只能有一个线程执行。
另外,在 Java 早期版本中,synchronized属于重量级锁,效率低下,因为监视器锁(monitor)是依
赖于底层的操作系统的 Mutex Lock 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果
要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态
转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,这也是为什么早期的
synchronized 效率低的原因。庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对synchronized 较大优
化,所以现在的 synchronized 锁效率也优化得很不错了。JDK1.6对锁的实现引入了大量的优化,如自
旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
17、说说自己是怎么使用 synchronized 关键字,在项目中用到了
synchronized关键字最主要的三种使用方式:
- 修饰实例方法: 作用于当前对象实例加锁,进入同步代码前要获得当前对象实例的锁
- 修饰静态方法: 也就是给当前类加锁,会作用于类的所有对象实例,因为静态成员不属于任何一个实例
对象,是类成员( static 表明这是该类的一个静态资源,不管new了多少个对象,只有一份)。所以如
果一个线程A调用一个实例对象的非静态 synchronized 方法,而线程B需要调用这个实例对象所属类的
静态 synchronized 方法,是允许的,不会发生互斥现象,因为访问静态 synchronized 方法占用的锁
是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁。 - 修饰代码块: 指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。
总结: synchronized 关键字加到 static 静态方法和 synchronized(class)代码块上都是是给 Class 类上
锁。synchronized 关键字加到实例方法上是给对象实例上锁。尽量不要使用 synchronized(String a) 因
为JVM中,字符串常量池具有缓存功能!
10、Java中synchronized 和 ReentrantLock 有什么不同?
相似点:
这两种同步方式有很多相似之处,它们都是加锁方式同步,而且都是阻塞式的同步,也就是说当如果一
个线程获得了对象锁,进入了同步块,其他访问该同步块的线程都必须阻塞在同步块外面等待,而进行
线程阻塞和唤醒的代价是比较高的.
区别:
这两种方式最大区别就是对于Synchronized来说,它是java语言的关键字,是原生语法层面的互斥,需
要jvm实现。而ReentrantLock它是JDK 1.5之后提供的API层面的互斥锁,需要lock()和unlock()方法配
合try/finally语句块来完成。
Synchronized进过编译,会在同步块的前后分别形成monitorenter和monitorexit这个两个字节码指
令。在执行monitorenter指令时,首先要尝试获取对象锁。如果这个对象没被锁定,或者当前线程已经
拥有了那个对象锁,把锁的计算器加1,相应的,在执行monitorexit指令时会将锁计算器就减1,当计
算器为0时,锁就被释放了。如果获取对象锁失败,那当前线程就要阻塞,直到对象锁被另一个线程释
放为止。
由于ReentrantLock是java.util.concurrent包下提供的一套互斥锁,相比Synchronized,
ReentrantLock类提供了一些高级功能,主要有以下3项:
1.等待可中断,持有锁的线程长期不释放的时候,正在等待的线程可以选择放弃等待,这相当于
Synchronized来说可以避免出现死锁的情况。
2.公平锁,多个线程等待同一个锁时,必须按照申请锁的时间顺序获得锁,Synchronized锁非公平锁,
ReentrantLock默认的构造函数是创建的非公平锁,可以通过参数true设为公平锁,但公平锁表现的性
能不是很好。
3.锁绑定多个条件,一个ReentrantLock对象可以同时绑定对个对象。
死锁
面试官:”死锁你了解吗?什么情况会造成死锁?要是你能给我讲清楚死锁,我就录取你了“
三歪:”要是你录取我,我就给你讲清楚死锁“
面试官&三歪:”......“
三歪:”造成死锁的原因可以简单概括为:当前线程拥有其他线程需要的资源,当前线程等待其他线程已拥有的资源,都不放弃自己拥有的资源。避免死锁的方式一般有以下方案:
- 固定加锁的顺序“,比如我们可以使用Hash值的大小来确定加锁的先后
- 尽可能缩减加锁的范围,等到操作共享变量的时候才加锁。
- 使用可释放的定时锁(一段时间申请不到锁的权限了,直接释放掉)
线程同步
线程同步的含义
- 第一点是:线程同步就是线程排队。同步就是排队。线程同步的目的就是避免线程“同步”执行。这可真是个无聊的绕口令。
- 第二点是 “共享”这两个字。只有共享资源的读写访问才需要同步。如果不是共享资源,那么就根本没有同步的必要。
- 需要牢牢记住的第三点是,只有“变量”才需要同步访问。如果共享的资源是固定不变的,那么就相当于“常量”,线程同时读取常量也不需要同步。至少一个线程修改共享资源,这样的情况下,线程之间就需要同步。
- 需要牢牢记住的第四点是:多个线程访问共享资源的代码有可能是同一份代码,也有可能是不同的代码;无论是否执行同一份代码,只要这些线程的代码访问同一份可变的共享资源,这些线程之间就需要同步。
线程同步的实现
- 同步锁模型 同步锁不是加在共享资源上,而是加在访问共享资源的代码段上
- 信号量模型
-
synchronized
-
volatile
-
原子变量 util.concurrent.automic
-
重入锁 ReentrantLock类是可重入、互斥、实现了Lock接口的锁, 它与使用synchronized方法和快具有相同的基本行为和语义,并且扩展了其能力
关于Lock对象和synchronized关键字的选择:
a.最好两个都不用,使用一种java.util.concurrent包提供的机制,
能够帮助用户处理所有与锁相关的代码。
b.如果synchronized关键字能满足用户的需求,就用synchronized,因为它能简化代码
c.如果需要更高级的功能,就用ReentrantLock类,此时要注意及时释放锁,否则会出现死锁,通常在finally代码释放锁 -
使用局部变量 如果使用ThreadLocal管理变量,则每一个使用该变量的线程都获得该变量的副本, 副本之间相互独立,这样每一个线程都可以随意修改自己的变量副本,而不会对其他线程产生影响
ThreadLocal与同步机制
a.ThreadLocal与同步机制都是为了解决多线程中相同变量的访问冲突问题。
b.前者采用以"空间换时间"的方法,后者采用以"时间换空间"的方式
线程间通信
线程死锁
线程控制:挂起、停止和回复
十网络编程
TCP/IP协议
TCP/IP(Transmission Control Protocol/Internet Protocol)即传输控制协议/网间协议,是一个工业标准的协议集,它是为广域网(WANs)设计的。UDP(User Data Protocol,用户数据报协议)是与TCP相对应的协议。它是属于TCP/IP协议族中的一种。
? TCP/IP协议族包括运输层、网络层、链路层。现在你知道TCP/IP与UDP的关系了吧。
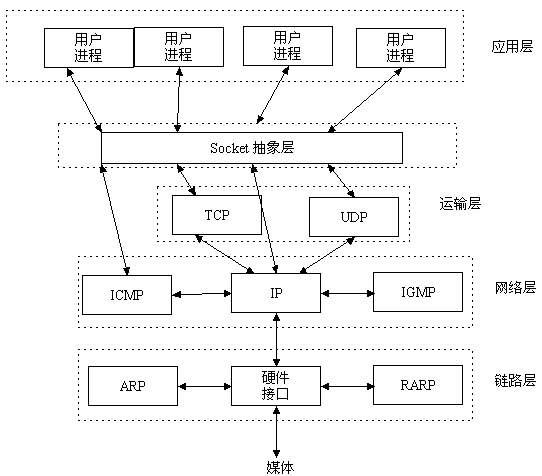 图2
图2
Socket
Socket是应用层与TCP/IP协议族通信的中间软件抽象层,它是一组接口。在设计模式中,Socket其实就是一个门面模式,它把复杂的TCP/IP协议族隐藏在Socket接口后面,对用户来说,一组简单的接口就是全部,让Socket去组织数据,以符合指定的协议。
一个生活中的场景。你要打电话给一个朋友,先拨号,朋友听到电话铃声后提起电话,这时你和你的朋友就建立起了连接,就可以讲话了。等交流结束,挂断电话结束此次交谈。 生活中的场景就解释了这工作原理,也许TCP/IP协议族就是诞生于生活中,这也不一定。
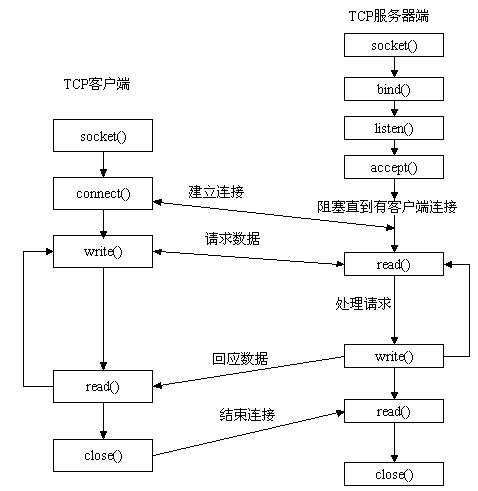
? 先从服务器端说起。服务器端先初始化Socket,然后与端口绑定(bind),对端口进行监听(listen),调用accept阻塞,等待客户端连接。在这时如果有个客户端初始化一个Socket,然后连接服务器(connect),如果连接成功,这时客户端与服务器端的连接就建立了。客户端发送数据请求,服务器端接收请求并处理请求,然后把回应数据发送给客户端,客户端读取数据,最后关闭连接,一次交互结束。
UDP通信
DatagranPacket
构造方法
- DatagramPacket(byte[]buf,int length)
- DatagramPacket(byte[]buf,int length,lnetAdress addr,int port)
- DatagramPacket(byte[]buf,int offset,int length)
- DatagramPacket(byte[]buf,int offset,int length,lnetAdress addr,int port)
常用方法
| 方法声明 | 功能描述 |
|---|---|
| inetAddress getAddress() | 该方法用于返回发送端或接收端的IP地址,如果是发送端的DatagramPacket对象,就返回接收端的IP地址;反之,就返回发送端的IP地址 |
| int getPort() | 该方法用于返回发送端或接收端的端口号,如果是发送端的DatagramPacket对象,就返回接收端的端口号;反之,就返回发送端的端口号 |
| byte[] getData() | 该方法用于返回将要接受或将要发送的数据,如果是发送端的DatagramPacket对象,就返回发送的数据;反之,就返回接收到的数据 |
| int getLength() | 该方法用于返回将要接受或将要发送的数据的长度,如果是发送端的DatagramPacket对象,就返回发送的数据长度;反之,就返回接收到的数据长度 |
DatagramSocket
构造方法
- DatagramSocket()
- DatagramSocket(int port)
- DatagramSocket(int port,InetAddress addr)
常用方法
| 方法声明 | 功能描述 |
|---|---|
| void receive(DatagramPacket p) | 该方法用于接收到的数据填充到DatagramPacket数据包中,在接受到数据之前一直处于阻塞状态,只有接收到数据包时,该方法才会返回 |
| void send(DatagramPacket p) | 该方法用于发送DatagramPacket数据包,发送的数据包中包含将要方的数据、数据的长度、远程主机的IP地址和端口号 |
| void close() | 关闭当前的Socket,通知驱动程序释放为这个Socket保留的资源 |
UDP网络程序
接收端
发送端
聊天程序设计
TCP通信
ServerSocket
Socket
简单的TCP网络程序
多线程的TCP网络程序
文件上传
以上是关于JAVA基础的主要内容,如果未能解决你的问题,请参考以下文章