大家好,这里是《齐姐聊数据结构》系列之大集合。
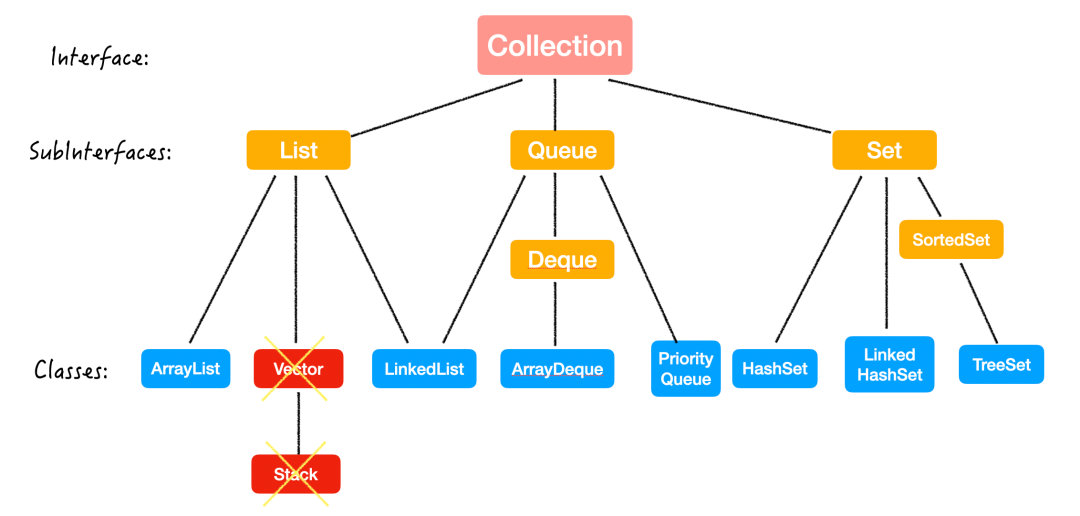
话不多说,直接上图:

Java 集合,也称作容器,主要是由两大接口 (Interface) 派生出来的:
Collection 和 Map
顾名思义,容器就是用来存放数据的。
那么这两大接口的不同之处在于:
- Collection 存放单一元素;
- Map 存放 key-value 键值对。
就是单身狗放 Collection 里面,couple 就放 Map 里。(所以你属于哪里?
学习这些集合框架,我认为有 4 个目标:
- 明确每个接口和类的对应关系;
- 对每个接口和类,熟悉常用的 API;
- 对不同的场景,能够选择合适的数据结构并分析优缺点;
- 学习源码的设计,面试要会答啊。
关于 Map,之前那篇 HashMap 的文章已经讲的非常透彻详尽了,所以本文不再赘述。如果还没看过那篇文章的小伙伴,快去公众号内回复「HashMap」看文章吧~
Collection
先来看最上层的 Collection.

Collection 里还定义了很多方法,这些方法也都会继承到各个子接口和实现类里,而这些 API 的使用也是日常工作和面试常见常考的,所以我们先来看下这些方法。
操作集合,无非就是「增删改查」四大类,也叫 CRUD:
Create, Read, Update, and Delete.
那我也把这些 API 分为这四大类:
| 功能 | 方法 |
|---|---|
| 增 | add()/addAll() |
| 删 | remove()/ removeAll() |
| 改 | Collection Interface 里没有 |
| 查 | contains()/ containsAll() |
| 其他 | isEmpty()/size()/toArray() |
下面具体来看:
增:
boolean add(E e);
add() 方法传入的数据类型必须是 Object,所以当写入基本数据类型的时候,会做自动装箱 auto-boxing 和自动拆箱 unboxing。
还有另外一个方法 addAll(),可以把另一个集合里的元素加到此集合中。
boolean addAll(Collection<? extends E> c);
删:
boolean remove(Object o);
remove()是删除的指定元素。
那和 addAll() 对应的,
自然就有removeAll(),就是把集合 B 中的所有元素都删掉。
boolean removeAll(Collection<?> c);
改:
Collection Interface 里并没有直接改元素的操作,反正删和增就可以完成改了嘛!
查:
- 查下集合中有没有某个特定的元素:
boolean contains(Object o);
- 查集合 A 是否包含了集合 B:
boolean containsAll(Collection<?> c);
还有一些对集合整体的操作:
- 判断集合是否为空:
boolean isEmpty();
- 集合的大小:
int size();
- 把集合转成数组:
Object[] toArray();
以上就是 Collection 中常用的 API 了。
在接口里都定义好了,子类不要也得要。
当然子类也会做一些自己的实现,这样就有了不同的数据结构。
那我们一个个来看。
List
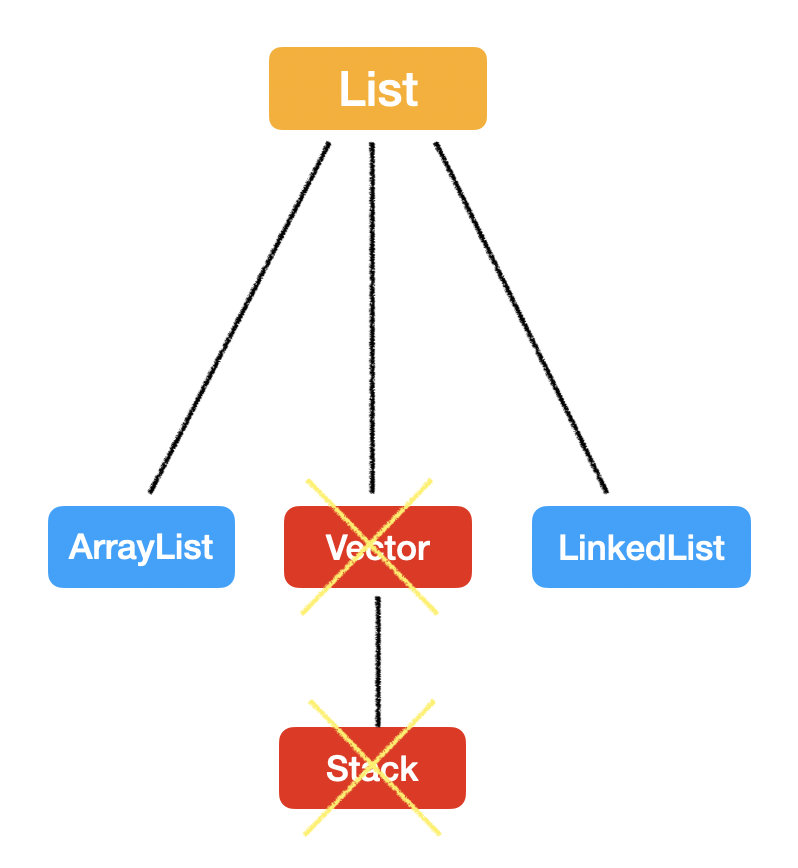
List 最大的特点就是:有序,可重复。
看官网说的:
An ordered collection (also known as a sequence).
Unlike sets, lists typically allow duplicate elements.
这一下把 Set 的特点也说出来了,和 List 完全相反,Set 是 无序,不重复的。
List 的实现方式有 LinkedList 和 ArrayList 两种,那面试时最常问的就是这两个数据结构如何选择。
对于这类选择问题:
一是考虑数据结构是否能完成需要的功能;
如果都能完成,二是考虑哪种更高效。
(万事都是如此啊。
那具体来看这两个 classes 的 API 和它们的时间复杂度:
| 功能 | 方法 | ArrayList | LinkedList |
|---|---|---|---|
| 增 | add(E e) | O(1) | O(1) |
| 增 | add(int index, E e) | O(n) | O(n) |
| 删 | remove(int index) | O(n) | O(n) |
| 删 | remove(E e) | O(n) | O(n) |
| 改 | set(int index, E e) | O(1) | O(n) |
| 查 | get(int index) | O(1) | O(n) |
稍微解释几个:
add(E e) 是在尾巴上加元素,虽然 ArrayList 可能会有扩容的情况出现,但是均摊复杂度(amortized time complexity)还是 O(1) 的。
add(int index, E e)是在特定的位置上加元素,LinkedList 需要先找到这个位置,再加上这个元素,虽然单纯的「加」这个动作是 O(1) 的,但是要找到这个位置还是 O(n) 的。(这个有的人就认为是 O(1),和面试官解释清楚就行了,拒绝扛精。
remove(int index)是 remove 这个 index 上的元素,所以
- ArrayList 找到这个元素的过程是 O(1),但是 remove 之后,后续元素都要往前移动一位,所以均摊复杂度是 O(n);
- LinkedList 也是要先找到这个 index,这个过程是 O(n) 的,所以整体也是 O(n)。
remove(E e)是 remove 见到的第一个这个元素,那么
- ArrayList 要先找到这个元素,这个过程是 O(n),然后移除后还要往前移一位,这个更是 O(n),总的还是 O(n);
- LinkedList 也是要先找,这个过程是 O(n),然后移走,这个过程是 O(1),总的是 O(n).
那造成时间复杂度的区别的原因是什么呢?
答:
-
因为 ArrayList 是用数组来实现的。
-
而数组和链表的最大区别就是数组是可以随机访问的(random access)。
这个特点造成了在数组里可以通过下标用 O(1) 的时间拿到任何位置的数,而链表则做不到,只能从头开始逐个遍历。
也就是说在「改查」这两个功能上,因为数组能够随机访问,所以 ArrayList 的效率高。
那「增删」呢?
如果不考虑找到这个元素的时间,
数组因为物理上的连续性,当要增删元素时,在尾部还好,但是其他地方就会导致后续元素都要移动,所以效率较低;而链表则可以轻松的断开和下一个元素的连接,直接插入新元素或者移除旧元素。
但是呢,实际上你不能不考虑找到元素的时间啊。。。而且如果是在尾部操作,数据量大时 ArrayList 会更快的。
所以说:
- 改查选择 ArrayList;
- 增删在尾部的选择 ArrayList;
- 其他情况下,如果时间复杂度一样,推荐选择 ArrayList,因为 overhead 更小,或者说内存使用更有效率。
Vector
那作为 List 的最后一个知识点,我们来聊一下 Vector。这也是一个年龄暴露帖,用过的都是大佬。
那 Vector 和 ArrayList 一样,也是继承自 java.util.AbstractList
但是现在已经被弃用了,因为...它加了太多的 synchronized!
任何好处都是有代价的,线程安全的成本就是效率低,在某些系统里很容易成为瓶颈,所以现在大家不再在数据结构的层面加 synchronized,而是把这个任务转移给我们程序员==
那么面试常问题:Vector 和 ArrayList 的区别是什么,只答出来这个还还不太全面。
来看 stack overflow 上的高票回答:

一是刚才已经说过的线程安全问题;
二是扩容时扩多少的区别。
这个得看看源码:
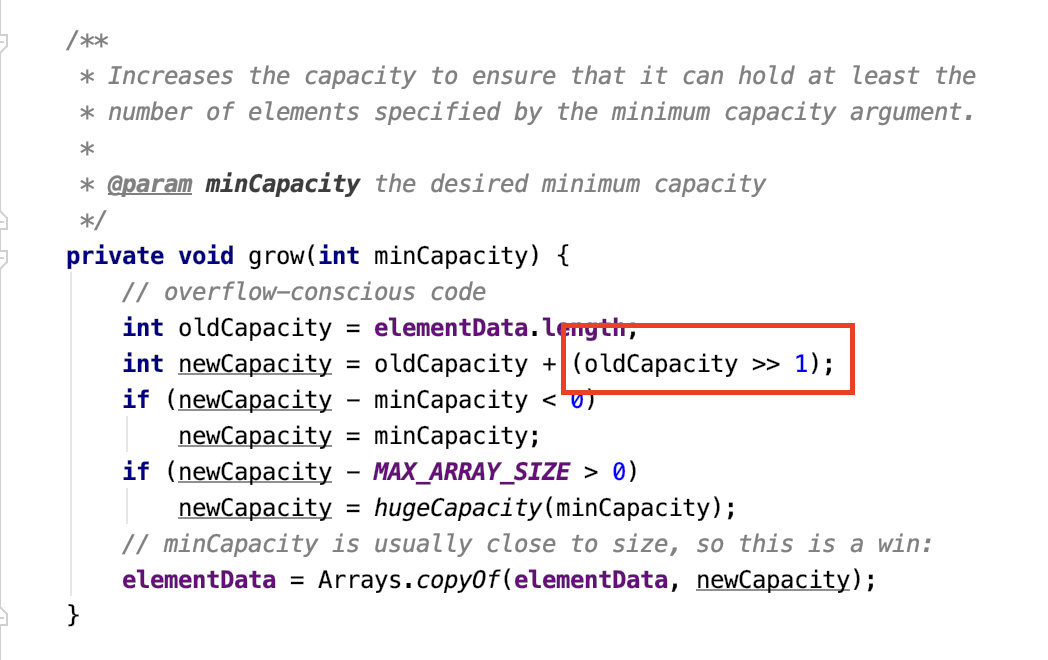
这是 ArrayList 的扩容实现,这个算术右移操作是把这个数的二进制往右移动一位,最左边补符号位,但是因为容量没有负数,所以还是补 0.
那右移一位的效果就是除以 2,那么定义的新容量就是原容量的 1.5 倍。
不了解这个右移操作符的小伙伴,公众号内回复「二进制」快复习一下吧~
再来看 Vector 的:

因为通常 capacityIncrement 我们并不定义,所以默认情况下它是扩容两倍。
答出来这两点,就肯定没问题了。
Queue & Deque
Queue 是一端进另一端出的线性数据结构;而 Deque 是两端都可以进出的。
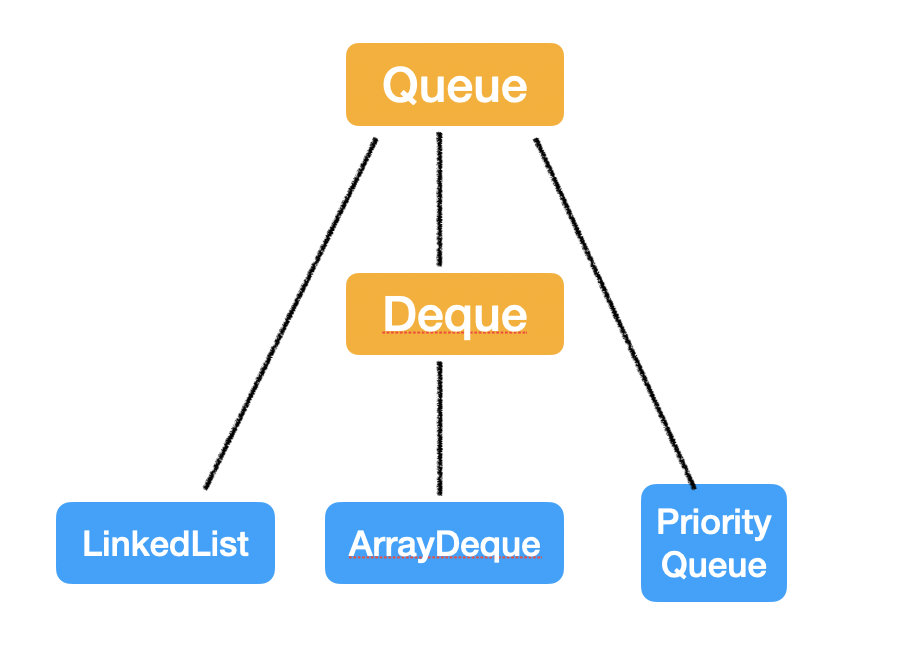
Queue
Java 中的 这个 Queue 接口稍微有点坑,一般来说队列的语义都是先进先出(FIFO)的。
但是这里有个例外,就是 PriorityQueue,也叫 heap,并不按照进去的时间顺序出来,而是按照规定的优先级出去,并且它的操作并不是 O(1) 的,时间复杂度的计算稍微有点复杂,我们之后单独开一篇来讲。
那 Queue 的方法官网都总结好了,它有两组 API,基本功能是一样的,但是呢:
- 一组是会抛异常的;
- 另一组会返回一个特殊值。
| 功能 | 抛异常 | 返回值 |
|---|---|---|
| 增 | add(e) | offer(e) |
| 删 | remove() | poll() |
| 瞧 | element() | peek() |
为什么会抛异常呢?
- 比如队列空了,那 remove() 就会抛异常,但是 poll() 就返回 null;element() 就会抛异常,而 peek() 就返回 null 就好了。
那 add(e) 怎么会抛异常呢?
有些 Queue 它会有容量的限制,比如 BlockingQueue,那如果已经达到了它最大的容量且不会扩容的,就会抛异常;但如果 offer(e),就会 return false.
那怎么选择呢?:
-
首先,要用就用同一组 API,前后要统一;
-
其次,根据需求。如果你需要它抛异常,那就是用抛异常的;不过做算法题时基本不用,所以选那组返回特殊值的就好了。
Deque
Deque 是两端都可以进出的,那自然是有针对 First 端的操作和对 Last 端的操作,那每端都有两组,一组抛异常,一组返回特殊值:
| 功能 | 抛异常 | 返回值 |
|---|---|---|
| 增 | addFirst(e)/ addLast(e) | offerFirst(e)/ offerLast(e) |
| 删 | removeFirst()/ removeLast() | pollFirst()/ pollLast() |
| 瞧 | getFirst()/ getLast() | peekFirst()/ peekLast() |
使用时同理,要用就用同一组。
Queue 和 Deque 的这些 API 都是 O(1) 的时间复杂度,准确来说是均摊时间复杂度。
实现类
它们的实现类有这三个:

所以说,
- 如果想实现「普通队列 - 先进先出」的语义,就使用 LinkedList 或者 ArrayDeque 来实现;
- 如果想实现「优先队列」的语义,就使用 PriorityQueue;
- 如果想实现「栈」的语义,就使用 ArrayDeque。
我们一个个来看。
在实现普通队列时,如何选择用 LinkedList 还是 ArrayDeque 呢?
来看一下 StackOverflow 上的高票回答:

总结来说就是推荐使用 ArrayDeque,因为效率高,而 LinkedList 还会有其他的额外开销(overhead)。
那 ArrayDeque 和 LinkedList 的区别有哪些呢?

还是在刚才的同一个问题下,这是我认为总结的最好的:
- ArrayDeque 是一个可扩容的数组,LinkedList 是链表结构;
- ArrayDeque 里不可以存 null 值,但是 LinkedList 可以;
- ArrayDeque 在操作头尾端的增删操作时更高效,但是 LinkedList 只有在当要移除中间某个元素且已经找到了这个元素后的移除才是 O(1) 的;
- ArrayDeque 在内存使用方面更高效。
所以,只要不是必须要存 null 值,就选择 ArrayDeque 吧!
那如果是一个很资深的面试官问你,什么情况下你要选择用 LinkedList 呢?
- 答:Java 6 以前。。。因为 ArrayDeque 在 Java 6 之后才有的。。
为了版本兼容的问题,实际工作中我们不得不做一些妥协。。
那最后一个问题,就是关于 Stack 了。
Stack
Stack 在语义上是 先进先出(LIFO) 的线性数据结构。
有很多高频面试题都是要用到栈的,比如接水问题,虽然最优解是用双指针,但是用栈是最直观的解法也是需要了解的,之后有机会再专门写吧。
那在 Java 中是怎么实现栈的呢?
虽然 Java 中有 Stack 这个类,但是呢,官方文档都说不让用了!

原因也很简单,因为 Vector 已经过被弃用了,而 Stack 是继承 Vector 的。
那么想实现 Stack 的语义,就用 ArrayDeque 吧:
Deque<Integer> stack = new ArrayDeque<>();
Set
最后一个 Set,刚才已经说过了 Set 的特定是无序,不重复的。
就和数学里学的「集合」的概念一致。
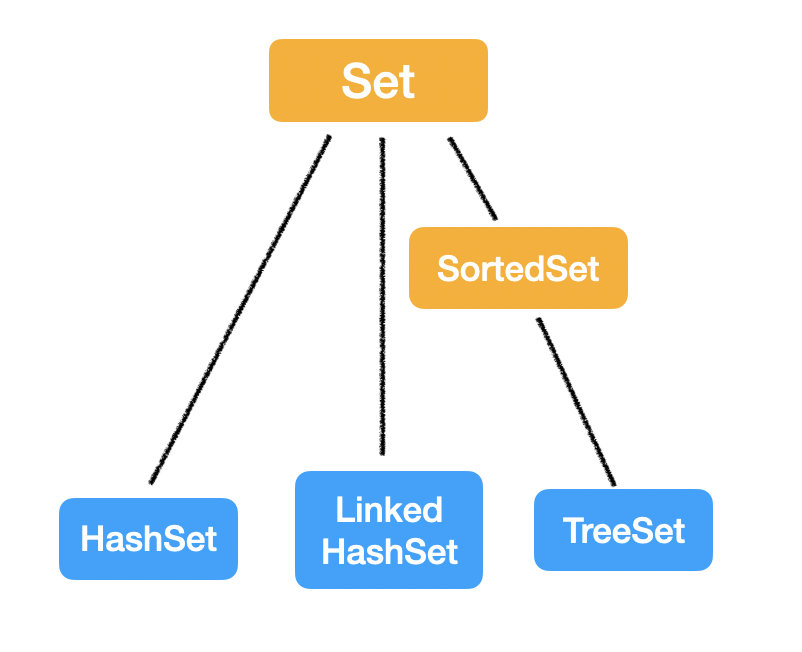
Set 的常用实现类有三个:
HashSet: 采用 Hashmap 的 key 来储存元素,主要特点是无序的,基本操作都是 O(1) 的时间复杂度,很快。
LinkedHashSet: 这个是一个 HashSet + LinkedList 的结构,特点就是既拥有了 O(1) 的时间复杂度,又能够保留插入的顺序。
TreeSet: 采用红黑树结构,特点是可以有序,可以用自然排序或者自定义比较器来排序;缺点就是查询速度没有 HashSet 快。
那每个 Set 的底层实现其实就是对应的 Map:
数值放在 map 中的 key 上,value 上放了个 PRESENT,是一个静态的 Object,相当于 place holder,每个 key 都指向这个 object。
那么具体的实现原理、增删改查四种操作,以及哈希冲突、hashCode()/equals() 等问题都在 HashMap 那篇文章里讲过了,这里就不赘述了,没有看过的小伙伴可以在公众号后台回复「HashMap」获取文章哦~
总结
再回到开篇的这张图,有没有清楚了一些呢?
每个数据结构下面其实都有很多内容,比如 PriorityQueue 也就是堆,齐姐之前也专门写过文章讲解它的相关操作,比如很有名的 heapify() 的过程为什么是 O(n) 的等面试常问题,感兴趣的小伙伴在公众号后台回复「堆」获取文章吧~
如果你喜欢这篇文章,记得给我点赞留言哦~你们的支持和认可,就是我创作的最大动力,我们下篇文章见!
我是小齐,纽约程序媛,终生学习者,每天晚上 9 点,云自习室里不见不散!
更多干货文章见我的 Github: https://github.com/xiaoqi6666/NYCSDE