读论文系列:Object Detection SPP-net
Posted 梦里茶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了读论文系列:Object Detection SPP-net相关的知识,希望对你有一定的参考价值。
本文为您解读SPP-net:
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Motivation
神经网络在计算机视觉方面的成功得益于卷积神经网络,然而,现有的许多成功的神经网络结构都要求输入为一个固定的尺寸(比如224x224,299x299),传入一张图像,需要对它做拉伸或者裁剪,再输入到网络中进行运算。

然而,裁剪可能会丢失信息,拉伸会使得图像变形,这些因素都提高了视觉任务的门槛,因此,如果能有一种模型能够接收各种尺度的输入,应当能够让视觉任务更加容易完成。
什么限制了输入的尺寸
深度卷积神经网络中的核心组件有两个,一个是CNN,一个是全连接层,卷积是用filter在图像上平移与图像的局部进行逐位乘法,多个filter则产生多个feature map(特征/特征图),然后可以用pooling操作进一步采样,得到更小的feature map;实际上,我们并不在意feature map有多大,不同图像的feature map完全可以有不同的尺寸;但是在后边的具体任务中,比如分类任务,为了输出softmax对应的one-hot层,需要输出固定的尺寸,为了让不同的输入能共用一套权重参数,要求全连接层的输入尺寸是一致的,逆推回去也就限制了feature map的大小必须一致;而不同尺寸的输入图片在使用同一套卷积核(filter)的时候,会产生不同尺寸的feature map,因此才需要将不同尺寸的输入图片通过裁剪、拉伸调整为相同的尺寸。
Solution
因此突破口有两个,
- 让卷积层能为不同尺寸的输入产生相同尺寸的输出(SPP)
- 让全连接层能为不同尺寸的输入产生相同尺寸的输出(全卷积)
全卷积和卷积的区别在于最后不是用全连接层进行分类, 而是用卷积层,假设我们要将一个16x16的feature map转为10x1的one-hot分类,则可以使用10个1x1卷积核,每个卷积核对应一个分类,参数数量少了很多,但是…实验结果表明还挺有效的,并且,全卷积+反卷积开辟了图像分割的新思路,可以说是一个开创新的工作了,感兴趣的同学可以看这篇博客
这里我们详细讲一下SPP

SPP中SP(Spatial Pyramid)的思想来源于SPM(Spatial Pyramid Matching),可以参考这篇文章,正如论文Conclusion中说的, Our studies also show that many time-proven techniques/insights in computer vision can still play important roles in deep-networks-based recognition.
SPM是在不同的分辨率(尺度)下,对图片进行分割,然后对每个局部提取特征,将这些特征整合成一个最终的特征,这个特征有宏观有微观(多尺度金字塔),保留了区域特性(不同的区域特征不同),然后用特征之间的相似度进行图片间的匹配(matching)。先前我们提到过,每个filter会得到一个feature map,SPP的输入则是卷积后的这些feature map,每次将一个feature map在不同尺度下进行分割,尺度L将图片分割为2^L^个小格子(其实格子数也可以自己定,不一定要分成2^L^个),L为0代表全图;对每个小格子的做pooling,论文中是max pooling, 实际中也可以用其他,这里不像SPM需要做SIFT之类的特征提取,因为feature map已经是卷积层提取过的特征了,将pooling得到的结果拼接起来,就可以得到固定尺寸的feature map。
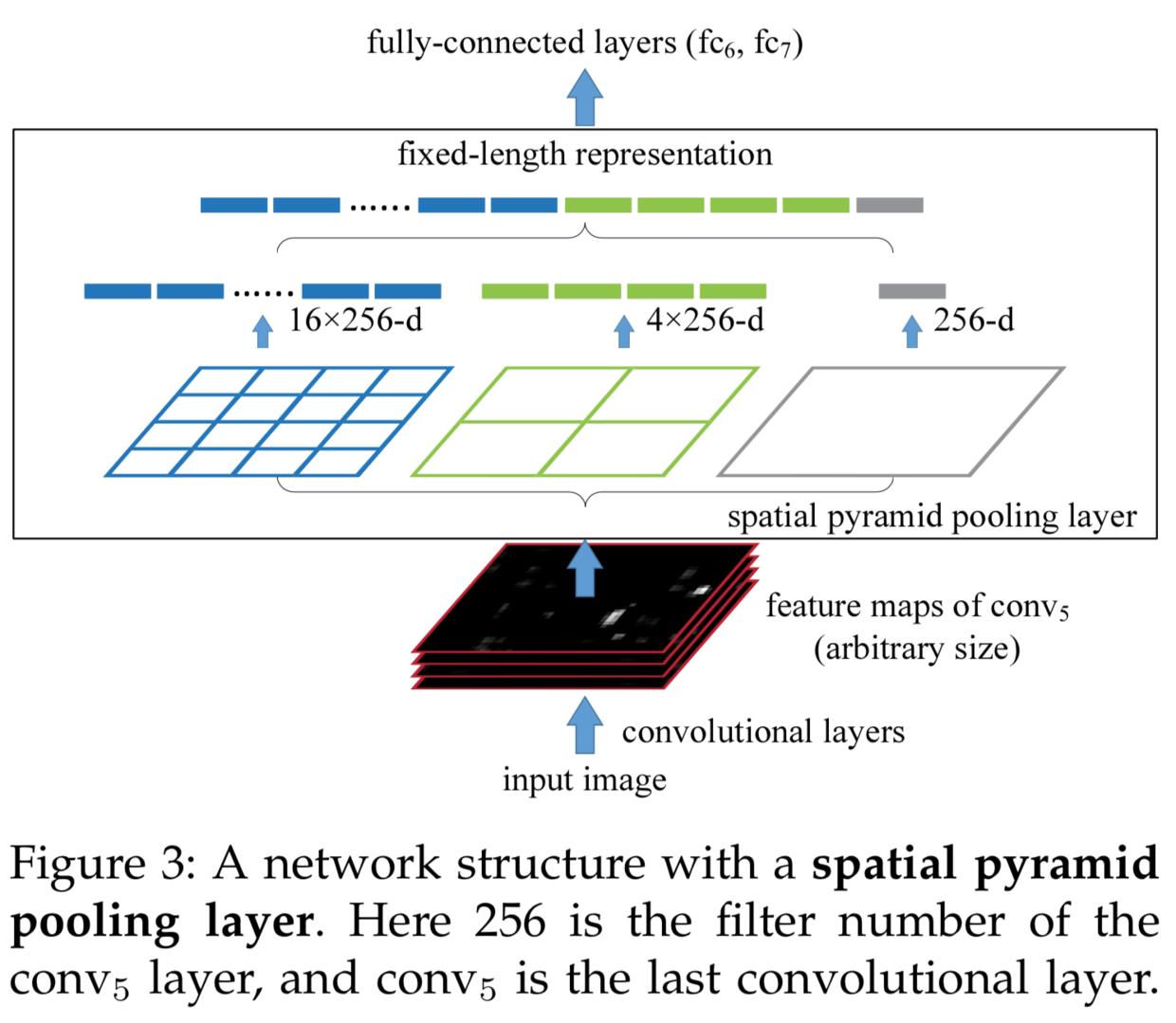
举个例子,一个具有256个filter的卷积层,输出了256个feature map,对于一个640x320的图片,输出的feature map可能是32x16的,对于一个640x640的图片,输出的feature map可能是32x32的,对256个feature map中的每个feature map,我们在4个尺度下对它们做切割,在最粗糙的尺度下切为1个图,次之切为2个子图,接下来是4个子图,8个, 对每个子图做max pooling,得到其中最大的数,放到最终的特征里,可以得到一个1+2+4+8=15这么长的特征,256个feature则可以得到最终256*15这么长的特征,可以看到,最终的特征尺寸只跟卷积层结构和SP尺度L有关,跟输入图片无关,从而保证了对不同尺寸的图片都输出一样大小的特征。
其实看到这里,你可能发现了,对不同尺寸输出相同尺寸特征这个特性,是由pooling操作决定的,像max pooling,sum pooling这些,就是将多个输入聚合为一个值的运算;而Spatial Pyramid只是让特征有更好的组织形式而已。当然,能找到这种有效的特征组织形式也是很值得肯定的。但这里有东西仍然值得商榷,max pooling实际上还是丢了一些信息,虽然通过多层的特征可以将这些信息弥补回来。
实验
然后作者就将这个结构应用到各种网络结构和各种任务里了,并且都取得了很好的效果(说的轻巧,复现一堆论文,改源码,跑大量实验,一定超级累);特别是在检测任务对RCNN的改进上,这个地方比较有意思。在RCNN中,需要将每个Region Proposal输入卷积层判断属于哪个分类,而region proposal是方形的,这就导致有很多区域做了重复的卷积运算。
在SPP-net的实验中,
- 整张图只过一遍卷积层,从conv5得到整张图对应的feature map;
- 然后将feature map中每个region proposal对应的部分提取出来,这个位置计算量也不小,但比算卷积本身还是要快很多,原图中的一个区域唯一对应于feature map中的一个区域,不过feature map中的一个区域实际上对应原图的范围(所谓感受野)要大于region proposal所在区域,从这个意义上来讲,依然是接收了更多不相关信息,但是好在没有裁剪或变形;
- 由于region proposal形状不一,对应的feature map尺寸也不一致,这时SPP就能充分发挥其特性,将不同尺寸的feature map转为尺寸一致的feature,传给全连接层进行分类
- 原图实际上可以保持原图的宽高比缩放到多种尺度(文中将宽或高缩放到480, 576, 688, 864, 1200这五个尺寸,),分别算一个特征,将不同尺度的特征拼接起来进行分类,这种combination的方式能一定程度上提高精度
- 这里还有一个小trick,可以将原图缩放到面积接近的范围(文中是224x224),再输入到网络中,进一步提升精度,至于原因…文中没有提,玄学解释是,输入的尺度更接近,模型训练更容易吧。
由于整张图只过了一遍卷积,所以比原来的RCNN快了很多,准确率也不差

Summary
严格来讲SPP-net不是为detection而生的模型,但是SPP-net为RCNN进化到Fast-RCNN起了很大的借鉴作用,值得一读。SPP-net的想法很有意思,SPP(Spatial Pyramid Pooling)是对网络结构的一种改进,可能因为是华人写的论文,感觉很好读,含金量个人感觉没有RCNN或者DPM的论文高,但是实验很丰富,从分类任务和检测任务上的各种网络结构证明SPP的有效性
以上是关于读论文系列:Object Detection SPP-net的主要内容,如果未能解决你的问题,请参考以下文章