Flink学习 批流版本的wordcount JAVA版本
Posted Xiaohu_BigData
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink学习 批流版本的wordcount JAVA版本相关的知识,希望对你有一定的参考价值。
Flink 开发环境
通常来讲,任何一门大数据框架在实际生产环境中都是以集群的形式运行,而我们调试代码大多数会在本地搭建一个模板工程,Flink 也不例外。
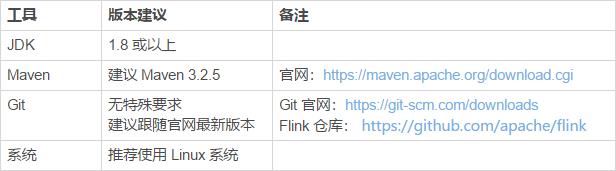
Flink 一个以 Java 及 Scala 作为开发语言的开源大数据项目,通常我们推荐使用 Java 来作为开发语言,Maven 作为编译和包管理工具进行项目构建和编译。对于大多数开发者而言,JDK、Maven 和 Git 这三个开发工具是必不可少的。
关于 JDK、Maven 和 Git 的安装建议如下表所示:
工程创建
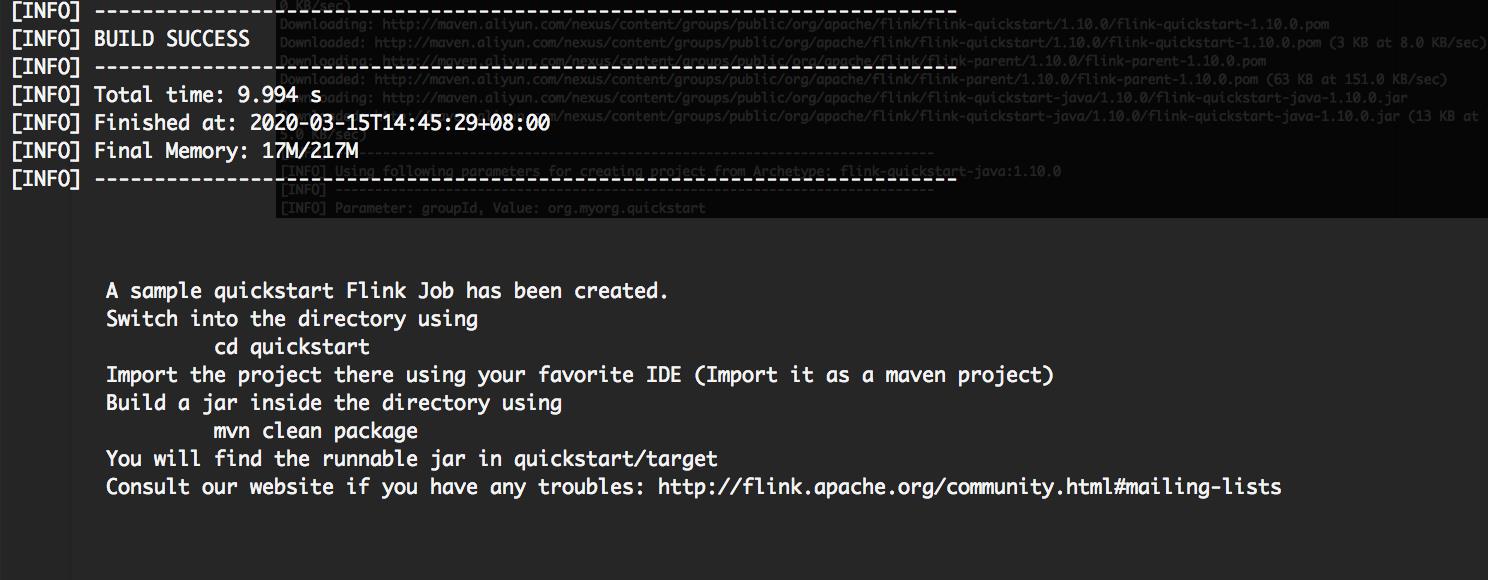
一般来说,我们在通过 IDE 创建工程,可以自己新建工程,添加 Maven 依赖,或者直接用 mvn 命令创建应用:
mvn archetype:generate \\
-DarchetypeGroupId=org.apache.flink \\
-DarchetypeArtifactId=flink-quickstart-java \\
-DarchetypeVersion=1.10.0
这里需要的主要的是,自动生成的项目 pom.xml 文件中对于 Flink 的依赖注释掉 scope:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> <!--<scope>provided</scope>--> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_${scala.binary.version}</artifactId> <version>${flink.version}</version> <!--<scope>provided</scope>--> </dependency>
DataSet WordCount (批处理)
WordCount 程序是大数据处理框架的入门程序,俗称“单词计数”。用来统计一段文字每个单词的出现次数,该程序主要分为两个部分:一部分是将文字拆分成单词;另一部分是单词进行分组计数并打印输出结果。
public static void main(String[] args) throws Exception { // 创建Flink运行的上下文环境 final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); // 创建DataSet,这里我们的输入是一行一行的文本 DataSet<String> text = env.fromElements( "Flink Spark Storm", "Flink Flink Flink", "Spark Spark Spark", "Storm Storm Storm" ); // 通过Flink内置的转换函数进行计算 DataSet<Tuple2<String, Integer>> counts = text.flatMap(new LineSplitter()) .groupBy(0) .sum(1); //结果打印 counts.printToErr(); } public static final class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap(String value, Collector<Tuple2<String, Integer>> out) { // 将文本分割 String[] tokens = value.toLowerCase().split("\\\\W+"); for (String token : tokens) { if (token.length() > 0) { out.collect(new Tuple2<String, Integer>(token, 1)); } } } }
实现的整个过程中分为以下几个步骤。
首先,我们需要创建 Flink 的上下文运行环境:
复制ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
然后,使用 fromElements 函数创建一个 DataSet 对象,该对象中包含了我们的输入,使用 FlatMap、GroupBy、SUM 函数进行转换。
最后,直接在控制台打印输出。
我们可以直接右键运行一下 main 方法,在控制台会出现我们打印的计算结果:

DataStream WordCount (流处理)
为了模仿一个流式计算环境,我们选择监听一个本地的 Socket 端口,并且使用 Flink 中的滚动窗口,每 5 秒打印一次计算结果。代码如下:
public class StreamingJob { public static void main(String[] args) throws Exception { // 创建Flink的流式计算环境 final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 监听本地9000端口 DataStream<String> text = env.socketTextStream("127.0.0.1", 9000, "\\n"); // 将接收的数据进行拆分,分组,窗口计算并且进行聚合输出 DataStream<WordWithCount> windowCounts = text .flatMap(new FlatMapFunction<String, WordWithCount>() { @Override public void flatMap(String value, Collector<WordWithCount> out) { for (String word : value.split("\\\\s")) { out.collect(new WordWithCount(word, 1L)); } } }) .keyBy("word") .timeWindow(Time.seconds(5), Time.seconds(1)) .reduce(new ReduceFunction<WordWithCount>() { @Override public WordWithCount reduce(WordWithCount a, WordWithCount b) { return new WordWithCount(a.word, a.count + b.count); } }); // 打印结果 windowCounts.print().setParallelism(1); env.execute("Socket Window WordCount"); } // Data type for words with count public static class WordWithCount { public String word; public long count; public WordWithCount() {} public WordWithCount(String word, long count) { this.word = word; this.count = count; } @Override public String toString() { return word + " : " + count; } } }
整个流式计算的过程分为以下几步。
首先创建一个流式计算环境:
复制StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
然后进行监听本地 9000 端口,将接收的数据进行拆分、分组、窗口计算并且进行聚合输出。代码中使用了 Flink 的窗口函数,我们在后面的课程中将详细讲解。
我们在本地使用 netcat 命令启动一个端口:
nc -lk 9000
然后直接运行我们的 main 方法:
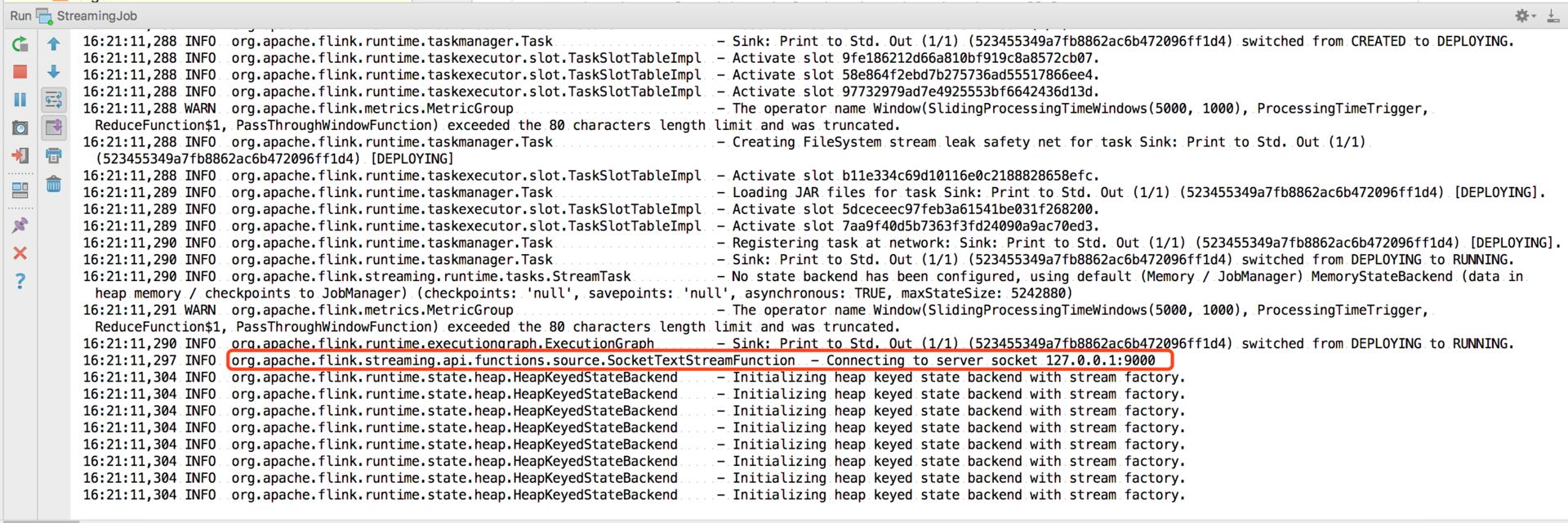
在 nc 中输入:
$ nc -lk 9000
Flink Flink Flink
Flink Spark Storm
可以在控制台看到:
Flink : 4 Spark : 1 Storm : 1
以上是关于Flink学习 批流版本的wordcount JAVA版本的主要内容,如果未能解决你的问题,请参考以下文章