垃圾收集器与内存分配策略
概述
程序计数器,虚拟机栈,本地方法栈随线程创建而产生,随线程销毁而消失,内存的分配和回收具有确定性,一般不考虑回收问题.
对象存活性判断
引用计数算法(Reference Counting)
特点:
- 在对象中添加一个引用计数器.
- 当有一个引用时,计数器加一;当一个引用失效时,计数器减一.
- 计数器为零时表示对象不可用.
- 存在对象间相互循环引用的问题.
可达性分析算法(Reachability Analysis)
特点:
- 通过根对象(GC Roots)作为起始节点集.
- 从这些根节点开始,根据引用关系向下搜索,搜索过的路径为引用链(Reference Chain).
- 若一个对象到GC Roots没有任何引用链链接,则该对象不再被使用.
GC Roots对象
- 虚拟机栈中(栈帧的本地变量表)引用的对象.(方法堆栈中使用的参数,局部变量,临时变量)
- 方法区中的类静态属性引用的对象.(类的引用类型静态变量)
- 方法区中常量引用对象.(字符串常量池中的引用)
- 本地方法栈中JNI引用的对象.
- Java虚拟机内部的引用.(基本数据类型对应的Class对象,异常对象,系统类加载器)
- 所有被同步锁持有的对象.
- Java虚拟机内存情况.(JMXBean,本地代码缓存)
- 可以将一些对象临时加入(需将相关联的对象加入)
引用的分类
分类:
- 强引用(Strongly Reference)
- 软引用(Soft Reference)
- 弱引用(Weak Reference)
- 虚引用(Phantom Reference)
强引用
- 创建对象并把对象赋给一个引用变量.
- 类似于
Object obj = new Object(),String str = "hello". - 垃圾收集器不会回收被引用的对象.
- 通过将引用赋为null来中断强引用.(Vector类的
clear()方法)
软引用
- 内存空间足够时,垃圾收集器不会回收。
- 若内存不足时,就会回收这些对象。
- 用于实现内存敏感的高速缓存(网页缓存,图片缓存)。
- 其每个实例保存一个对象的软引用,通过
get()方法返回强引用。 - 软引用不会影响垃圾收集器的回收。
- 垃圾收集器在抛出
OutOfMemoryError前尽量保留软可及对象,并且尽量保留刚创建或使用的软可及对象。 - 通过使用
ReferenceQueue保留引用对象,当引用所指向的对象被回收时,则引用对象进入队列。通过队列是否为空可以判断一个引用所指向的对象是否被回收。
示例:
Object obj = new Object();
SoftReference soft = new SoftReference(obj); // 创建一个软引用
obj = null; // 原对象设为null
Object getRef = soft.get(); // 若原对象没有被回收,则通过get()方法获取强引用
ReferenceQueue queue = new ReferenceQueue(); // 引用对象队列
SoftReference newSoft = new SoftReference(obj, queue); // 创建软引用时设置一个引用对象队列,若软引用指向的对象被回收,则引用对象进入队列
newSoft = null;
弱引用
- 用来描述非必需对象。
- 无论内存是否充足,都会回收只被弱引用关联的对象。
- 弱引用可以与引用队列结合使用,若弱引用所引用的对象被JVM回收,则对应的弱引用对象进入队列中。
WeakReference<Object> weakRef1 = new WeakReference<>(new Object());
System.out.println(weakRef1.get());
System.gc();
System.out.println(weakRef1.get()); // 只有弱引用,直接回收
Object obj = new Object();
WeakReference<Object> weakRef2 = new WeakReference<>(obj);
System.out.println(weakRef2.get());
System.gc();
System.out.println(weakRef2.get()); // 有强引用,不会被回收
虚引用
- 不影响对象的生命周期,和没有引用与之关联一样,随时可以被回收。
- 虚引用必须与引用队列关联,若一个对象被回收时,其虚引用会进入引用队列。
ReferenceQueue<Object> queue = new ReferenceQueue<>();
PhantomReference<Object> ref = new PhantomReference<Object>(new Object(),queue);
不可达与回收
- 不可达不是立即回收,需要经过一段时间。
- 对象被回收要经过两个阶段:
- 若对象没有与GC Roots有引用链,则被第一次标记。
- 若第二次扫描发现没有覆盖
finalize()或已被JVM调用过,则不会回收。
- 若需要执行
finalize()方法,则对象进入F-Queue队列中,可以在finalize()方法中避免被回收。 - 通过将自己(this)赋值给一个类变量或对象的成员变量,退出队列,避免被回收。
回收方法区
回收的内容:
- 不再使用的常量
- 不再使用的类型
常量:常量池中的类,接口,方法,字段的符号引用在没有对象引用时可能被清除。
类型:需满足三个条件:
- 该类的所有的实例都已被回收(没有该类或派生类的实例)
- 加载该类的类加载器已被回收
- 该类对应的
java.lang.Class对象没有地方被引用(无法反射访问类的方法)
垃圾收集算法
分类:
- 引用计数式垃圾收集(Reference Counting GC)/直接垃圾收集
- 追踪式垃圾收集(Tracing GC)/间接垃圾收集
分代收集理论(Generational Collection)
假说:
- 弱分代假说(Weak Generational Hypothesis):大多数对象存活时间较短。
- 强分代假说(Strong Generational Hypothesis):多次垃圾收集过程没有被回收的对象存活几率更大。
- 跨代引用假说(Intergenerational Reference Hypothesis):跨代引用相对于同代引用占极少数。
对Java堆的分类:(按照对象经历过垃圾收集的次数)
- 新生代(Yong Generation):每次有大量对象被回收。
- 老年代(Old Generation):新时代对象经历多个回收仍然存活。
注:
- 存活时间短的对象:保留较少的对象。
- 存活时间长的对象:较低频率回收该区域。
- 针对不同区域的划分:"Minor GC","Major GC","Full GC"。
- 不同区域匹配的垃圾回收算法:"标记-复制算法","标记-清除算法","标记-整理算法"。
- 对于跨代引用,在新生代中使用记忆集(Rememebered Set),将老年代划分成若干块,标记有跨代引用的老年代,在Minor GC时将对应的老年代对象加入GC Roots。
对GC的分类:
- 部分收集(Partial GC):目标不是完整收集整个堆的垃圾收集。
- 新生代收集(Minor GC/Young GC):目标只为新生代。
- 老年代收集(Major GC/Old GC):目标只为老年代(CMS收集器)。
- 混合收集(Mixed GC):目标是整个新生代和部分老年代。(G1收集器)。
- 整堆收集(Full GC):收集整个堆和方法区。
标记-清除算法(Mark-Sweep)
过程:
- 标记:标记出需要回收的对象。
- 清除:统一回收所有被标记的对象。
缺陷:
- 执行效率不稳定:大量需要回收的对象,则需要大量标记和清除动作,执行效率低。
- 内存空间的碎片化:清除后产生大量不连续内存碎片,导致新对象没有足够内存而出发新的垃圾收集动作。
标记-复制算法
半区复制(Semispace Copying)
- 将内存分成两个大小相同的块。
- 当一个块用完后,将存活的对象复制另外一个块上,将当前块的空间清理。
缺陷:
- 大量对象为存活时产生大量的内存复制开销.
- 可用内存缩小为原来的一半.
Appel式回收
- 新生代:
- 一块较大的*Eden空间**
- 两块较小的Survivor空间
- 每次只使用Eden和其中一块Survivor.
- 垃圾回收时,将Eden和Survivor中存活的对象复制到另外一块Survivor空间,然后清除Eden和之前的Survivor空间.
- HotSpot默认Eden:Survivor = 8:1.
- 当一个Survivor无法容纳一次Minor GC后存活的对象,则使用其他内存区域(老年代)进行分配担保(Handle Promotion).
标记-整理算法(Mark-Compact)
- 与标记-清除算法类似,先标记需要回收的对象.
- 将所有存活的对象都向内存空间的一端移动,并清理边界以外的内存.
缺陷:
- 当有大量存活的对象时,对象移动期间必须暂停用户应用(Stop The World).
- 内存的回收更加复杂.
注:
- 不移动对象 ==> 停顿时间短,收集器效率高,但内存分配耗时,总吞吐量下降,适用于延迟低的要求.(CMS收集器)
- 移动对象 ==> 整体吞吐量高.(Parallel Scavenge收集器)
- 结合两种 ==> 正常情况 ==> 标记-清除算法(容忍内存碎片), 碎片影响对象分配 ==> 标记-整理算法.
HotSpot算法细节实现
根节点枚举
经典垃圾收集器
Young generation:
- Serial
- ParNew
- Parallel Scavenge
Tenured generation:
- CMS
- Serial Old (MSC)
- Parallel Old
Serial收集器
特点:
- 单线程工作的收集器.
- 进行垃圾收集时,必须暂停其他所有工作线程,直到收集结束.
- 运行过程:
- 所有用户线程在safepoint暂停
- 然后GC线程对新生代采用复制算法
- 其后用户线程重新开始,再次到达safepoint后再次暂停
- GC线程(Serial Old)对老年代采用标记-整理算法,完成后再次启动用户线程.
- 简单高效,更高的单线程收集效率.
- 适用于新生代内存不大的情况.
ParNew收集器
特点:
- 实质是Serial收集器的多线程并行版本.
- 除了使用多个线程同时进行垃圾收集外.其他与Serial收集器完全一致.
- 运行流程:
- 用户线程运行到safepoint处中断.
- 多个GC线程并行对新生代采取复制算法.
- 用户线程恢复运行,直到新的safepoint处.
- GC线程对老年代采取标记-整理算法.
- 可与CMS收集器配合使用.
- 单核心处理器下不一定比Serial收集器好.
注:(收集器中的并行和并发)
- 并行(Parallel):多条垃圾收集器线程协同工作,用户线程处于等待状态.
- 并发(Concurrent):垃圾收集器线程和用户线程同时运行.
Parallel Scavenge收集器
特点:
- 基于标记-复制算法.
- 能够并行收集的多线程收集器.
- 关注于达到可控制的吞吐量(Throughput,吞吐量=用户代码运行时间/(用户代码运行时间+垃圾收集运行时间))
- 低停顿时间 ==> 交互性或服务响应质量要求高. 高吞吐量 ==> 高效利用处理器,尽快完成任务.
- 参数:
-XX:MaxGCPauseMills:控制最大垃圾收集停顿时间.(通过减少吞吐量和新生代空间)-XX:GCTimeRatio:吞吐量大小,垃圾收集:用户运行=1:设定值.-XX:+UseAdaptiveSizePolicy:系统自动调整新生代大小的比例,晋升老年代对象的大小.
Serial Old收集器
特点:
- 单线程收集器.
- 使用标记-整理算法.
- 与Parallel Scavenge收集器搭配使用,或CMS失败后作为后备.
- 用于收集老年代.
Parallel Old收集器
- 用于收集老年代.
- 支持多线程并发收集.
- 基于标记-整理算法.
- 注重吞吐量或处理器资源紧缺可优先考虑:Parallel Scavenge + Parallel Old.
CMS收集器(Concurrent Mark Sweep)
- 目标:获取最短回收停顿时间.
- 适用:关注服务响应速度,良好交互体验.
- 基于:标记-清除算法.
过程:
- 初始标记(CMS inital mark)
- 并发标记(CMS concurrent mark)
- 重新标记(CMS remark)
- 并发清除(CMS concurrent sweep)
详细介绍:
- 初始标记: 标记GC Roots能直接关联的对象.(单线程,需要暂停用户进程,速度快)
- 并发标记: 从GC Roots直接关联对象开始遍历整个对象图.(耗时但与用户线程并发运行)
- 重新标记: 修正在并发标记阶段,用户程序运行导致标记变动的对象的标记(暂停用户线程,多垃圾收集线程并发,较初始标记时间稍长)
- 并发清除: 清理需要收集的对象(与用户进程并发运行)
缺陷:
- 对处理器资源敏感.(导致应用变慢,降低吞吐量.处理器核心少时影响用户线程执行.)
- 无法处理"浮动垃圾"(Floating Garbage).
- 浮动垃圾:并发标记和并发清除阶段,用户线程并发运行产生的垃圾无法收集,需要等到下一次垃圾收集.
- 需预留足够的空间给用户线程并发使用.空间不足导致并发失败==>冻结用户线程,启用Serial Old收集器.
- 会产生大量内存碎片,影响对象分配.==>触发Full GC.
参数:
* -XX:CMSInitiatingOccupancyFraction:设置触发垃圾收集的老年代使用率.
* -XX:+UseCMSCompactAtFullCollection:设置每多少次Full GC前进行一次内存碎片合并.(0:每次都进行)
Garbage First收集器(G1)
特点:
- 面向局部收集,基于Region的内存布局形式.
- 一款能够建立停顿时间模型(Pause Prediction Model)的收集器.(一个M毫秒的时间片内,垃圾收集消耗的时间大概率不超过N毫秒)
- 面向堆内存任何部分组成回收集(Collection Set,CSet).
- 将堆空间分成多个大小相等的独立区域(Region),每个区域可当作Eden空间,Survivor空间或老年代空间.
- 使用Humongous区域存放超过一个Region容量一半的大对象.一个Region可设为1MB~32MB.超过整个Region的对象放在连续的多个Humongous区域中.
G1实现可预测的停顿时间的原因:
- 将Region作为单次回收的最小单位,而非整个堆的全区域.
- 跟踪各个Region垃圾收集的价值(收集的大小与花费的时间).
- 使用优先级列表维护各个Region的收集价值,根据设定的收集停顿时间,优先处理收集回报大的Region.
实现细节:
- 跨Region引用对象:
- 每个Region维护自己的记忆集.
- 记忆集中记录其他Region指向自己的指针和对应的卡页范围.
- 本质上是哈希表:key是其他Region的起始地址,value时卡表的索引号.
- 需要额外的内存占用.
- 并发标记阶段与用户线程互不干扰:
- 通过原始快照(SATB)算法解决.
- 每个Region设置两个TAMS(Top at Mark Start)指针,将Region的一部分空间划分出来用于并发回收过程中创建的新对象.
- 建立可靠的停顿预测模型:
- 基于衰减均值(Decaying Average)理论实现.
- 标记每个Region的回收耗时,记忆集中的脏卡数量等回收成本,计算平均值,标准偏差,置信度等信息.
- 更容易受到最近状态的影响,由这些信息预测回收集.
回收过程:
- 初始标记(Initial Marking)
- 标记GC Roots直接关联的对象.
- 修改TAMS指针,使得与用户线程并发运行时可以在Region分配新对象.
- 停顿线程,耗时短,使用Minor GC完成.
- 并发标记(Concurrent Marking)
- 从GC Roots开始对堆中对象进行可达性分析.
- 扫描整个堆中的对象图,找到要回收的对象.
- 耗时长,可与用户线程并发执行.
- 扫描后更新SATB记录并发时有引用变动的对象.
- 最终标记(Final Marking)
- 暂停用户线程,处理并发阶段结束后存在的少量SATB记录.
- 筛选回收(Live Data Counting and Evacuation)
- 更新Region统计信息.
- 对每个Region回收价值和成本进行排序.
- 根据用户期望停顿时间指定回收计划.
- 选择Region组成回收集.
- 将回收集中存活对象复制到空Region中,清理旧的Region.
- 需暂停用户线程,由多条收集器线程并行完成.
注:
- 设置期望停顿时间:一般在100~300毫秒间.停顿时间太短 ==> 每次收集器很小 ==> 收集速度小于分配速度,垃圾堆积 ==> 堆满引发Full GC.
- 目标:收集速度能跟得上内存分配速率(Allocation Rate).
G1与CMS的对比
- CMS:基于"标记-清除"算法;G1:整体基于"标记-整理"算法,局部基于"标记-复制"算法,不会产生空间碎片.
- G1的卡表复杂,新生代和老年代都有卡表,内存消耗高.
- CMS:使用写后屏障更新卡表;G1:除了写后屏障更新卡表外,使用写前屏障跟踪并发时指针变化.==>减少最终标记阶段的停顿时间,但带来额外的计算负担.
低延迟垃圾收集器
衡量垃圾收集器的三个指标:
- 内存占用(Footprint)
- 吞吐量(Throughput)
- 延迟(Latency)
各种收集器的并发情况:
| 收集器 | Young GC | Old GC |
|---|---|---|
| Serial,Parallel | Copy(非并发) | Mark == >Compact(非并发) |
| CMS | Copy(非并发) | Init Mark(非并发) == >Concurrent Mark(并发) == >Finish Mark(非并发) == >Concurrent Sweep(并发) |
| G1 | Copy(非并发) | Init Mark(非并发) == >Courrent Mark(并发) == >Compact(并发) |
| Shenandoah,ZGC | Init Mark(非并发) == > Concurrent Partial(并发) == > Finish Mark(非并发) | Init Mark(并发) ==> Concurrent Mark(并发) ==> Finish Mark(非并发) == > Concurrent Compact(并发) |
Shenandoah收集器
- 来自RetHat的第一款非Oracle开发的HotSpot垃圾收集器。
- 目标:任何堆大小实现垃圾收集停顿时间限制在十毫秒内。
- 是基于Region的堆内存布局。
- 有存放大对象的Humongous Region。
- 回收策略是优先处理回收价值大的Region。
- 与G1的不同:
- 支持并发的整理算法。
- 不使用分代收集。
- 使用"连接矩阵"(Connection Matrix)的全局数据结构记录跨Region的引用关系。(连接矩阵:若Region N有对象指向Region M,则第N行第M列打上标记)
工作流程:
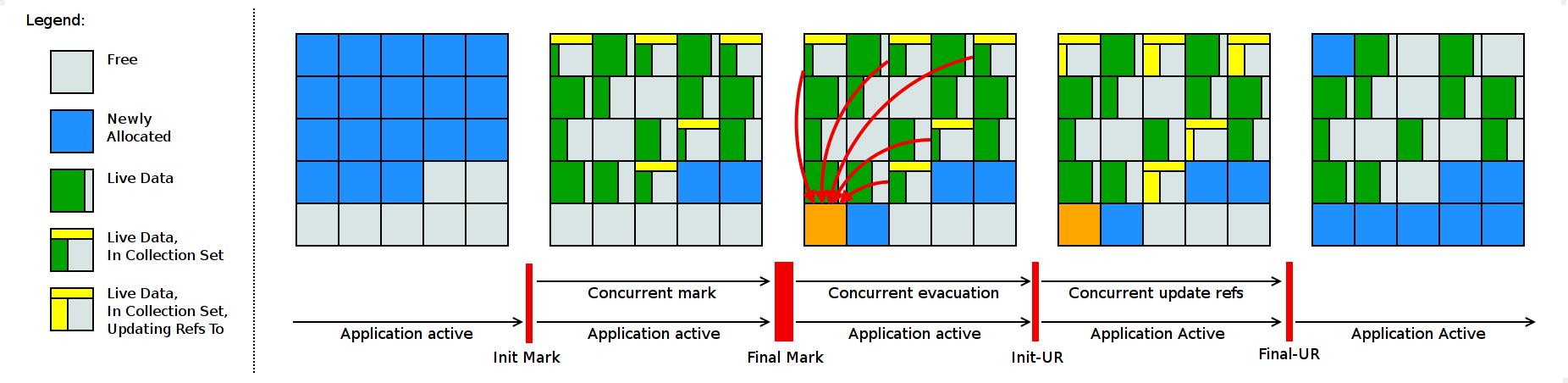
- 初始标记(Initial Marking):标记与GC Roots直接关联的对象(停止用户线程,时间与GC Roots数量有关)
- 并发标记(Concurrent Marking):遍历对象图,标记所有可达的对象(并发进行)
- 最终标记(Final Marking):扫描剩余SATB,统计回收价值,对Region排序构成回收集(短暂暂停用户线程)
- 并发清理(Concurrent Cleanup):清理没有存活对象的Region(Immediate Garbage Region)
- 并发回收(Concurrent Evacuation):将回收集中存活的对象复制到未被使用的Region中(通过读屏障和"Brooks Pointers"转发指针实现)
- 初始引用更新(Initial Update Reference):将堆中指向旧对象的引用修正到复制后的新地址(引用更新)。初始化阶段:建立线程集合点,确保回收任务的收集器线程完成任务。(短暂停顿)
- 并发引用更新(Concurrent Update Reference):进行引用更新操作。(与用户线程并发执行,按照物理地址搜索引用)
- 最终引用更新(Final Update Reference):修正在GC Roots中的引用。(停顿)
- 并发清理(Concurrent Cleanup):再调用来回收Immediate Garbage Regions.
三个主要阶段:
- 并发标记
- 并发回收
- 并发引用更新
对象移动和用户程序并发问题
- 传统方式:原来内存上设置保护陷阱(Memory Protection Trap),用户程序访问旧内存地址会产生自陷中断,进入核心态,由其中的代码逻辑将访问转发发哦复制后的新对象中。(用户态与核心态切换,成本大)
- 转发指针(Forwarding Pointer/Indirection Pointer):每个对象前有一个引用字段,若正常,则指向自己;若处于并发移动,则指向新对象。(增加额外内存消耗和转向开销)
并发更新问题:对象移动时,保证对象的更新发生在新对象上。 == >通过CAS操作保证用户线程和收集器线程对转发指针的访问只有一个会成功。
为了实现Brooks Pointer,使用读屏障。读取的频率高,不能使用重量级操作。 ==> 使用基于引用访问屏障(Load Reference Barrier)。只拦截对象中数据类型为引用类型的读写操作。
ZGC收集器
ZGC收集器是一款基于Region内存布局的,不设分代的,使用了读屏障,染色指针和内存多重映射等技术实现可并发的标记-整理算法的,以低延迟为首要目标的垃圾收集器.
ZGC的内存布局
- 基于Region(Page/ZPage)的堆内存布局.
- 具有动态性:动态创建和销毁,动态的区域容量大小.
- 三种类型的容量:
- Small Region
- Medium Region
- Large Region
| 名称 | 容量 | 特点 |
|---|---|---|
| 小型Region | 2MB | 放置小于256KB的小对象 |
| 中型Region | 32MB | 放置大于等于256KB小于4MB的对象 |
| 大型Region | 动态变化,为2MB的整数倍 | 放置4MB以上大对象,每个Region只放一个对象,不会被重分配 |
并发整理算法
- 采用染色指针技术(Colored Pointer).
- 将少量额外信息存储在指针上.
- 64位指针的高18位不能用于寻址,剩下的46位指针中,高4位提取出来用于存储四个标志信息.
- 四个状态位:
- Finalizable: 是否只能通过
finalize()方法才能被访问 - Remapped: 是否进入重分配集(即被移动过)
- Marked 1:三色标记状态
- Marked 0:三个标记状态
- Finalizable: 是否只能通过
染色指针的实现
使用多重映射(Multi-Mapping):将多个不同的虚拟内存地址映射到同一个物理内存地址上.
可以将不同的地址段映射到同一个物理内存空间.
ZGC运行过程(都是并发执行的)
- 并发标记(Concurrent Mark):遍历对象图做可达性分析(标记在指针上进行,更新染色指针的Marked 0和Marked 1)
- 并发预备重分配(Concurrent Prepare for Relocate):根据查询条件统计收集过程清理的Region,将这些Region组成重分配集(Relocation Set)(扫描所有Region,重分配集决定Region内存活的对象被复制到其他Region,该Region被释放)
- 并发重分配(Concurrent Relocate):将重分配集中的存活对象复制到新的Region上,为重分配表的每个Region维护一个转发表(Forward Table),记录旧对象到新对象的转向关系.首次访问旧对象会被内存屏障捕获,然后根据转发表进行转发,然后更新该引用,使其指向新对象,后续直接访问新对象(自愈,Self-Healing).
- 并发重映射(Concurrent Remap):修正整个堆中指向重分配集中旧对象的所有引用.(可以与下次并发阶段一起完成)
优势:
- 一旦某热Region中存活的对象被移走,则该Region立即被释放重新使用.不需要浪费一半空闲Region完成收集.
- 减少内存屏障使用,提高运行效率.
- 若开发高18位,则可进行扩展,存储更多标志信息.
- 没有记忆集,卡表等,节省内存空间.
- 支持NUMA-Aware的内存分配:优先尝试在请求线程所处的处理器本地内存分配对象,保证高速内存访问.
缺陷:
- 4TB内存限制
- 不支持32位
- 不支持压缩指针
- 大型堆并发收集时间长,收集速率可能不及分配新对象的速率.
参考: