SpringCloud----分布式事务
Posted 小名的同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SpringCloud----分布式事务相关的知识,希望对你有一定的参考价值。
分布式事务
方式1:2PC(两阶段提交协议)
参考:https://www.cnblogs.com/balfish/p/8658691.html
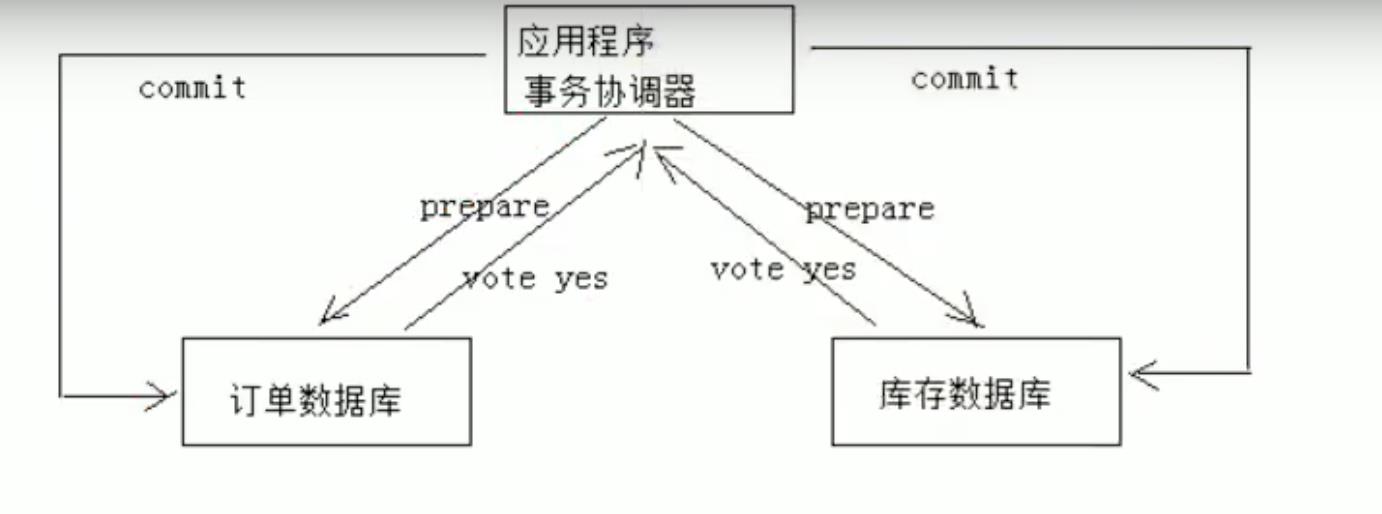
- 1、应用程序连接两个数据源。
- 2、应用程序通过事务协调器向两个库发起prepare ,两个数据库收到消息分别执行本地事务( 记录日志),不提交,如果执行成功则回复yes ,否则回复no。
- 3、事务协调器收到回复,只要有一方向复no则分别向参 与者发起回滚事务,参与者开始回滚事务。
- 4、事务协调器收到回复,全部回复yes ,此时向参与者发起提交事务。如果参与者有一方提交事务失败则由事务协调器发起回滚事务。
2PC
- 优点:实现强一致性,部分关系数据库支持( Oracle、mysql等)。
- 缺点:整个事务的执行需要由协调者在多个节点之间去协调,增加了事务的执行时间,性能低下。
- 解决方案有: springboot+Atomikos or Bitronix
3PC
方式2:事务补偿(TCC)
TCC事务补偿是基于2PC实现的业务层事务控制方案,它是Try、Confirm和Cancel三个单词的首字母,含义如下:
- 1、Try检查及预留业务资源完成提交事务前的检查,并预留好资源。
- 2、Confirm 确定执行业务操作、对try阶段预留的资源正式执行。
- 3、Cancel 取消执行业务操作、对try阶段预留的资源释放。
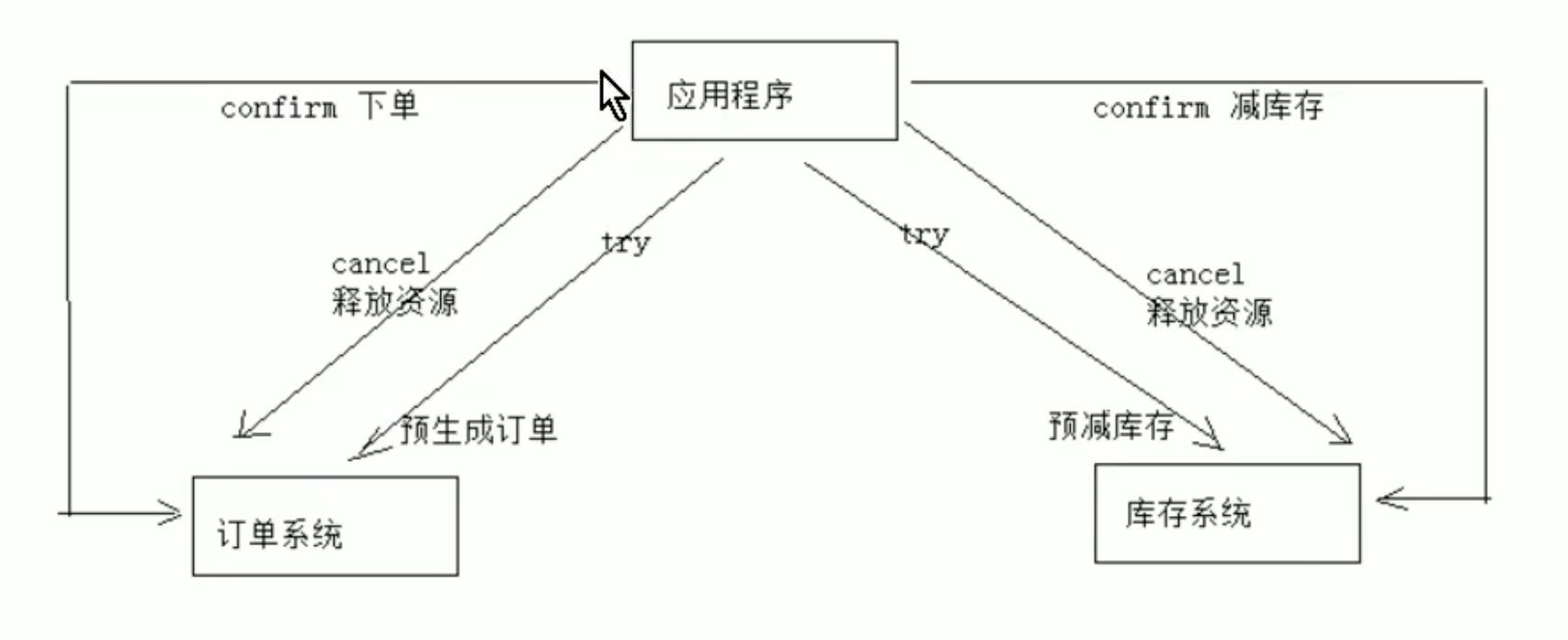
1、Try
下单业务由订单服务和库存服务协同完成,在try阶段订单服务和库存服务完成检查和预留资源。订单服务检查当前是否满足提交订单的条件(比如:当前存在未完成订单的不允许提交新订单)。库存服务检查当前是否有充足的库存,并锁定资源。
2、Confirm
订单服务和库存服务成功完成Try后开始正式执行资源操作。订单服务向订单写一条订单信息。库存服务减去库存。(真实向数据库写入数据)
3、Cancel
如果订单服务和库存服务有一方出現失敗則全部取消操作。订单服务需要刪除新増的订单信息。库存服务减去的库存还原(事务补偿)
优点:最终保证数据的一致性,在业务层实现事务控制,灵活性好。
缺点:开发成本高,每个事务操作每个参与者都需要实现try/confirm/cancel三个接口(由程序员自己实现)。
注意: TCC的try/confirm/cancel接口都要实现幂等性,在为在try、confirm. cancel失败后要 不断重试。
什么是幂等性?
幂等性是指同一个操作无论请求多少次,其结果都相同。
幂等操作实现方式有:
- 1、操作之前在业务方法进行判断如果执行过了就不再执行。
- 2、缓存所有请求和处理的结果,已经处理的请求则直接返回结果。
- 3、在数据库表中加一个状态字段(未处理,已处理) , 数据操作时判断未处理时再处理。
方式3:消息队列实现最终一致性
将分布式事务拆分成多个本地事务来完成,并且由消息队列异步协调完成
案
基于zookeeper实现分布式锁
参考:https://blog.csdn.net/emprere/article/details/107308413
参考:https://www.cnblogs.com/Chenjiabing/p/12666426.html
Zookeeper是一种提供配置管理、分布式协同以及命名的中心化服务。
zk的模型是这样的:zk包含一系列的节点,叫做znode,就好像文件系统一样每个znode表示一个目录
-
持久性节点:节点创建后将会一直存在
-
临时节点:临时节点的生命周期和当前会话绑定,一旦当前会话断开临时节点也会删除,当然可以主动删除。
-
持久有序节点:节点创建一直存在,并且zk会自动为节点加上一个自增的后缀作为新的节点名称。
-
临时有序节点:保留临时节点的特性,并且zk会自动为节点加上一个自增的后缀作为新的节点名称。
事件监听
在读取数据时,我们可以同时对节点设置事件监听,当节点数据或结构变化时,zookeeper会通知客户端。当前zookeeper有如下四种事件:
-
节点创建
-
节点删除
-
节点数据修改
-
子节点变更
zk实现分布式锁的落地方案zk实现分布式锁的落地方案
-
使用zk的临时节点和有序节点,每个线程获取锁就是在zk创建一个临时有序的节点,比如在/lock/目录下。
-
创建节点成功后,获取/lock目录下的所有临时节点,再判断当前线程创建的节点是否是所有的节点的序号最小的节点
-
如果当前线程创建的节点是所有节点序号最小的节点,则认为获取锁成功。
-
如果当前线程创建的节点不是所有节点序号最小的节点,则对节点序号的前一个节点添加一个事件监听。
比如当前线程获取到的节点序号为
/lock/003,然后所有的节点列表为[/lock/001,/lock/002,/lock/003],则对/lock/002这个节点添加一个事件监听器。
如果锁释放了,会唤醒下一个序号的节点,然后重新执行第3步,判断是否自己的节点序号是最小。
比如/lock/001释放了,/lock/002监听到时间,此时节点集合为[/lock/002,/lock/003],则/lock/002为最小序号节点,获取到锁。
整个过程如下:

Curator介绍
基于Zookeeper实现分布式锁,使用方式也比较简单
//arg1:CuratorFramework连接对象,arg2:节点路径path lock=new InterProcessMutex(client,\'/local\'); //获取锁 lock.acquire(); //释放锁 lock.release();
其实现分布式锁的核心源码如下:
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception
{
boolean haveTheLock = false;
boolean doDelete = false;
try {
if ( revocable.get() != null ) {
client.getData().usingWatcher(revocableWatcher).forPath(ourPath);
}
while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock ) {
// 获取当前所有节点排序后的集合
List<String> children = getSortedChildren();
// 获取当前节点的名称
String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash
// 判断当前节点是否是最小的节点
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
if ( predicateResults.getsTheLock() ) {
// 获取到锁
haveTheLock = true;
} else {
// 没获取到锁,对当前节点的上一个节点注册一个监听器
String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();
synchronized(this){
Stat stat = client.checkExists().usingWatcher(watcher).forPath(previousSequencePath);
if ( stat != null ){
if ( millisToWait != null ){
millisToWait -= (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
if ( millisToWait <= 0 ){
doDelete = true; // timed out - delete our node
break;
}
wait(millisToWait);
}else{
wait();
}
}
}
// else it may have been deleted (i.e. lock released). Try to acquire again
}
}
}
catch ( Exception e ) {
doDelete = true;
throw e;
} finally{
if ( doDelete ){
deleteOurPath(ourPath);
}
}
return haveTheLock;
}
redis和zk的实现方案中各自的优缺点
对于redis的分布式锁而言,它有以下缺点:
-
它获取锁的方式简单粗暴,获取不到锁直接不断尝试获取锁,比较消耗性能。
-
另外来说的话,redis的设计定位决定了它的数据并不是强一致性的,在某些极端情况下,可能会出现问题。锁的模型不够健壮
-
即便使用redlock算法来实现,在某些复杂场景下,也无法保证其实现100%没有问题,关于redlock的讨论可以看How to do distributed locking
-
redis分布式锁,其实需要自己不断去尝试获取锁,比较消耗性能。
但是另一方面使用redis实现分布式锁在很多企业中非常常见,而且大部分情况下都不会遇到所谓的“极端复杂场景”
所以使用redis作为分布式锁也不失为一种好的方案,最重要的一点是redis的性能很高,可以支撑高并发的获取、释放锁操作。
对于zk分布式锁而言:
-
zookeeper天生设计定位就是分布式协调,强一致性。锁的模型健壮、简单易用、适合做分布式锁。
-
如果获取不到锁,只需要添加一个监听器就可以了,不用一直轮询,性能消耗较小。
但是zk也有其缺点:如果有较多的客户端频繁的申请加锁、释放锁,对于zk集群的压力会比较大。
以上是关于SpringCloud----分布式事务的主要内容,如果未能解决你的问题,请参考以下文章