Spring Cloud 使用sleuth&zipkin 链路追踪
Posted 昕友软件开发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spring Cloud 使用sleuth&zipkin 链路追踪相关的知识,希望对你有一定的参考价值。
微服务系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位服务故障点,以对症下药。于是就有了分布式系统调用跟踪的诞生。
针对微服务化应用链路追踪的问题,Google在2010年发表了论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,这篇文章是业内实现链路追踪的标杆和理论基础,具有非常大的参考价值。目前链路追踪组件主要有Google的Dapper,Twitter 的Zipkin,以及阿里的Eagleeye (鹰眼)等,它们都是非常优秀的链路追踪开源组件。
Spring Cloud Sleuth是 Spring Cloud为分布式服务链路跟踪提供的解决方案。本文我们将详细介绍与分析 Spring Cloud Sleuth + Zipkin 的实现原理。
sleuth是spring cloud的分布式跟踪工具,主要记录链路调用数据,本身只支持内存存储,在业务量大的场景下,为拉提升系统性能也可通过http传输数据,也可换做rabbit或者kafka来传输数据。
zipkin是Twitter开源的分布时追踪系统,可接收数据,存储数据(内存/cassandra/mysql/es),检索数据,展示数据,他本神不会直接在分布式的系统服务种trace追踪数据,可便捷的使用sleuth来收集传输数据。
Spring Cloud Sleuth
- 提供链路追踪。通过sleuth可以很清楚的看出一个请求都经过了哪些服务;可以很方便的理清服务间的调用关系。
- 可视化错误。对于程序未捕捉的异常,可以结合zipkin分析。
- 分析耗时。通过sleuth可以很方便的看出每个采样请求的耗时,分析出哪些服务调用比较耗时。当服务调用的耗时随着请求量的增大而增大时,也可以对服务的扩容提供一定的提醒作用。
- 优化链路。对于调用频繁的服务,可以并行调用或针对业务做一些优化措施等。
Spring Cloud Sleuth可以追踪以下类型的组件:async,hystrix,messaging,websocket,rxjava,scheduling,web(SpringWebMvc,Spring WebFlux, Servlet),webclient(Spring RestTemplate),feign,zuul。通过spring-cloud-sleuth-core的jar包结构,可以很明显的看出,sleuth支持链路追踪的组件(web下面包括http、client和feign)。
通讯方式:
- sleuth 默认采用 http 通信方式,将数据传给 zipkin 作页面渲染,但是 http 传输过程中如果由于不可抗因素导致 http 通信中断,那么此次通信的数据将会丢失。而使用中间件的话,RabbitMQ 消息队列可以积压千万级别的消息,下次重连之后可以继续消费。
- 随着线程增多,并发量提升之后,RabbitMQ 异步发送数据明显更具有优势。
- RabbitMQ 支持消息、队列持久化,可以通过消息状态落库、重回队列、镜像队列等技术手段保证其高可用。
zipkin
来自Twitte的分布式日志收集工具,分为上传端(spring-cloud-starter-zipkin,集成到项目中)与服务端(独立部署,默认将数据存到内存中)
注意: Zipkin仅对RPC通信过程进行记录,注意它与业务代码日志是无关的,如果你希望找到一款LogAppender来分析所有Log4j留下的日志,那么建议还是使用Kakfa+ELK这种传统的方法来实现。
Zipkin Server主要包括四个模块:
(1)Collector 接收或收集各应用传输的数据
(2)Storage 存储接受或收集过来的数据,当前支持Memory,MySQL,Cassandra,ElasticSearch等,默认存储在内存中。
(3)API(Query) 负责查询Storage中存储的数据,提供简单的JSON API获取数据,主要提供给web UI使用
(4)Web 提供简单的web界面
两者之间的关系
即sleuth是zipkin的一个java spring 库。
zipkin架构

下载zipkin
https://github.com/openzipkin/zipkin/releases
安装Zipkin
Docker方式
The Docker Zipkin project is able to build docker images, provide scripts and a docker-compose.yml for launching pre-built images. The quickest start is to run the latest image directly:
docker run -d -p 9411:9411 openzipkin/zipkin
Java jar方式
curl -sSL https://zipkin.io/quickstart.sh | bash -s java -jar zipkin.jar
源码方式
# get the latest source git clone https://github.com/openzipkin/zipkin cd zipkin # Build the server and also make its dependencies ./mvnw -DskipTests --also-make -pl zipkin-server clean install # Run the server java -jar ./zipkin-server/target/zipkin-server-*exec.jar
启动后访问:
依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>2.0.4.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
<version>2.0.4.RELEASE</version>
</dependency>
注意,Finchley一定要和2.0.X的sleuth相配合,如果使用了2.2.X,就会报错。
zipkin-release-2.21以上版本不受sleuth客户端影响。
配置
spring.zipkin.base-url=http://localhost:9411/ spring.zipkin.service.name=springboot2-nacos-consumer spring.zipkin.sender.type=web
spring.sleuth.sampler.percentage=1
还可以使用RabbitMQ方式,而web方式是通过http向9411发送数据,随着线程数的增加也就是并发量的增加,mq 传输时延将会大大低于 http。
#sleuth 使用 rabbitmq 来向 zipkin 发送数据 spring.zipkin.sender.type=rabbit spring.rabbitmq.host=localhost spring.rabbitmq.port=5672 spring.rabbitmq.username=guest spring.rabbitmq.password=guest
feign调用
@Autowired private EchoService echoService; @GetMapping(value = "/feignEcho/{str}") public String feignEcho(@PathVariable String str) { return echoService.echo(str); }
测试http://localhost:8090/feignEcho/
发现zipkin进行了数据采集

链路过程,首先访问springboot2-nacos-consumer的feignEcho,然后访问springboot2-nacos-discovery的echo。
spring.sleuth.sampler.percentage参数配置(如果不配置默认0.1),如果我们调大此值为1,可以看到信息收集就更及时。但是当这样调整后,我们会发现我们的rest接口调用速度比0.1的情况下慢了很多,即使在0.1的采样率下,我们多次刷新consumer的接口,会发现对同一个请求两次耗时信息相差非常大。
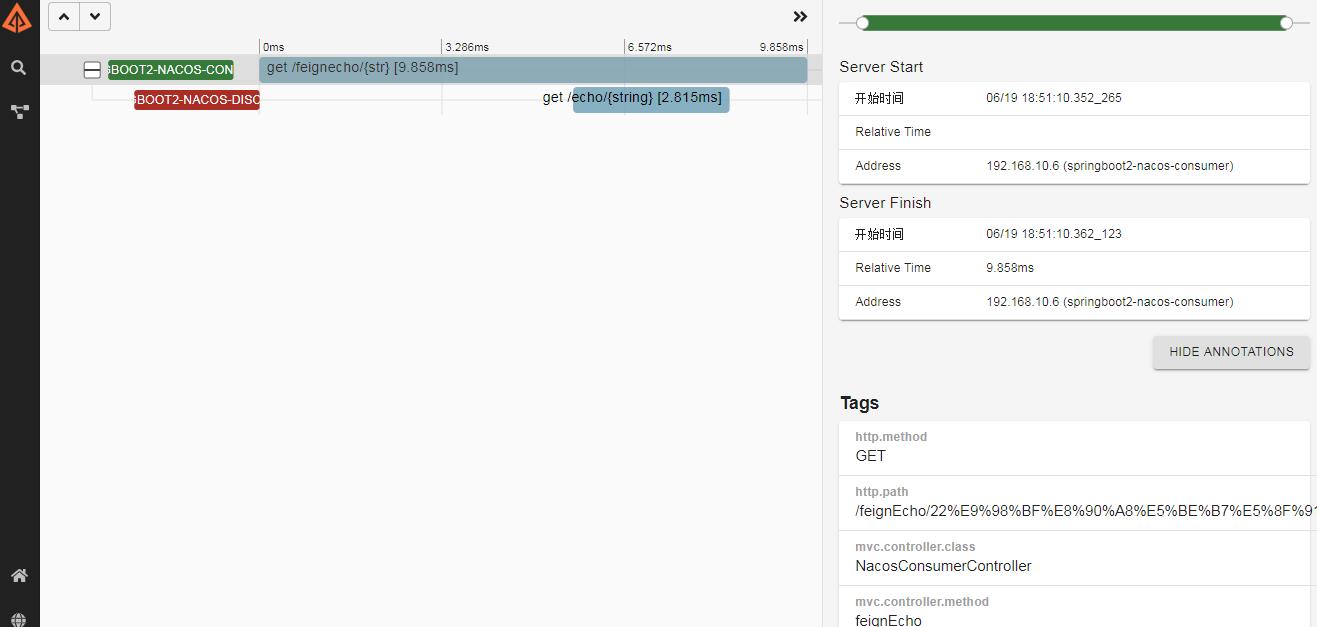
具体的链路

下载zipkin的json文件
[{"traceId":"8da56c7f067fbe9f",
"parentId":"8da56c7f067fbe9f",
"id":"e55168fadce7489a",
"kind":"CLIENT",
"name":"get",
"timestamp":1592563870357910,
"duration":2815,
"localEndpoint":{"serviceName":"springboot2-nacos-consumer","ipv4":"192.168.10.6"},
"tags":{"http.method":"GET","http.path":"/echo/22阿萨德发asdf"}},
{"traceId":"8da56c7f067fbe9f",
"id":"8da56c7f067fbe9f",
"kind":"SERVER",
"name":"get /feignecho/{str}",
"timestamp":1592563870352265,
"duration":9858,
"localEndpoint":{"serviceName":"springboot2-nacos-consumer","ipv4":"192.168.10.6"},
"remoteEndpoint":{"ipv6":"::1","port":63372},
"tags":{"http.method":"GET","http.path":"/feignEcho/22%E9%98%BF%E8%90%A8%E5%BE%B7%E5%8F%91asdf","mvc.controller.class":"NacosConsumerController","mvc.controller.method":"feignEcho"}},
{"traceId":"8da56c7f067fbe9f",
"parentId":"8da56c7f067fbe9f",
"id":"e55168fadce7489a",
"kind":"SERVER",
"name":"get /echo/{string}",
"timestamp":1592563870359087,
"duration":1641,
"localEndpoint":{"serviceName":"springboot2-nacos-discovery","ipv4":"192.168.10.6"},
"remoteEndpoint":{"ipv4":"192.168.10.6","port":63374},
"tags":{"http.method":"GET","http.path":"/echo/22%E9%98%BF%E8%90%A8%E5%BE%B7%E5%8F%91asdf","mvc.controller.class":"NacosProviderController","mvc.controller.method":"echo"},"shared":true}]
源码
以上是关于Spring Cloud 使用sleuth&zipkin 链路追踪的主要内容,如果未能解决你的问题,请参考以下文章