现在tensorflow和mxnet很火,是不是还有必要学习scikit-learn等框架
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了现在tensorflow和mxnet很火,是不是还有必要学习scikit-learn等框架相关的知识,希望对你有一定的参考价值。
参考技术A 很有必要,但不用太深入,在Kaggle上认真搞2,3个比赛能进10%的程度就够了 参考技术B 1.1 MXNet相关概念深度学习目标:如何方便的神经网络,以及如何快速训练得到模型
CNN(卷积层):表达空间相关性(学表示)
RNN/LSTM:表达时间连续性(建模信号)
命令式编程(imperative programming):嵌入的较浅,其中每个语句都按原来的意思执行,如numpy和Torch就是属于这种
声明式语言(declarative programing):嵌入的很深,提供一整套针对具体应用的语言。即用户只需要声明要做什么,而具体执行则由系统完成。这类系统包括Caffe,Theano和TensorFlow。命令式编程显然更容易懂一些,更直观一些,但是声明式的更做优化,以及更利于做自动求导,所以都保留。
浅嵌入,命令式编程
深嵌入,声明式编程
如何执行a=b+1
需要b已经被赋值。立即执行,将结果保存在a中。
返回对应的计算图(computation graph),我们可以之后对b进行赋值,然后再执行加法运算
语义上容易理解,灵活,可以精确控制行为。通常可以无缝的和言交互,方便的利用主语言的各类算法,工具包,bug和性能调试器。
在真正开始计算的时候已经拿到了整个计算图,所以我们可以做一系列优化来提升性能。实现辅助函数也容易,例如对任何计算图都提供forward和backward函数,对计算图进行可视化,将图保存到硬盘和从硬盘读取。
实现统一的辅助函数和提供整体优化都很困难。
很多主语言的特性都用不上。某些在主语实现简单,但在这里却经常麻烦,例如if-else语句 。debug也不容易,例如监视一个复杂的计算图中的某个节点的中间结果并不简单。
目前现有的系统大部分都采用上两种编程模式的一种。与它们不同的是,MXNet尝试将两种模式无缝的结合起来。在命令式编程上MXNet提供张量运算,而声明式编程中MXNet支持符号表达式。用户可以自由的混合它们来快速实现自己的想法。例如我们可以用声明式编程来描述神经网络,并利用系统提供的自动求导来训练模型。另一方便,模型的迭代训练和更新模型法则中可能涉及大量的控制逻辑,因此我们可以用命令式编程来实现。同时我们用它来进行方便的和与主语言交互数据。
1.2 深度学习的关键特点
(1)层级抽象
(2)端到端学习
TensorFlow
C++/Lua/cuda
Python/c++/cuda
Python/Matlab
Python/R/Julia/Go
CPU/GPU/FPGA
CPU/GPU/Mobile
CPU/GPU/Mobile
Linux, OSX
Linux, OSX
C++/Python
Python/R/Julia/Go
符号张量图
符号张量图
$T.total > 0 && $T.page <= $T.pageNum
#foreach $T.data as r
$T.r.formt_tm#if $T.r.nickname#else匿名#/if
$T.r.content
#if $T.page > 1 && $T.pageNum > 1)
$T.s_num > 2
#for index = $T.s_num to $T.e_num
$T.pageNum > $T.pageNavSize+ 2 && $T.s_num != $T.pageNum - $T.pageNavSize
#if $T.pageNum > 1
#if $T.pageNum != $T.page && $T.pageNum > 1
<a href="javascript:void(0);" page="$T.page 下一页
您的回应...
也许你感兴趣
(window.slotbydup=window.slotbydup || []).push(
id: '3465635',
container: s,
size: '120,240',
display: 'float'
(C)2012 本站提供的内容来源于广大网络用户,我们不保证内容的正确性。如果转载了您的内容,希望删除的请联系我们!机器学习和深度学习的最佳框架大比拼
在过去的一年里,咱们讨论了六个开源机器学习和/或深度学习框架:Caffe,Microsoft Cognitive Toolkit(又名CNTK 2),MXNet,Scikit-learn,Spark MLlib和TensorFlow。如果把网撒得大些,可能还会覆盖其他几个流行的框架,包括Theano(一个10年之久的Python深度学习和机器学习框架),Keras(一个Theano和TensorFlow深度学习的前端),DeepLearning4j(Java和Scala在Hadoop和Spark之上的深度学习软件)。如果你有兴趣使用机器学习和神经网络,你从来没有像现在这样多的选择。机器学习框架和深度学习框架之间有区别。本质上,机器学习框架涵盖用于分类,回归,聚类,异常检测和数据准备的各种学习方法,并且其可以或可以不包括神经网络方法。深度学习或深度神经网络(DNN)框架涵盖具有许多隐藏层的各种神经网络拓扑。这些层包括模式识别的多步骤过程。网络中的层越多,可以提取用于聚类和分类的特征越复杂。Caffe,CNTK,DeepLearning4j,Keras,MXNet和TensorFlow是深度学习框架。 Scikit-learning和Spark
MLlib是机器学习框架。 Theano跨越了这两个类别。一般来说,深层神经网络计算在GPU(特别是Nvidia
CUDA通用GPU,大多数框架)上运行的速度要比CPU快一个数量级。一般来说,更简单的机器学习方法不需要GPU的加速。虽然你可以在一个或多个CPU上训练DNN,训练往往是缓慢的,慢慢我不是说秒或分钟。需要训练的神经元和层数越多,可用于训练的数据越多,需要的时间就越长。当Google
Brain小组在2016年针对新版Google翻译训练语言翻译模型时,他们在多个GPU上同时运行了一周的训练时间。没有GPU,每个模型训练实验将需要几个月。这些框架中每一个框架具有至少一个显著特征。
Caffe的强项是用于图像识别的卷积DNN。 Cognitive Toolkit有一个单独的评估库,用于部署在ASP.Net网站上工作的预测模型。 MXNet具有良好的可扩展性,可用于多GPU和多机器配置的训练。
Scikit-learn具有广泛的强大的机器学习方法,易学已用。 Spark MLlib与Hadoop集成,具有良好的机器学习可伸缩性。
TensorFlow为其网络图TensorBoard提供了一个独特的诊断工具。另一方面,所有深度学习框架在GPU上的训练速度几乎相同。这是因为训练内循环在Nvidia
CuDNN包中花费大部分时间。然而,每个框架采用一种不同的方法来描述神经网络,具有两个主要的阵营:使用图形描述文件的阵营,以及通过执行代码来创建它们的描述的阵营。考虑到这一点,让我们来看看每一个框架的特性。Caffe(咖啡)&Caffe深度学习项目,最初是一个强大的图像分类框架,似乎停滞不前,基于它的持续的bug,以及它已被卡住1.0版RC3一年多的事实,并且创始人已离开项目。它仍然有良好的卷积网络图像识别和良好的支持Nvidia CUDA GPU,以及一个简单的网络描述格式。另一方面,它的模型通常需要大量的GPU内存(超过1GB)运行,它的文档是多斑点和问题,支持很难获得,安装是iffy,特别是对于它的Python笔记本支持。Caffe有命令行,Python和Matlab接口,它依靠ProtoText文件来定义它的模型和求解器。 Caffe在其自己的模型模式中逐层定义网络。网络定义从输入数据到丢失的整个模型。当数据和派生数据在前向和后向遍历网络时,Caffe存储,通信和操作信息为blob(二进制大对象),内部是以C连续方式存储的N维数组(表示行该数组被存储在连续的存储器块中,如在C语言中)。 Blob之于Caffe如Tensor之于TensorFlow。图层对blob执行操作,并构成Caffe模型的组件。层卷积滤波器,执行池,取内部乘积,应用非线性(诸如整流线性和S形以及其他元素方面的变换),归一化,加载数据和计算诸如softmax和铰链的损失。Caffe已经证明其在图像分类中的有效性,但它的时刻似乎已经过去了。除非现有的Caffe模型符合您的需要,或者可以根据您的目的进行微调,我建议使用TensorFlow,MXNet或CNTK。在NBViewer中显示的预先计算的CaffeJupyter笔记本。这本笔记本解释了使用一只可爱的小猫在Caffe网络上做“手术”。Microsoft
Cognitive Toolkit(Microsoft认知工具包)Microsoft Cognitive
Toolkit是一个快速,易用的深度学习软件包,但与TensorFlow相比,其范围有限。它有各种各样的模型和算法,极好的支持Python和Jupyter笔记本,一个有趣的声明性神经网络配置语言BrainScript,以及在Windows和Ubuntu Linux环境下自动部署。在缺点方面,当我审查Beta 1的文档还没有完全更新到CNTK 2,并且包没有对MacOS支持。虽然自Beta 1以来,CNTK 2有许多改进,包括新的内存压缩模式,以减少GPU和新的Nuget安装包的内存使用,但对MacOS支持仍然缺失。为Beta 1添加的PythonAPI有助于将认知工具包带入主流的、用Python码的、深度学习研究人员当中。 API包含模型定义和计算、学习算法、数据读取和分布式训练的抽象。作为PythonAPI的补充,CNTK 2具有新的Python示例和教程,以及对
Google Protocol Buffer序列化的支持。教程以Jupyter笔记本实现。CNTK 2组件可以处理来自Python,C
++或BrainScript的多维密集或稀疏数据。认知工具包包括各种各样的神经网络类型:FFN(前馈),CNN(卷积),RNN/
LSTM(递归/长期短期记忆),批次标准化和序列注意序列。它支持强化学习,生成对抗网络,监督和非监督学习,自动超参数调整,以及从Python添加新的,用户定义的核心组件在GPU上运行的能力。它能够在多个GPU和机器上做到精确的并行性,而且(微软声称)它甚至可以适应最大的模型到GPU内存。CNTK 2 API支持从Python,C ++和BrainScript定义网络,学习者,读者,培训和评估。他们还支持使用C#进行评估。 Python API与NumPy互操作,并包括一个高级层级库,可以精确定义包括复现在内的高级神经网络。该工具包支持以符号形式表示循环模型作为神经网络中的循环,而不需要静态展开循环步骤。您可以在Azure网络和GPU上训练CNTK 2模型。配备GPU的N系列Azure虚拟机系列,在我审核Beta 1时受到限制,现在通常可以从Azure控制台获得并完全管理。几个CNTK
2 / Microsoft Cognitive
Toolkit教程以Jupyter笔记本提供。该图显示了Logistic回归训练的绘制的可视化。MXNetMXNet是一个可移植的、可伸缩的深度学习库,是亚马逊的DNN框架的选择,结合了神经网络几何的象征性声明与张量操作的命令性编程。
MXNet可跨多个主机扩展到多个GPU,接近线性扩展效率为85%,具有出色的开发速度、可编程性和可移植性。它支持Python,R,Scala,Julia和C ++,支持程度各不相同,它允许你混合符号和命令式编程风格。在我第一次评论MXNet时,文档感觉还没有完成,除Python之外,我发现很少有其它语言的例子。自从我评论以后,这两种情况都有所改善。MXNet平台是建立在一个动态依赖调度器上的,它可以自动并行化符号和命令式操作,但是你必须告诉MXNet要使用哪些GPU和CPU核心。在调度器顶部的图优化层使符号执行快速和内存高效。MXNet目前支持用Python,R,Scala,Julia和C ++构建和训练模型;训练的MXNet模型也可以用于Matlab和JavaScript中的预测。无论您选择哪种语言来构建模型,MXNet都会调用优化的C ++后端引擎。MXNet作者认为他们的API是Torch、Theano、Chainer和Caffe提供的一个超集,尽管对GPU集群有更多的可移植性和支持。在许多方面MXNet类似于TensorFlow,但增加了嵌入命令张量操作的能力。除了实际强制的MNIST数字分类之外,MXNet教程的计算机视觉包含使用卷积神经网络(CNN)的图像分类和分割,使用更快的R-CNN的对象检测,神经艺术和使用深度CNN的大规模图像分类和ImageNet数据集。还有自然语言处理、语音识别、对抗网络以及监督和非监督机器学习的其他教程。亚马逊测试了在P2.16xlarge实例上的MXNet中实现的Inception
v3算法,发现其伸缩效率为85%。Scikit-learnScikit-learn
Python框架具有广泛的可靠的机器学习算法,但没有深度学习算法。如果你是一个Python粉丝,Scikit-learn可能是一般机器学习库中最佳选择。Scikit-learn是一个强大的,成熟的机器学习Python库,包含各种各样成熟的算法和集成图。它相对容易安装、学习和使用,带有很好的例子和教程。在另一方面,Scikit-learn不包括深度学习或强化学习,缺少图模型和序列预测,并且除Python之外,不能真正使用其它语言。它不支持PyPy,Python即时编译器或GPU。也就是说,除了它的少量进入神经网络,它不会真的有速度问题。它使用Cython(Python到C编译器)来处理需要快速的函数,例如内循环。Scikit-learn对分类、回归、聚类、降维、模型选择和预处理算法具有很好的选择。它有所有这些的良好的文档和示例,但没有任何种类的指导工作流以完成这些任务。Scikit-learn赢得了易于开发的最高分,主要是因为算法都像广告和文档一样工作,API是一致的,设计良好,数据结构之间几乎没有“阻抗不匹配”。函数库其中的功能已彻底充实,错误彻底消除,用来开发十分愉快。本示例使用Scikit-learn的小手写数字数据集来演示使用Label
Spreading模型的半监督学习。在1,797总样本中只有30个被标记。另一方面,函数库没有涵盖深度学习或强化学习,这隐藏了当前困难但重要的问题,例如准确的图像分类和可靠的实时语言解析和翻译。显然,如果你对深度学习感兴趣,你应该另觅他处。然而,存在许多问题,从建立链接不同观察值的预测函数到分类观察值到学习未标记数据集的结构,这使得它们适应于普通的老的机器学习,而不需要数十层的神经元,对于这些领域
Scikit-learn 是非常好的选择。Spark MLlibSpark
MLlib是Spark的开源机器学习库,提供了通用的机器学习算法,如分类、回归、聚类和协同过滤(但不包括DNN)以及特征提取、转换、维数降低工具,以及构建、评估和调整机器学习管道选择和工具。Spark MLlib还包括用于保存和加载算法、模型和管线、用于数据处理以及进行线性代数和统计的实用程序。Spark
MLlib是用Scala编写的,并使用线性代数包Breeze。
Breeze依靠netlib-java来优化数值处理,虽然在开源分布中意味着优化使用CPU。
Databricks提供与GPU配合使用的定制Spark集群,这有可能为您带来另一个10倍的速度改进,用于训练具有大数据的复杂机器学习模型。MLlib实现了大量的分类和回归的常用算法和模型,新手可能变得混乱不堪,无可适从,但专家最终可能会为分析数据找到一个很好的模型的数据。对于这么多的模型Spark2.x增加了超参数调优的重要特性,也称为模型选择。超参数t允许调优分析人员设置参数网格、估计器和评估器,并且它允许交叉验证方法(耗时但准确)或训练验证分割方法(更快但不太准确)找到最佳数据模型。Spark MLlib拥有针对Scala和Java的完整API,主要是针对Python的完整API以及针对R的粗略部分API。您可以通过计算示例来获得良好的覆盖率:54个Java和60个Scala机器学习示例,52个Python机器学习示例,只有五个R示例。在我的经验中,Spark
MLlib是最容易使用Jupyter笔记本,但你可以肯定地在控制台运行它,如果你驯服详细的Spark状态消息。Spark
MLlib提供了你想要的基本机器学习、特性选择、管道和持久性的任何东西。它在分类、回归、聚类和过滤方面做得相当不错。鉴于它是Spark的一部分,它具有访问数据库、流和其他数据源的强大访问权限。另一方面,SparkMLlib并不真正采用与TensorFlow,MXNet,Caffe和Microsoft Cognitive Toolkit相同的方式建模和训练深层神经网络。Spark MLlibPython示例(Naive Bayes)作为Databricks笔记本。注意解释,代码和输出如何散布。TensorFlowTensorFlow,Google的可移植机器学习和神经网络库,执行和伸缩性很好,虽然它有点难学。TensorFlow拥有各种各样的模型和算法,它们对深度学习非常重视,并且在具有GPU(用于训练)或Google TPU(用于生产规模预测)的硬件上具有出色的性能。它还具有对Python的良好支持,良好的文档和良好的软件,用于显示和理解描述其计算的数据流图TensorBoard。数据流图中的节点表示数学运算,而图的边表示在它们之间流动的多维数据数组(张量)。这种灵活的架构允许您将计算部署到桌面、服务器或移动设备中的一个或多个CPU或GPU,而无需重写代码。使用TensorFlow的主要语言是Python,虽然对C
++有限的支持。TensorFlow提供的教程包括手写数字分类。图像识别、字嵌入、递归神经网络,用于机器翻译的序列到序列模型、自然语言处理和基于PDE(偏微分方程)的模拟的应用。TensorFlow可以方便地处理各种神经网络,包括目前正在急剧变化的图像识别和语言处理领域的深度CNN和LSTM递归模型。用于定义图层的代码可能fan,但是您方便但不详细,可以使用三个可选的深度学习界面中的任何一个来修复它。虽然调试异步网络求解器可以是平凡的,但TensorBoard软件可以帮助您可视化图。TensorBoard显示TensorFlow计算的图形。我们放大了几个部分来检查图形的细节。总结对于任何给定的预测任务,您应该使用哪种机器学习或深度学习包取决于机器学习的复杂性,用于训练的数据量和形式,您的计算资源以及您的编程语言偏好和技能。它也可能取决于您是否喜欢使用代码或配置文件定义模型。但是,在开始自己的模型训练考察之前,您可能希望了解来自Google,HPE和MicrosoftAzure云的任何预先训练的应用机器学习服务是否能够处理您的数据,无论是语音、文本或图像。如果他们对你的数据不能很好地工作,你可能还想在尝试基本的机器学习训练(最后,如果没有其他工作)深度学习训练之前,看看你能用简单的统计方法获得多大的好处。这里的原则是保持分析尽可能简单,但不是更简单。在我讨论的两个基本的机器学习包,我建议喜欢Scala和在Hadoop中有他们的数据的使用Spark MLlib 。我建议喜欢Python的人Scikit-learn。我应该提到那些喜欢Scala(和Java)的人和在Hadoop中有他们的数据的人的另一个选择事Deeplearning4j。我没有评论他,但是,因为其名称意味着它是一个学习深度包。选择Caffe,Microsoft Cognitive Toolkit,MXNet和TensorFlow的深度学习包是一个更困难的决定。我不再建议使用Caffe,因为它的发展停滞不前。然而,选择其他三个中的一个仍然是棘手,因为对于具有类似功能,它们都是最好的选择。Cognitive Toolkit现在有Python和C
++
API以及网络配置语言BrainScript。如果您喜欢使用配置文件而不是编程网络拓扑,那么CognitiveToolkit可能是一个不错的选择。另一方面,它似乎不像TensorFlow一样成熟,它不能在MacOS上运行。MXNet支持Python、R、Scala、Julia和C ++,但其支持最好的API是用Python开发的。 MXNet在多个主机上的多个GPU上展示出良好的伸缩性(85%的线性)。当我评论MXNet的文档和示例是吝啬的,但他们已经改进了。TensorFlow可能是三个包中最成熟的,并且它是一个很好的选择,只要你喜欢编写Python,并可以克服学习曲线。
TensorFlow具有你可以使用基本的构建块,它给你细粒度的控制,但也需要你编写大量的代码来描述一个神经网络。有三个简化的API与TensorFlow一起工作来解决这个问题:tf.contrib.learn,TF-Slim和Keras。支持TensorFlow的最终考虑是TensorBoard,它对于可视化和理解您的数据流图非常有用。
MXNet作者认为他们的API是Torch、Theano、Chainer和Caffe提供的一个超集,尽管对GPU集群有更多的可移植性和支持。在许多方面MXNet类似于TensorFlow,但增加了嵌入命令张量操作的能力。
除了实际强制的MNIST数字分类之外,MXNet教程的计算机视觉包含使用卷积神经网络(CNN)的图像分类和分割,使用更快的R-CNN的对象检测,神经艺术和使用深度CNN的大规模图像分类和ImageNet数据集。还有自然语言处理、语音识别、对抗网络以及监督和非监督机器学习的其他教程。
亚马逊测试了在P2.16xlarge实例上的MXNet中实现的Inception v3算法,发现其伸缩效率为85%。
Android Things 专题6 完整的栗子:运用TensorFlow解析图像
文| 谷歌开发技术专家 (GDE) 王玉成 (York Wang)
前面絮叨了这么多,好像还没有一个总体的概念,我们如何写一个完整的代码呢?
现在深度学习很火,那我们就在Android Things中,利用摄像头抓拍图片,让 TensorFlow 去识别图像,最后用扬声器告诉我们结果。
是不是很酷?说基本的功能就说了这么长一串,那垒代码得垒多久啊?
项目结构
我们就从 Android Studio 的环始境开始说起吧。
启动 Android Studio 之后,务必把 SDK Tools 的版本升级到 24 及以上。然后再把 SDK 升级到 Android 7.0 及以上。让 Android Studio 自己完成相关组件的更新,导入项目,项目的结构如下:
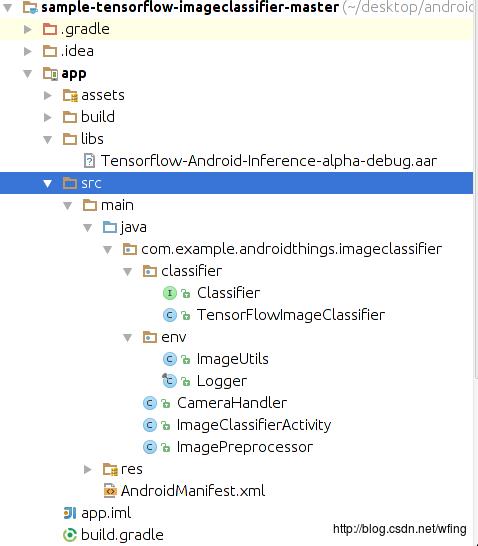
代码中的 imageclassifier 是用于跟 TensorFlow 做交互的,还有摄头,图片处理的相关 handler。
我们再来看看外部的引用库:
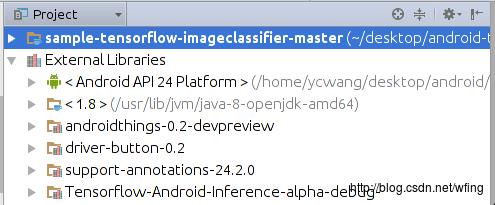
包括了 Android Things 和 TensorFlow 的相关库,当然,Android 的 API 的版本是24。gradle 的依赖和 Manifest 中的 filer 是和之前搭建开发环境的讲解一致的。
引用的 TensorFlow 的库是 aar 打包的 Tensorflow-Android-Inference-alpha-debug.aar,这就意味着,我们不需要 NDK 环境就能够编译整个项目了。
主要是留意 dependencies 这一项,包括了 TensorFlow 的库和 Android thing 的库:
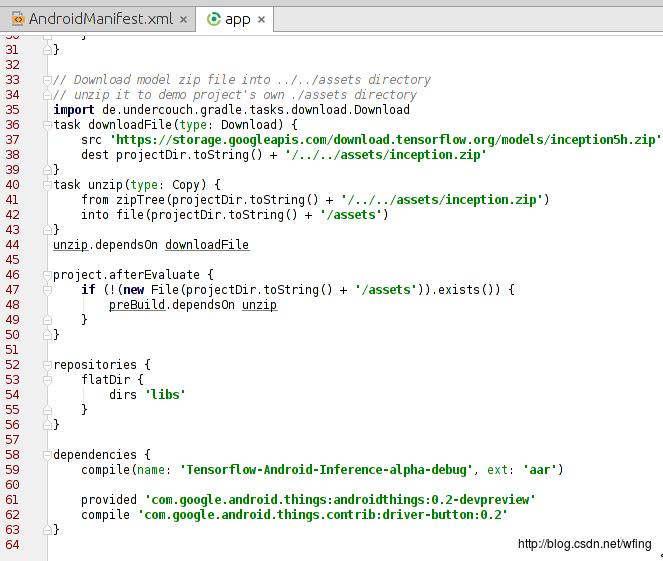
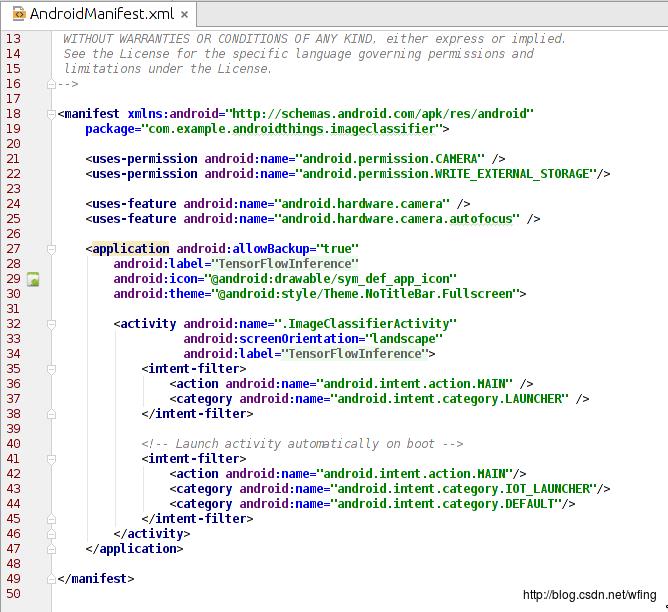
再申请了摄头相关的权限。补充一下,Android Things 是不支持动态权限的申请的。
硬件连接
接下来便是硬件如何连接了。
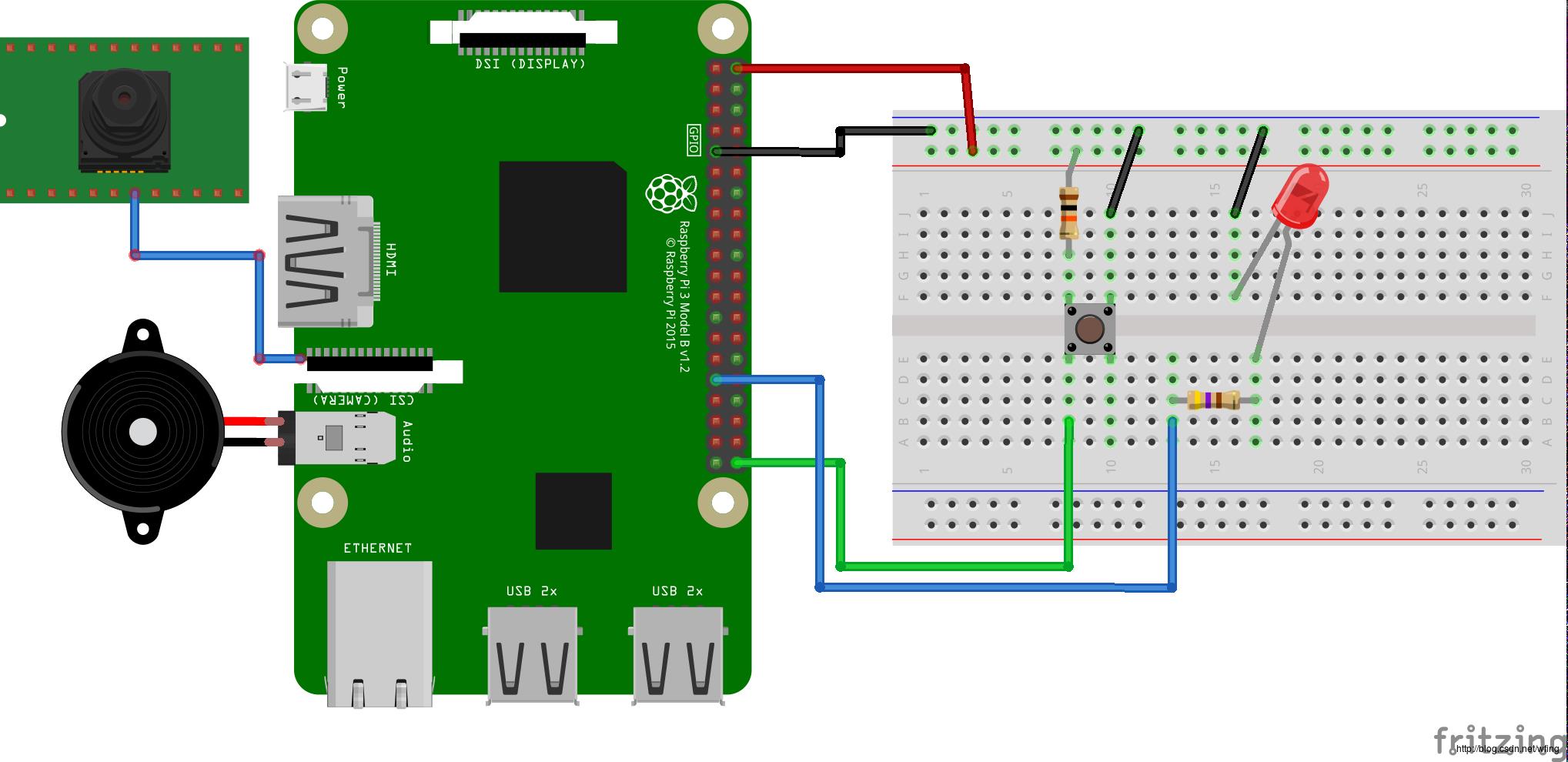
硬件清单如下:
Android Things 兼容的开发板,比如 Raspberry Pi 3
Android Things 兼容的摄像头,比如 Raspberry Pi 3 摄头模块
元器件:
1 个按钮,见面包板
2 个电阻,这块儿必须要说明一下:由于图片是接的 5V 的电压,一般来说 GPIO 和 led 的承压能力是 3V,有些 GPIO 是兼容 5V 的,所以中间需要串联 100~200 欧的电阻。当然,为了保险,建议用 3.3V 的电压。
1 个LED灯
1 个面包板
杜邦线若干
可选:扬声器或者耳机
可选:HDMI输出
连完了硬件,我们这时候就要理解操作流程了。
操作流程
按照前面讲解的内容,用 Andorid Studio,连接 ADB,配置好开发板的 Wi-Fi,然后把应用加载到开发板上。
操作流程如下:
重启设备,运行程序,直到 LED 灯开始闪烁;
把镜头对准猫啊,狗啊,或者一些家具;
按下开关,开始拍摄图片;
在 Raspberry Pi 3 中,一般在 1s 之内,可以完成图片抓拍,经 Tensorflow 处理,然后再通过 TTS 放出声音。在运行的过程中 LED 灯是熄灭的;
Logcat 中会打印出最终的结果,如果是有显示设备连接的话,图片和结果都会显示出来;
如果有扬声器或者是耳机的话,会把结果语音播报出来。
由于代码的结构特别简单,注意一下几段关健的操作即可。想必图形、摄头的操作在Android 的编程中大家都会了,所以不做讲解了。
代码流程
主要是看 LED 的初始化操作:
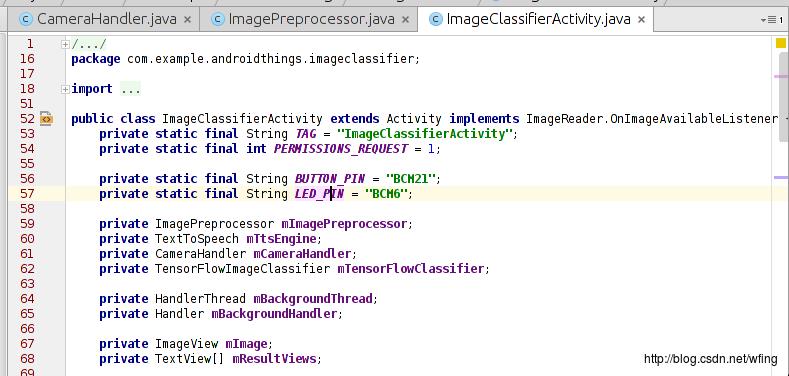
有必要说一下,ImageClassifierActivity.java 是应用唯一的 Activity 的入口。在 Manifest 中已经有定义,它初始化了 LED, Camera, TensorfFlow 等组件。其中,我们用到的 Button 是 BCM32 这个管脚,用到的 LED 是 BCM6 管脚,相关的初始化在这个 Activity 中已经完成。
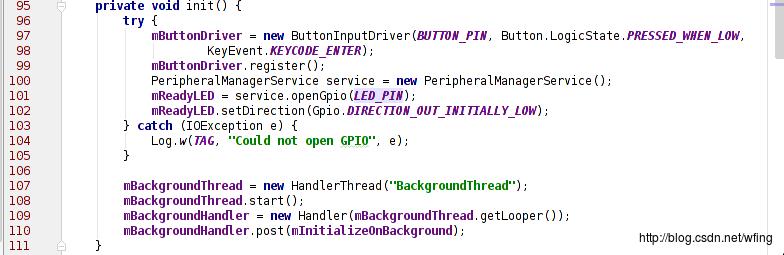
这部分代码是捕捉按键按下的代码。当按下按键时,摄头开始捕捉数据。
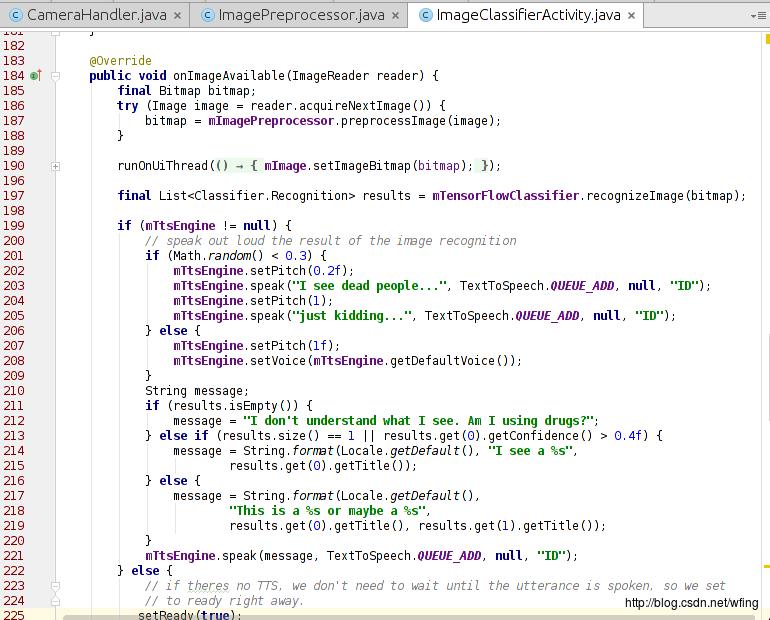
把摄像头拍摄的数据转成 Bitmap 文件之后,我们会调用 TensorFlow 来处理图像。
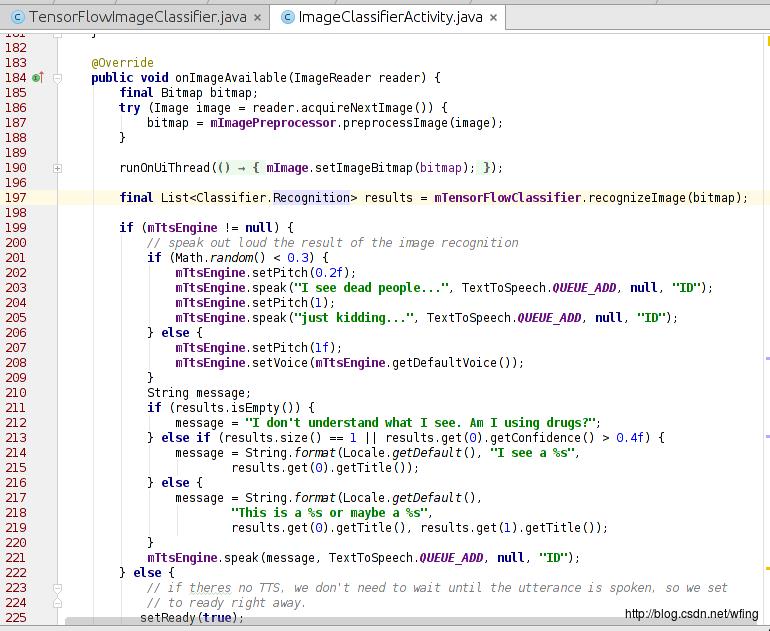
这个函数调用了 TensorFlow 进行处理,最后把结果输出到 logcat 中。如果代码中调用了 tts 引擎,那么则把结果转成语音读出来。看来,最重要的就是 TensorFlowClassifie 类的 recognizeImage() 这个接口了。我们继续往下看。
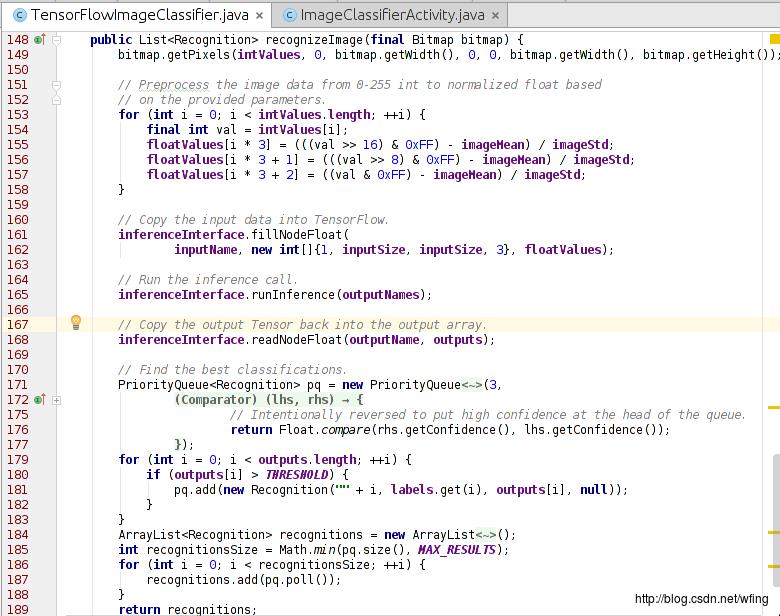
这是最后的一步,调用 TensorFlow 进行图像识别:
把 RGB 图像转成 TensorFlow 能够识别的数据;
把数据拷到 TensorFlow 中;
识别出图像,给出结果。
调用 TensorFlow 的过程还是挺好玩的,也挺方便。那么,为啥 TensorFlow 一下子就能够识别出是什么图片呢?Tensorflow 的官网给出的解答:
www.tensorflow.org/tutorials/image_recognition
有一点需要提示,TensorFlow 的图像识别分类可以用网络提交到服务器识别,也可以离线的数据识别。可以先把 200M 左右的识别数据放在本地,然后提交后识别。现在大概能分出 1000 个类别的图像,哪 1000 个类别呢?项目代码中已经包含了哦。
是不是运用 TensorFlow 来处理物联网的数据会特别简单,不光是 TensorFlow, Firebase 也可以用到 Android Things 中来。这功能,强大的没话说了!
今天提到的这个项目,来源于 Google 在 GitHub 上维护的项目,项目的地址是
github.com/androidthings/sample-tensorflow-imageclassifier
当然,GitHub 上还有很多 Android Things 的代码可以参考。
是不是迫不急待的自己写一个应用呢?实际上,这个项目稍加改动便能有新的玩法。例如加上一个红外感应器,一旦有生物在附近就马上拍图片,并且识别。
大开你的脑洞吧
后记
这一篇文章是这个专题的最后一篇了。写完整个专题,发现 Android Things 带给开发者太多太多的便利,如何烧写文件?如何运用 SDK?甚至如何用 Google 的其它服务做物联网相关的数据处理?都有太多太多的现成的方案供我们选择,感叹使用 Android Things 进行物联网应用开发实在太方便了!
您如果有任何涉及到 Android Things 方面的想法,都欢迎大家在下方留言,我们会把好的建议转交给 Android Things 的产品部门。也许在某一天,你的建议就是 Andorid Things 的一部分。
以上是关于现在tensorflow和mxnet很火,是不是还有必要学习scikit-learn等框架的主要内容,如果未能解决你的问题,请参考以下文章
Android Things 专题6 完整的栗子:运用TensorFlow解析图像
开源项目 TensorFlow,PyTorch,MXNet,CNTK 和 Caffe2
深度学习框架哪家强?MXNet称霸CNNRNN和情感分析,TensorFlow仅擅长推断特征提取
Android Things 专题6 完整的栗子:运用TensorFlow解析图像