Java Review (二十集合----- Set 集合)
Posted 三分恶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java Review (二十集合----- Set 集合)相关的知识,希望对你有一定的参考价值。
@
Set 集合,它类似于一个罐子 , 程序可以依次把多个对象"丢进" Set 集合,而 Set集合通常不能记住元素的添加顺序 。 Set 集合与 Collection 基本相同,没有提供任何额外的方法。实际上 Set 就是 Collection , 只是行为略有不同( Set不允许包含重复元素) 。
HashSet 类
散列表(hashtable )是一种可以快速地査找所需要的对象的数据结构, 散列表为每个对象计算一个整数, 称为散列码(hashcode)。 散列码是由对象的实例域产生的一个整数。更准确地说, 具有不同数据域的对象将产生不同的散列码。
HashSet是 Set 接口的典型实现 ,大多数时候使用 Set 集合时就是使用这个实现类。 HashSet 按 Hash算法来存储集合中 的元素,因此具有很好的存取和查找性能。
?HashSet 具有以下特点 :
- 不能保证元素的排列顺序,顺序可能与添加顺序不同,顺序也有可能发生变化 。
- HashSet 不是同步的,如果多个线程同时访问 一个 HashSet,假设有两个或者两个以上线程同时修改了 HashSet 集合时,则必须通过代码来保证其同步。
- 集合元素值可以是 null 。
元素比较
当向 HashSet 集合中存入一个元素时, HashSet 会调用该对象的 hashCode()方法来得到该对象的hashCode 值,然后根据该 hashCode 值决定该对象在 HashSet 中的存储位置。如果有两个元素通过 equals()方法比较返回 true,但它们的 hashCode()方法返回值不相等, HashSet 将会把它们存储在不同的位置,
依然可以添加成功。
HashSet 集合判断两个元素相等的标准是两个对象通过 equals()方法比较相等,并且两个对象的 hashCode()方法返回值也相等。
下面程序分别提供了 三个类 A 、 B 和 C ,它们分别重写了 equals()、 hashCode()两个方法的一个或全部,通过此程序可以了解HashSet 判断集合元素相同的标准 :
// 类A的equals方法总是返回true,但没有重写其hashCode()方法
class A
{
public boolean equals(Object obj)
{
return true;
}
}
// 类B的hashCode()方法总是返回1,但没有重写其equals()方法
class B
{
public int hashCode()
{
return 1;
}
}
// 类C的hashCode()方法总是返回2,且重写其equals()方法总是返回true
class C
{
public int hashCode()
{
return 2;
}
public boolean equals(Object obj)
{
return true;
}
}
public class HashSetTest
{
public static void main(String[] args)
{
HashSet books = new HashSet();
// 分别向books集合中添加两个A对象,两个B对象,两个C对象
books.add(new A());
books.add(new A());
books.add(new B());
books.add(new B());
books.add(new C());
books.add(new C());
System.out.println(books);
}
}
运行结果:
 即使两个 A 对象通过 equals()方法 比较返回 true ,但 HashSet 依然把它们当成两个对象:即使两个 B 对象的 hashCode()返回相 同值〈都是1), 但 HashSet 依然把它们 当成两个对象 。
即使两个 A 对象通过 equals()方法 比较返回 true ,但 HashSet 依然把它们当成两个对象:即使两个 B 对象的 hashCode()返回相 同值〈都是1), 但 HashSet 依然把它们 当成两个对象 。
当把一个对象放入 HashSet 中时 ,如果需要重写该对象对应类的 equalsO方法 ,则也应该重写其 hashCode()方法 。 规则是 :如果两个对象通过 equals()方法比较返回 true , 这两个对象的 hashCode 值也应该相同 。
散列表用链表数组实现。每个列表被称为桶( bucket) (参看图二) 要想査找表中对象的位置, 就要先计算它的散列码, 然后与桶的总数取余, 所得到的结果就是保存这个元素的桶的索引。
例如, 如果某个对象的散列码为 76268, 并且有 128 个桶, 对象应该保存在第 108 号桶中(76268除以 128余 108 )。或许会很幸运, 在这个桶中没有
其他元素,此时将元素直接插人到桶中就可以了。
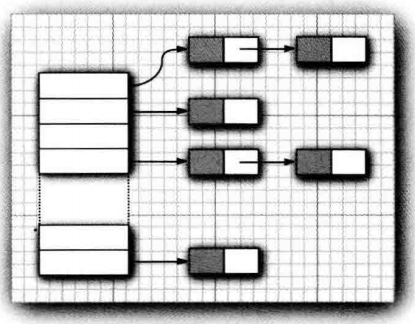
有时候会遇到桶被占满的情况, 这也是不可避免的。这种现象被称为散列冲突( hash collision) 。 这时, 需要用新对象与桶中的所有对象进行比较,査看这个对象是否已经存在。如果散列码是合理且随机分布的, 桶的数目也足够大, 需要比较的次数就会很少。
当向 HashSet 中添加可变对象时,必须十分小心 。 如果修改 HashSet 集合中 的对象,有可能导致该对象与 集合中的其他对象相等,从而导致 HashSet 无法准确访问该对象 。
LinkedHashSet 类
HashSet还有一个子类 LinkedHashSet , LinkedHashSet 集合也是根据元素的 hashCode 值来决定元素的存储位置 , 但它同时使用链表维护元素的次序 ,这样使得元素看起来是以插入的顺序保存的 。 也就是说 , 当遍历 LinkedHashSet 集合里的元素时, LinkedHashSet 将会按元素的添加顺序来访问集合里的元素。
LinkedHashSet 需要维护元素 的插入顺序,因此性能略低于 HashSet 的性能,但在迭代访问 Set 里的全部元素时将有很好的性能,因为它以链表来维护内部顺序 。
public class LinkedHashSetTest
{
public static void main(String[] args)
{
LinkedHashSet books = new LinkedHashSet();
books.add("疯狂Java讲义");
books.add("轻量级Java EE企业应用实战");
System.out.println(books);
// 删除 疯狂Java讲义
books.remove("疯狂Java讲义");
// 重新添加 疯狂Java讲义
books.add("疯狂Java讲义");
System.out.println(books);
}
}
虽然 LinkedHashSet 使用了链表记录集合元素的添加顺序,但 LinkedHashSet 依然是HashSet ,因此它依然不九许集合元素重复 。
TreeSet 类

TreeSet 是 SortedSet 接口的实现类,正如 SortedSet 名字所暗示的, TreeSet 可以确保集合元素处于排序状态。与 HashSet 集合相比, TreeSet 还提供了如下几个额外的方法 :
- Comparator comparator(): 如 果 TreeSet 采用了定制排序,则该方法返回定制排序所使用的Comparator; 如 果 TreeSet 采用了自然排序,则返回 null 。
- Object ftrst(): 返回集合中的第一个元素。
- Object last(): 返回集合中的最后一个元素 。
- Object lower(Object e): 返回集合中位于指定元素之前的元素( 即小于指定元素的最大元素 ,参考元素不需要是 TreeSet 集合里的元素)。
- Object higher (Object e): 返回集合中位于指定元素之后的元素(即大于指定元素的最小元素,参考元素不需要是 TreeSet 集合里的元素) 。
- SortedSet subSet(Object fromElement, Object toElement): 返回此 Set 的子集合,范围从 fromElement(包含〉到 toElement (不包含)。
- SortedSet headSet(Object toElement): 返回此 Set 的子集 ,由小于toElement 的元素组成 。
- SortedSet tailSet(Object 仕omElement): 返回此Set 的子集 , 由大于或等于企omElement 的元素组成 。
下面程序测试了 TreeSet 的通用用法:
public class TreeSetTest
{
public static void main(String[] args)
{
TreeSet nums = new TreeSet();
// 向TreeSet中添加四个Integer对象
nums.add(5);
nums.add(2);
nums.add(10);
nums.add(-9);
// 输出集合元素,看到集合元素已经处于排序状态
System.out.println(nums);
// 输出集合里的第一个元素
System.out.println(nums.first()); // 输出-9
// 输出集合里的最后一个元素
System.out.println(nums.last()); // 输出10
// 返回小于4的子集,不包含4
System.out.println(nums.headSet(4)); // 输出[-9, 2]
// 返回大于5的子集,如果Set中包含5,子集中还包含5
System.out.println(nums.tailSet(5)); // 输出 [5, 10]
// 返回大于等于-3,小于4的子集。
System.out.println(nums.subSet(-3 , 4)); // 输出[2]
}
}
运行结果:

与 HashSet 集合采用 hash 算法来决定元素 的存储位置不同, TreeSet 采用红黑树的数据结构来存储集合元素。TreeSet 支持两种排序方法 : 自然排序和定制排序。在默认情况下, TreeSet 采用自然排序。
要使用树集, 必须能够比较元素。这些元素必须实现 Comparable 接口, 或者构造集时必须提供一个 Comparator 。
自然排序
TreeSet 会调用集合元素的 compareTo(Object obj)方法来比较元素之间的大小关系,然后将集合元素按升序排列,这种方式就是自然排序 。
Java 提供了 一个 Comparable 接口,该接口里定义了一个 compareTo(Object obj )方法,该方法返回一个整数值,实现该接口的类必须实现该方法 , 实现了 该接口的类的对象就可以比较大小。当一个对象调用该方法与另一个对象进行 比较时,例如 obj 1.compareTo(obj2) ,如果该方法返回 0 ,则表明这两个对象
相等 :如果该方法返回一个正整数, 则表明 objl 大于 obj2; 如果该方法返回一个负整数, 则表明 objl小于 obj2 。
Java 的 一些常用类已经实现了 Comparable 接口,并提供了比较大小的标准。
?下面是实现了Comparable 接口的常用类:
- BigDecimal 、 BigInteger 以及所有的数值型对应的包装类 : 按它们对应的数值大小进行比较。
- Character: 按字符的 UNICODE 值进行比较。
- Boolean: true 对应的包装类实例大于 false 对应的包装类实例。
- String: 按字符串中字符的UNICODE 值进行 比较。
- Date 、 Time: 后面的时间、日期比前面的时间、日期大。
如果试图把一个对象添加到 TreeSet 时,则该对象的类必须实现 Comparable 接口,否则程序将会抛出异常。如下程序示范了这个错误:
class Err{}
public class TreeSetErrorTest
{
public static void main(String[] args)
{
TreeSet ts = new TreeSet();
// 向TreeSet集合中添加Err对象
// 自然排序时,Err没实现Comparable接口将会引发错误
ts.add(new Err());
}
}
向 TreeSet 中添加的应该是同一个类的对象,否则也会引发ClassCastException 异常,因为大部分类在实现 compareTo(Object obj)方法时,都需要将被比较对象 obj 强制类型转换成相同类型。
如下程序示范了这个错误 :
public class TreeSetErrorTest2
{
public static void main(String[] args)
{
TreeSet ts = new TreeSet();
// 向TreeSet集合中添加两个对象
ts.add(new String("疯狂Java讲义"));
ts.add(new Date()); // ①
}
}
当把一个对象加入 TreeSet 集合中时, TreeSet 调用该对象的compareTo(Object obj)方法与容器中的其他对象比较大小,然后根据红黑树结构找到它的存储位置 。 如果两个对象通过 compareTo(Object obj)方法比较相等,新对象将无法添加到 TreeSet 集合中 。
class Z implements Comparable
{
int age;
public Z(int age)
{
this.age = age;
}
// 重写equals()方法,总是返回true
public boolean equals(Object obj)
{
return true;
}
// 重写了compareTo(Object obj)方法,总是返回1
public int compareTo(Object obj)
{
return 1;
}
}
public class TreeSetTest2
{
public static void main(String[] args)
{
TreeSet set = new TreeSet();
Z z1 = new Z(6);
set.add(z1);
// 第二次添加同一个对象,输出true,表明添加成功
System.out.println(set.add(z1)); //①
// 下面输出set集合,将看到有两个元素
System.out.println(set);
// 修改set集合的第一个元素的age变量
((Z)(set.first())).age = 9;
// 输出set集合的最后一个元素的age变量,将看到也变成了9
System.out.println(((Z)(set.last())).age);
}
}
运行结果:

程序中①代码行把同 一个对象再次添加到 TreeSet 集合中,因为 zl 对象的
ompareTo(Object obj)方法总是返回 1, 虽然它的 equalsO方法总是返回 true ,但 TreeSet会认为 z1对 象和它自己也不相等,因此TreeSet 可以添加两个 z1 对 象。
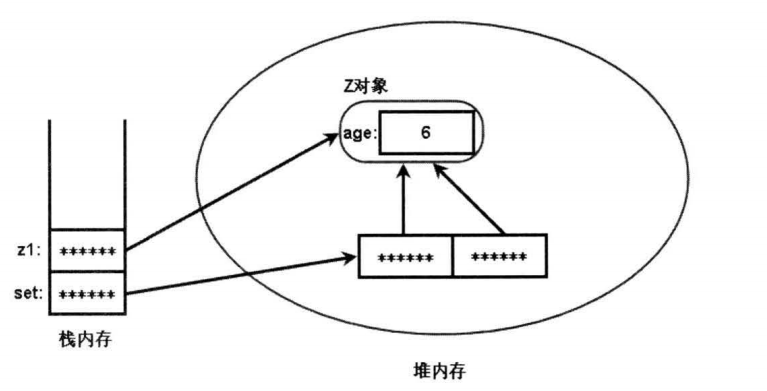
由此应该注意一个问题 : 当需要把一个对象放入 TreeSet中, 重写该对象对应类的 equals()方法时,应保证该方法与 compareTo(Object obj)方法有一致的结果,其规则 是 : 如果两个对象通过 equals()方法比较返回 true 时,这两个对象通过 compareTo(Object obj)方法比较应返回 0 。
定制排序
TreeSet 的自 然排序是根据集合元素 的大小, TreeSet 将它们以升序排列 。 如果需要实现定制排序,例如以降序排列, 则可以通过 Comparator 接口 的帮助 。该接口里包含一个 int compare(T 01 , T 02)方法,该方法用于比较 01 和 02 的大小:如果该方法返 回正整数 ,则表明 01 大于 02; 如果该方法返回 0 ,则表明 01 等于 02; 如果该方法返回负整数, 则表 明 01 小于 02 。
如果需要实现定制排序,则需要在创建 TreeSet 集合对象时,提供一个Comparator 对象与该TreeSet集合关联 , 由该 Comparator 对象负责集合元素 的排序逻辑。由于 Comparator 是一个函数式接口,因此可使用 Lambda 表达式来代替 Comparator 对象 。
class M
{
int age;
public M(int age)
{
this.age = age;
}
public String toString()
{
return "M [age:" + age + "]";
}
}
public class TreeSetTest4
{
public static void main(String[] args)
{
// 此处Lambda表达式的目标类型是Comparator
TreeSet ts = new TreeSet((o1 , o2) ->
{
M m1 = (M)o1;
M m2 = (M)o2;
// 根据M对象的age属性来决定大小,age越大,M对象反而越小
return m1.age > m2.age ? -1
: m1.age < m2.age ? 1 : 0;
});
ts.add(new M(5));
ts.add(new M(-3));
ts.add(new M(9));
System.out.println(ts);
}
}
运行结果:

EnumSet 类
EnumSet 是一个专为枚举类设计的集合类, EnumSet 中的所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建 EnumSet 时显式或隐式地指定。
EnumSet 的集合元素也是有序的, EnumSet 以枚举值在 Enum 类内的定义顺序来决定集合元素的顺序。
EnumSet 在内部以位向 量 的形式存储,这种存储形式非常紧凑 、 高效 ,因此 EnumSet 对象占用内存很小,而且运行效率很好。尤其是进行批量操作(如调用 containsAll() 和 retainAll()方法〉时,如果其参数也是 EnumSet 集合,则该批量操作的执行速度也非常快。
EnumSet 集合不允许加入 null 元素,如果试图插入 null 元素, EnumSet 将抛出 NullPointerException异常。如果只是想判断 EnumSet 是否包含 null 元素或试图删除 null 元素都不会抛出异常,只是删除操作将返回 false,因为没有任何 null 元素被删除。
EnumSet 类没有暴露任何构造器来创建该类的实例,程序应该通过它提供的类方法来创建 EnumSet对象 。 EnumSet 类它提供了如下常用的类方法来创建 EnumSet 对象 :
- EnumSet allOf(Class elementType): 创建一个包含指定枚举类里所有枚举值的 EnumSet 集合 。
- EnumSet complementOf(EnumSet s): 创建一个其元素类型与指定 EnumSet 里元素类型相同的
*EnumSet 集合,新 EnumSet 集合包含原 EnumSet 集合所不包含的 、此枚举类剩下的枚举值(即新EnumSet 集合和原 EnumSet 集合的集合元素加起来就是该枚举类的所有枚举值)。 - EnumSet copyOf(Collection c): 使用 一个普通集合来创建 EnumSet 集合 。
- EnumSet copyOf(EnumSet s): 创建一个与指定 EnumSet 具有相同元素类型、相同集合元素的EnumSet 集合 。
- EnumSet noneOf(Class elementType): 创建一个元素类型为指定枚举类型的空 EnumSet 。
- EnumSet of(E first, E... rest): 创建一个包含一个或多个枚举值 的 EnumSet 集合,传入的多个枚举值必须属于同一个枚举类。
- EnumSet range(E from, E to): 创建一个包含从 from 枚举值到 to 枚举值范围内所有枚举值的EnumSet集合。
下面程序示范了 如何使用 EnumSet来保存枚举类的多个枚举值 :
enum Season
{
SPRING,SUMMER,FALL,WINTER
}
public class EnumSetTest
{
public static void main(String[] args)
{
// 创建一个EnumSet集合,集合元素就是Season枚举类的全部枚举值
EnumSet es1 = EnumSet.allOf(Season.class);
System.out.println(es1); // 输出[SPRING,SUMMER,FALL,WINTER]
// 创建一个EnumSet空集合,指定其集合元素是Season类的枚举值。
EnumSet es2 = EnumSet.noneOf(Season.class);
System.out.println(es2); // 输出[]
// 手动添加两个元素
es2.add(Season.WINTER);
es2.add(Season.SPRING);
System.out.println(es2); // 输出[SPRING,WINTER]
// 以指定枚举值创建EnumSet集合
EnumSet es3 = EnumSet.of(Season.SUMMER , Season.WINTER);
System.out.println(es3); // 输出[SUMMER,WINTER]
EnumSet es4 = EnumSet.range(Season.SUMMER , Season.WINTER);
System.out.println(es4); // 输出[SUMMER,FALL,WINTER]
// 新创建的EnumSet集合的元素和es4集合的元素有相同类型,
// es5的集合元素 + es4集合元素 = Season枚举类的全部枚举值
EnumSet es5 = EnumSet.complementOf(es4);
System.out.println(es5); // 输出[SPRING]
}
}
各 Set 实现类的性能分析
HashSet 和 TreeSet 是 Set 的两个典型实现 , 到底如何选择 HashSet 和 TreeSet 呢?
HashSet 的性能总是 比 TreeSet 好(特别是最常用的添加 、 查询元素等操作) , 因为 TreeSet 需要额外的红黑树算法来维护集合元素的次序 。 只有当需要一个保持排序 的 Set 时,才应该使用 TreeSet,否则都应该使用 HashSet 。
HashSet 还有一个子类 : LinkedHashSet , 对于普通的插入、删除操作 , LinkedHashSet 比 HashSet要略微慢一点 , 这是由维护链表所带来的额外开销造成的 , 但由于有了链表,遍历 LinkedHashSet 会更快 。
EnumSet 是所有 Set 实现类中性能最好的,但它只能保存同一个枚举类的枚举值作为集合元素。
必须指出的是, Set 的三个实现类 HashSet 、 TreeSet 和 EnumSet 都是线程不安全的 。如果有多个线程同时访问 一个 Set 集合,并且有超过一个线程修改了该 Set 集合 ,则必须手动保证该Set 集合的同步性。通常可以通过 Collections 工具类的 syncbronizedSortedSet 方法来 "包装"该 Set 集合。 此操作最
好在创建时进行 , 以防止对 Set 集合的意外非同步访问 。
SortedSet s = Collections.synchronizedSortedSet(new TreeSet(.. .));
参考:
【1】:《疯狂Java讲义》
【2】:《Java核心技术 卷一》
【3】:廖雪峰的官方网站:使用Set
以上是关于Java Review (二十集合----- Set 集合)的主要内容,如果未能解决你的问题,请参考以下文章