c++模板类的知识,为啥下面程序要用结构体,把T data写在类里面不可以吗?看到好多地方这样写
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了c++模板类的知识,为啥下面程序要用结构体,把T data写在类里面不可以吗?看到好多地方这样写相关的知识,希望对你有一定的参考价值。
template <class T>
struct Node
T data;
Node<T>* next;
;
template <class T>
class LinkList
public:
LinkList();
LinkList(T a[],int n);
~LinkList();
int Locate(T x);
void Insert(int i,T x);
T Delete(int i);
void PrintList();
public:
Node<T>* first;
;
可能我表达不清楚,我想问的是为什么不把struct结构体去掉,然后把里面的改成T data, LinkList<T>* next;放到下面 类LinkList里面去
template <class T>
class Node
public:
T data;
Node<T>* next;
;
而本身使用class的原因,就是为了封装保护数据,尽少可能的将成员数据直接暴露出来,如果完全按照面向对象原则来写的话,又会变成
template <class T>
class Node
private:
T data;
Node<T>* next;
public:
T getData();
void setData(T data);
Node<T>* getNext();
void setNext(Node<T>* next);
;
而使用struct就不需要这么麻烦,所以在这里使用struct而不使用class,更多的是出于一种习惯追问
可能我表达不清楚,我想问的是为什么不把struct结构体去掉,然后把里面的改成T data, LinkList* next;放到下面 类LinkList里面去
参考技术A 因为你这是链表。 链表的每个结点都是一个结构体就像你写的那样。 也可以写在类里面但是你的作用域就多了一个类比如你再类里面定义链表。 你要处理结点的内容的话 链表的函数的定义时 前面的作用域就要多写一层类 以表示它是属于这个类里面的成员。 否则报错。 参考技术B 看起来是可以写在类里啊。。。你 写在类里编译下试试,看出错么。C++ 类和对象上
什么是面向对象,什么是面向过程
C语言是面向过程的,关注的是过程,分析出求解问题的步骤,通过函数调用逐步解决问题面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了。
C++是基于面向对象的,关注的是对象,将一件事情拆分成不同的对象,靠对象之间的交互完成面向对象是把构成问题事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个事物在整个解决问题的步骤中的行为。
封装:
- 把变量(属性)和函数(操作)合成一个整体,封装在一个类中
- 对变量和函数进行访问控制
目的:封装的目的是为了保证变量的安全性,使用者不必在意具体实现细节,而只是通过外部接口即可访问类的成员
类的引入
C语言中,结构体中只能定义变量,在C++中,结构体内不仅可以定义变量,也可以定义函数。
struct Student
{
void SetStudentInfo(const char* name, const char* gender, int age)
{
strcpy(_name, name);
strcpy(_gender, gender);
_age = age;
}
void PrintStudentInfo()
{
cout << _name << " " << _gender << " " << _age << endl;
}
char _name[20];
char _gender[3];
int _age;
};
void test01()
{
Student m1;
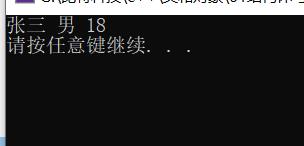
m1.SetStudentInfo("张三", "男", 18);
m1.PrintStudentInfo();
}
类的引入
class className
{
// 类体:由成员函数和成员变量组成
}; // 一定要注意后面的分号
class为定义类的关键字,ClassName为类的名字,{}中为类的主体,注意类定义结束时后面分号。类中的元素称为类的成员:类中的数据称为类的属性或者成员变量; 类中的函数称为类的方法或者成员函数。
类的权限问题
- 在类的内部(作用域范围内),没有访问权限之分,所有成员可以相互访问
- 在类的外部(作用域范围外),访问权限才有意义:public,private,protected
- 在类的外部,只有public修饰的成员才能被访问,在没有涉及继承与派生时,
| 访问属性 | 属性 | 内部属性 | 外部属性 |
|---|---|---|---|
| public | 公有 | 可访问 | 可访问 |
| protected | 保护 | 可访问 | 不可访问 |
| private | 私有 | 可访问 | 不可访问 |
类定义的两种方式
1.类内声明,类外定义(一般推荐使用)
class person
{
public:
void setperson(const char* name, int age);
void print();
private:
char _name[15];
int _age;
};
void person::setperson(const char* name, int age)//::为作用域限定符
{
strcpy(_name, name);
_age = age;
}
void person::print()
{
cout << "name:" << _name << endl;
cout << "age:" << _age << endl;
}
2.类内定义
class person
{
public:
void setperson(const char* name, int age)
{
strcpy(_name, name);
_age = age;
}
void print()
{
cout << "name:" << _name << endl;
cout << "age:" << _age << endl;
}
private:
char _name[15];
int _age;
};
类的访问限定符及封装
访问限定符的说明
- public修饰的成员在类外可以直接被访问
- protected和private修饰的成员在类外不能直接被访问(此处protected和private是类似的)
- 访问权限作用域从该访问限定符出现的位置开始直到下一个访问限定符出现时为止
- class的默认访问权限为private,struct为public(因为struct要兼容C)
C++中struct 和class区别是什么?
本题我会给出相对我自己的理解,或许对于刚入手C++的不是很友好,就挑自己会的记。
变量的默认方式不同
1.struct 默认变量的属性为公有的
struct student
{
void set(const char* name1, int age1);
void print();
int age;
char name[15];
};
void student::set(const char* name1, int age1)
{
strcpy(name, name1);
age = age1;
}
void student::print()
{
cout << "name" << name << endl;
cout << "age" << age << endl;
}
void test01()
{
student m1;
m1.set("张三", 18);
m1.print();
cout << "姓名" << m1.name << endl;
cout << "年龄" << m1.age << endl;
}
运行截图

2.class 默认属性为私有的
class student
{
void set(const char* name1, int age1);
void print();
char name[15];
int age;
};
void student::set(const char* name1, int age1)
{
strcpy(name, name1);
age = age1;
}
void student::print()
{
cout << "name" << name << endl;
cout << "age" << age << endl;
}
void test01()
{
student m1;
m1.set("张三", 18);
m1.print();
}
我们跑一下这个程序,看下结果

可以得出结论,类默认属性是私有的。
默认的继承方式不同
结构体的默认继承方式为公有继承
struct Student
{
void SetStudentInfo(const char* name, const char* gender, int age)
{
strcpy(_name, name);
strcpy(_gender, gender);
_age = age;
}
void PrintStudentInfo()
{
cout << _name << " " << _gender << " " << _age << endl;
}
char _name[20];
char _gender[3];
int _age;
};
struct person :Student//给一个默认的继承方式
{
void set(int high1);
void print();
int high;
};
void person::set(int high1)
{
high = high1;
}
void person::print()
{
cout << "姓名" << _name << endl;
cout << "性别" << _gender << endl;
cout << "年龄" << _age << endl;
cout << "身高" << high << endl;
}
void test01()
{
person m2;//这里我们设置m2,
//我们用可以用子类对象对调用父类的函数,说明为公有继承
m2.SetStudentInfo("张三", "男", 20);
m2.set(180);
m2.print();
}

类的默认继承为私有继承(当子类的对象为私有情况下,公有的依旧在子类中是公有的)
class student
{
void set(const char* name1, int age1);
void print();
char name[15];
int age;
};
void student::set(const char* name1, int age1)
{
strcpy(name, name1);
age = age1;
}
void student::print()
{
cout << "name" << name << endl;
cout << "age" << age << endl;
}
class person :student
{
void set1(int high1);
int high;
};
void student::set1(int high1)
{
high = high1;
}
void test01()
{
person m1;
m1.set("张三", "男", 20);
m1.set1(180);//我们使用子类的对象去调用父类的对象,发现错误
m1.print();
}

class中可以使用模板
不做解释,记住即可。
了解封装
封装:将数据和操作数据的方法进行有机结合,隐藏对象的属性和实现细节,仅对外公开接口来和对象进行交互。
封装本质上是一种管理:我们如何管理兵马俑呢?比如如果什么都不管,兵马俑就被随意破坏了。那么我们首先建了一座房子把兵马俑给封装起来。但是我们目的全封装起来,不让别人看。所以我们开放了售票通道,可以买票突破封装在合理的监管机制下进去参观。类也是一样,我们使用类数据和方法都封装到一下。不想给别人看到的,我们使用protected/private把成员封装起来。开放一些共有的成员函数对成员合理的访问。所以封装本质是一种管理
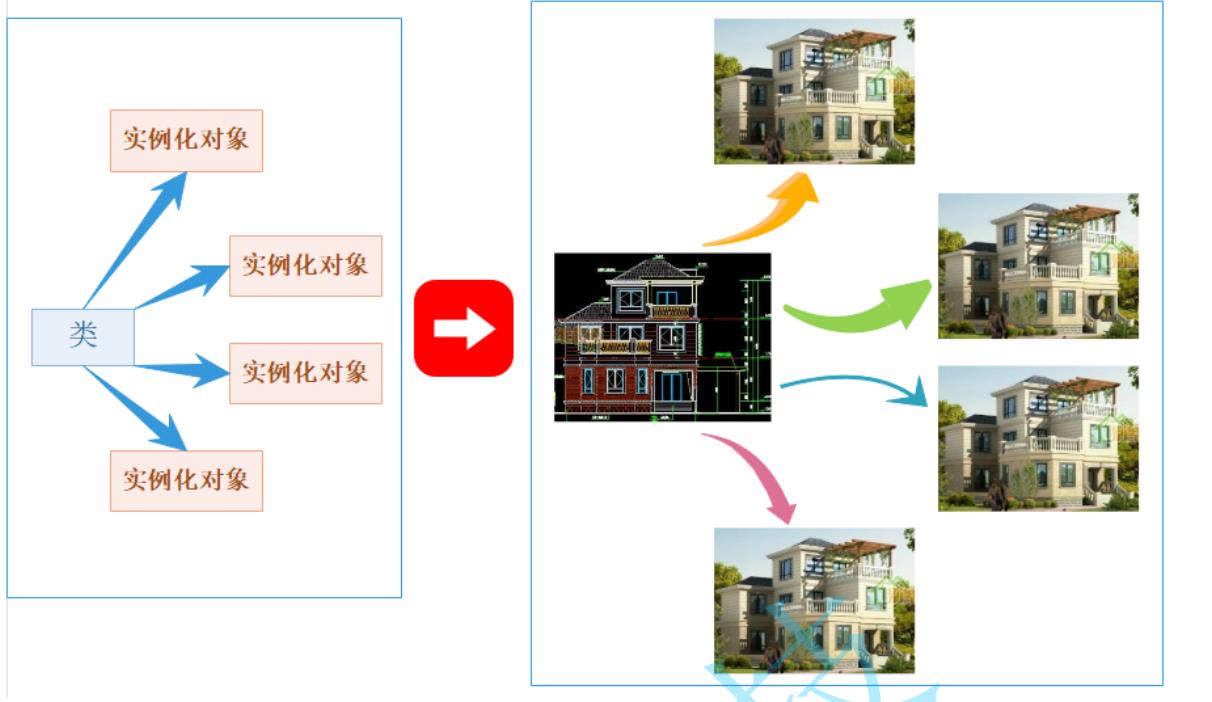
类的实例化
用类类型创建对象的过程,称为类的实例化
- 类只是一个模型一样的东西,限定了类有哪些成员,定义出一个类并没有分配实际的内存空间来存储它
- 一个类可以实例化出多个对象,实例化出的对象 占用实际的物理空间,存储类成员变量。
- 做个比方。类实例化出对象就像现实中使用建筑设计图建造出房子,类就像是设计图,只设计出需要什么东西,但是并没有实体的建筑存在,同样类也只是一个设计,实例化出的对象才能实际存储数据,占用物理空间。
其实这里没什么好说的,只要记得对象在不被创建出来的时候它都是没有空间的。
就比如int 类型,它 自身不占空间,但是你声明了一个int a;你再去对它求sizeof(a);它就存在空间了,这便是类型的实例化。
类对象模型
计算一个类的大小
几个特性:
1. 类对象的成员函数是不占空间的。
2.空类是有大小的。
3. 类中的static变量是不会被计入到类的所占空间大小中的。
1.示例代码:
class person
{
void set()
{
}
void print()
{
}
int num1;
int num2;
int num3;
};
void test01()
{
cout << sizeof(person) << endl; //输出结果为12
}
2.空类是有大小的
class person
{
void print()
{
}
};
void test()
{
cout << sizeof(person) << endl;//输出结果为1
}
int main()
{
test();
return 0;
}
原因:
每个实例在内存中都有一个独一无二的地址,为了达到这个目的,编译器往往会给一个空类隐含的加一个字节,这样空类在实例化后在内存得到了独一无二的地址。所以大小为1。
3.static 变量不属于任何一个类
class person
{
int age;
int num1;
int p;
static int p1;
};
void test01()
{
cout << sizeof(person) << endl;//结果为12
}
int main()
{
test01();
return 0;
}
结构体的内存对齐规则
1.从第一个属性开始,内存从0开始,第二个属性应放在**min(该属性的大小,对齐模数)的整数倍上。
2.当所有属性计算完成后,整体做二次偏移,当所有的属性偏移完成后,取min(该结构体最大元素,对齐模数)**的整数倍。
给大家个代码解释一下吧:
eg:
struct student
{ 第一次偏移 第二次偏移(起始内存必须是min(当前类型大小,对齐模数)整数倍)
char a;// 0 0-3(因为要保证b的地址必须从4开始)
int b;// 1-4 4-7
double c;// 5-12 8-15
}
故对齐后为16字节大小。
当调换元素顺序时,其大小可能会发生改变
struct student
{ 这边直接给值,不写分析步骤
int b; //0-7
double c; //8-15
char a; //16 此时占17个字节,故结果为24字节(内存对齐)
}
//故在定义结构体时在没有特殊需求的情况下,元素应从小到大进行定义
几道关于结构体的面试题
结构体怎么对齐? 为什么要进行内存对齐
为什么要进行内存对齐:(自己见解)
通俗点来说,就比如说你现在1字节1字节的进行读取,假如我现在内存中要放一个int 类型的,char类型的,double 类型的数据 。在32位平台下,我们只需要仅13个字节就可以存储完,相较于内存对齐的情况,我们可以省下3个字节的大小,那为什么不这样做呢?
解释:如果我们需要读取这13个字节的数据,我们1个1个读,会不会显得太蠢了点。首先,从操作系统层面看,为什么要设置缓存,就是为了匹配cpu读取速度与I/o设备不匹配的问题,如果1个字节1个字节读取的话,那是不是要经历13次的访存,这只是最理想的情况下,(在段表、页表中访存)需要两次,段页式需要三次访存。所以,为什么要内存对齐的原因本质上目的是为了用空间换时间,最大化的减少cpu访存的次数,32位的机器每次可以读取4个字节。最大程度上规避了多次访存的情况。计算机自脱机处理阶段开始一直都在想办法去避免 "机等人"的现象出现,提高cpu利用率,让cpu忙起来。
内存对齐原因:
1.不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2、性能原因:经过内存对齐后,CPU的内存访问速度(这块我觉得应该是访问次数)大大提升(大大减少)。
怎么对齐:
1.从第一个属性开始,内存从0开始,第二个属性应放在**min(该属性的大小,对齐模数)的整数倍上。
2.当所有属性计算完成后,整体做二次偏移,当所有的属性偏移完成后,取min(该结构体最大元素,对齐模数)**的整数倍。
如何让结构体按照指定的对齐参数进行对齐
#pragma pack(num) //num为自行设置的内存对齐参数,但必须是2的次方倍。[0-n)
什么是大小端?如何测试某台机器是大端还是小端,有没有遇到过要考虑大小端的场景
大端存储模式:就是内存的低地址上存着数据的高位,高地址上存着数据的低位。
小端存储模式:就是内存的低地址上存数据的低位,而高地址上存数据的高位。
大小端场景:代码移植和网络通信。
类的成员函数到底存在什么地方?
成员函数可以被看作是类作用域的全局函数,不在对象分配的空间里,只有虚函数才会在类对象里有一个指针,存放虚函数的地址等相关信息。成员函数的地址,编译期就已确定,并静态绑定或动态的绑定在对应的对象上。对象调用成员函数时,编译器可以确定这些函数的地址,并通过传入this指针和其他参数,完成函数的调用,所以类中就没有必要存储成员函数的信息。这里有两种猜测,1.多个对象共用一段相同的代码段 2.每个对象都有自己的代码段(每个对象的代码段都是定义代码段的一份拷贝)(笔者不倾向这种) 所以笔者认为此时成员函数的代码段应放在公共代码段中,不单单属于某一特定对象,属于整个对象类。
具体深入探讨的话会涉及到内存的管理,这里就不深挖了。
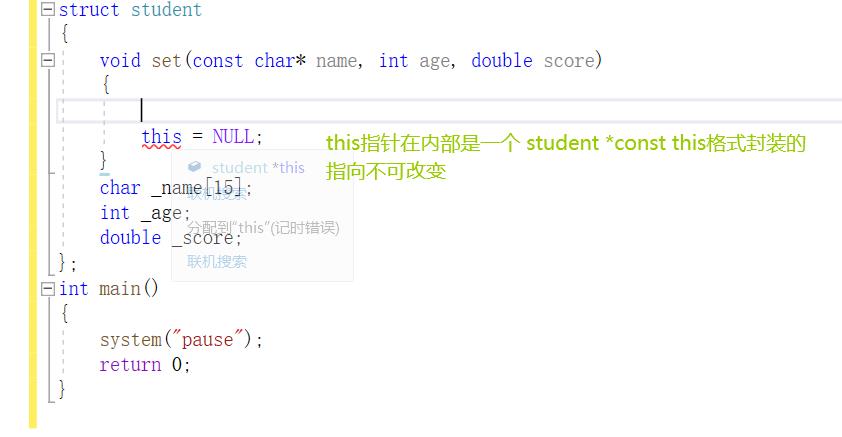
this指针
c++规定,this指针是隐含在对象成员函数内的一种指针。 当一个对象被创建后,它的每一个成员函数都含有一个系统自动生成的隐含指针this,用以保存这个对象的地址, 也就是说虽然我们没有写上this指针,编译器在编译的时候也是会加上的。因此this也称为“指向本对象的指针”,this指针并不是对象的一部分,不会影响sizeof(对象)的结果。
this指针是C++实现封装的一种机制,它将对象和该对象调用的成员函数连接在一起,在外部看来,每一个对象都拥有自己的函数成员。一般情况下,并不写this,而是让系统进行默认设置。
this指针永远指向当前对象。
成员函数通过this指针即可知道操作的是那个对象的数据。This指针是一种隐含指针,它隐含于每个类的非静态成员函数中。This指针无需定义,直接使用即可。
this指针是一个 常指针
任何对象自创建之后都隐含一个this指针
struct student
{
void set(const char* name, int age, double score)
//void set(const char* name, int age, double score.student*const this)
{
strcpy(_name, name);//底层是strcpy(this->_name,name)
_age = age;//底层是this->_age=age;
_score = score;//底层是this->_score=score;
}
void print()//void print(student*const this)
{
cout << "name :" << _name << endl;//底层是cout<<this->_name<<endl;
cout << "age:" << _age << endl;
cout << "score" << _score << endl;
}
char _name[15];
int _age;
double _score;
};
void test01()
{
student m1;
m1.set("张三", 20, 98.9);//底层编译器会将其变为set("张三", 20, 98.9,&m1);
m1.print();//底层编译器会将其变为print(&m1);
}

this指针可以为空
此时会报错,因为this’指针是一个空指针,此时没有空间,去获取它里面的值,当然为错。只是执行会出错,在编译阶段不会报错
struct student
{
void set(const char* name, int age, double score)//void set(const char* name, int age, double score.student*const this)
{
strcpy(_name, name);//底层是strcpy(this->_name,name)
_age = age;//底层是this->_age=age;
_score = score;//底层是this->_score=score;
}
void print()//void print(student*const this)
{
cout << "name :" << _name << endl;//底层是cout<<this->_name<<endl;
cout << "age:" << _age << endl;
cout << "score" << _score << endl;
}
char _name[15];
int _age;
double _score;
};
void test02()
{
student* m1=nullptr;
m1->set("张三", 18, 20);
m1->print();
}
相关面试题
this指针存在哪里?
其实编译器在生成程序时加入了获取对象首地址的相关代码。并把获取的首地址存放在了寄存器ECX中(VC++编译器是放在ECX中,其它编译器有可能不同)。也就是成员函数的其它参数正常都是存放在栈中。而this指针参数则是存放在寄存器中。类的静态成员函数因为没有this指针这个参数,所以类的静态成员函数也就无法调用类的非静态成员变量。
this指针可以为空吗
上面已经给出了解答。
可以为空,当我们调用函数时,如果函数内部不需要使用到this,也就是不需要通过this指向当前对象并对其进行操作时才可以为空(当我们在其中什么都不放或者在里面随便打印一个字符串),如果调用的函数需要指向当前对象,并进行操作,则会发生错误(空指针引用)就跟C中一样不能进行空指针的引用
以上是关于c++模板类的知识,为啥下面程序要用结构体,把T data写在类里面不可以吗?看到好多地方这样写的主要内容,如果未能解决你的问题,请参考以下文章