java多线程之ForkJoinPool
Posted miye
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java多线程之ForkJoinPool相关的知识,希望对你有一定的参考价值。
背景:ForkJoinPool的优势在于,可以充分利用多cpu,多核cpu的优势,把一个任务拆分成多个“小任务”,把多个“小任务”放到多个处理器核心上并行执行;当多个“小任务”执行完成之后,再将这些执行结果合并起来即可。这种思想值得学习。
主要参考《疯狂java讲义》
使用
Java7 提供了ForkJoinPool来支持将一个任务拆分成多个“小任务”并行计算,再把多个“小任务”的结果合并成总的计算结果。
ForkJoinPool是ExecutorService的实现类,因此是一种特殊的线程池。
使用方法:创建了ForkJoinPool实例之后,就可以调用ForkJoinPool的submit(ForkJoinTask<T> task) 或invoke(ForkJoinTask<T> task)方法来执行指定任务了。
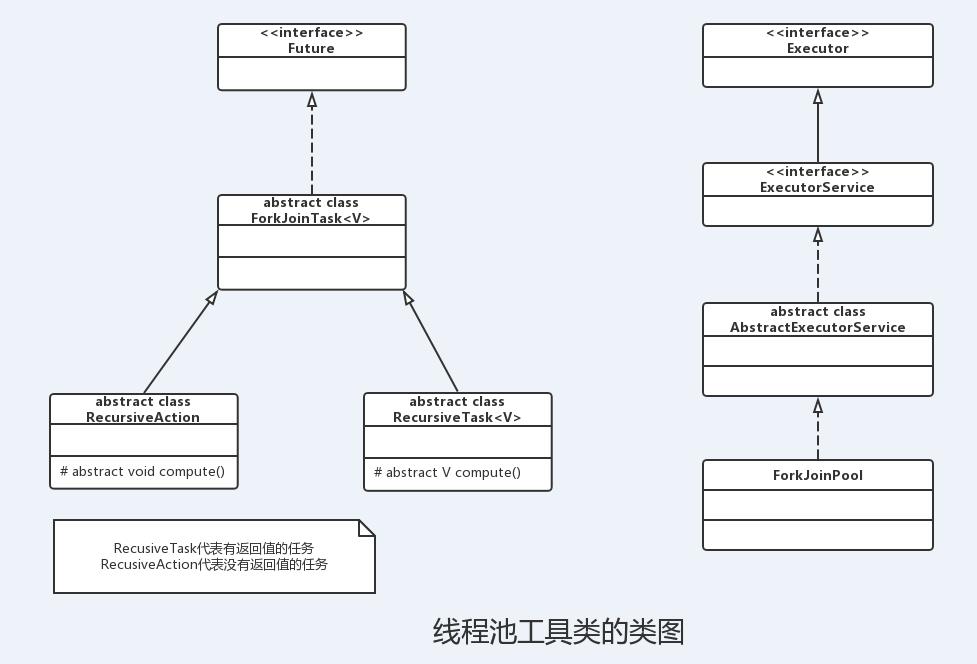
其中ForkJoinTask代表一个可以并行、合并的任务。ForkJoinTask是一个抽象类,它还有两个抽象子类:RecusiveAction和RecusiveTask。其中RecusiveTask代表有返回值的任务,而RecusiveAction代表没有返回值的任务。
下面的UML类图显示了ForkJoinPool、ForkJoinTask之间的关系:
举例
以还行没有返回值的“大任务”(简单低打印1~300的数值)为例,程序将一个“大任务”拆分成多个“小任务”,并将任务交给ForkJoinPool来执行

/**
* Project Name:Spring0725
* File Name:ForkJoinPoolAction.java
* Package Name:work1201.basic
* Date:2017年12月4日下午2:26:55
* Copyright (c) 2017, 深圳金融电子结算中心 All Rights Reserved.
*
*/
package work1201.basic;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.RecursiveAction;
import java.util.concurrent.TimeUnit;
/**
* ClassName:ForkJoinPoolAction <br/>
* Function: 使用ForkJoinPool完成一个任务的分段执行
* 简单的打印0-300的数值。用多线程实现并行执行
* Date: 2017年12月4日 下午2:26:55 <br/>
* @author prd-lxw
* @version 1.0
* @since JDK 1.7
* @see
*/
public class ForkJoinPoolAction {
public static void main(String[] args) throws Exception{
PrintTask task = new PrintTask(0, 300);
//创建实例,并执行分割任务
ForkJoinPool pool = new ForkJoinPool();
pool.submit(task);
//线程阻塞,等待所有任务完成
pool.awaitTermination(2, TimeUnit.SECONDS);
pool.shutdown();
}
}
/**
* ClassName: PrintTask <br/>
* Function: 继承RecursiveAction来实现“可分解”的任务。
* date: 2017年12月4日 下午5:17:41 <br/>
*
* @author prd-lxw
* @version 1.0
* @since JDK 1.7
*/
class PrintTask extends RecursiveAction{
private static final int THRESHOLD = 50; //最多只能打印50个数
private int start;
private int end;
public PrintTask(int start, int end) {
super();
this.start = start;
this.end = end;
}
@Override
protected void compute() {
if(end - start < THRESHOLD){
for(int i=start;i<end;i++){
System.out.println(Thread.currentThread().getName()+"的i值:"+i);
}
}else {
int middle =(start+end)/2;
PrintTask left = new PrintTask(start, middle);
PrintTask right = new PrintTask(middle, end);
//并行执行两个“小任务”
left.fork();
right.fork();
}
}
}
执行结果:
ForkJoinPool-1-worker-1的i值:262 ForkJoinPool-1-worker-7的i值:75 ForkJoinPool-1-worker-7的i值:76 ForkJoinPool-1-worker-5的i值:225 ForkJoinPool-1-worker-3的i值:187 ForkJoinPool-1-worker-6的i值:150 ForkJoinPool-1-worker-6的i值:151 ForkJoinPool-1-worker-6的i值:152 ForkJoinPool-1-worker-6的i值:153 ForkJoinPool-1-worker-6的i值:154 ......
因为我的电脑是i7处理器,一共8个cpu,观察线程的名称可以发现,8个cpu都在运行。
通过RecursiveTask的返回值,来对一个长度为100的数组元素进行累加。
/**
* Project Name:Spring0725
* File Name:ForJoinPollTask.java
* Package Name:work1201.basic
* Date:2017年12月4日下午5:41:46
* Copyright (c) 2017, 深圳金融电子结算中心 All Rights Reserved.
*
*/
package work1201.basic;
import java.util.Random;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
/**
* ClassName:ForJoinPollTask <br/>
* Function: 对一个长度为100的元素值进行累加
* Date: 2017年12月4日 下午5:41:46 <br/>
* @author prd-lxw
* @version 1.0
* @since JDK 1.7
* @see
*/
public class ForJoinPollTask {
public static void main(String[] args) throws Exception {
int[] arr = new int[100];
Random random = new Random();
int total =0;
//初始化100个数组元素
for(int i=0,len = arr.length;i<len;i++){
int temp = random.nextInt(20);
//对数组元素赋值,并将数组元素的值添加到sum总和中
total += (arr[i]=temp);
}
System.out.println("初始化数组总和:"+total);
SumTask task = new SumTask(arr, 0, arr.length);
// 创建一个通用池,这个是jdk1.8提供的功能
ForkJoinPool pool = ForkJoinPool.commonPool();
Future<Integer> future = pool.submit(task); //提交分解的SumTask 任务
System.out.println("多线程执行结果:"+future.get());
pool.shutdown(); //关闭线程池
}
}
/**
* ClassName: SumTask <br/>
* Function: 继承抽象类RecursiveTask,通过返回的结果,来实现数组的多线程分段累累加
* RecursiveTask 具有返回值
* date: 2017年12月4日 下午6:08:11 <br/>
*
* @author prd-lxw
* @version 1.0
* @since JDK 1.7
*/
class SumTask extends RecursiveTask<Integer>{
private static final int THRESHOLD = 20; //每个小任务 最多只累加20个数
private int arry[];
private int start;
private int end;
/**
* Creates a new instance of SumTask.
* 累加从start到end的arry数组
* @param arry
* @param start
* @param end
*/
public SumTask(int[] arry, int start, int end) {
super();
this.arry = arry;
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum =0;
//当end与start之间的差小于threshold时,开始进行实际的累加
if(end - start <THRESHOLD){
for(int i= start;i<end;i++){
sum += arry[i];
}
return sum;
}else {//当end与start之间的差大于threshold,即要累加的数超过20个时候,将大任务分解成小任务
int middle = (start+ end)/2;
SumTask left = new SumTask(arry, start, middle);
SumTask right = new SumTask(arry, middle, end);
//并行执行两个 小任务
left.fork();
right.fork();
//把两个小任务累加的结果合并起来
return left.join()+right.join();
}
}
}
执行结果:
初始化数组总和:1008 多线程执行结果:1008
分析
在Java 7中引入了一种新的线程池:ForkJoinPool。
它同ThreadPoolExecutor一样,也实现了Executor和ExecutorService接口。它使用了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入希望的线程数量,那么当前计算机可用的CPU数量会被设置为线程数量作为默认值。
ForkJoinPool主要用来使用分治法(Divide-and-Conquer Algorithm)来解决问题。典型的应用比如快速排序算法。
这里的要点在于,ForkJoinPool需要使用相对少的线程来处理大量的任务。
比如要对1000万个数据进行排序,那么会将这个任务分割成两个500万的排序任务和一个针对这两组500万数据的合并任务。以此类推,对于500万的数据也会做出同样的分割处理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于10时,会停止分割,转而使用插入排序对它们进行排序。
那么到最后,所有的任务加起来会有大概2000000+个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。
所以当使用ThreadPoolExecutor时,使用分治法会存在问题,因为ThreadPoolExecutor中的线程无法像任务队列中再添加一个任务并且在等待该任务完成之后再继续执行。而使用ForkJoinPool时,就能够让其中的线程创建新的任务,并挂起当前的任务,此时线程就能够从队列中选择子任务执行。
以上程序的关键是fork()和join()方法。在ForkJoinPool使用的线程中,会使用一个内部队列来对需要执行的任务以及子任务进行操作来保证它们的执行顺序。
那么使用ThreadPoolExecutor或者ForkJoinPool,会有什么性能的差异呢?
首先,使用ForkJoinPool能够使用数量有限的线程来完成非常多的具有父子关系的任务,比如使用4个线程来完成超过200万个任务。但是,使用ThreadPoolExecutor时,是不可能完成的,因为ThreadPoolExecutor中的Thread无法选择优先执行子任务,需要完成200万个具有父子关系的任务时,也需要200万个线程,显然这是不可行的。
ps:ForkJoinPool在执行过程中,会创建大量的子任务,导致GC进行垃圾回收,这些是需要注意的。
以上是关于java多线程之ForkJoinPool的主要内容,如果未能解决你的问题,请参考以下文章