Java 集合补充
Posted 谁将新樽辞旧月,今月曾经照古人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 集合补充相关的知识,希望对你有一定的参考价值。
集合大致可以分List,Set,Queue,Map四种体系。
集合和数组不一样,数组元素可以是基本类型的值,也可以是对象(的引用变量),集合里只能保存对象(的引用变量)。
访问:如果访问List集合中的元素可以根据元素的索引,访问Map集合中的元素可以根据元素的key,访问Set集合中的元素只能根据元素本身来访问。
Collection操作:
public class CollectionTest { public static void main(String[] args) { Collection c = new ArrayList(); // 添加元素 c.add("孙悟空"); // 虽然集合里不能放基本类型的值,但Java支持自动装箱 c.add(6); System.out.println("c集合的元素个数为:" + c.size()); // 输出2 // 删除指定元素 c.remove(6); System.out.println("c集合的元素个数为:" + c.size()); // 输出1 // 判断是否包含指定字符串 System.out.println("c集合的是否包含\\"孙悟空\\"字符串:" + c.contains("孙悟空")); // 输出true c.add("轻量级Java EE企业应用实战"); System.out.println("c集合的元素:" + c); Collection books = new HashSet(); books.add("轻量级Java EE企业应用实战"); books.add("疯狂Java讲义"); System.out.println("c集合是否完全包含books集合?" + c.containsAll(books)); // 输出false // 用c集合减去books集合里的元素 c.removeAll(books); System.out.println("c集合的元素:" + c); // 删除c集合里所有元素 c.clear(); System.out.println("c集合的元素:" + c); // 控制books集合里只剩下c集合里也包含的元素 books.retainAll(c); System.out.println("books集合的元素:" + books); } }

注意:
JDK1.5以前系统吧集合所有的元素都当成Object类型,从1.5以后,可以使用泛型来限制集合元素的类型,并让集合记住所有集合元素的类型。
使用Lambda表达式遍历集合:
Java8为Iterable接口新增了一个foreach(Consumer action)默认方法,该方法所需参数的类型是一个函数式接口,而Iterable接口是Collection接口的父接口,因此Collection集合也可以直接调用该方法。
当程序调用Iterable的foreach遍历集合元素,程序会依次将集合元素传给Consumer 的accep(T t)(该接口唯一的抽象方法)方法,因为Consumer是函数式接口,可以使用Lambda表达式来遍历集合元素:
public class CollectionEach { public static void main(String[] args) { // 创建一个集合 Collection books = new HashSet(); books.add("轻量级Java EE企业应用实战"); books.add("疯狂Java讲义"); books.add("疯狂android讲义"); // 调用forEach()方法遍历集合 books.forEach(obj -> System.out.println("迭代集合元素:" + obj)); } }
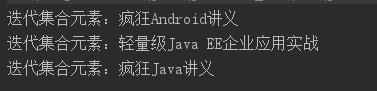
最后一行调用了forEach()方法,传给该方法的参数是一个Lambda表达式,该Lambda表达式的目标类型是Comsumer。
使用Java8增强的Iterator遍历集合元素:
Iterator接口主要用于遍历Collection集合中的元素,Iterator也被称为迭代器。
next()方法返回迭代器刚刚经过的元素。
hasNext()若返回True,则表明接下来还有元素,迭代器不在尾部。
remove()方法必须和next方法一起使用,功能是去除刚刚next方法返回的元素。
forEachRemaining(Consumer action)是Java8新增的方法,可以使用Lambda表达式来遍历集合元素。
public class IteratorTest { public static void main(String[] args) { // 创建集合、添加元素的代码与前一个程序相同 Collection books = new HashSet(); books.add("轻量级Java EE企业应用实战"); books.add("疯狂Java讲义"); books.add("疯狂Android讲义"); // 获取books集合对应的迭代器 Iterator it = books.iterator(); while(it.hasNext()) { // it.next()方法返回的数据类型是Object类型,因此需要强制类型转换 String book = (String)it.next(); System.out.println(book); if (book.equals("疯狂Java讲义")) { // 从集合中删除上一次next方法返回的元素 it.remove(); } // 对book变量赋值,不会改变集合元素本身 book = "测试字符串"; //① } System.out.println(books); } }

注意:
使用Iterator对集合元素进行迭代时,Iterator并不是把集合元素本身传给了迭代变量,而是把集合元素的值传给了迭代变量,所以修改迭代变量的值对集合元素本身没有影响。
当使用Iterator迭代访问Collection集合元素时,Iterator集合里的元素不能被改变,只有通过Iterator的remove方法删除上一次next方法返回的集合元素才可以,否则异常。
public class IteratorErrorTest { public static void main(String[] args) { // 创建集合、添加元素的代码与前一个程序相同 Collection books = new HashSet(); books.add("轻量级Java EE企业应用实战"); books.add("疯狂Java讲义"); books.add("疯狂Android讲义"); // 获取books集合对应的迭代器 Iterator it = books.iterator(); while(it.hasNext()) { String book = (String)it.next(); System.out.println(book); if (book.equals("疯狂Android讲义")) { // 使用Iterator迭代过程中,不可修改集合元素,下面代码引发异常 books.remove(book); } } } }

Iterator使用的时快速失败机制(fail-fast),一旦在迭代过程中检测到该集合已经被修改(通常是程序中的其他线程修改)程序立即引发异常,而不是显示修改后的结果,这样可以避免共享资源而引发的潜在问题。
使用Lambda表达式遍历Iterator
Java8为Iterator新增的forEachRemaining(Consunmer action)方法,该方法所需的Consunmer 同样是函数式接口。
public class IteratorEach { public static void main(String[] args) { // 创建集合、添加元素的代码与前一个程序相同 Collection books = new HashSet(); books.add("轻量级Java EE企业应用实战"); books.add("疯狂Java讲义"); books.add("疯狂Android讲义"); // 获取books集合对应的迭代器 Iterator it = books.iterator(); // 使用Lambda表达式(目标类型是Comsumer)来遍历集合元素 it.forEachRemaining(obj -> System.out.println("迭代集合元素:" + obj)); } }
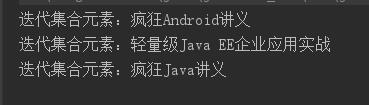
使用Java8新增的Predicate操作集合
Java8起Collection集合新增了一个removeIf(Predicate filter)方法,该方法将会批量删除符合filter条件的所有元素。该方法需要一个Predicate(谓词)对象作为参数,Predicate也是函数式接口,因此可以用Lambda表达式作为参数。
public class PredicateTest { public static void main(String[] args) { // 创建一个集合 Collection books = new HashSet(); books.add(new String("轻量级Java EE企业应用实战")); books.add(new String("疯狂Java讲义")); books.add(new String("疯狂ios讲义")); books.add(new String("疯狂Ajax讲义")); books.add(new String("疯狂Android讲义")); // 使用Lambda表达式(目标类型是Predicate)过滤集合 books.removeIf(ele -> ((String)ele).length() < 10); System.out.println(books); } }

Predicate可以充分简化集合运算:
public class PredicateTest2 { public static void main(String[] args) { // 创建books集合、为books集合添加元素的代码与前一个程序相同。 Collection books = new HashSet(); books.add(new String("轻量级Java EE企业应用实战")); books.add(new String("疯狂Java讲义")); books.add(new String("疯狂iOS讲义")); books.add(new String("疯狂Ajax讲义")); books.add(new String("疯狂Android讲义")); // 统计书名包含“疯狂”子串的图书数量 System.out.println(calAll(books , ele->((String)ele).contains("疯狂"))); // 统计书名包含“Java”子串的图书数量 System.out.println(calAll(books , ele->((String)ele).contains("Java"))); // 统计书名字符串长度大于10的图书数量 System.out.println(calAll(books , ele->((String)ele).length() > 10)); } public static int calAll(Collection books , Predicate p) { int total = 0; for (Object obj : books) { // 使用Predicate的test()方法判断该对象是否满足Predicate指定的条件 if (p.test(obj)) { total ++; } } return total; } }

使用Java8新增的Stream操作集合
Java8新增了Stream、IntStream、LongStream、DoubleStream等流式API。这些API代表多个支持串行和并行聚集操作的元素。其中Stream是一个通用的流接口,其他代表元素类型的流。
Java8还为每个流式API提供了对应的Builder。
public class IntStreamTest { public static void main(String[] args) { IntStream is = IntStream.builder() .add(20) .add(13) .add(-2) .add(18) .build(); // 下面调用聚集方法的代码每次只能执行一个 System.out.println("is所有元素的最大值:" + is.max().getAsInt()); System.out.println("is所有元素的最小值:" + is.min().getAsInt()); System.out.println("is所有元素的总和:" + is.sum()); System.out.println("is所有元素的总数:" + is.count()); System.out.println("is所有元素的平均值:" + is.average()); System.out.println("is所有元素的平方是否都大于20:" + is.allMatch(ele -> ele * ele > 20)); System.out.println("is是否包含任何元素的平方大于20:" + is.anyMatch(ele -> ele * ele > 20)); // 将is映射成一个新Stream,新Stream的每个元素是原Stream元素的2倍+1 IntStream newIs = is.map(ele -> ele * 2 + 1); // 使用方法引用的方式来遍历集合元素 newIs.forEach(System.out::println); // 输出41 27 -3 37 } }
public class CollectionStream { public static void main(String[] args) { // 创建books集合、为books集合添加元素的代码与8.2.5小节的程序相同。 Collection books = new HashSet(); books.add(new String("轻量级Java EE企业应用实战")); books.add(new String("疯狂Java讲义")); books.add(new String("疯狂iOS讲义")); books.add(new String("疯狂Ajax讲义")); books.add(new String("疯狂Android讲义")); // 统计书名包含“疯狂”子串的图书数量 System.out.println(books.stream() .filter(ele->((String)ele).contains("疯狂")) .count()); // 输出4 // 统计书名包含“Java”子串的图书数量 System.out.println(books.stream() .filter(ele->((String)ele).contains("Java") ) .count()); // 输出2 // 统计书名字符串长度大于10的图书数量 System.out.println(books.stream() .filter(ele->((String)ele).length() > 10) .count()); // 输出2 // 先调用Collection对象的stream()方法将集合转换为Stream, // 再调用Stream的mapToInt()方法获取原有的Stream对应的IntStream books.stream().mapToInt(ele -> ((String)ele).length()) // 调用forEach()方法遍历IntStream中每个元素 .forEach(System.out::println);// 输出8 11 16 7 8 } }
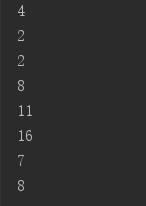
Set集合
set和Collection基本相同,实际上set就是Collection,只是行为略有不同(set不允许重复)。
如果把两个形同元素添加进set,会返回false,并元素不会被加入。
HashSet
HashSet是Set接口的典型实现,HasHSet按照Hash算法来存储集合中的元素,因此具有很好的存取和查找性能。
特点:
无序。不同步,如果多个线程访问同一个HashSet,有两个或以上线程修改了时,必须通过代码保证其同步。集合元素可以null。
原理:
当HashSet集合存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后给根据hashCode值决定该对象的存储位置。判断两个元素相等的标准是2个对象的equals()方法比较相等,hashCode()方法返回值也相等。
// 类A的equals方法总是返回true,但没有重写其hashCode()方法 class A { public boolean equals(Object obj) { return true; } } // 类B的hashCode()方法总是返回1,但没有重写其equals()方法 class B { public int hashCode() { return 1; } } // 类C的hashCode()方法总是返回2,且重写其equals()方法总是返回true class C { public int hashCode() { return 2; } public boolean equals(Object obj) { return true; } } public class HashSetTest { public static void main(String[] args) { HashSet books = new HashSet(); // 分别向books集合中添加两个A对象,两个B对象,两个C对象 books.add(new A()); books.add(new A()); books.add(new B()); books.add(new B()); books.add(new C()); books.add(new C()); System.out.println(books); } }
C类重写了equals()方法和hashCode()方法,返回相同的值,因此set集合中只有一个C类对象。
注意:
当一个对象放入Has和Set()集合时,如果需要重写该对象的equals()方法,则也应当重写该对象的hashCode()方法。规则是如果equals()返回true,则hashCode值也相等。
hash算法
散列算法(Hash Algorithm),又称哈希算法,杂凑算法,是一种从任意文件中创造小的数字「指纹」的方法。与指纹一样,散列算法就是一种以较短的信息来保证文件唯一性的标志,这种标志与文件的每一个字节都相关,而且难以找到逆向规律。因此,当原有文件发生改变时,其标志值也会发生改变,从而告诉文件使用者当前的文件已经不是你所需求的文件。散列算法最重要的用途在于给证书、文档、密码等高安全系数的内容添加加密保护。这一方面的用途主要是得益于散列算法的不可逆性,这种不可逆性体现在,你不仅不可能根据一段通过散列算法得到的指纹来获得原有的文件,也不可能简单地创造一个文件并让它的指纹与一段目标指纹相一致。
一个优秀的 hash 算法,将能实现:
- 正向快速:给定明文和 hash 算法,在有限时间和有限资源内能计算出 hash 值。
- 逆向困难:给定(若干) hash 值,在有限时间内很难(基本不可能)逆推出明文。
- 输入敏感:原始输入信息修改一点信息,产生的 hash 值看起来应该都有很大不同。
- 冲突避免:很难找到两段内容不同的明文,使得它们的 hash 值一致(发生冲突)。即对于任意两个不同的数据块,其hash值相同的可能性极小;对于一个给定的数据块,找到和它hash值相同的数据块极为困难。
hash算法的功能是,保证快速查找被检索的对象,hash算法的价值在于速度,,当需要查询集合中的元素时,hash算法可以根据该元素的hashCode值计算出该元素的存储位置,从而快速定位该元素。
HashSet和数组:
数组有索引可以快速定位,HashSet集合里的元素没有索引,实际上当程序向HashSet集合中添加元素时,HashSet会根据该元素的hashCode值计算他的存储位置,这样也可以快速定位该元素。
优势:
数组元素的索引是连续的,数组长度是固定的,无法自由增加数组长度。HashSet因为使用hashCode值计算存储位置,从而可以自由增加HashSet长度,并根据hashCode值访问元素。因此,当从HashSet中访问元素时,HashSet先计算该元素的hashCode值,然后到hashCode值对应的位置取出该元素,所以速度快。
HashSet中每个能存储元素的槽位通常称为桶,如果有多个元素的hashCode值相同,但他们通过equals方法返回false,就会在同一个桶里放多个元素,导致性能下降。
如果像HashSet中添加一个可变对象后,后面程序修改了该可变对象的实例变量,可能导致它与集合中其他元素相同,这就可能导致HashSet中包含两个相同的对象。
class R { int count; public R(int count) { this.count = count; } public String toString() { return "R[count:" + count + "]"; } public boolean equals(Object obj) { if(this == obj) return true; if (obj != null && obj.getClass() == R.class) { R r = (R)obj; return this.count == r.count; } return false; } public int hashCode() { return this.count; } } public class HashSetTest2 { public static void main(String[] args) { HashSet hs = new HashSet(); hs.add(new R(5)); hs.add(new R(-3)); hs.add(new R(9)); hs.add(new R(-2)); // 打印HashSet集合,集合元素没有重复 System.out.println(hs); // 取出第一个元素 Iterator it = hs.iterator(); R first = (R)it.next(); // 为第一个元素的count实例变量赋值 first.count = -3; // ① // 再次输出HashSet集合,集合元素有重复元素 System.out.println(hs); // 删除count为-3的R对象 hs.remove(new R(-3)); // ② // 可以看到被删除了一个R元素 System.out.println(hs); System.out.println("hs是否包含count为-3的R对象?" + hs.contains(new R(-3))); // 输出false System.out.println("hs是否包含count为-2的R对象?" + hs.contains(new R(-2))); // 输出false } }
LinkedHashSet类
LinkedHashSet集合也是根据hashCode值来决定元素存储的位置,同时他使用链表维护元素的次序。性能低于HashSet,但是在迭代访问Set里的全部元素时将有很好的性能,因为他以链表来维护内部顺序。
public class LinkedHashSetTest { public static void main(String[] args) { LinkedHashSet books = new LinkedHashSet(); books.add("疯狂Java讲义"); books.add("轻量级Java EE企业应用实战"); System.out.println(books); // 删除 疯狂Java讲义 books.remove("疯狂Java讲义"); // 重新添加 疯狂Java讲义 books.add("疯狂Java讲义"); System.out.println(books); } }
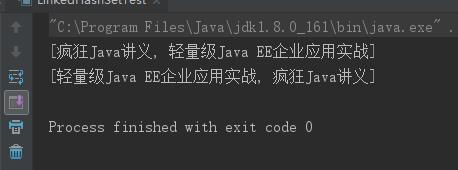
TreESet类
TreESet时SortedSet接口的实现类,TreeSet可以保证集合元素处于排序状态。
public class TreeSetTest { public static void main(String[] args) { TreeSet nums = new TreeSet(); // 向TreeSet中添加四个Integer对象 nums.add(5); nums.add(2); nums.add(10); nums.add(-9); // 输出集合元素,看到集合元素已经处于排序状态 System.out.println(nums); // 输出集合里的第一个元素 System.out.println(nums.first()); // 输出-9 // 输出集合里的最后一个元素 System.out.println(nums.last()); // 输出10 // 返回小于4的子集,不包含4 System.out.println(nums.headSet(4)); // 输出[-9, 2] // 返回大于5的子集,如果Set中包含5,子集中还包含5 System.out.println(nums.tailSet(5)); // 输出 [5, 10] // 返回大于等于-3,小于4的子集。 System.out.println(nums.subSet(-3 , 4)); // 输出[2] } }
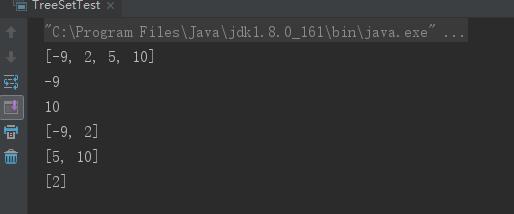
可以看出TreeSet是根据元素实际值大小排序的。
TreeSet采用红黑树的数据结构来存储集合元素。
自然排序:
TreeSet调用几何元素的compareTo(Object obj)方法比较元素的大小关系,然后升序排列。
Java提供了Comparable接口,里面提供了compareTo(Object obj)方法,该方法返回一个整数值,当返回0说明相等,正整数大于,负整数小于。
如果把一个对象添加到TreeSet时,该对象必须实现Comparable接口:
class Err{} public class TreeSetErrorTest { public static void main(String[] args) { TreeSet ts = new TreeSet(); // 向TreeSet集合中添加Err对象 // 自然排序时,Err没实现Comparable接口将会引发错误 ts.add(new Err()); } }

想TreeSet添加的应该是同一个类的对象:
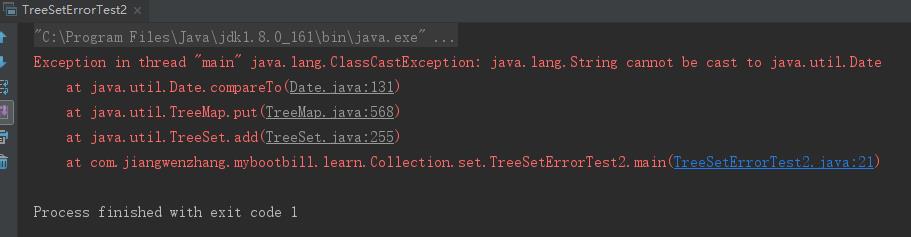
public class TreeSetErrorTest2 { public static void main(String[] args) { TreeSet ts = new TreeSet(); // 向TreeSet集合中添加两个对象 ts.add(new String("疯狂Java讲义")); ts.add(new Date()); // ① } }
如果像TreeSet中添加的是自定义类,且自定义类实现了Comparable接口,且实现了compareTo(Object obj)方法没有进行强制转换,可以添加多种类型。
TreeSet判断相等的唯一标准是compareTo(Object obj)方法返回0。返回0则无法添加相同对象。
class Z implements Comparable { int age; public Z(int age) { this.age = age; } // 重写equals()方法,总是返回true public boolean equals(Object obj) { return true; } // 重写了compareTo(Object obj)方法,总是返回1 public int compareTo(Object obj) { return 1; } } public class TreeSetTest2 { public static void main(String[] args) { TreeSet set = new TreeSet(); Z z1 = new Z(6); set.add(z1); // 第二次添加同一个对象,输出true,表明添加成功 System.out.println(set.add(z1)); //① // 下面输出set集合,将看到有两个元素 System.out.println(set); // 修改set集合的第一个元素的age变量 ((Z)(set.first())).age = 9; // 输出set集合的最后一个元素的age变量,将看到也变成了9 System.out.println(((Z)(set.last())).age); } }

注意:把一个对象放入TreeSet集合时,重写该对象的equals()方法时应保证该方法与compareTo()方法一致。
如果像TreeSet中添加一个可变对象并修改该对象的实例变量,导致它与其他对象的大小顺序发生了改变,但TreeSet不会再次调整他们的顺序,甚至可能他们的compareTo()结果返回0.
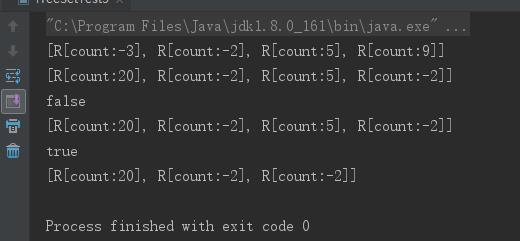
class R implements Comparable { int count; public R(int count) { this.count = count; } public String toString() { return "R[count:" + count + "]"; } // 重写equals方法,根据count来判断是否相等 public boolean equals(Object obj) { if (this == obj) { return true; } if(obj != null && obj.getClass() == R.class) { R r = (R)obj; return r.count == this.count; } return false; } // 重写compareTo方法,根据count来比较大小 public int compareTo(Object obj) { R r = (R)obj; return count > r.count ? 1 : count < r.count ? -1 : 0; } } public class TreeSetTest3 { public static void main(String[] args) { TreeSet ts = new TreeSet(); ts.add(new R(5)); ts.add(new R(-3)); ts.add(new R(9)); ts.add(new R(-2)); // 打印TreeSet集合,集合元素是有序排列的 System.out.println(ts); // ① // 取出第一个元素 R first = (R)ts.first(); // 对第一个元素的count赋值 first.count = 20; // 取出最后一个元素 R last = (R)ts.last(); // 对最后一个元素的count赋值,与第二个元素的count相同 last.count = -2; // 再次输出将看到TreeSet里的元素处于无序状态,且有重复元素 System.out.println(ts); // ② // 删除实例变量被改变的元素,删除失败 System.out.println(ts.remove(new R(-2))); // ③ System.out.println(ts); // 删除实例变量没有被改变的元素,删除成功 System.out.println(ts.remove(new R(5))); // ④ System.out.println(ts); } }
定制排序:
如果需要实现定制排序则需要在创建TreeSet集合对象时,提供一个Comparator对象与该TreeSet集合关联,由该Comparator对象负责集合元素的排序逻辑。Comparator是函数式接口,可以使用Lambda代替Comparator对象。
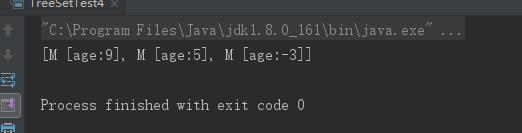
class M { int age; public M(int age) { this.age = age; } public String toString() { return "M [age:" + age + "]"; } } public class TreeSetTest4 { public static void main(String[] args) { // 此处Lambda表达式的目标类型是Comparator TreeSet ts = new TreeSet((o1 , o2) -> { M m1 = (M)o1; M m2 = (M)o2; // 根据M对象的age属性来决定大小,age越大,M对象反而越小 return m1.age > m2.age ? -1 : m1.age < m2.age ? 1 : 0; }); ts.add(new M(5)); ts.add(new M(-3)); ts.add(new M(9)); System.out.println(ts); } }
EnumSet类
EnumSet是一个专为枚举设计的集合类。EnumSet也是有序的,EnumSet以枚举值在EnumSet类内的定义顺序来决定集合元素的顺序。
EnumSet在内部以位向量的形式存储,紧凑高效,占内存小,效率高。
enum Season { SPRING,SUMMER,FALL,WINTER } public class EnumSetTest { public static void main(String[] args) { // 创建一个EnumSet集合,集合元素就是Season枚举类的全部枚举值 EnumSet es1 = EnumSet.allOf(Season.class); System.out.println(es1); // 输出[SPRING,SUMMER,FALL,WINTER] // 创建一个EnumSet空集合,指定其集合元素是Season类的枚举值。 EnumSet es2 = EnumSet.noneOf(Season.class); System.out.println(es2); // 输出[] // 手动添加两个元素 es2.add(Season.WINTER); es2.add(Season.SPRING); System.out.println(es2); // 输出[SPRING,WINTER] // 以指定枚举值创建EnumSet集合 EnumSet es3 = EnumSet.of(Season.SUMMER , Season.WINTER); System.out.println(es3); // 输出[SUMMER,WINTER] EnumSet es4 = EnumSet.range(Season.SUMMER , Season.WINTER); System.out.println(es4); // 输出[SUMMER,FALL,WINTER] // 新创建的EnumSet集合的元素和es4集合的元素有相同类型, // es5的集合元素 + es4集合元素 = Season枚举类的全部枚举值 EnumSet es5 = EnumSet.complementOf(es4); System.out.println(es5); // 输出[SPRING] } }
public class EnumSetTest2 { public以上是关于Java 集合补充的主要内容,如果未能解决你的问题,请参考以下文章