撸一撸Spring Cloud Ribbon的原理-负载均衡策略
Posted 白色的海
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了撸一撸Spring Cloud Ribbon的原理-负载均衡策略相关的知识,希望对你有一定的参考价值。
在前两篇《撸一撸Spring Cloud Ribbon的原理》,《撸一撸Spring Cloud Ribbon的原理-负载均衡器》中,整理了Ribbon如何通过负载均衡拦截器植入RestTemplate,以及调用负载均衡器获取服务列表,如何过滤,如何更新等的处理过程。
因为,负载均衡器最终是调用负载均衡策略的choose方法来选择一个服务,所以这一篇,整理Ribbon的负载均衡策略。
策略类
- RandomRule
- RoundRobinRule
- RetryRule
- WeightedResponseTimeRule
- ClientConfigEnabledRoundRobinRule
- BestAvailableRule
- PredicateBasedRule
- AvailabilityFilteringRule
- ZoneAvoidanceRule
他们的位置在:
ribbon-loadbalancer-2.2.2.jar
com.netflix.loadbalancer
类继承关系

RandomRule
随机选取负载均衡策略。
choose方法中,通过随机Random对象,在所有服务实例数量中随机找一个服务的索引号,然后从上线的服务中获取对应的服务。
这时候,很可能会有不在线的服务,就有可能从上线的服务中获取不到,那么休息会儿再获取知道随机获取到一个上线的服务为止。
public class RandomRule extends AbstractLoadBalancerRule { Random rand; public RandomRule() { rand = new Random(); } @edu.umd.cs.findbugs.annotations.SuppressWarnings(value = "RCN_REDUNDANT_NULLCHECK_OF_NULL_VALUE") public Server choose(ILoadBalancer lb, Object key) { if (lb == null) { return null; } Server server = null; while (server == null) { if (Thread.interrupted()) { return null; } List<Server> upList = lb.getReachableServers(); List<Server> allList = lb.getAllServers(); int serverCount = allList.size(); if (serverCount == 0) { /* * No servers. End regardless of pass, because subsequent passes * only get more restrictive. */ return null; } int index = rand.nextInt(serverCount); server = upList.get(index); if (server == null) { /* * The only time this should happen is if the server list were * somehow trimmed. This is a transient condition. Retry after * yielding. */ Thread.yield(); continue; } if (server.isAlive()) { return (server); } // Shouldn\'t actually happen.. but must be transient or a bug. server = null; Thread.yield(); } return server; } //略 }
RoundRobinRule
线性轮询负载均衡策略。
choose方法中,通过incrementAndGetModulo方法以线性轮询方式获取服务。
在incrementAndGetModulo中,实际上在类中维护了一个原子性的nextServerCyclicCounter成员变量作为当前服务的索引号,每次在所有服务数量的限制下,就是将服务的索引号加1,到达服务数量限制时再从头开始。
public class RoundRobinRule extends AbstractLoadBalancerRule { private AtomicInteger nextServerCyclicCounter; // 略 public RoundRobinRule() { nextServerCyclicCounter = new AtomicInteger(0); } public RoundRobinRule(ILoadBalancer lb) { this(); setLoadBalancer(lb); } public Server choose(ILoadBalancer lb, Object key) { if (lb == null) { log.warn("no load balancer"); return null; } Server server = null; int count = 0; while (server == null && count++ < 10) { List<Server> reachableServers = lb.getReachableServers(); List<Server> allServers = lb.getAllServers(); int upCount = reachableServers.size(); int serverCount = allServers.size(); if ((upCount == 0) || (serverCount == 0)) { log.warn("No up servers available from load balancer: " + lb); return null; } int nextServerIndex = incrementAndGetModulo(serverCount); server = allServers.get(nextServerIndex); if (server == null) { /* Transient. */ Thread.yield(); continue; } if (server.isAlive() && (server.isReadyToServe())) { return (server); } // Next. server = null; } if (count >= 10) { log.warn("No available alive servers after 10 tries from load balancer: " + lb); } return server; } private int incrementAndGetModulo(int modulo) { for (;;) { int current = nextServerCyclicCounter.get(); int next = (current + 1) % modulo; if (nextServerCyclicCounter.compareAndSet(current, next)) return next; } } // 略 }
WeightedResponseTimeRule
响应时间作为选取权重的负载均衡策略。
其含义就是,响应时间越短的服务被选中的可能性大。
继承自RoundRobinRule类。
public class WeightedResponseTimeRule extends RoundRobinRule { // 略 // holds the accumulated weight from index 0 to current index // for example, element at index 2 holds the sum of weight of servers from 0 to 2 private volatile List<Double> accumulatedWeights = new ArrayList<Double>(); // 略 void initialize(ILoadBalancer lb) { if (serverWeightTimer != null) { serverWeightTimer.cancel(); } serverWeightTimer = new Timer("NFLoadBalancer-serverWeightTimer-" + name, true); serverWeightTimer.schedule(new DynamicServerWeightTask(), 0, serverWeightTaskTimerInterval); // do a initial run ServerWeight sw = new ServerWeight(); sw.maintainWeights(); Runtime.getRuntime().addShutdownHook(new Thread(new Runnable() { public void run() { logger .info("Stopping NFLoadBalancer-serverWeightTimer-" + name); serverWeightTimer.cancel(); } })); } // 略 @edu.umd.cs.findbugs.annotations.SuppressWarnings(value = "RCN_REDUNDANT_NULLCHECK_OF_NULL_VALUE") @Override public Server choose(ILoadBalancer lb, Object key) { if (lb == null) { return null; } Server server = null; while (server == null) { // get hold of the current reference in case it is changed from the other thread List<Double> currentWeights = accumulatedWeights; if (Thread.interrupted()) { return null; } List<Server> allList = lb.getAllServers(); int serverCount = allList.size(); if (serverCount == 0) { return null; } int serverIndex = 0; // last one in the list is the sum of all weights double maxTotalWeight = currentWeights.size() == 0 ? 0 : currentWeights.get(currentWeights.size() - 1); // No server has been hit yet and total weight is not initialized // fallback to use round robin if (maxTotalWeight < 0.001d) { server = super.choose(getLoadBalancer(), key); if(server == null) { return server; } } else { // generate a random weight between 0 (inclusive) to maxTotalWeight (exclusive) double randomWeight = random.nextDouble() * maxTotalWeight; // pick the server index based on the randomIndex int n = 0; for (Double d : currentWeights) { if (d >= randomWeight) { serverIndex = n; break; } else { n++; } } server = allList.get(serverIndex); } if (server == null) { /* Transient. */ Thread.yield(); continue; } if (server.isAlive()) { return (server); } // Next. server = null; } return server; } class DynamicServerWeightTask extends TimerTask { public void run() { ServerWeight serverWeight = new ServerWeight(); try { serverWeight.maintainWeights(); } catch (Exception e) { logger.error("Error running DynamicServerWeightTask for {}", name, e); } } } class ServerWeight { public void maintainWeights() { ILoadBalancer lb = getLoadBalancer(); if (lb == null) { return; } if (!serverWeightAssignmentInProgress.compareAndSet(false, true)) { return; } try { logger.info("Weight adjusting job started"); AbstractLoadBalancer nlb = (AbstractLoadBalancer) lb; LoadBalancerStats stats = nlb.getLoadBalancerStats(); if (stats == null) { // no statistics, nothing to do return; } double totalResponseTime = 0; // find maximal 95% response time for (Server server : nlb.getAllServers()) { // this will automatically load the stats if not in cache ServerStats ss = stats.getSingleServerStat(server); totalResponseTime += ss.getResponseTimeAvg(); } // weight for each server is (sum of responseTime of all servers - responseTime) // so that the longer the response time, the less the weight and the less likely to be chosen Double weightSoFar = 0.0; // create new list and hot swap the reference List<Double> finalWeights = new ArrayList<Double>(); for (Server server : nlb.getAllServers()) { ServerStats ss = stats.getSingleServerStat(server); double weight = totalResponseTime - ss.getResponseTimeAvg(); weightSoFar += weight; finalWeights.add(weightSoFar); } setWeights(finalWeights); } catch (Exception e) { logger.error("Error calculating server weights", e); } finally { serverWeightAssignmentInProgress.set(false); } } } void setWeights(List<Double> weights) { this.accumulatedWeights = weights; } // 略 }
既然是按照响应时间权重来选择服务,那么先整理一下权重算法是怎么做的。
观察initialize方法,启动了定时器定时执行DynamicServerWeightTask的run来调用计算服务权重,计算权重是通过内部类ServerWeight的maintainWeights方法来进行。
整理一下maintainWeights方法的逻辑,里面有两个for循环,第一个for循环拿到所有服务的总响应时间,第二个for循环计算每个服务的权重以及总权重。
第一个for循环。
假设有4个服务,每个服务的响应时间(ms):
A: 200
B: 500
C: 30
D: 1200
总响应时间:
200+500+30+1200=1930ms
接下来第二个for循环,计算每个服务的权重。
服务的权重=总响应时间-服务自身的响应时间:
A: 1930-200=1730
B: 1930-500=1430
C: 1930-30=1900
D: 1930-1200=730
总权重:
1730+1430+1900+730=5790
响应时间及权重计算结果示意图:
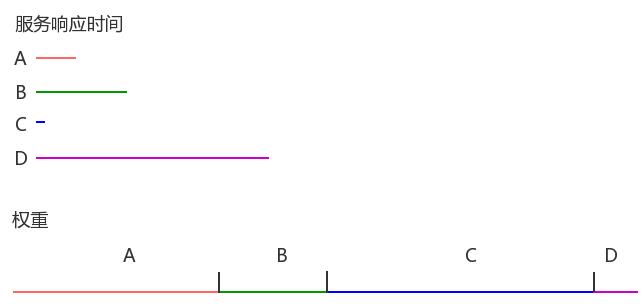
结果就是响应时间越短的服务,它的权重就越大。
再看一下choose方法。
重点在while循环的第3个if这里。
首先如果判定没有服务或者权重还没计算出来时,会采用父类RoundRobinRule以线性轮询的方式选择服务器。
有服务,有权重计算结果后,就是以总权重值为限制,拿到一个随机数,然后看随机数落到哪个区间,就选择对应的服务。
所以选取服务的结论就是:
响应时间越短的服务,它的权重就越大,被选中的可能性就越大。
RetryRule
这个策略默认就是用RoundRobinRule策略选取服务,当然可以通过配置,在构造RetryRule的时候传进想要的策略。
为了应对在有可能出现无法选取出服务的情况,比如瞬时断线的情况,那么就要提供一种重试机制,在最大重试时间的限定下重复尝试选取服务,直到选取出一个服务或者超时。
最大重试时间maxRetryMillis是可配置的。
public class RetryRule extends AbstractLoadBalancerRule { IRule subRule = new RoundRobinRule(); long maxRetryMillis = 500; public RetryRule() { } public RetryRule(IRule subRule) { this.subRule = (subRule != null) ? subRule : new RoundRobinRule(); } public RetryRule(IRule subRule, long maxRetryMillis) { this.subRule = (subRule != null) ? subRule : new RoundRobinRule(); this.maxRetryMillis = (maxRetryMillis > 0) ? maxRetryMillis : 500; } // 略 public void setMaxRetryMillis(long maxRetryMillis) { if (maxRetryMillis > 0) { this.maxRetryMillis = maxRetryMillis; } else { this.maxRetryMillis = 500; } } // 略 /* * Loop if necessary. Note that the time CAN be exceeded depending on the * subRule, because we\'re not spawning additional threads and returning * early. */ public Server choose(ILoadBalancer lb, Object key) { long requestTime = System.currentTimeMillis(); long deadline = requestTime + maxRetryMillis; Server answer = null; answer = subRule.choose(key); if (((answer == null) || (!answer.isAlive())) && (System.currentTimeMillis() < deadline)) { InterruptTask task = new InterruptTask(deadline - System.currentTimeMillis()); while (!Thread.interrupted()) { answer = subRule.choose(key); if (((answer == null) || (!answer.isAlive())) && (System.currentTimeMillis() < deadline)) { /* pause and retry hoping it\'s transient */ Thread.yield(); } else { break; } } task.cancel(); } if ((answer == null) || (!answer.isAlive())) { return null; } else { return answer; } } // 略 }
ClientConfigEnabledRoundRobinRule
该策略本身很简单,就是默认通过RoundRobinRule策略选取服务,策略还不能自定义。
这个策略的的目的就是通过继承该类,并且通过对choose的重写,来实现更多的功能,继承后保底是有RoundRobinRule策略。
public class ClientConfigEnabledRoundRobinRule extends AbstractLoadBalancerRule { RoundRobinRule roundRobinRule = new RoundRobinRule(); @Override public void initWithNiwsConfig(IClientConfig clientConfig) { roundRobinRule = new RoundRobinRule(); } @Override public void setLoadBalancer(ILoadBalancer lb) { super.setLoadBalancer(lb); roundRobinRule.setLoadBalancer(lb); } @Override public Server choose(Object key) { if (roundRobinRule != null) { return roundRobinRule.choose(key); } else { throw new IllegalArgumentException( "This class has not been initialized with the RoundRobinRule class"); } } }
BestAvailableRule
继承自上面的ClientConfigEnabledRoundRobinRule,重写choose方法。
从所有的服务中,从那些没有断开的服务中,找到,到目前为止,请求数量最小的服务。
public class BestAvailableRule extends ClientConfigEnabledRoundRobinRule { private LoadBalancerStats loadBalancerStats; @Override public Server choose(Object key) { if (loadBalancerStats == null) { return super.choose(key); } List<Server> serverList = getLoadBalancer().getAllServers(); int minimalConcurrentConnections = Integer.MAX_VALUE; long currentTime = System.currentTimeMillis(); Server chosen = null; for (Server server: serverList) { ServerStats serverStats = loadBalancerStats.getSingleServerStat(server); if (!serverStats.isCircuitBreakerTripped(currentTime)) { int concurrentConnections = serverStats.getActiveRequestsCount(currentTime); if (concurrentConnections < minimalConcurrentConnections) { minimalConcurrentConnections = concurrentConnections; chosen = server; } } } if (chosen == null) { return super.choose(key); } else { return chosen; } } @Override public void setLoadBalancer(ILoadBalancer lb) { super.setLoadBalancer(lb); if (lb instanceof AbstractLoadBalancer) { loadBalancerStats = ((AbstractLoadBalancer) lb).getLoadBalancerStats(); } } }
PredicateBasedRule
这是一个抽象类,提供一个choose的模板,通过调用AbstractServerPredicate实现类的过滤方法来过滤出目标的服务,再通过轮询方法选出一个服务。
PredicateBasedRule的子类ZoneAvoidanceRule使用了该模板选择服务。
public abstract class PredicateBasedRule extends ClientConfigEnabledRoundRobinRule { public abstract AbstractServerPredicate getPredicate(); @Override public Server choose(Object key) { ILoadBalancer lb = getLoadBalancer(); Optional<Server> server = getPredicate().chooseRoundRobinAfterFiltering(lb.getAllServers(), key); if (server.isPresent()) { return server.get(); } else { return null; } } }
AvailabilityFilteringRule
按可用性进行过滤服务的负载均衡策略。
继承自PredicateBasedRule,但是重写了choose方法。
public class AvailabilityFilteringRule extends PredicateBasedRule { private AbstractServerPredicate predicate; // 略
@Override public Server choose(Object key) { int count = 0; Server server = roundRobinRule.choose(key); while (count++ <= 10) { if (predicate.apply(new PredicateKey(server))) { return server; } server = roundRobinRule.choose(key); } return super.choose(key); } // 略 }
先用线性轮询策略选出一个服务,通过predicate对象判断是否符合可用性要求,符合的就作为目标服务。这里的做法就是先选择后过滤。
如果尝试了十次都没有可用的服务,调用父类PredicateBasedRule的choose。
在构造函数中会看到AvailabilityFilteringRule用的是AvailabilityPredicate对象对服务进行判定。
public class AvailabilityFilteringRule extends PredicateBasedRule { private AbstractServerPredicate predicate; public AvailabilityFilteringRule() { super(); predicate = CompositePredicate.withPredicate(new AvailabilityPredicate(this, null)) .addFallbackPredicate(AbstractServerPredicate.alwaysTrue()) .build(); } @Override public void initWithNiwsConfig(IClientConfig clientConfig) { predicate = CompositePredicate.withPredicate(new AvailabilityPredicate(this, clientConfig)) .addFallbackPredicate(AbstractServerPredicate.alwaysTrue()) .build(); } // 略 }
在AvailabilityPredicate中,通过shouldSkipServer函数判定服务状态。
public class AvailabilityPredicate extends AbstractServerPredicate { // 略 @Override public boolean apply(@Nullable PredicateKey input) { LoadBalancerStats stats = getLBStats(); if (stats == null) { return true; } return !shouldSkipServer(stats.getSingleServerStat(input.getServer())); } private boolean shouldSkipServer(ServerStats stats) { if ((CIRCUIT_BREAKER_FILTERING.get() && stats.isCircuitBreakerTripped()) || stats.getActiveRequestsCount() >= activeConnectionsLimit.get()) { return true; } return false; } }
判定规则:
以下两项有一项成立,就表示该服务不可用,不能使用该服务。
1.
配置项niws.loadbalancer.availabilityFilteringRule.filterCircuitTripped为true(未配置则默认为true),并且已经触发断路。
2.
服务的活动请求数 > 配置项niws.loadbalancer.availabilityFilteringRule.activeConnectionsLimit(未配则默认为Interge.MAX_VALUE)。
在AvailabilityFilteringRule的choose中无法选出服务的情况下,会调用父类PredicateBasedRule的choose,PredicateBasedRule采用先过滤后线性轮行方法选择服务,不过,用来判定的predicate还是AvailabilityPredicate,所以过滤用的判定规则和上面是一样的。
ZoneAvoidanceRule
可以发现在ZoneAvoidanceRule本身并没有重写choose方法,用的还是抽象父类PredicateBasedRule的choose。
上面记录过,PredicateBasedRule的choose本身使用的是predicate进行过滤。
看一下ZoneAvoidanceRule定义的predicate。
public class ZoneAvoidanceRule extends PredicateBasedRule { // 略 private CompositePredicate compositePredicate; public ZoneAvoidanceRule() { super(); ZoneAvoidancePredicate zonePredicate = new ZoneAvoidancePredicate(this); AvailabilityPredicate availabilityPredicate = new AvailabilityPredicate(this); compositePredicate = createCompositePredicate(zonePredicate, availabilityPredicate); } private CompositePredicate createCompositePredicate(ZoneAvoidancePredicate p1, AvailabilityPredicate p2) { return CompositePredicate.withPredicates(p1, p2) .addFallbackPredicate(p2) .addFallbackPredicate(AbstractServerPredicate.alwaysTrue()) .build(); } @Override public void initWithNiwsConfig(IClientConfig clientConfig) { ZoneAvoidancePredicate zonePredicate = new ZoneAvoidancePredicate(this, clientConfig); AvailabilityPredicate availabilityPredicate = new AvailabilityPredicate(this, clientConfig); compositePredicate = createCompositePredicate(zonePredicate, availabilityPredicate); } // 略 @Override public AbstractServerPredicate getPredicate() { return compositePredicate; } }
在这里的predicate主要用了两个,ZoneAvoidancePredicate,AvailabilityPredicate,都被复合进了CompositePredicate。
PredicateBasedRule的choose会去调用CompositePredicate的getEligibleServers来获取符合要求的服务。
而在getEligibleServers内部会对所有服务逐一调用复合进来的predicate(ZoneAvoidancePredicate,AvailabilityPredicate)的getEligibleServers。
public class CompositePredicate extends AbstractServerPredicate { private AbstractServerPredicate delegate; private List<AbstractServerPredicate> fallbacks = Lists.newArrayList(); private int minimalFilteredServers = 1; private float minimalFilteredPercentage = 0; @Override public boolean apply(@Nullable PredicateKey input) { return delegate.apply(input); } // 略 /** * Get the filtered servers from primary predicate, and if the number of the filtered servers * are not enough, trying the fallback predicates */ @Override public List<Server> getEligibleServers(List<Server> servers, Object loadBalancerKey) { List<Server> result = super.getEligibleServers(servers, loadBalancerKey); Iterator<AbstractServerPredicate> i = fallbacks.iterator(); while (!(result.size() >= minimalFilteredServers && result.size() > (int) (servers.size() * minimalFilteredPercentage)) && i.hasNext()) { AbstractServerPredicate predicate = i.next(); result 以上是关于撸一撸Spring Cloud Ribbon的原理-负载均衡策略的主要内容,如果未能解决你的问题,请参考以下文章