Java面试
Posted laidianjilu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java面试相关的知识,希望对你有一定的参考价值。
字节,数据类型,类型转换
基本数据类型 包装类
| 数据类型 | 关键字 | 包装类 | 字节数 | 范围 | 默认值 | |
|---|---|---|---|---|---|---|
| 数值型 | 整数型 | byte | Byte | 1 | -27 --(27-1),即-128--127。1字节 | 0 |
| short | Short | 2 | -215--215-1,即-32768--32767。2字节。 | |||
| int | Integer | 4 | -231--231-1,即-2147483648--2147483647。4字节 | |||
| long | Long | 8 | -263--263-1,即-9223372036854774808--9223372036854774807。8字节 | |||
| 浮点型 | float | Float | 4 | 单精度 -3.40292347E+38到+3.40292347E+38 | double0.0 | |
| double | Double | 8 | 双精度 -1.79E+308~--1.79E+308 | |||
| 布尔型 | boolean | Boolean | 1(位) | false | ||
| 字符型 | char | Character | 2 | ‘/u0000’ |
1. 8种基本数据类型及其字节数:基本数值
引用数据类型:数组 接口 类:和内存有关 默认值 null
2. 类型转换:类型大的必须强制转换为类型小的。
-
0~255 int自动转为byte。>255 int强制转换为byte.char和int自动转换,通过int获取字符对应的系统编码A65 -Z90;a97-z122 ‘0’48 ‘9’57
-
float f=3.4;是否正确?答:不正确。小数是默认类型是double。,因此需要强制类型转换float f =(float)3.4; 或者写成float f =3.4F;否则精度损失。
-
有字符串,所有类型先变为字符串,再进行连接操作。
3. Boolean表示true,false.(别的编码语言用0表示true,非0表示false,Java不存在。)
4. 实线表示自动转换时不会造成数据丢失,虚线则可能会出现数据丢失问题。
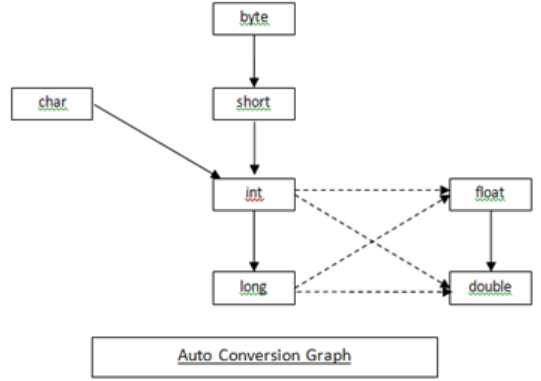
5. +=是Java语法规定运算符,会进行特殊转换,编译通过。 
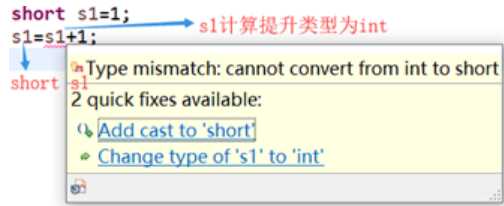
-
char,使用Unicode编码格式,可以存储常见汉字
-
System.out.println(3*0.1==0.3);//false 浮点数精度损失。
-
为什么基本数据类型转包装类?
基本数据类型不是面向对象的(没有属性、方法),不方便操作。
-
自动装箱(autoboxing)和自动拆箱(autounboxing)JDK1.5实现基本数据类型和包装类之间的自动转换。
-
switch(expr)
expr可以是byte、short、char、int。
jdk1.5,引入枚举类型(enum)枚举, JDK 1.7,引入(String)字符串。
== equals()
new Integer,int,Integer.valueOf()
对象
public class Square { long width; public` `Square(``long` `l) { width = l; } public` `static` `void` `main(String arg[]) { ``Square a, b, c; ``a = ``new` `Square(42L); ``b = ``new` `Square(42L); ``c = b; ``long` `s = 42L; ``} }
这题考的是引用和内存。 //声明了3个Square类型的变量a, b, c //在stack中分配3个内存,名字为a, b, c Square a, b, c; //在heap中分配了一块新内存,里边包含自己的成员变量width值为48L,然后stack中的a指向这块内存 a = ``new` `Square(42L); //在heap中分配了一块新内存,其中包含自己的成员变量width值为48L,然后stack中的b指向这块内存 b = ``new` `Square(42L); //stack中的c也指向b所指向的内存 c = b; //在stack中分配了一块内存,值为42 long` `s = 42L;
==
a) 基本类型,比较的是值;引用类型,比较对象地址;不能比较没有父子关系的两个对象
equals():
a) 系统类一般override equals(字符串内容,值),比较的是值。
b) 自定义类调用父类的equals (Object),而Object.equals(地址)的实现代码 this == obj,比较的是对象地址是否相同;自定义类需要override equals()
Object的==和equals比较的都是地址,作用相同
String a=”aaa”; String b=”aaa”; a==b true java底层提供了字符串池(字符串数组)
定义一个变量,首先查找池,字符串可以实现池数据的自动保存
new String两块内存空间,字符串常量定义的匿名对象将成为垃圾空间
new在堆内存中开辟新的对象空间,新对象不会自动保存到字符串池。手工入池new String().intern()
“”空字符串 null:无实例化
.trim():不能消除中间空格
值传递与引用传递
-
值传递与引用传递的区别:传递的内容,如果是个值,就是值传递。如果是个引用,就是引用传递。
基本数据类型传值,将实参复制一份传递给形参,形参 实参 两份;
引用类型传引用,形参和实参指向同一个内存地址(同一个对象),形参实参 一份。调用函数时将实际参数的地址直接传递到函数
-
Java没有引用传递。
对象作为参数,值是对象引用的副本,指向同一个对象。内容可以改变,但对象引用不变。大量的Wrapper类(将需要【通过方法调用】修改的引用置于一个Wrapper类中,再将Wrapper对象传入方法)
String, Integer, Double等immutable的类型特殊处理,可以理解为传值,最后的操作不会修改**实参对象。
如何保证自己创建的类是immutable类 . 一成不变的
-
所有成员都是private final。
-
不提供对成员的改变方法,setXX
-
确保所有的方法不会被重写。手段有两种:使用final Class(强不可变类),或者将所有类方法加上final(弱不可变类)。
-
如果某一个类成员不是原始变量(例如int,double)或者不可变类,必须通过在成员初始化或者使用get方法时要通过深度拷贝方法,来确保类的不可变。
-
String
String 和StringBuilder、StringBuffer 的区别?
相同点:
储存和操作字符串,
使用final修饰,都属于终结类不能派生子类,
操作的相关方法类似,例如,获取字符串长度等;
不同点:
String是只读字符串(字符数组长度不可变),字符串内容不变,String对象不变,一个字符串需要一个String对象来表示。Jdk1.8保存字符数组private final char[] value;jdk1.9保存字节数组private final byte[] value;
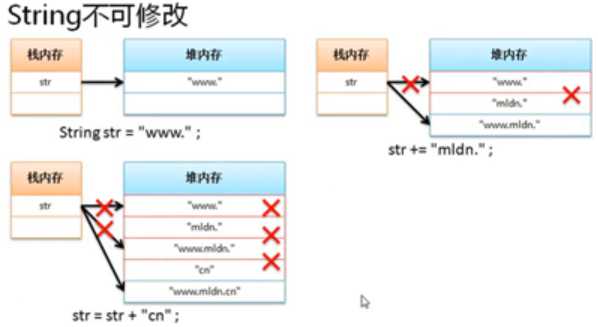
字符串内容不变,只变引用。将带来大量垃圾空间。开发中String类不要进行内容的频繁修改。
而StringBuffer和StringBuilder类可以直接修改字符串对象,地址值变。
| StringBuilder jdk1.5 | StringBuffer |
|---|---|
| 方法相同 append() | |
| 单线程使用,效率高 | synchronized修饰 |
三者类型不一样,无法使用equals()方法比较其字符串内容!
String+ 字符串连接,接后得到的字符串在静态存储区中是早已存在的。比StringBuffer / StringBuilder对象的append方法性能更好
对象(常量)池:
目的:实现数据的共享处理
静态常量池:.class加载时,常量
运行时常量池:.class加载后,变量
String两种实例化对象的区别:
-
直接赋值:只产生一个实例化对象,可以自动保存到对象池中,可以实现对象重用
直接赋值指的是:一个匿名对象被引用。
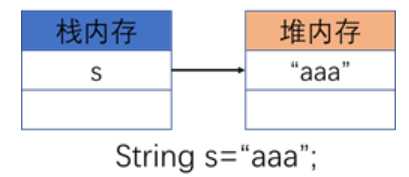
String s=new String("aaa");//构造方法实例化
System.*out*.println("aaa".equals(s));//true。aaa是String匿名对象,而不是字符串常量。
接收用户输入的字符串方法,null.equals():运行时异常NullPointerException。匿名对象一定是开辟好堆内存空间的对象,““.equals()。
-
构造方法: 产生两个实例化对象,不可以自动保存到对象池中,无法实现对象重用
-
直接赋值的好处:只开辟一块堆内存空间,产生一个实例化对象。数据自动保存到对象池中。实现同一个数据的共享操作。
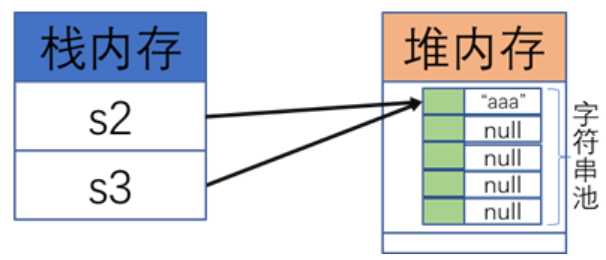
String s2="aaa";//直接赋值
String s3="aaa";
System.out.println(s2==s3);//地址判断 true,两个对象指向同一个堆内存空间。 匿名对象自动保存到字符串常量池中。
构造方法的存在为了满足设计的结构要求,匿名对象将成为垃圾空间。
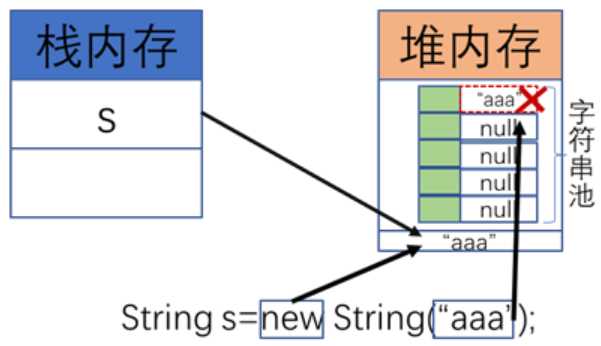
String s=new String("aaa");//构造方法实例化
String s2="aaa";//直接赋值
System.out.println(s==s2);// false,比较地址。直接赋值自动入池。实例化new不会入池。
System.out.println(s.equals(s2));//true,系统类比较内容
String s2="aaa";//直接赋值
String s4=new String("aaa").intern();//实例化方法手工入池public String intern();
System.out.println(s2==s4);//地址判断 true
对象(常量)池 分类
1. 静态常量池 .class加载时,分配数据
2. 运行时常量池 .class加载时,变量常量池
String s2="aaa";//直接赋值
String s3="a"+"a"+"a";//程序加载自动处理字符串连接。整体存在,不会产生内存垃圾。
System.out.println(s2==s3);// True地址判断,常量数据(都是匿名对象)。数据加载时,值相同。
String value="a"; String s4="a"+"a"+value; //程序加载时不确定value变量值。
System.out.println(s2==s4);//地址判断 false s3在静态常量池,s4在运行时常量池。
重载和重写
方法重载和方法重写(覆盖)的区别
public static void main(String[] args)
| 英文 | 位置不同 | 作用不同 | ||
|---|---|---|---|---|
| 重载 | overload | 同一类 | 为一种行为提供多种实现方式(实现功能相似),提高可读性 | 编译时多态 |
| 重写 | override | 父子类 | 父类方法无法满足子类的要求,子类通过方法重写满足要求。 | 运行时多态 |
| 修饰符 | 返回值 | 方法名 | 参数 | 抛出异常 | 特别的 | |
|---|---|---|---|---|---|---|
| 重载 | 无关 | 无关 | 相同 | 不同 类型个数顺序 | 无关 | 与返回类型无关 |
| 重写 | 》 | 《父类 | 相同 | 相同 | 《 | 父类方法修饰符为private,final,不能被override |
抽象类和接口的区别
| 抽象类 | 接口 interface | |
|---|---|---|
| 成员 | 抽象类无限制 0-all抽象方法。成员变量/常量 | 抽象类的一种特例。所有方法为public abstract类型,都是抽象方法且只有声明,成员变量为public static final,是常量 |
| 添加新方法 | 抽象类直接添加,提供默认的实现 | 接口的实现类必须改变 |
| 构造方法 | 有,不可实例化 | 无,不可实例化 |
| 类 | extends 一个抽象类,代码实现与重用,怎么做,接口与实现类 is-a关系。 | implements多个接口,功能规范,做什么,接口与实现类 has-a 关系。 |
| 抽象类 | 无限制 0-all 接口方法 |
所有抽象方法必须被重写。否则,该子类也必须声明为抽象类。
理解:假设不重写所有抽象方法,则类中可能包含抽象方法。那么创建对象后,调用抽象的方法,没有意义。
什么时候使用抽象类和接口
-
方法有默认实现,用抽象类。
-
多重继承,用接口。
-
基本功能不断改变,用抽象类。
关键字
https://docs.oracle.com/javase/tutorial/java/nutsandbolts/_keywords.html
关键字都是小写的
非关键字:const和goto是java的保留字(为java预留的关键字,升级版本中可能作为关键字)。true,false,null, friendly,sizeof 显示常量值
static
public class Base
{
private String baseName = "base";
public Base()
{
callName();
}
public void callName()
{
System. out. println(baseName);
}
static class Sub extends Base
{
private String baseName = "sub";
public void callName()
{
System. out. println (baseName) ;
}
}
public static void main(String[] args)
{
Base b = new Sub();
}
}
1.首先,需要明白类的加载顺序。
(1) 父类静态代码块(包括静态初始化块,静态属性,但不包括静态方法)
(2) 子类静态代码块(包括静态初始化块,静态属性,但不包括静态方法 )
(3) 父类非静态代码块( 包括非静态初始化块,非静态属性 )
(4) 父类构造函数
(5) 子类非静态代码块 ( 包括非静态初始化块,非静态属性 )
(6) 子类构造函数
其中:类中静态块按照声明顺序执行,并且(1)和(2)不需要调用new类实例的时候就执行了(意思就是在类加载到方法区的时候执行的)
2.其次,需要理解子类覆盖父类方法的问题,也就是方法重写实现多态问题。
Base b = new Sub();它为多态的一种表现形式,声明是Base,实现是Sub类, 理解为 b 编译时表现为Base类特性,运行时表现为Sub类特性。
当子类覆盖了父类的方法后,意思是父类的方法已经被重写,题中 父类初始化调用的方法为子类实现的方法,子类实现的方法中调用的baseName为子类中的私有属性。
由1.可知,此时只执行到步骤4.,子类非静态代码块和初始化步骤还没有到,子类中的baseName还没有被初始化。所以此时 baseName为空。 所以为null。
不管是哪种状态都会调用Base构造器执行 callName()方法;
执行方法时,由于多台表现为子类特性,所以会先在子类是否有 callName();
而此时子类尚未初始化(执行完父类构造器后才会开始执行子类),
如果有就执行,没有再去父类寻找
如果把父类 callName()改为 callName2(),则会输出base
final
final、finally、finalize
final
-
属性不可变,变量要赋初值,基本数据类型,数据值不变,引用数据类型: 栈内存中的引用不可变,所指向的堆内存中对象的属性值可变;
-
方法不可override,只能overload;
-
无子类(类不可继承,成员方法为final方法),如 String类、Math类;对象引用地址不变,值可变。( private 方法隐式为final方法 )
class Test {
public static void main(String[] args) {
• final Dog dog = new Dog("欧欧");
• dog.name = "美美";//正确
• dog = new Dog("亚亚");//错误
}
}
finally 异常处理,执行清除操作,关闭物理连接(IO流、数据库连接、Socket连接)
finalize garbage collector 内存里清除对象前清理工作;Object定义, JVM调用
Object
getClass 当前运行的class对象
hashCode equals 比较
toString 输出字符串
clone
notify notifyall wait
finalize 垃圾回收前操作
main()
public static void main(String[] args) {}
public:访问权限。作为一切的开始点的主方法一定是公共的。
static: main()由类直接调用。程序的执行通过类名称完成。
void :起点一旦开始就没有返回的可能。
Main:系统定义的方法名称
String[] args: 程序启动参数的接收。
键盘输入
Scanner input=new Scanner(System.in); String s=input.nextLine(); input.close() BufferedReader bf=new BufferedReader(new InputStreamReader(System.in)); String s=input.readLine();
数据结构
哈希表
一个元素为链表的数组
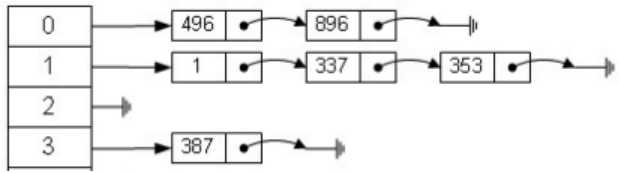
平衡二叉树
二叉搜索(查找,排序)树:空树/ 左<根<右
红黑树
-
红黑树是二叉搜索树。
-
根节点是黑色。
-
每个叶子节点都是黑色的空节点(NIL节点)。
-
每个红色节点的两个子节点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
-
从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点(每一条树链上的黑色节点数量(称之为“黑高”)必须相等)。
集合
集合:存储数据(对象/变量)的容器。数据结构不同,但都能实现增删,判断contains(),isEmpty(),获取iterator(),容量size(),交集 retainAll()
迭代器:集合类的数据结构不同,遍历方式不同,没有统一的迭代器类。获取元素是集合必备的一个功能。所以定义迭代器接口,在具体子类中以内部类的方式实现迭代器接口的方法。
-
public interface Collection<E> extends Iterable<E>{}
-
public interface Iterable<T>{ Iterator<T> iterator();}
-
public interface Iterator<E> { boolean hasNext(); E next(); void remove();}
-
Iterator在 ArrayList里以内部类的方式实现。
private class Itr implements Iterator<E> { int cursor; // index of next element to return int lastRet = -1; // index of last element returned; -1 if no such int expectedModCount = modCount; Itr() {} public boolean hasNext() { return cursor != size; } @SuppressWarnings("unchecked") public E next() { checkForComodification(); int i = cursor; if (i >= size) throw new NoSuchElementException(); Object[] elementData = ArrayList.this.elementData; if (i >= elementData.length) throw new ConcurrentModificationException(); cursor = i + 1; return (E) elementData[lastRet = i]; } public void remove() { if (lastRet < 0) throw new IllegalStateException(); checkForComodification(); try { ArrayList.this.remove(lastRet); cursor = lastRet; lastRet = -1; expectedModCount = modCount; } catch (IndexOutOfBoundsException ex) { throw new ConcurrentModificationException(); } } }
Collection/Array 长度,数据类型(不同类型,值类型与引用类型)
-
1:长度的区别
-
-
数组的长度固定
-
集合的长度可变
-
-
2:内容不容
-
-
数组存储的是同一种类型的元素
-
集合可以存储不同类型的元素(但是一般不这样干..)
-
-
3:元素的数据类型
-
-
数组可以存储基本数据类型,也可以存储引用类型
-
集合只能存储引用类型(你存储的是简单的int,它会自动装箱成Integer)
-
List/Set 有序 重复 (角标)
List 存储顺序与取出顺序一致,可重复。
set 无序,不可重复。
Vector/ArrayList/LinkedList 数据结构(双向链表) 安全性 增删改查(快速随机访问) 内存空间占用(list结尾预留空间/ 单个元素占用空间大)
-
ArrayList
-
-
底层数据结构是数组。线程不安全
-
-
LinkedList
-
-
底层数据结构是链表。线程不安全
-
-
Vector
-
-
底层数据结构是数组。线程安全
-
Vector/ArrayList 数组/功能/长度 互用 ;版本 /安全/长度需增长时,Vector默认增长一倍,ArrayList增长50%
HashSet(hashCode,equals)/ TreeSet(Comparable compareTo/Comparator compare ) 数据结构(哈希表,二叉树) 安全性 顺序
-
HashSet集合
-
-
A:底层数据结构是哈希表(是一个 元素为链表的数组)
-
-
TreeSet集合
-
-
A:底层数据结构是红黑树(是一个自平衡的二叉树)
-
B:保证元素的排序方式
-
-
LinkedHashSet集合
-
-
A::底层数据结构由哈希表和链表组成。
-
Map/Collection 元素个数(映射关系) 增加() 取出()
HashTable/ HashMap/ TreeMap 数据结构(哈希表/哈希表/红黑树) 安全 null键 排序
HashTable/ HashMap
-
线程是否安全:HashTable 是线程安全的;HashTable 内部的方法基本都经过 synchronized 修饰。 HashMap 是非线程安全的,。(如果你要保证线程安全的话就使用 ConcurrentHashMap );
-
效率: HashTable 基本被淘汰,不要在代码中使用它;因为线程安全的问题,HashMap效率高
-
对Null key 和Null value的支持:HashTable 中 put 进的键值只要有一个 null,直接抛出 NullPointerException。 HashMap 中,只有一个null键,任意值可为null。
-
初始容量大小和每次扩充容量大小的不同 : ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为 11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来 的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充 为2的幂次方大小(HashMap 中的 tableSizeFor() 方法保证)。也就是说 HashMap 总 是使用2的幂作为哈希表的大小
-
底层数据结构: JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
-
Hashtable继承Dictionary类,HashMap实现Map接口
Collections 工具类的sort()
元素可比较 implements Comparable
集合可比较 参数是Comparator接口的子类型,需要重写compare方法实现元素的比较,通过接口注入比较元素大小
TreeMap,TreeSet,HashMap 底层都用到红黑树
多线程
java.lang.ThreadLocal的作用和原理
线程共享资源困难, 为每个线程创建资源的副本。在ThreadLocal类中有一个Map,用于存储每一个线程的变量的副本
创建线程
extends java.lang.Thread @Override run()
implements java.lang.Runnable @Override run()
implements Callable<Integer> @Override call()
start()/run()
-
run():仅仅是封装被线程执行的代码,直接调用是普通方法 -
start():首先启动了线程,然后再由jvm去调用该线程的run()方法。
同时启动所有线程
for循环创建线程对象,run()里面:while循环调用 wait()方法,所有线程(数量大小)等待;调用notifyAll(), 同时启动所有线程。
线程生命周期
-
新建(new Thread)
-
就绪(runnable) 线程启动,排队等待CPU资源
-
运行(running) 获得CPU资源,执行任务
-
死亡(dead)
-
自然终止:run()结束
-
异常终止:stop() 被杀死,
-
interrept 设终止标志, 不会对线程的状态造成影响,让线程自己终止 检查该线程是否被中断
-
-
-
堵塞(blocked)
-
让出CPU,暂停执行
-
正在睡眠:sleep(long t) 。t时间后过去进入阻塞。不会释放锁 ,catch InterruptedException
-
yield() 优先级;进入就绪,没有异常;sleep()方法比yield()方法(跟操作系统相关)具有更好的可移植性
-
会让别的线程先执行,不确保会真正让出,少用
-
-
正在等待:wait()释放锁。(调用motify()方法回到就绪状态)
-
必须 synchronized方法或者synchronized代码块 中,由锁对象调用
-
-
被另一个线程所阻塞:调用suspend()方法暂停。(调用resume()方法恢复)
-
线程通信
final void wait() 线程等待
final void notify() JVM确定唤醒多个线程中的一个(不是按优先级)
final void notifyAll() 唤醒同一个对象上所有调用wait()方法的线程,不是给线程一个对象锁,而是让线程竞争。
JDK 1.5通过Lock接口提供了显式(explicit)的锁机制,加锁lock();解锁unlock();提供newCondition()产生用于线程之间通信的Condition对象;
信号量(semaphore)机制,限制访问共享资源的线程数量。访问前,acquire();访问后release()。
join() 该等线程执行完毕,执行别的线程
volatile关键字
弱的同步机制,确保将变量的更新操作通知到其他线程 ,将本地内存变量值立即刷新到主内存。
实现线程同步
同步代码块:synchronized (同步锁) { }
同步锁可以是三种,1、this 2、 共享资源 3、 字节码文件对象
同步方法:public synchronized void makeWithdrawal(int amt) { }
同步锁,默认的是this
好处:解决了线程安全问题;缺点:性能下降,可能会带来死锁
同步锁
每个对象只有一个内置锁,只被单个线程获得,一个线程可以获得多个对象锁。当程序运行到非静态的synchronized同步方法(只能是同步方法)上时,自动获得当前实例(this实例)有关的锁,对象锁起作用。获得一个对象的锁也称为获取锁、锁定对象、在对象上锁定或在对象上同步。
释放锁:持锁线程退出了synchronized同步方法或代码块。
synchronized 和java.util.concurrent.locks.Lock的异同
synchronized关键字 将对象/方法标记为同步。
Lock 能完成synchronized的功能
Lock 有比synchronized 更精确的线程语义和更好的性能。
synchronized 会自动释放锁,而Lock 手动释放,并且必须在finally 块中释放
悲观锁和乐观锁
拿到数据就上锁 Java中synchronized和ReentrantLock等独占锁就是悲观锁思想的实现。
无锁模式。 使用版本号机制( version字段 表示数据被修改的次数)和CAS算法( compare and swap )判断有没有人更新数据
-
内存值 V
-
进行比较的值 A
-
拟写入的新值 B
当且仅当 V == A时,CAS通过原子方式set V=B,否则不会执行任何操作。循环操作,直到成功
synchronized和lock区别以及volatile和synchronized的区别
可重入锁与非可重入锁的区别
多线程是解决什么问题的
线程池解决什么问题
线程池的原理
线程池使用时的注意事项
AQS原理
ReentranLock源码,设计原理,整体过程
IO流
序列化
对象内容流化,进行读写操作,或对象网络传输。 实现Serializable接口,该接口是一个标识性接口
构造输出流对象, writeObject(Object obj) 实现对象写出。
构造输入流对象, readObject(Object obj) 实现对象从流中读取。
流
字节流继承于InputStream、OutputStream,
字符流继承于Reader、Writer。
BIO、NIO和AIO
Java BIO: 同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
Java NIO: 同步非阻塞,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
Java AIO: 异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理。
NIO比BIO的改善之处是把一些无效的连接挡在了启动线程之前,减少了这部分资源的浪费(因为我们都知道每创建一个线程,就要为这个线程分配一定的内存空间)
AIO比NIO的进一步改善之处是将一些暂时可能无效的请求挡在了启动线程之前,比如在NIO的处理方式中,当一个请求来的话,开启线程进行处理,但这个请求所需要的资源还没有就绪,此时必须等待后端的应用资源,这时线程就被阻塞了。
适用场景分析:
BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解,如之前在Apache中使用。
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持,如在 nginx,Netty中使用。
AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持,在成长中,Netty曾经使用过,后来放弃。
网络编程
IP 通信实体(计算机,路由器)的地址 IPV4,IPV6
端口 区分应用程序
OSI七层模型和TCP/IP模型
OSI(Open System Interconnection),开放式系统互联参考模型
网络层的IP协议和传输层的TCP协议
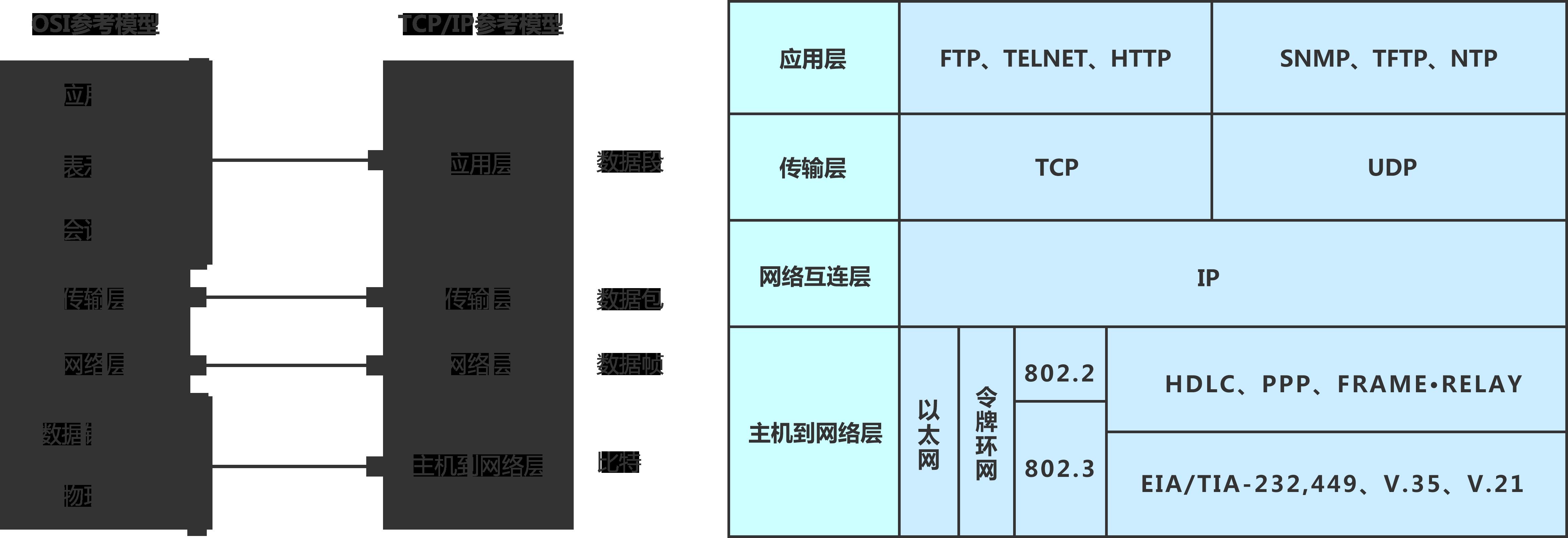
| OSI七层模型 | TCP/IP概念模型 | 功能 | TCP/IP协议族 |
|---|---|---|---|
| 应用层 | 应用层 | 文件传输,电子邮件,文件服务,虚拟终端 | HTTP,DNS,Telnet |
| 表示层 | 数据格式化,代码转换,数据加密 | 无 | |
| 会话层 | 解除/建立与别的接点的联系。 | 无 | |
| 传输层 | 传输层 | 提供端对端的接口 | TCP ,UDP |
| 网络层 | 网络层 | 为数据包选择路由 | IP |
| 数据链路层 | 链路层 | 传输有地址的帧和错误检测功能 | SLIP |
| 物理层 | 以二进制数在物理媒体上传输数据 | ISO2110 ,IEEE802 |
TCP与HTTP
-
一个TCP连接可以发多少个HTTP请求
§ 一次http请求结束后,不会断开TCP 连接,只有在请求报头中声明 Connection: close 才会在请求完成后关闭连接
§ 多个 HTTP 请求可以在同一个 TCP 连接中并行进行。http2的Multiplexing多路传输特性实现。
§ Chrome 最多允许对同一个 Host 建立六个 TCP 连接。不同的浏览器有一些区别。
收到的 html 如果包含几十个图片标签,这些图片是以什么方式、什么顺序、建立了多少连接、使用什么协议被下载下来的呢?
如果图片都是 HTTPS 连接并且在同一个域名下,那么浏览器在 SSL 握手之后会和服务器商量能不能用 HTTP2
如果能的话就使用 Multiplexing 功能在这个连接上进行多路传输。不过也未必会所有挂在这个域名的资源都会使用一个 TCP 连接去获取,但是可以确定的是 Multiplexing 很可能会被用到。
如果发现用不了 HTTP2 呢?或者用不了 HTTPS(现实中的 HTTP2 都是在 HTTPS 上实现的,所以也就是只能使用 HTTP/1.1)
那浏览器就会在一个 HOST 上建立多个 TCP 连接,进行HTTP单请求。连接数量的最大限制取决于浏览器设置,这些连接会在空闲的时候被浏览器用来发送新的请求,如果所有的连接都正在发送请求呢?那其他的请求就只能等等了。
-
TCP和UDP
TCP 两者连接再传输。 流量控制、拥塞控制,检验数据按序到达 。UDP 知道对方地址就传输
-
TCP的路由选择只发生在建立连接的时候,而UDP的每个报文都要进行路由选择
-
TCP是可靠性传输,他的可靠性是由超时重发机制实现的,而UDP则是不可靠传输
-
UDP因为少了很多控制信息,所以传输速度比TCP速度快
-
TCP适合用于传输大量数据,UDP适合用于传输小量数据
-
java.net包中。与TCP对应的是服务器的ServerSocket和客户端的Socket,与UDP对应的是DatagramSocket。
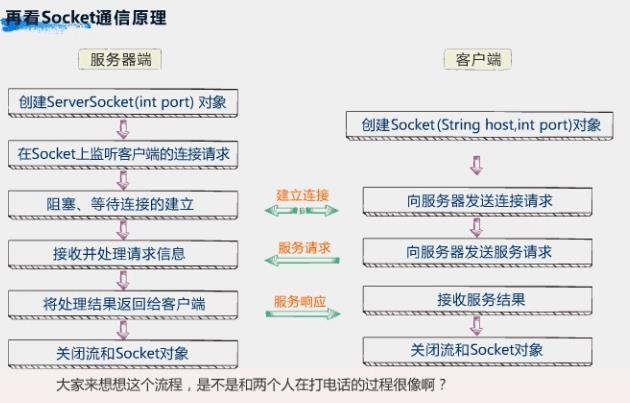
Socket
描述IP地址和端口 应用层-传输层间
异常
异常声明
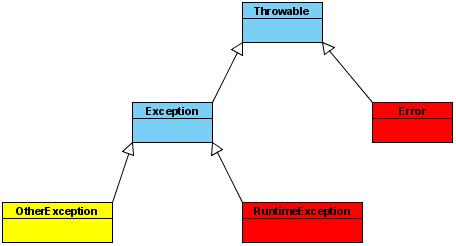
ClassCastException(类转换异常)
比如 Object obj=new Object(); String s=(String)obj;
IndexOutOfBoundsException(下标越界异常)
NullPointerException(空指针异常)
ArrayStoreException(数据存储异常,操作数组时类型不一致)
BufferOverflowException(IO操作时出现的缓冲区上溢异常)
InputMismatchException(输入类型不匹配异常)
ArithmeticException(算术异常)
以上这些异常都是程序在运行时发生的异常,所以不需要在编写程序时声明
OutOf MemoryError(OOM 错误)的原因
finally return
先保留return结果,再调用finally,再返回return结果
异常处理,会逐层往上抛
java虚拟机
①Java内存区域、②虚拟机垃圾算法、③虚拟机垃圾收集器、④JVM内存管理、⑤JVM调优、⑥Java类加载机制
javac编译.java文件为.class文件。Java 运行.class文件
.class字节码文件不能直接运行,由JVM解析成对应操作系统的机器码文件
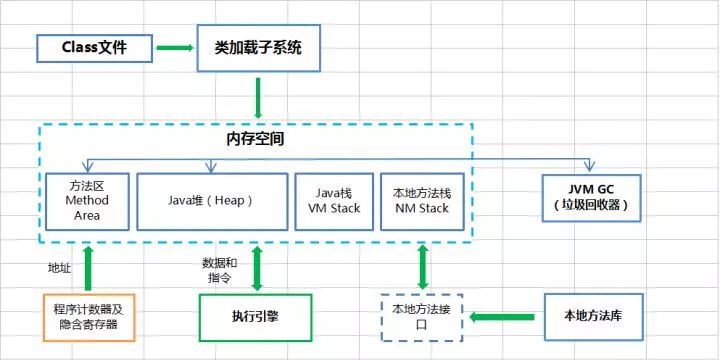
VM运行时,数据区包含:虚拟机栈,堆,方法区,本地方法栈,程序计数器,其中,堆和方法区是线程共享的,虚拟机栈和程序计数器是线程私有的。
方法区 被虚拟机加载的类元数据信息 在方法区中,存储了每个类的信息(包括类的名称、方法信息、字段信息)、静态变量、常量以及编译器编译后的代码等, 线程共享。
堆Heap :存放对象实例 线程共享 所有的对象都在堆区上分配内存,是线程之间共享的
虚拟机栈 VM Stacks:虚拟机栈描述的是Java方法执行的内存结构:每个方法被执行的时候都会同时创建一个栈帧(Stack Frame)用于存储局部变量表、操作栈、动态链接、方法出口等信息 线程私有
本地方法栈native method stack:本地方法栈则是为虚拟机使用到的Native方法服务。
PC 寄存器(程序计数器) program counter register 程序计数器是一个比较小的内存区域,用于指示当前线程所执行的字节码执行到了第几行,是线程私有的
方法区 jdk1.7以前的PermGen(永久代),替换成Metaspace(元空间)
-
原本永久代存储的数据:符号引用(Symbols)转移到了native heap;字面量(interned strings)转移到了java heap;类的静态变量(class statics)转移到了java heap
-
Metaspace(元空间)存储的是类的元数据信息(metadata)
-
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。
-
替换的好处:一、字符串存在永久代中,容易出现性能问题和内存溢出。二、永久代会为 GC 带来不必要的复杂度,并且回收效率偏低
类加载过程
-
1、通过
java.exe运行.class,随后被加载到JVM中,元空间存储着类的信息(包括类的名称、方法信息、字段信息..)。 -
2、然后JVM找到主函数入口(main),为main函数创建栈帧,开始执行main函数
-
3、main函数的第一条命令是
Java3yjava3y=newJava3y();就是让JVM创建一个Java3y对象,但是这时候方法区中没有Java3y类的信息,所以JVM马上加载Java3y类,把Java3y类的类型信息放到方法区中(元空间) -
4、加载完Java3y类之后,Java虚拟机做的第一件事情就是在堆区中为一个新的Java3y实例分配内存, 然后调用构造函数初始化Java3y实例,这个Java3y实例持有着指向方法区的Java3y类的类型信息(其中包含有方法表,java动态绑定的底层实现)的引用
-
5、当使用
java3y.setName("Java3y");的时候,JVM根据java3y引用找到Java3y对象,然后根据Java3y对象持有的引用定位到方法区中Java3y类的类型信息的方法表,获得setName()函数的字节码的地址 -
6、为
setName()函数创建栈帧,开始运行setName()函数
-Xmx:最大堆大小
-Xms:初始堆大小
-Xmn:年轻代大小
-XXSurvivorRatio:年轻代中Eden区与Survivor区的大小比值
年轻代5120m, Eden:Survivor=3,Survivor区大小=1024m(Survivor区有两个,即将年轻代分为5份,每个Survivor区占一份),总大小为2048m。
-Xms初始堆大小即最小内存值为10240m
GC
JVM是使用一组称为OopMap的数据结构,来存储所有的对象引用(这样就不用遍历整个内存去查找了,空间换时间)。 并且不会将所有的指令都生成OopMap,只会在安全点上生成OopMap,在安全区域上开始GC。
回收堆前,
判断死去的对象。
-
引用计数法-->这种难以解决对象之间的循环引用的问题
-
可达性分析算法-->主流的JVM采用的是这种方式
回收算法
-
标记-清除算法
-
复制算法
-
标记-整理算法
-
分代收集算法
垃圾收集器
垃圾收集器:
-
Serial收集器
-
ParNew收集器
-
Parallel Scavenge收集器
-
Serial Old收集器
-
Parallel Old收集器
-
CMS收集器
-
G1收集器
设计模式
JavaWeb
JSP 动态include 与静态include
AJAX
数据库连接池
Druid,C3P0,DBCP 数据库连接池
Druid: 自带监控页面,实时监控应用的连接池情况
https://mp.weixin.qq.com/s/jzx7j0anBeyHKH8pThCQNQ
Json
是什么
JSON:javascript Object Notation 【JavaScript 对象表示法】
Js提供的一种数据交换格式
Json语法
客户端与服务端的交互数据格式
属性名:双引号
属性值:null, 数字(整数或浮点数),字符串(在双引号中),逻辑值(true 或 false),数组(在方括号中),对象(在花括号中)
数组
var employees = [
{ "firstName":"Bill" , "lastName":"Gates" },
{ "firstName":"George" , "lastName":"Bush" },
{ "firstName":"Thomas" , "lastName": "Carter" }
];
对象
var obj = {
age: 20,
str: "AAA",
method: function () {
alert("我爱学习");
}
};
163.Java中的日期和时间:
1 ) 如何取得年月日、小时分钟秒?
2 ) 如何取得从1970年1月1日0时0分0秒到现在的毫秒数?
3 ) 如何取得某月的最后一天?
4 ) 如何格式化日期?
答:操作方法如下所示:
1 ) 创建java.util.Calendar 实例,调用其get()方法传入不同的参数即可获得参数所对应的值
2 ) 以下方法均可获得该毫秒数:
Calendar.getInstance().getTimeInMillis();
time.getActualMaximum(Calendar.DAY_OF_MONTH);
4 ) 利用java.text.DataFormat 的子类(如SimpleDateFormat类)中的format(Date)方法可将日期格式化。
164.打印昨天的当前时刻。
Calendar cal = Calendar.getInstance(); cal.add(Calendar.DATE, -``1``); System.out.println(cal.getTime());
反射机制实现类
java.lang.reflect包
1)Class类:代表一个类
2)Field 类:代表类的成员变量(属性)
3)Method类:代表类的成员方法
4)Constructor 类:代表类的构造方法
5)Array类:提供了动态创建数组,以及访问数组的元素的静态方法
Class
获取与类相关的信息
| 方 法 | 示 例 |
|---|---|
| 对象名 .getClass() | String str="bdqn";Class clazz = str.getClass(); 类名 |
| 对象名 .getSuperClass() | Student stu = new Student();Class c1 = stu.getClass();Class c2 = stu.getSuperClass(); 父类 |
| Class.forName() | Class clazz = Class.forName("java.lang.Object");Class.forName("oracle.jdbc.driver.OracleDriver"); |
| 类名.class | 类名.classClass c2 = Student.class;Class c2 = int.class |
| 包装类.TYPE | 包装类.TYPEClass c2 = Boolean.TYPE; |
167.反射的使用场合和作用、及其优缺点
编译无法确定对象或类,只能在运行时确定
jvm加载访问代码,获取类内部信息 (属性,方法,构造)
缺点:解释操作,慢,应用在对灵活性和扩展性要求很高的系统框架上,普通程序不建议使用。会模糊程序内部逻辑,复杂
面向对象设计的七大设计原则详解
设计目标:
开闭原则、The Open-Closed Principle ,OCP
软件实体(模块,类,方法等)应该对扩展开放,对修改关闭。
某模块被其他模块调用,如果该模块的源代码不允许修改,则该模块修改关闭的。
不变的部分加以抽象成不变的接口
通过对接口的不同实现以及类的继承行为等为系统增加新的或改变系统原来的功能
设计过程中,通过对模块功能的抽象(接口定义),模块之间的关系的抽象(通过接口调用),抽象与实现的分离(面向接口的程序设计)
里氏代换原则、Liskov Substitution Principle ,LSP
出现if/else之类对派生类类型进行判断的条件。
代码中使用基类的地方用它的派生类所代替,代码还能正常工作。 子类可以扩展父类的功能,但不能改变父类原有的功能。
重构违反LSP的设计:新的抽象类C,作为两个具体类的基类,将A,B的共同行为移动到C中来解决问题。 从B到A的继承关系改为关联关系。
迪米特原则 Law of Demeter ,LoD Least Knowledge Principle 高内聚低耦合
1)一个软件实体应当尽可能少地与其他实体发生相互作用。
2)每一个软件单位对其他的单位都只有最少的知识,而且局限于那些与本单位密切相关的软件单位。
设计方法:
单一职责原则、
**一个类存在多个使其改变的原因,那么这个类就存在多个职责。 ** 这个接口包含了2个职责:第一个是连接管理(dial,hangup);另一个是数据通信(send,recv)。很多情况下,这2个职责没有任何共通的部分,它们因为不同的理由而改变,被不同部分的程序调用。所以它违反了SRP原则。
接口分隔原则、Interface Segregation Principle ,ISP
使用多个专门的接口比使用单一的总接口总要好。
-
一个类对一个类的依赖应该建立在最小的接口上
-
建立单一接口,不要建立庞大臃肿的接口
-
尽量细化接口,接口中的方法尽量少
多重继承实现
关联实现
单一职责原则和接口分隔原则的区别
单一职责强调的是接口、类、方法的职责是单一的,强调职责,方法可以多,针对程序中实现的细节;
接口分隔原则主要是约束接口,针对抽象、整体框架。
依赖倒置原则、Dependency Inversion Principle ,DIP
A. 高层模块不应该依赖于低层模块,二者都应该依赖于抽象 B. 抽象不应该依赖于细节,细节应该依赖于抽象 C.针对接口编程,不要针对实现编程。
依赖:在程序设计中,如果一个模块a使用/调用了另一个模块b,我们称模块a依赖模块b。 高层模块与低层模块:往往在一个应用程序中,我们有一些低层次的类,这些类实现了一些基本的或初级的操作,我们称之为低层模块;另外有一些高层次的类,这些类封装了某些复杂的逻辑,并且依赖于低层次的类,这些类我们称之为高层模块。 依赖倒置(Dependency Inversion): 面向对象程序设计相对于面向过程(结构化)程序设计而言,依赖关系被倒置了。因为传统的结构化程序设计中,高层模块总是依赖于低层模块。
在高层模块与低层模块之间,引入一个抽象接口层。
1. 依赖于抽象
-
任何变量都不应该持有一个指向具体类的指针或引用。
-
任何类都不应该从具体类派生。
-
2. 设计接口而非设计实现
-
使用继承避免对类的直接绑定
-
抽象类/接口: 倾向于较少的变化;抽象是关键点,它易于修改和扩展;不要强制修改那些抽象接口/类
-
-
3. 避免传递依赖
-
避免高层依赖于低层
-
使用继承和抽象类来有效地消除传递依赖
-
组合/聚合复用原则 Composite/Aggregate Reuse Principle ,CARP
(转)UML类图关系(泛化 、继承、实现、依赖、关联、聚合、组合)
数据库
存储过程和触发器
触发器是一个隐藏的存储过程,不需要参数,隐式调用感觉,不到执行的存在,增加系统复杂性。
触发器复杂业务,需要嵌套。级联关系增大,再涉及存储过程和事务,容易出现死锁。
存储过程移植性差,需重写
存储过程是好东西,分场景,分业务来用。晚上定期的数据统计操作。
为实现代码可用性,存储过程传参操作。
group by
先分组,后统计 select 后面只能跟着group by 的字段/聚合函数。
去重 两条重复的数据(除了ID,其余的字段都是相同的) 可查询包含group by之外的字段
select * from user where id in( select min(id) from user where name = ‘Java3y‘ and pv = 20 and time=‘7-25‘ group by name,pv,time; )
执行顺序
昨天 SELECT * FROM 表名 WHERE TO_DAYS( NOW( ) ) - TO_DAYS( 时间字段名) <= 1 7天 SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 7 DAY) <= date(时间字段名) 近30天 SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 30 DAY) <= date(时间字段名) 本月 SELECT * FROM 表名 WHERE DATE_FORMAT( 时间字段名, ‘%Y%m‘ ) = DATE_FORMAT( CURDATE( ) , ‘%Y%m‘ ) 上一月 SELECT * FROM 表名 WHERE PERIOD_DIFF( date_format( now( ) , ‘%Y%m‘ ) , date_format( 时间字段名, ‘%Y%m‘ ) ) =1 函数 length --计算字符串长度 concat --连接两个字符串 substring -- 截取字符串 count -- 统计数量 max -- 最大 min -- 最小 sum -- 合计 floor/ceil --...数学函数
drop table
-
1)属于DDL
-
2)不可回滚
-
3)不可带where
-
4)表内容和结构删除
-
5)删除速度快
truncate table
-
1)属于DDL
-
2)不可回滚
-
3)不可带where
-
4)表内容删除
-
5)删除速度快
delete from
-
1)属于DML
-
2)可回滚
-
3)可带where
-
4)表结构在,表内容要看where执行的情况
-
5)删除速度慢,需要逐行删除
-
不再需要一张表的时候,用drop
-
想删除部分数据行时候,用delete,并且带上where子句
-
保留表而删除所有数据的时候用truncate
innodb myisam
mysql中myisam与innodb的区别
InnoDB支持事务,而MyISAM不支持事务
InnoDB支持行级锁,而MyISAM支持表级锁
InnoDB支持MVCC, 而MyISAM不支持
InnoDB支持外键,而MyISAM不支持
InnoDB不支持全文索引,而MyISAM支持。
InnoDB提供提交、回滚、崩溃恢复能力的事务安全(ASID)能力,实现并发控制。MyISAM提供较高的插入和查询记录的效率,主要用于插入和查询。
https://www.cnblogs.com/duanshouchang/p/10292923.html
https://www.cnblogs.com/whitebai/p/11668972.html
Basics
-
main签名
public static void main(String[] args)
-
public: 任何人都可以访问它
-
static: 方法可以在不创建包含main方法的类的实例的情况下运行
-
void: 方法不会返回任何值
-
main: 方法名,是主方法的默认方法名
-
-
在类,方法和其他流控制结构中,代码总是用花括号括起来{}。
-
注意
-
大小写敏感 :标识符,文件名
-
标识符 :类名、变量名、方法名。age、_age、$age、age1
-
关键字 :class、void
-
修饰符:
-
访问控制修饰符 : default, public , protected, private
-
非访问控制修饰符 : final, abstract, static,synchronized 和 volatile
-
-
-
类名,首字母大写 MyJavaClass
-
方法名,小写字母开头 myJavaClass
-
源文件名必须和类名相同
-
主方法入口:Java程序由public static void main(String[] args)方法开始
-
快捷键
?快捷键? -
变量
String name = "Lu";
类型 变量名 值 一一对应 :一个变量与一个类型相关联,并且只能够存储该特定类型的值。
-
取模:
Modulo Operatiomod。余数符号与除数相同取余:
Complementation.rem。余数符号与被除数相同负整数进行除法运算时操作不同
生成机制:mod 函数采用了 floor 函数,rem 函数采用 fix 函数,(这两个函数是用来取整的,floor 函数向无穷小方向舍入小数位,fix 函数向0 方向舍入小数位)
mod(x,y) =x-n.*y,如果 y != 0,n=floor(x./y)
rem(x,y)=x-n.*y,如果 y != 0, n = fix(x./y),
4/(-3) 约等于 -1.3
4mod(-3)=-2 4rem(-3)=1
-
++ 、--
int a=5; int b=++a; //先自增 a=6,b=6 int c=a++;// a=6,c=5
-
字符串
-
‘+‘ 操作符来连接字符串。
-
-
枚举
-
枚举可以单独声明或者声明在类里面。方法、变量、构造函数也可以在枚举中定义。
-
-
类型
byte 8-bit 有符号数据类型 char 16-bit Unicode字符数据类型 double 64-bit双精度浮点数 float 32-bit单精度浮点数 int 32位整型数 long 64位整型数 short 16位数字 -
类
-
继承
extends父子类superclass,subclass -
实现接口
implements -
接口
interface。定义方法,派生类为实现类
-
Data Structures 30minutes
-
Bitset 数组自增,保存位值
-
构造方法
-
实现 Cloneable接口,执行与/抑或操作。位数 ture(set)/false(clear)
-
isEmpty没有包含true的位
-
void flip(int index) 反转 ,设为当前值的补码
-
boolean intersects(BitSet bitSet)有true位,此 BitSet 中也将其设置为 true,则返回 ture。
-
-
-
array a group of similar elements, accessed by index
-
hashmap的底层实现,hashmap与hashset的区别
Object Oriented
Basic Classes
Advanced
Number
Character
String
Eclipse 使用
该项目使用IDEA作为开发工具,Ngnix实现反向代理,项目使用SpringBoot简化配置过程,redis sentry集群提高查询速度,使用微服务SpringCloud,Git版本控制工具,postman进行接口测试,并使用BootStrap快速 打造一个功能齐全的全功能网站页面。
数据库遵循三范式并采用子数据库子选项卡技术。 拆分后,业务清晰,专用于特殊图书馆。 可以实现热数据和冷数据的分离。 不经常变化的数据和具有大变化的数据是分散的。 /在表中,使用mysql的主键来递增,但引入了算法“雪花算法”来生成主键。
使用 eclipse 开发软件、Sping SpringMVC MyBatis三大技术以及MySQL数据库、前段等应用软件
以Mybatis,spring-boot作为框架的主技术。
Spring、SpringMVC、Mybatis、Shiro、layui、百度AI语音合成、阿里支付、POI等。
项目使用Spring、SpringMVC、Mybatis三大框架搭建,在用户管理模块用到了Shiro权限管理框架,前端页面制作的时候用了不少的layui组件,浏览文章时的听书功能用到了百度AI开放平台的智能语音合成技术,充值的时候使用阿里的支付宝充值接口,还有各种数据导出的时候用到了Java操作微软表格文件的POI扩展包。
其中实时新闻更新利用recyView布局加上adapter适配器,引入后台实时接口,给用户展现实时数据,其中的banner利用Viewpage加上计时器进行无线轮播,利用recyView用的属性清楚缓存,其中解析利用Utils框架解析后台的json数据。
项目使用框架:Spring+SpringMVC+Mybatis
前端运用到技术:HTML、CSS、Ajax、JavaScript
项目使用平台:基于Maven、Tomcat、Eclipses开发
项目后端使用技术:RestFul/转发/重定向到页面
JDK1.8
Mysql5.6
操作系统 :centos 6.5+
作为面试官,真的会很紧张。 社招一面、二面这些面试官,可能他们跳槽时候换成了你面试他们,所以他们只能逮着你简历里他熟悉的东西一个劲的问,假如你当时只是浅尝辄止,那可能就悲剧,如果你真的很深入,那恭喜你。。 所以综上,面试有时候真的需要运气。
学校给的最大保障是,即便不会,你也有时间有机会一直做下去。你可以自己创造机会吗?
以上是关于Java面试的主要内容,如果未能解决你的问题,请参考以下文章