Java Review (二十正则表达式)
Posted 三分恶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java Review (二十正则表达式)相关的知识,希望对你有一定的参考价值。
@
正则表达式是一个强大的字符串处理工具 ,可以对字符串进行查找、提取、分割、替换等操作 。 String类里也提供了如下几个特殊的方法 :
- boolean matches(String regex): 判断该宇符串是否匹配指定的正则表达式 。
- String replaceAll(String regex, String replacement): 将该宇符串中所有匹配regex 的子串替换成replacement 。
- String replaceFirst(String regex, String replacement): 将该字符串中第一个匹配 regex 的子串替换成 replacement 。
- String[] split(String regex): 以 regex 作为分隔符,把该字符串分割成多个子串 。
上面这些特殊的方法都依赖于 Java 提供的正则表达式支持,除此之外, Java 还提供了 Pattem 和Matcher 两个类专门用于提供正则表达式支持。
创建正则表达式
正则表达式就是一个用于匹配字符串的模板,可以匹配一批字符串,所以创建正则表达式就是创建一个特殊的字符串 。
在其他语言中,\ 表示:想要在正则表达式中插入一个普通的(字面上的)反斜杠,不要给它任何特殊的意义。在 Java 中,\ 表示:要插入一个正则表达式的反斜线,所以其后的字符具有特殊的意义。
所以,在其他的语言中(如Perl),一个反斜杠 就足以具有转义的作用,而在 Java 中正则表达式中则需要有两个反斜杠才能被解析为其他语言中的转义作用。也可以简单的理解在 Java 的正则表达式中,两个 代表其他语言中的一个 ,这也就是为什么表示一位数字的正则表达式是 d,而表示一个普通的反斜杠是 \。
正则表达式所支持的合法字符如表一所示 :

正则表达式中有一些特殊字符,这些特殊字符在正则表达式中有其特殊的用途:
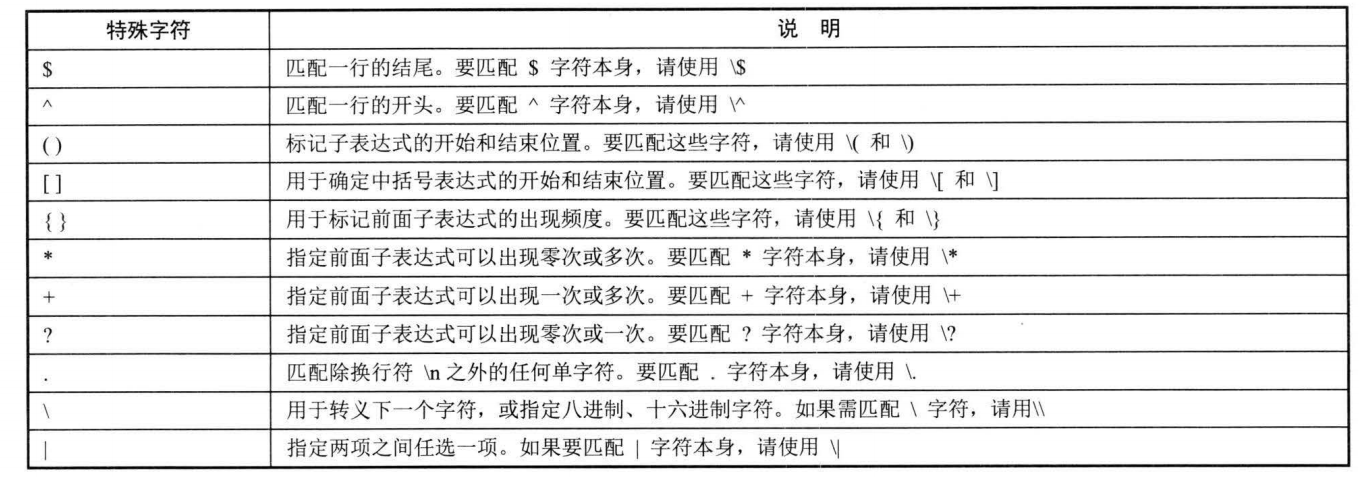
将上面多个字符拼起来 , 就可以创建一个正则表达式。例如:
" u0041\\ " // 匹配 A " u0061 " // 匹配 a <制表符〉
" \?\ [" // 匹配? [
上面的正则表达式依然只 能匹配单个字符,这是因为还未在正则表达式中使用"通配符","通配符"是可以匹配多个字符的特殊字符。正则表达式中 的"通配符"远远超出了普通通配符的功能,它被称为预定义字符:
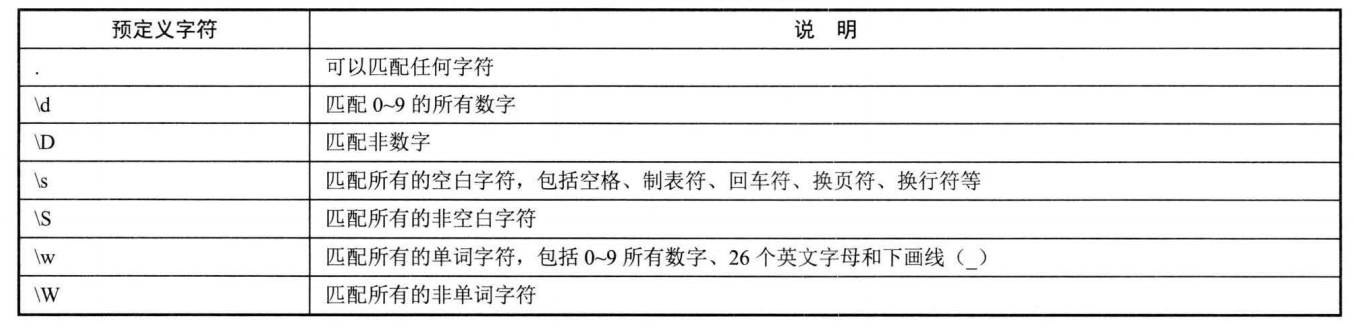
上面的 7 个预定义字符其 实很容易记忆: d 是 digit 的意思,代表数字; s 是 space的意思, 代表空白; W 是 word 的意思 , 代表单词 。 d 、 s 、 w 的大写形式恰好匹配与之相反的字符 。
有了上面的预定义字符后 ,接下来就可以创建更强大的正则表达式了。 例如:
c\wt //可 以匹配 cat 、 cbt 、 cct 、 cOt 、 c9t 等一批字符串
\d\d\d-\d\d\d-d\d\d\d //匹配如 000-000-0000 形式的电话号码
只想匹配 a~ f 的字母 ,或者匹配除 ab 之外的所有小写字母,或者匹配中文字符,此时就需要使用方括号表达式:
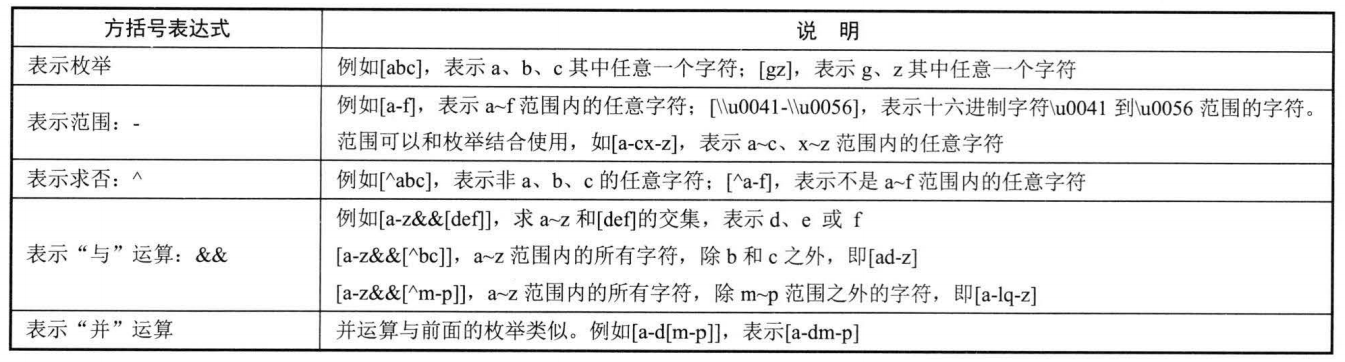
正则表示还支持圆括号表达式,用于将多个表达式组成一个子表达式 ,圆括号中可 以使用或运算符(|)。 例如, 正 则 表达式 "((public)|(Protected)l(private))"用于匹配 Java 的 三个访问控制符其中之 一。
Java 正则表达式还支持边界匹配符 :

前面例子中需要建立一个匹配 000-000-0000 形式的电话号码时,使用了\ddd-ddd-dddd
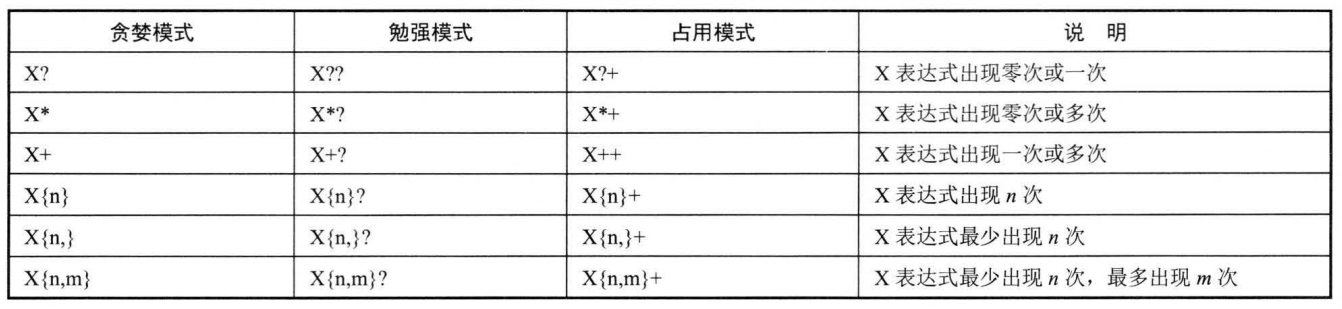
正则表达式,这看起来比较烦琐 。 实际上,正则表达式还提供了数量标识符,正则表达式支持的数量标识符有如下几种模式 :
- Greedy (贪婪模式) : 数量表示符默认采用贪婪模式 , 除非另有表示。贪婪模式的表达式会一直匹配下去 ,直到无法匹配为止 。 如果你发现表达式匹配的结果与预期的不符 , 很有可能是因为一一你以为表达式只会匹配前面几个宇符,而实际上它是贪婪模式 , 所以会一直匹配下去 。
- Reluctant (勉强模式) : 用问号后缀(?) 表示 , 它只会匹自己最少的字符 。 也称为最小匹配模式 。
- Possessive (占有模式) : 用加号后缀(+)表示 ,目前只有 Java 支持占有模式,通常比较少用 。
三种模式的数量表示符如表六所示 。
使用正则表达式
一旦在程序中定义了正则表达式,就可以使用 Pattem 和 Matcher 来使用正则表达式 。
Pattem 对象是正则表达式编译后在内存中的表示形式,因此,正则表达式宇符串必须先被编译为Pattem 对象,然后再利用该 Pattem 对象创建对应的 Matcher 对象 。 执行匹配所涉及的状态保留在 Matcher对象中,多个 Matcher 对象可共享同一个 Pattem 对象 。
因此,典型的调用顺序如下:
/ /将一个字符串编译成 Pattern 对象
Pattern p = Pattern.compil e( "a*b");
// 使用 Pattern 对象创建 Matcher 对象
Matcher m = p .matcher( "aaaaab" ) ;
boolean b = m.matches(); / /返回 true
上面定义的 Pattem 对象可以多次重复使用 。 如果某个正则表达式仅需一次使用,则可直接使用Pattem 类的静态 matches()方法,此方法自动把指定字符串编译成匿名的 Pattem 对象,并执行匹配,如下所示 :
boolean b = Pattern.matches("a*b" , "aaaaab"); // 返回 true
Pattem 是不可变类,可供多个并发线程安全使用 。
Matcher 类提供了如下几个常用方法 :
- find(): 返回目标字符串中是否包含与 Pattem 匹配的子 串 。
- group(): 返回上一次与 Pattem 匹配的子串 。
- start(): 返回上一 次与 Pattem 匹配的子串在目标字符串中的开始位置 。
- end(): 返回上一次与 Pattem 匹配的子串在目标字符串中的结束位置加 1 。
- lookingAt() : 返回目标字符串前面部分与 Pattem 是否匹配 。
- matches() : 返回整个目标字符串与 Pattem 是否匹配 。
- reset(): 将现有的 Matcher 对象应用于一个新的字符序列 。
通过 Matcher 类的 findO和 groupO方法可以从目标字符串中依次取出特定子串(匹配正则表达式的子串),例如互联网的网络爬虫,它们可以自动从网页中识别出所有的电话号码 。 下面程序示范了如何从大段的宇符串中找出电话号码 :
public class FindGroup
{
public static void main(String[] args)
{
// 使用字符串模拟从网络上得到的网页源码
String str = "我想求购一本《***》,尽快联系我13500006666"
+ "交朋友,电话号码是13611125565"
+ "出售二手电脑,联系方式15899903312";
// 创建一个Pattern对象,并用它建立一个Matcher对象
// 该正则表达式只抓取13X和15X段的手机号,
// 实际要抓取哪些电话号码,只要修改正则表达式即可。
Matcher m = Pattern.compile("((13\d)|(15\d))\d{8}")
.matcher(str);
// 将所有符合正则表达式的子串(电话号码)全部输出
while(m.find())
{
System.out.println(m.group());
}
}
}
运行结果:
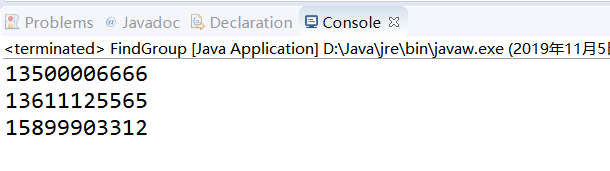
find()方法依次查找字符串中与 Pattem 匹配的子串, 一旦找到对应的子
串,下次调用 find()方法时将接着向下查找。
find()方法还可以传入一个 int 类型的参数,带 int 参数的 find()方法将从该 int 索引处向下搜索 。start()和 end()方法主要用于确定子串在目标字符串中的位置,如下程序所示:
public class StartEnd
{
public static void main(String[] args)
{
// 创建一个Pattern对象,并用它建立一个Matcher对象
String regStr = "Java is very easy!";
System.out.println("目标字符串是:" + regStr);
Matcher m = Pattern.compile("\w+")
.matcher(regStr);
while(m.find())
{
System.out.println(m.group() + "子串的起始位置:"
+ m.start() + ",其结束位置:" + m.end());
}
}
}
运行结果:
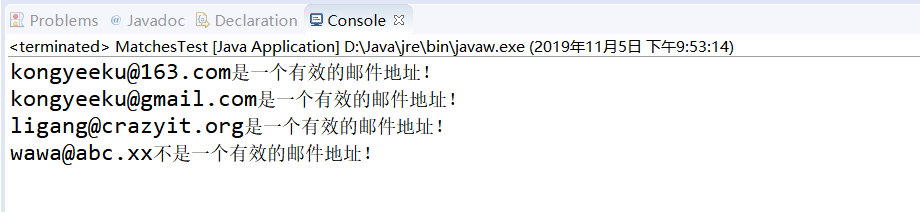
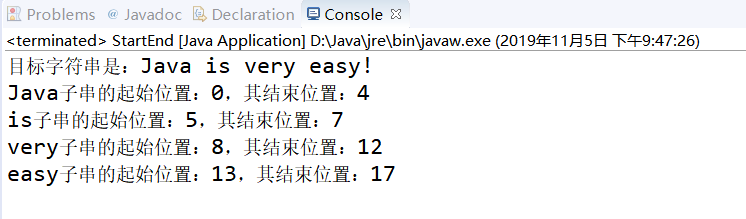 matchesO和 lookingAt()方法有点相 似,只 是 matches()方法要求整个字符串和 Pattem 完全匹配时才返回 true ,而 lookingAtO只要字符串以 Pattem 开头就会返回 true 。 reset()方法可将现有的 Matcher 对象应用于新的字符序列 。看如下程序:
matchesO和 lookingAt()方法有点相 似,只 是 matches()方法要求整个字符串和 Pattem 完全匹配时才返回 true ,而 lookingAtO只要字符串以 Pattem 开头就会返回 true 。 reset()方法可将现有的 Matcher 对象应用于新的字符序列 。看如下程序:
public class MatchesTest
{
public static void main(String[] args)
{
String[] mails =
{
"kongyeeku@163.com" ,
"kongyeeku@gmail.com",
"ligang@crazyit.org",
"wawa@abc.xx"
};
String mailRegEx = "\w{3,20}@\w+\.(com|org|cn|net|gov)";
Pattern mailPattern = Pattern.compile(mailRegEx);
Matcher matcher = null;
for (String mail : mails)
{
if (matcher == null)
{
matcher = mailPattern.matcher(mail);
}
else
{
matcher.reset(mail);
}
String result = mail + (matcher.matches() ? "是" : "不是")
+ "一个有效的邮件地址!";
System.out.println(result);
}
}
}
运行结果:
除此之外 ,还可以利用正则表达式对目标字符串进行分割、查找、替换等操作,看如下程序:
public class ReplaceTest
{
public static void main(String[] args)
{
String[] msgs =
{
"Java has regular expressions in 1.4",
"regular expressions now expressing in Java",
"Java represses oracular expressions"
};
Pattern p = Pattern.compile("re\w*");
Matcher matcher = null;
for (int i = 0 ; i < msgs.length ; i++)
{
if (matcher == null)
{
matcher = p.matcher(msgs[i]);
}
else
{
matcher.reset(msgs[i]);
}
System.out.println(matcher.replaceAll("哈哈:)"));
}
}
}
运行结果:

参考:
【1】:《疯狂Java讲义》
【2】:Java正则表达式
【3】:正则表达式匹配规则
【3】:正则表达式复杂匹配规则
【4】:正则表达式教程
以上是关于Java Review (二十正则表达式)的主要内容,如果未能解决你的问题,请参考以下文章
通过 Java 正则表达式提取 semver 版本字符串的片段