[Java复习] MySQL复习
Posted 潜林
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Java复习] MySQL复习相关的知识,希望对你有一定的参考价值。
数据库集群会产生哪些问题?
1. 自增id问题 2. 数据关联查询问题(水平拆分) 3.数据同步问题
数据库集群下自增id问题的解决?
1. UUID(不推荐, 不能建索引)
2. 设置id步长(缺点:需要在设计数据库时需要确定库的数量,才能定好步长间隔)
3. 雪花算法(sharding-jdbc使用雪花算法)或Redis
MySQL主从复制
MySQL主从复制是MySQL本身自带功能
从库生成两个线程,一个I/O线程,一个SQL线程;
I/O线程去请求主库 的binlog,并将得到的binlog日志写到relay log(中继日志) 文件中;
主库会生成一个 log dump 线程,用来给从库 i/o线程传binlog;
SQL 线程,会读取relay log文件中的日志,并解析成具体操作,来实现主从的操作一致,而最终数据一致;
读写分离
MyCat:
MyCAT原理MyCAT主要是通过对SQL的拦截,
然后经过一定规则的分片解析、路由分析、读写分离分析、缓存分析等,然后将SQL发给后端真实的数据块,并将返回的结果做适当处理返回给客户端。
特点:第三方客户端,反向代理
SpringBoot动态切换数据源:
动态切换数据源,根据配置的文件,业务动态切换访问的数据库:此方案通过Spring的AOP,AspactJ来实现动态织入,
通过编程继承实现Spring中的AbstractRoutingDataSource,来实现数据库访问的动态切换,不仅可以方便扩展,不影响现有程序,
而且对于此功能的增删也比较容易。
在Spring 2.0+中引入了AbstractRoutingDataSource, 该类充当了DataSource的路由中介, 能有在运行时, 根据某种key值来动态切换到真正的DataSource上。
1.项目中需要集成多个数据源分别为读和写的数据源,绑定不同的key。
2.采用AOP技术进行拦截业务逻辑层方法,判断方法的前缀是否需要写或者读的操作
3.如果方法的前缀是写的操作的时候,直接切换为写的数据源,反之切换为读的数据源
也可以自己定义注解进行封装
分表分库
原则:垂直拆分和水平拆分
垂直拆分:根据不同业务,分位不同数据库。比如会员DB,订单DB,支付DB等等。
优点:业务清晰,系统间整合和扩展容易。
缺点:业务表不能join,只能通过接口调用,系统复杂度挺高,还有分布式事务问题。
水平拆分:把同一个表的数据按字段拆分到不同数据库,或者把同一个表拆分多份到不同数据库。
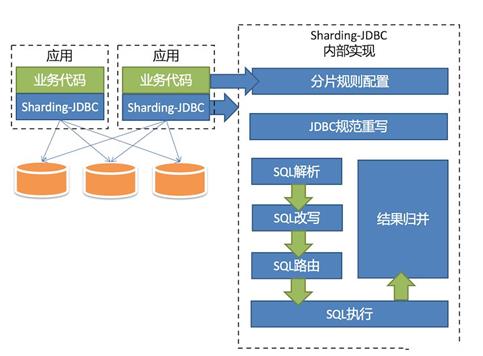
Sharding-JDBC:
Sharding-JDBC与MyCat的区别:
MyCat是一个基于第三方应用中间件数据库代理框架,客户端所有的jdbc请求都必须要先交给MyCat,再有MyCat转发到具体的真实服务器中。
Sharding-Jdbc是一个Jar形式,在本地应用层重写Jdbc原生的方法,实现数据库分片形式。
MyCat属于服务器端数据库中间件,而Sharding-Jdbc是一个本地数据库中间件框架。
Sharding-JDBC实现读写分离原理:
需要在项目中集成主和从的数据源,Sharding-Jdbc根据DML和DQL语句类型连接主或者从数据源。
PS:查看MasterSlaveDataSource即可查看该类getDataSource方法获取当前数据源名称
SpringBoot整合Sharding-Jdbc分为两种方式
一种为原生配置方式,自己需要实现接口。
1.分库算法类需要实现SingleKeyDatabaseShardingAlgorithm<T>接口
2.分表算法类需要实现SingleKeyTableShardingAlgorithm<T>接口
第二种通过配置文件形式配置。
案例比如:t_order 拆分成t_order_0, t_order _1
Sharding-Jdbc原理:
1. Sharding-JDBC中的路由结果是通过分片字段和分片方法来确定的,如果查询条件中有 id 字段的情况还好,查询将会落到某个具体的分片。
2. 如果查询没有分片的字段,会向所有的db或者是表都会查询一遍,让后封装结果级给客户端。
索引实现原理
索引数据结构:
1. hash算法
优点:通过字段值计算hash值,查询效率高
缺点:不支持范围查询(底层数据结构是散列,无法比较大小)
2. AVL(平衡二叉树)
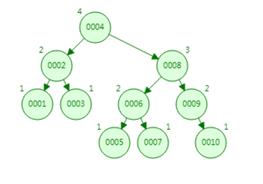
优点:查询效率还可以,缺点:虽然支持范围查询,但是回旋查询效率低。
规律:如果树的高度越高,那么查询IO次数会越多。
3. B树
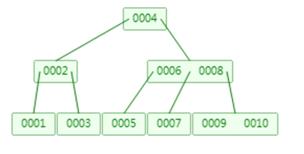
一个节点可以拥有多于2个子节点的二叉查找树。
优点:B树节点元素比平衡二叉树要多,所以B树数据结构相比平衡二叉树数据结构实现减少磁盘IO的操作,提高查询效率。
缺点: 范围查询效率还是比较低。
4. B+树
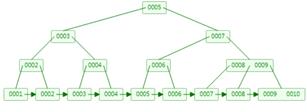
通过继承了B树的特征,B+树相比B树,新增叶子节点与非叶子节点关系,叶子节点中包含了key和value,非叶子节点中只是包含了key,不包含value。
通过非叶子节点查询叶子节点获取对应的value,所有相邻的叶子节点包含非叶子节点,使用链表进行结合,有一定顺序排序,从而范围查询效率非常高。
缺点:因为有冗余节点数据,会比较占内存。
MyISAM和InnoDB对于B+树索引的实现区别:
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。叶子节点的value存放行数地址,通过行数定位到数据。
InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。
这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
叶子节点的value存放是行的data数据,比MyISAM效率要高一些,但更占磁盘空间。
mysql定位慢查询?
slow_query_log_file 慢查询日志存放的位置
long_query_time 查询超过多少秒才记录
1.查询慢查询配置
show variables like \'slow_query%\';
2.查询慢查询限制时间
show variables like \'long_query_time\';
3.将 slow_query_log 全局变量设置为“ON”状态
set global slow_query_log=\'ON\';
4.查询超过2秒就记录
set global long_query_time=2;
索引为什么会失效?
1. 索引字段存了null值
2. 条件中有or
3. like以%开头
4. 联合索引,不是使用最左原则
5. 字符串没有用引号引起来
联合索引为什么需要遵循左前缀原则?
因为索引底层采用B+树叶子节点顺序排列,必须通过左前缀索引才能定位到具体的节点范围。
以上是关于[Java复习] MySQL复习的主要内容,如果未能解决你的问题,请参考以下文章