如何正确在Linux Shell脚本中定义一个时间变量?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何正确在Linux Shell脚本中定义一个时间变量?相关的知识,希望对你有一定的参考价值。
我有一个Shell脚本,从开始执行到结束是需要花费一定的时间的。我现在想记录这个具体的时间段。如下脚本:
#!/bin/bash
LOG_TIME=`date +%H:%M:%S`
echo "脚本开始时间:"$LOG_TIME
/bin/sleep 10
echo "脚本结束时间:"$LOG_TIME
exit 1
我设置中间停顿了10秒钟。
问:执行该脚本时输出到控制台的脚本开始时间和结束时间为什么是一样的?
1、创建脚本 test.sh,并入截图内容。
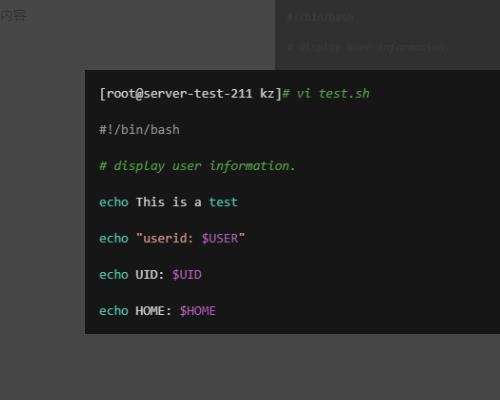
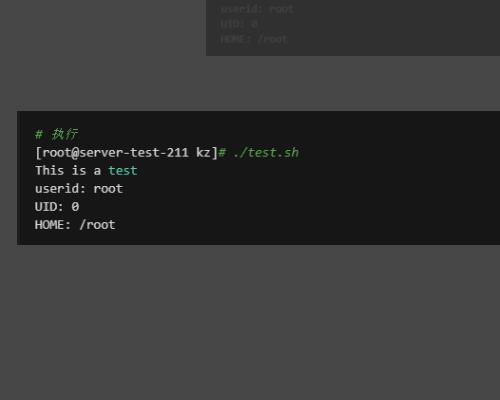
2、执行test.sh脚本。
3、使用用户变量,创建 test.sh 脚本,填入截图内容。
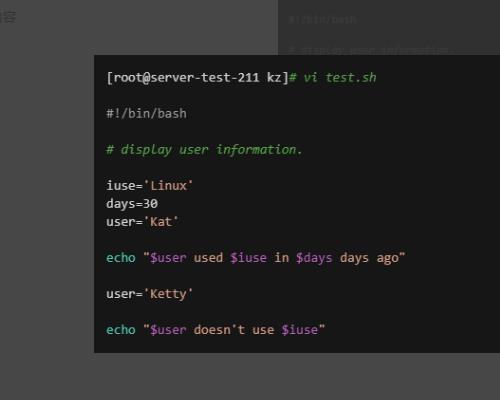
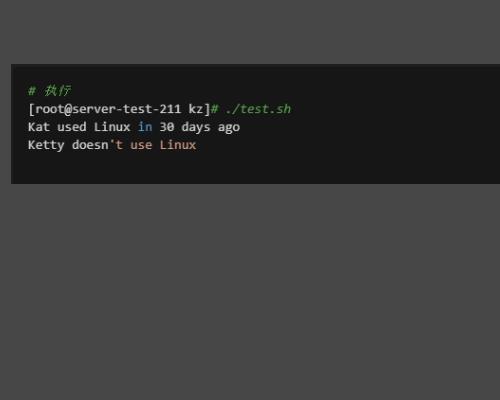
4、执行脚本输出结果。
5、命令替换将命令赋值自定义变量,可以通过反引号字符实现 。
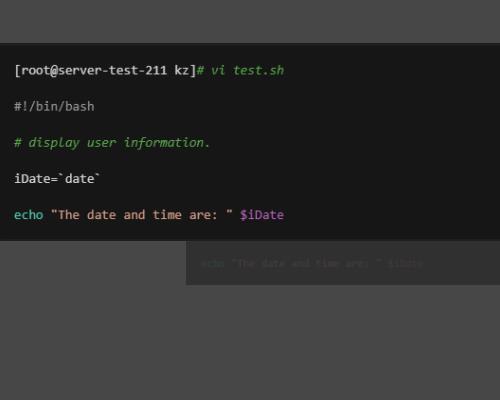
LOG_TIME=`date +%H:%M:%S`
这只是一个变量而已,你不给他赋值他怎么会自己变化呢?追问
定义一个变量,当然就是为了方便一处定义下面多处调用啊,如果下面再执行一遍那么定义这个变量就似乎没有意义了。
难道LOG_TIME第一次执行之后就变成了一个常量,而下面调用的时候就只获取这个常量,而不是获取当前的`date +%H:%M:%S`?
大哥,你连变量和常量的区别都没有搞清楚。。
看一下你这个脚本的逻辑:
#!/bin/bash
LOG_TIME=`date +%H:%M:%S` # 取出当前的时间值,赋值给变量LOG_TIME
echo "脚本开始时间:"$LOG_TIME # 打印一下该变量的值
/bin/sleep 10 # 暂停10秒
echo "脚本结束时间:"$LOG_TIME # 再打印一下该变量的值
exit 1
你只是将一个变量的值打印了两遍,中间又没有修改变量的值,两次打印的结果为什么要不一样呢?
大哥,别生气,气坏身子不好啦。。。我就是有疑问啦,既然是变量两次打印应该就不一样咯,既然一样我就打个比方当作赋值后变常量。。。我现在已经将所有的更改为`date +%H:%M:%S`了。。。`date +%H:%M:%S`本身是随时可以变化的。。。有其他方法动态的调用没?
本回答被提问者采纳如何使用 Shell 脚本自动化 Linux 系统维护任务?
如果一个系统管理员花费大量的时间解决问题以及做重复的工作,你就应该怀疑他这么做是否正确。
一个高效的系统管理员应该制定一个计划使得其尽量花费少的时间去做重复的工作。
因此尽管看起来他没有做很多的工作,但那是因为 shell 脚本帮助他完成了大部分任务,这也就是我们将要探讨的东西。
简单的说,shell 脚本就是一个由 shell 一步一步执行的程序,而 shell 是在 Linux 内核和最终用户之间提供接口的另一个程序。
默认情况下,RHEL 7 中用户使用的 shell 是 bash(/bin/bash)。
首先让我们新建一个目录用于保存我们的 shell 脚本:
# mkdir scripts # cd scripts
新建一个文本文件system_info.sh,在头部插入一些注释以及一些命令:
#!/bin/bash # 该脚本会返回以下这些系统信息: # -主机名称: echo -e "\e[31;43m***** HOSTNAME INFORMATION *****\e[0m" hostnamectl echo "" # -文件系统磁盘空间使用: echo -e "\e[31;43m***** FILE SYSTEM DISK SPACE USAGE *****\e[0m" df -h echo "" # -系统空闲和使用中的内存: echo -e "\e[31;43m ***** FREE AND USED MEMORY *****\e[0m" free echo "" # -系统启动时间: echo -e "\e[31;43m***** SYSTEM UPTIME AND LOAD *****\e[0m" uptime echo "" # -登录的用户: echo -e "\e[31;43m***** CURRENTLY LOGGED-IN USERS *****\e[0m" who echo "" # -使用内存最多的 5 个进程 echo -e "\e[31;43m***** TOP 5 MEMORY-CONSUMING PROCESSES *****\e[0m" ps -eo %mem,%cpu,comm --sort=-%mem | head -n 6 echo "" echo -e "\e[1;32mDone.\e[0m"
然后,给脚本可执行权限,并运行脚本:
# chmod +x system_info.sh ./system_info.sh
为了更好的可视化效果各部分标题都用颜色显示:
颜色功能是由以下命令提供的:
echo -e "\e[COLOR1;COLOR2m\e[0m"
其中 COLOR1 和 COLOR2 是前景色和背景色,是你想用颜色显示的字符串。
你想使其自动化的任务可能因情况而不同。因此,我们不可能在一篇文章中覆盖所有可能的场景,但是我们会介绍使用 shell 脚本可以使其自动化的三种典型任务:
1) 更新本地文件数据库
1) 查找(或者删除)有 777 权限的文件
2) 文件系统使用超过定义的阀值时发出警告。
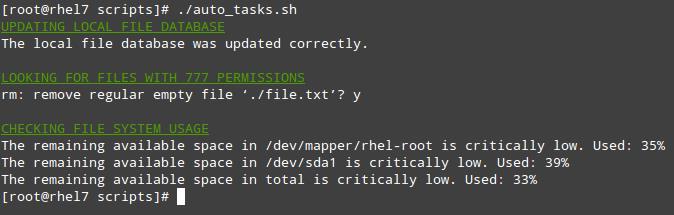
让我们在脚本目录中新建一个名为 auto_tasks.sh 的文件并添加以下内容:
#!/bin/bash # 自动化任务示例脚本: # -更新本地文件数据库: echo -e "\e[4;32mUPDATING LOCAL FILE DATABASE\e[0m" updatedb if [ $? == 0 ]; then echo "The local file database was updated correctly." else echo "The local file database was not updated correctly." fi echo "" # -查找 和/或 删除有 777 权限的文件。 echo -e "\e[4;32mLOOKING FOR FILES WITH 777 PERMISSIONS\e[0m" # Enable either option (comment out the other line), but not both. # Option 1: Delete files without prompting for confirmation. Assumes GNU version of find. #find -type f -perm 0777 -delete # Option 2: Ask for confirmation before deleting files. More portable across systems. find -type f -perm 0777 -exec rm -i {} +; echo "" # -文件系统使用率超过定义的阀值时发出警告 echo -e "\e[4;32mCHECKING FILE SYSTEM USAGE\e[0m" THRESHOLD=30 while read line; do # This variable stores the file system path as a string FILESYSTEM=$(echo $line | awk '{print $1}') # This variable stores the use percentage (XX%) PERCENTAGE=$(echo $line | awk '{print $5}') # Use percentage without the % sign. USAGE=${PERCENTAGE%?} if [ $USAGE -gt $THRESHOLD ]; then echo "The remaining available space in $FILESYSTEM is critically low. Used: $PERCENTAGE" fi done < <(df -h --total | grep -vi filesystem)
请注意该脚本最后一行两个 < 符号之间有个空格。
下面的脚本(filesystem_usage.sh)会运行有名的 df -h 命令,格式化输出到 HTML 表格并保存到 report.html 文件中:
#!/bin/bash # 演示使用 shell 脚本创建 HTML 报告的示例脚本 # Web directory WEB_DIR=/var/www/html # A little CSS and table layout to make the report look a little nicer echo "<HTML> <HEAD> <style> .titulo{font-size: 1em; color: white; background:#0863CE; padding: 0.1em 0.2em;} table { border-collapse:collapse; } table, td, th { border:1px solid black; } </style> <meta http-equiv='Content-Type' content='text/html; charset=UTF-8' /> </HEAD> <BODY>" > $WEB_DIR/report.html # View hostname and insert it at the top of the html body HOST=$(hostname) echo "Filesystem usage for host <strong>$HOST</strong><br> Last updated: <strong>$(date)</strong><br><br> <table border='1'> <tr><th class='titulo'>Filesystem</td> <th class='titulo'>Size</td> <th class='titulo'>Use %</td> </tr>" >> $WEB_DIR/report.html # Read the output of df -h line by line while read line; do echo "<tr><td align='center'>" >> $WEB_DIR/report.html echo $line | awk '{print $1}' >> $WEB_DIR/report.html echo "</td><td align='center'>" >> $WEB_DIR/report.html echo $line | awk '{print $2}' >> $WEB_DIR/report.html echo "</td><td align='center'>" >> $WEB_DIR/report.html echo $line | awk '{print $5}' >> $WEB_DIR/report.html echo "</td></tr>" >> $WEB_DIR/report.html done < <(df -h | grep -vi filesystem) echo "</table></BODY></HTML>" >> $WEB_DIR/report.html
在我们的 RHEL 7 服务器(192.168.0.18)中,看起来像下面这样:
你可以添加任何你想要的信息到那个报告中。添加下面的 crontab 条目在每天下午的 1:30 运行该脚本:
30 13 * * * /root/scripts/filesystem_usage.sh
译者:ictlyh
以上是关于如何正确在Linux Shell脚本中定义一个时间变量?的主要内容,如果未能解决你的问题,请参考以下文章