
一.概述
LinkedHashMap是HashMap的子类,关于HashMap可以看下前面的章节:java基础进阶篇 HashMap
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
二.特点
- 非线程安全
- LinkedHashMap 内部保证顺序; 分插入顺序和访问排序两种, 如果是访问顺序,那put和get操作已存在的Entry时,都会把Entry移动到双向链表的表尾(其实是先删除再插入)。 HashMap不保证插入顺序.
- LinkedHashMap存取数据,还是跟HashMap一样使用的Entry[]的方式,双向链表只是为了保证顺序。
- LinkedHashMap是继承于HashMap,是基于HashMap和双向链表来实现的。
- LinkedHashMap的插入顺序和访问顺序可以由开发者自己决定.
三.应用场合
HashMap是无序的,当我们希望有顺序(保证插入顺序)地去存储key-value时,就需要使用LinkedHashMap了.
使用HashMap:
Map<Integer, String> hashMap = new HashMap<Integer, String>();
hashMap.put(1, "a1");
hashMap.put(3, "a3");
hashMap.put(2, "a2");
hashMap.put(0, "a0");
Set<Entry<Integer, String>> set = hashMap.entrySet();
Iterator<Entry<Integer, String>> iterator = set.iterator();
while (iterator.hasNext()) {
Entry entry = iterator.next();
Integer key = (Integer) entry.getKey();
String value = (String) entry.getValue();
System.out.println("key:" + key + ",value:" + value);
}
输出结果:
key:0,value:a0
key:1,value:a1
key:2,value:a2
key:3,value:a3
HashMap 给key做了排序, 不能保证插入顺序, 当有插入顺序的需求时, 就轮到LinkedHashMap 登场了.
使用LinkedHashMap:
Map<Integer, String> hashMap = new LinkedHashMap<Integer, String>();
hashMap.put(1, "a1");
hashMap.put(3, "a3");
hashMap.put(2, "a2");
hashMap.put(0, "a0");
Set<Entry<Integer, String>> set = hashMap.entrySet();
Iterator<Entry<Integer, String>> iterator = set.iterator();
while (iterator.hasNext()) {
Entry entry = iterator.next();
Integer key = (Integer) entry.getKey();
String value = (String) entry.getValue();
System.out.println("key:" + key + ",value:" + value);
}
输出结果:
key:1,value:a1
key:3,value:a3
key:2,value:a2
key:0,value:a0
完美保证了插入时的顺序.
四.构造方法
LinkedHashMap继承了HashMap,所以它们有很多相似的地方。
在这儿我们只看参数为空 和修改排序模式的两种构造方法.
1.参数为空
/**
* Constructs an empty insertion-ordered <tt>LinkedHashMap</tt> instance
* with the default initial capacity (16) and load factor (0.75).
*/
public LinkedHashMap() {
super();
accessOrder = false;
}
默认初始容量是16, 负载因子是0.75. 这里调用了super() 即HashMap的构造方法.
accessOrder设置为false,表示不是访问顺序而是插入顺序存储的,这也是默认值,表示LinkedHashMap中存储的顺序是按照调用put方法插入的顺序进行排序的。LinkedHashMap也提供了可以设置accessOrder的构造方法.
2.accessOrder
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
通过例子来看下参数accessOrder 在插入顺序和访问顺序上的作用.
true的情况:
Map<Integer, String> hashMap = new LinkedHashMap<Integer, String>(16,0.75f,true);
hashMap.put(1, "a1");
hashMap.put(3, "a3");
hashMap.put(2, "a2");
hashMap.put(0, "a0");
Set<Entry<Integer, String>> set = hashMap.entrySet();
Iterator<Entry<Integer, String>> iterator = set.iterator();
while (iterator.hasNext()) {
Entry entry = iterator.next();
Integer key = (Integer) entry.getKey();
String value = (String) entry.getValue();
System.out.println("key:" + key + ",value:" + value);
}
输出结果:
key:1,value:a1
key:3,value:a3
key:2,value:a2
key:0,value:a0
accessOrder 等于true: 保证了插入顺序. 前面的例子,默认为false的情况, 保证了访问顺序即对key进行了排序.
五.源码结构分析
LinkedHashMap 实现了Map<K,V>接口。其内部还维护了一个双向链表.
默认情况,遍历时的顺序是按照插入节点的顺序。这也是其与HashMap最大的区别。
也可以在构造时传入accessOrder参数,使得其遍历顺序按照访问的顺序输出。
LinkedHashMap的实现主要分两部分,一部分是哈希表,另外一部分是链表。
双向链表左右箭头代表前后指针. 每个节点都包含前指针和后指针.
下面源码部分可以看出, 每个节点都定义了before, after;用于维护双向链表间的节点顺序.
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
类里有两个成员变量head tail,分别指向内部双向链表的表头、表尾。
/**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail;
LinkedHashMap 没有重写put 方法, 但是重写了put方法中的newNode()方法.
newNode()会在HashMap的putVal()方法里被调用,putVal()方法会在批量插入数据putMapEntries(Map<? extends K, ? extends V> m, boolean evict)或者插入单个数据public V put(K key, V value)时被调用。
LinkedHashMap重写了newNode(),在每次构建新节点时,通过linkNodeLast(p);将新节点链接在内部双向链表的尾部。
在构建新节点时,构建的是LinkedHashMap.Entry 不再是Node.
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
将新增的节点链接在双向链表的尾部.
// link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {// 将新节点连接在链表的尾部
p.before = last;
last.after = p;
}
}
LinkedHashMap 还重写了三个方法:
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
我们主要看下afterNodeAccess 方法, 该方法是在 accessOrder = true 并且 插入的当前节点不等于尾节点时,该方法才会生效。并且该方法的作用是将插入的节点变为尾节点,后面在get方法中也会调用.
// 把当前节点放到双向链表的尾部
void afterNodeAccess(HashMap.Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
//当 accessOrder = true 并且当前节点不等于尾节点tail。这里将last节点赋值为tail节点
if (accessOrder && (last = tail) != e) {
//记录当前节点的上一个节点b和下一个节点a
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
//释放当前节点和后一个节点的关系
p.after = null;
//如果当前节点的前一个节点为null
if (b == null)
//头节点=当前节点的下一个节点
head = a;
else
//否则b的后节点指向a
b.after = a;
//如果a != null
if (a != null)
//a的前一个节点指向b
a.before = b;
else
//b设为尾节点
last = b;
//如果尾节点为null
if (last == null)
//头节点设为p
head = p;
else {
//否则将p放到双向链表的最后
p.before = last;
last.after = p;
}
//将尾节点设为p
tail = p;
//LinkedHashMap对象操作次数+1,用于快速失败校验
++modCount;
}
}
总结就是: 在每次插入数据,或者访问、修改数据时,会增加节点、调整链表的节点顺序。以决定迭代时输出的顺序。
六.常见问题
1.如何实现的元素有序?
在HashMap的基础上,对每一个节点添加向前向后指针,这样所有的节点形成了双向链表,自然就是有序的.
2.如何保证顺序的正确以及同步
通过重写的一些关键的方法,在元素发生增删改查等行为时,除了在Hash桶上进行操作,也对链表进行相应的更新,以此来保证顺序的正确.
3.如何实现两种顺序(插入顺序或者访问顺序)?
通过内部的标识位accessOrder(可以手动传入构造方法参数来控制)来记录当前LinkedHashMap是以什么为序,之后再处理元素时通过读取accessOrder的值来控制链表的顺序.
4.为什么重写containsValue()而不重写containsKey()?
public boolean containsValue(Object value) {
Node<K,V>[] tab; V v;
if ((tab = table) != null && size > 0) {
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
if ((v = e.value) == value ||
(value != null && value.equals(v)))
return true;
}
}
}
return false;
}
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}
containsKey()是通过hash值直接计算出该key对应的数组下标,之后在该hash桶的链表上进行查找相同的key.
containsValue()是对table进行遍历,对其中的每一个hash桶的所有值进行遍历,去寻找相同的value.
而在LinkedHashMap中, 其主干利用了哈希表即链表, 需要把传入的key 转化成哈希值再转化成索引, 很低效.
就这个问题补充下:
数据结构中有数组和链表来实现对数据的存储,但这两者基本上是两个极端。
数组存储区间是连续的,占用内存严重,故空间复杂的很大。但数组的二分查找时间复杂度小,为O(1);数组的特点是:寻址容易,插入和删除困难;
链表存储区间离散,占用内存比较宽松,故空间复杂度很小,但时间复杂度很大,达O(N)。链表的特点是:寻址困难,插入和删除容易。
哈希表综合了数组和链表的特点, 内部结构如下:
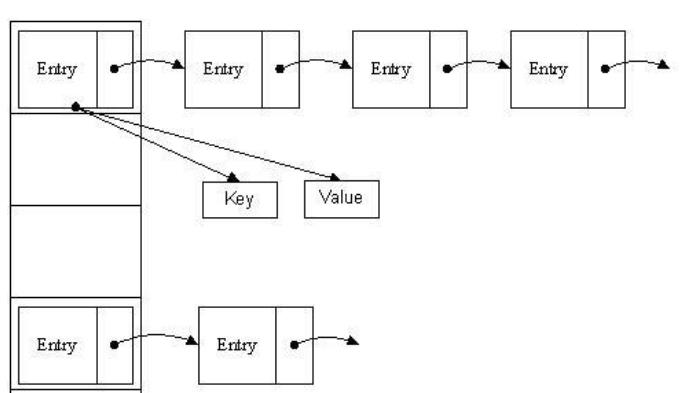
可以理解为带链表的数组, 哈希表是由数组+链表组成的, 长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢? 一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
HashMap其实也是一个线性的数组实现的,所以可以理解为其存储数据的容器就是一个线性数组。这可能让我们很不解,一个线性的数组怎么实现按键值对来存取数据呢?这里HashMap有做一些处理。
首先HashMap里面实现一个静态内部类Entry,其重要的属性有 key , value, next,从属性key,value我们就能很明显的看出来Entry就是HashMap键值对实现的一个基础bean,我们上面说到HashMap的基础就是一个线性数组,这个数组就是Entry[],Map里面的内容都保存在Entry[]里面。
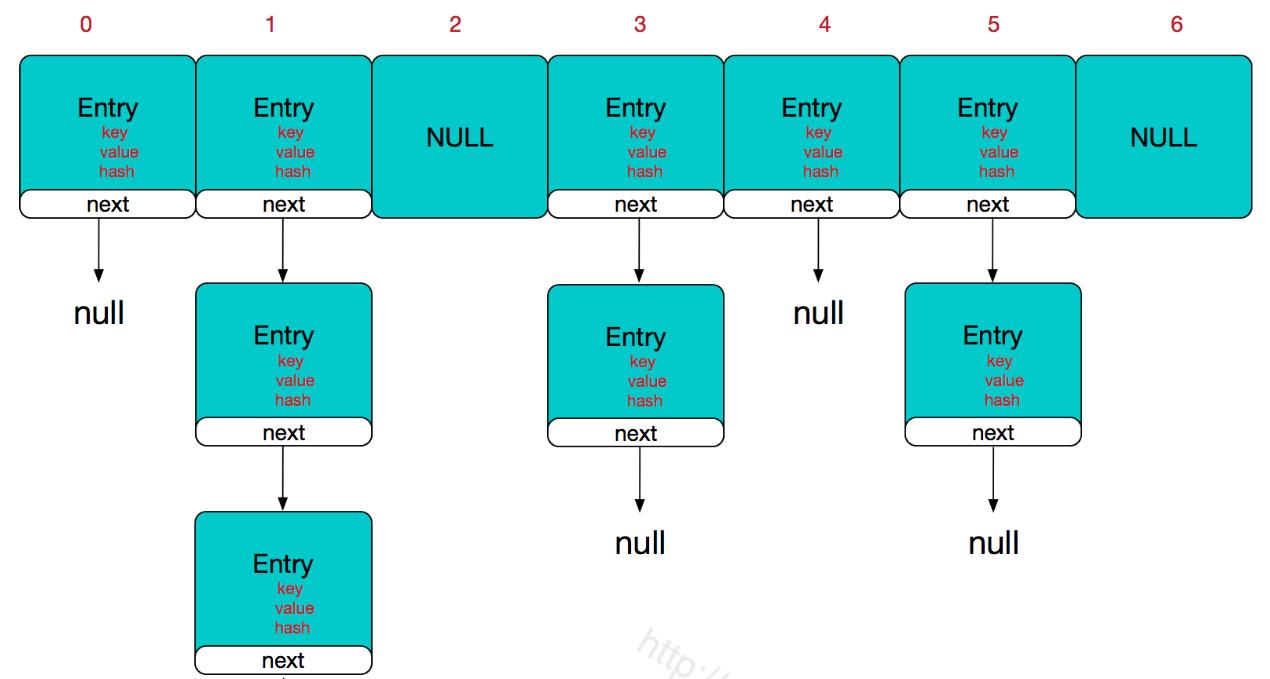
下面是HashMap 的结构, 也可以理解成单向链表结构,(个人自定义的名称, 便于理解勿喷)
而LinkedHashMap 的双向链表结构如下:(作者自涂鸦)
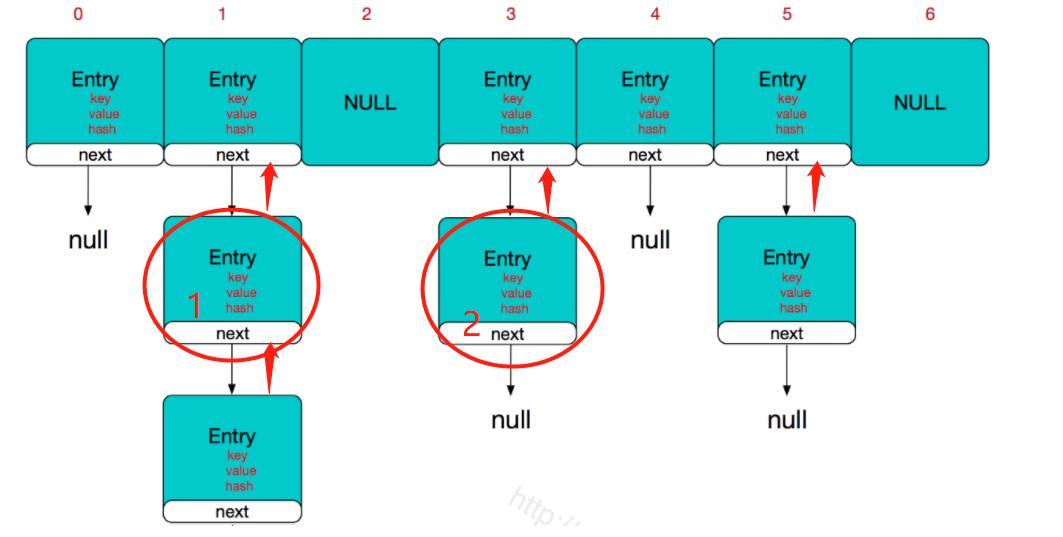
红色箭头表示节点Entry 之间是双向的, 回到主题, 为什么LinkedHashMap不重写containsKey()?
比如我们拥有 1 处 的key 和value, 从1 -> 2, 需要经历3个步骤
1.把key 转换成hash 值
2.把hash值转换成索引,方便在主干查找到对应的数组下标.(描述不准确,是这个意思)
3.没完呢, 还得根据key 或者是转化后的hash去查找所在下标处的Entry.
三个步骤等于回到了ArrayList 的原始数组时代.
再次重申,便于理解,高手请指教勿喷.
七.常用方法
常用方法请参照前面的章节: [ java基础进阶篇(七)_LinkedHashMap------【java源码栈】][https://www.cnblogs.com/tingbogiu/p/12403583.html]
