针对多轮推理分类问题的软标签构造方法
Posted 3A是个坏同志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了针对多轮推理分类问题的软标签构造方法相关的知识,希望对你有一定的参考价值。
Motivation
在非对称博弈中,我们常常要对对手的状态(如持有的手牌类型)进行推理。此类推理问题有两个特点:(1) 虽然存在正确结果,但正确结果往往无法经过一次推理得到。因为随着游戏的进行,才能获得足够的信息 (2) 虽然无法一次性获得正确的结果,但可以基于现有信息推理获得更正确的分布。更正确的分布会有益于我们在接下来的游戏中做出正确决策。
基于这两个特点,我们考虑一个简化的问题:我们想要知道对手持有的(唯一)一张手牌的类型。该问题可以被理解为多分类问题。考虑使用神经网络的情况,由于需要进行多轮推理,参照针对MDP的DQN模型结构,网络的输入将是我们先前推理得到的关于手牌所属类型的概率分布(当前状态),以及得到的新信息(使得状态转移的动作);网络输出基于新信息更新的概率分布(新状态)。训练这个网络需要使用从真实游戏中采集的数据,包括每轮的玩家行为,以及最重要的对手手牌真实值。
对于多分类,真实值应当是一个ont-hot向量。它代表着当我们已经拥有足够信息时应当得到的正确推理结果。但当还没有足够信息时,模型在理论上是没有能力推理出这个结果的(除非过拟合)。考虑一般的推理过程,在没有任何信息时,先验分布应当是一个均匀分布或正态分布。随着新信息的获得,这个分布被逐步修正,直至收敛为一个one-hot向量。如果在一开始就想要将它直接变换为one-hot向量,这种dynamics将破坏该分布应有的均匀或正态性,这将得到不准确的新分布,不不利于下一步决策的进行。
Contribution
本文提出了一个基于experience replay的两步过程,以构造适应于当前推理进程的软标签。模型在训练时使用本方法构造的软标签(而非直接使用真实ont-hot标签)以防止训练时产生不合时宜的dynamics。两步过程简述如下:
1. 采集阶段:使用该轮游戏数据中的推理结果和对应真实值(one-hot形式),构造软标签(每步构造一个)
2. 训练阶段:损失函数中分别对软标签和one-hot标签计算loss,并取min作为损失函数值。这样做可以在模型生成尚未确定的结果时使用软标签优化,避免破坏分布的均匀或正态性。在生成相对确定结果时使用one-hot标签优化,避免软标签带来的不确定性。
Method
下面详细介绍构造软标签的过程。为了方便下面的推导,首先说明一下分布的表示:假设我们要推断对手持有的一张手牌,该手牌可能有四种类型,那么对应的概率分布为一个长度为4的向量。每个维度(下标)代表一个随机变量值,对应元素代表该随机变量值出现的概率。
我们考虑该手牌不同类型是否相互独立两种情况。“不相互独立”指的是相邻的随机变量值之间存在概率密度的连续性,如手牌分为1、2、3、4四种,且1的个数最多,此后逐个减小。那么先验分布应当是一个从X=1开始概率值逐渐减小的分布。相反,若手牌不同类型相互独立,即说明类型下标相邻手牌间没有实质联系(包括数量或者其它方面的连续性)。那么先验分布将是一个均匀分布。
我们使用前一轮训练得到的模型(在当前步)的推理结果和one-hot真实标签两个分布来构造该步对应的软标签。该步推理结果(分布)的均值和方差作为当前推理进程的度量,那么一种简单的思路是使构造的软标签均值方差与当前推理结果相同。下面分别介绍是否相互独立两种情况的不同软标签构造方法:
相互独立情况:构造均匀分布
我们需要保证真实值(对应的随机变量值)对应的概率值比其它位置更大,且其它位置概率值不能为0。由于各个位置相互独立,且没有其它信息,我们只能认为其它各个位置的概率值都相等。处理这种简单的形式,我们可以直接让新分布向量的均值方差与推理结果(分布向量)的均值方差相等。那么设真实值位置对应概率值为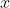 ,其它位置概率值为
,其它位置概率值为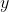 ,以均值方差相等为条件,可以直接得到方程:
,以均值方差相等为条件,可以直接得到方程:
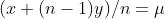
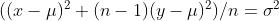
其中 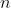 为分布向量长度。
为分布向量长度。
不相互独立情况:构造正态分布
在各随机变量值不相互独立时,与真实值(对应的随机变量值)相近的位置较更远位置有更大的概率密度,针对这种情况应当构造以真实值位置为峰的正态分布。该过程分为两步:首先构造一个与推理结果接近的正态分布,然后再将其峰的位置与真实值位置对齐。
基于推理结果构造正态分布
正态分布的形态由方差决定,位置由均值决定。但需要注意的是,这里的均值方差与上一种情况使用的分布向量均值方差不同。因为这种情况的下标具有语义,所以我们必须将分布向量作为离散概率密度函数(分布列)来理解。同时还需要分别处理所求的分布均值与峰的位置(正态分布均值即为峰的位置,但这与我们期望的不一定相同,因此要对其进行平移来得到我们期望的峰位置)。
设推理结果分布为 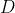 ,其随机变量值为
,其随机变量值为 


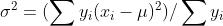
为了方便下一步进行对齐,我们尽可能把将要求出的正态分布峰(上式中 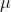 )平移到
)平移到  位置,但显然平移会影响 与
位置,但显然平移会影响 与 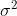 的值。因此先以
的值。因此先以  作为峰位置的估计值平移:
作为峰位置的估计值平移:

再对上式中  ( 与 。
( 与 。
对齐峰位置构造软标签
使用 计算的 (峰位置)会比直接使用 的位置。这步我们需要构造对 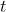 与峰位置 完全对齐。即当
与峰位置 完全对齐。即当 
 。显然有:
。显然有:

这样可以使用  代入分布
代入分布 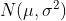 的累计密度函数
的累计密度函数 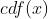 计算软标签各个维度值:位置
计算软标签各个维度值:位置 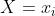 的对应密度为
的对应密度为 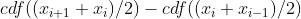
至此,软标签构造完成。
以上是关于针对多轮推理分类问题的软标签构造方法的主要内容,如果未能解决你的问题,请参考以下文章