Relu激励函数
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Relu激励函数相关的知识,希望对你有一定的参考价值。
参考技术A 因为Sigmod函数的梯度有可能会下降很慢。甚至梯度消失。在分类的时候很多都使用这个Relu激励函数,尤其是深度学习中。线性整流函数(Rectified Linear Unit, ReLU),Relu激励函数,也称“热鲁”激励函数。是一种人工神经网络中常见的激活函数。相比于Sigmoid函数,
Relu函数的优点:
梯度不饱和。梯度计算公式为:1x>0。因此在反向传播过程中,减轻了梯度弥散的问题,神经网络前几层的参数也可以很快的更新。
计算速度快。正向传播过程中,sigmoid和tanh函数计算激活值时需要计算指数,而Relu函数仅需要设置阈值。如果x<0,f(x)=0,如果x>0,f(x)=x。加快了正向传播的计算速度。
f(x)=max(o,x)
在神经元中输出为:
是不是很简单。
PyTorch学习激活函数
激励函数的功能:解决不能用线性方程概括的问题
y=Wx, 神经网络
y=AF(Wx),,AF为激励函数,是一个非线性方程。激励函数必须是可以微分的。
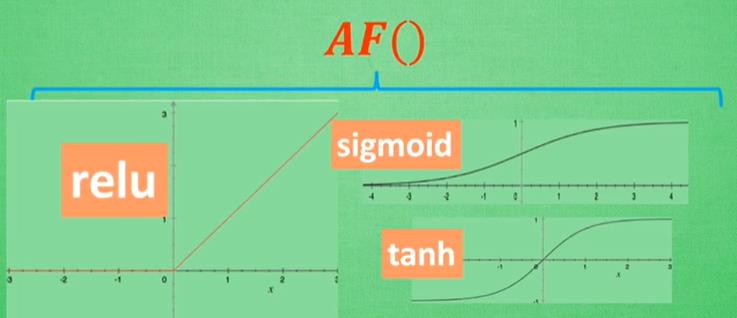
当神经网络有很多层的时候,不能随意使用激活函数,因为很有可能造成梯度爆炸或者梯度消失
默认首选激励函数:
卷积神经网络中:relu
循环神经网络中:relu or tanh
激励(激活)函数(activation function)
import torch
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
x=torch.linspace(-5, 5,200)#-5到5的200个数据
x=Variable(x)
x_np=x.data.numpy()#画图的时候要用numpy类型的数据
y_relu=F.relu(x).data.numpy()
y_sigmoid=F.sigmoid(x).data.numpy()
y_tanh=F.tanh(x).data.numpy()
y_softplus=F.softplus(x).data.numpy()
#画图,感觉类似于matlab里面作图
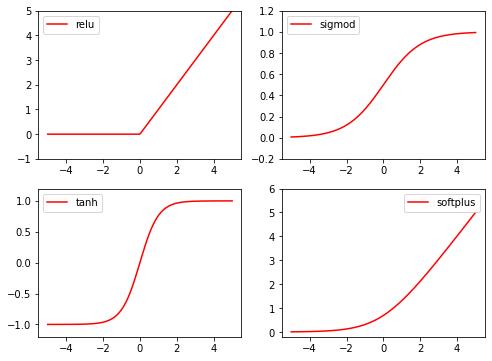
plt.figure(1,figsize=(8,6))
plt.subplot(221)
plt.plot(x_np,y_relu,c='red',label='relu')
plt.ylim(-1,5)
plt.legend(loc='best')
plt.subplot(222)
plt.plot(x_np,y_sigmoid,c='red',label='sigmod')
plt.ylim(-0.2,1.2)
plt.legend(loc='best')
plt.subplot(223)
plt.plot(x_np,y_tanh,c='red',label='tanh')
plt.ylim(-1.2,1.2)
plt.legend(loc='best')
plt.subplot(224)
plt.plot(x_np,y_softplus,c='red',label='softplus')
plt.ylim(-0.2,6)
plt.legend(loc='best')
结果图为:
以上是关于Relu激励函数的主要内容,如果未能解决你的问题,请参考以下文章