X4740 为啥是2个核心4个逻辑处理器
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了X4740 为啥是2个核心4个逻辑处理器相关的知识,希望对你有一定的参考价值。
急求原因
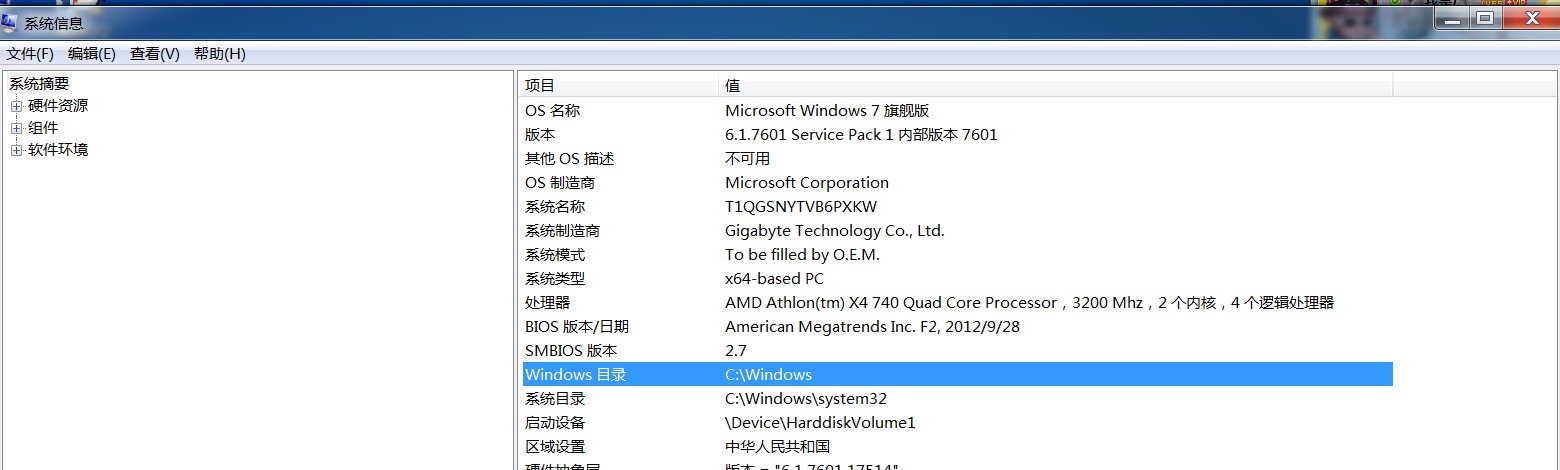
X4 740处理器的确是双核心四线程处理器。
1、AMD Athlon X4 740 Quad Core处理器参数一览:
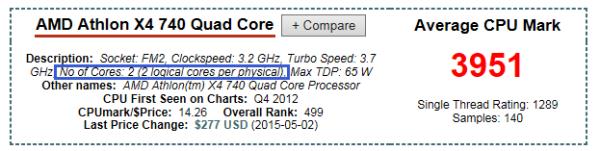
2、上图蓝色框内显示,该处理器具有两个物理核心,每个物理核心有两个逻辑核心。这点说明,AMD已经在该款处理器上使用类似intel超线程的技术了。
参考技术A 以下是搜索出来的:X4 740
插槽类型:Socket FM2
CPU主频:3.2GHz
制作工艺:32纳米
二级缓存:4MB
核心数量:四核心
核心代号:Trinity
热设计功耗(TDP):65W
适用类型:台式机
倍频:16倍
包装形式:盒装
动态超频最高频率:3.7GHz
64位处理器:是
是真4核心的,为什么是双模块4线程呢,因为这个CPU的制作是模块化的,就是说一个模块里面有两个物理核心,用两个模块就是4个物理核心!这种制作方法可以根据需要增加或者减少模块来增加或者减少核心很灵活!需要6核就再增加一个模块即可
双核4线程不是真的4个物理核心,只有两个物理核心然后然后软件模拟两个核心就是双核4线程!但是intel的CPU效率很高,所以就算是这样性能还是比AMD的CPU性能好!但是在4线程同时运行的时性能略低于真4核的AMD追问
意思是说这个CPU是其实是4核4线程对吧?
追答可以这么说,只不过两个核心分别放在两个模块里,跟intel的不一样,但是一样是四核四线程的
为啥 R 中的逻辑(布尔值)需要 4 个字节?
【中文标题】为啥 R 中的逻辑(布尔值)需要 4 个字节?【英文标题】:Why do logicals (booleans) in R require 4 bytes?为什么 R 中的逻辑(布尔值)需要 4 个字节? 【发布时间】:2012-02-28 23:58:23 【问题描述】:对于逻辑值向量,为什么 R 分配 4 个字节,而位向量每个条目会消耗 1 位? (有关示例,请参阅this question。)
现在,我意识到 R 还有助于存储 NA 值,但不能通过额外的位向量来完成吗?换句话说,为什么仅仅使用廉价的两位数据结构还不够?
不管怎样,Matlab 使用 1 个字节来进行逻辑运算,尽管它不利于 NA 值。我不确定为什么 MathWorks 对一位功能不满意,更不用说两位数据结构了,但他们有花哨的裤子营销人员...... . ;-)]
更新 1。我认为所提供的架构原因是有道理的,但这有点事后的感觉。 我还没有检查 32 位或 16 位 R 来查看它们的逻辑有多大 - 这可能会为这个想法提供一些支持。 从the R Internals manual 看来,逻辑向量 (LGLSXP) 和整数(INTSXP) 在每个平台上都是 32 位。我可以理解整数的通用大小,与字长无关。同样,逻辑的存储似乎也与字长无关。但它是如此之大。 :)
此外,如果 word size 参数如此强大,我觉得 Matlab(我认为它是 32 位 Matlab)只消耗 1 个字节似乎很奇怪 - 我想知道 MathWorks 是否选择通过权衡来提高内存效率用于编程复杂性和查找子词对象的一些其他开销。
此外,当然还有其他选项:正如 Brian Diggs 所指出的,bit 包促进了位向量,这对于上述问题中的问题非常有用(该任务的 8X-10X 加速是通过从 4 字节 logical 值转换为位向量)。尽管访问内存的速度很重要,但移动 30-31 个额外的无信息位(从信息论的角度来看)是浪费的。例如,可以使用类似用于整数的内存技巧described here - 获取一堆额外的内存(V 个单元),然后在位级别处理事物(例如bit())。为什么不这样做并为长向量保存 30 位(1 表示值,1 表示 NA)?
由于我的 RAM 和计算速度受布尔值影响,我打算改用 bit,但这是因为在某些情况下节省 97% 的空间很重要。 :)
我认为这个问题的答案将来自对 R 的设计或内部结构有更深入了解的人。最好的例子是 Matlab 对它们的逻辑使用不同的大小,在这种情况下,内存字大小不是答案。 Python 可能类似于 R,因为它的价值。
一种相关的表达方式可能是:为什么LGLSXP 在所有平台上都是 4 字节? (CHARSXP 通常会更小吗,那不是很好吗?为什么不更小,只是过度分配?)(更新使用CHARSXP 的想法可能是假的,因为CHARSXP 上的操作不如整数有用,例如sum。使用与字符相同的数据结构可能会节省空间,但会限制哪些现有方法可以对其进行操作。更合适的考虑是使用较小的整数,如下所述。)
更新 2。这里有一些非常好的和启发性的答案,特别是关于一个应该为了速度和编程效率的目标而实现布尔值的检索和处理。我认为 Tommy 的回答对于它在 R 中以这种方式出现的 为什么 特别合理,这似乎来自两个前提:
为了支持逻辑向量的加法(请注意,“逻辑”由编程语言/环境定义,与布尔值不同),最好通过重用代码来添加整数。在 R 的情况下,整数消耗 4 个字节。在 Matlab 的情况下,最小的整数是 1 个字节(即int8)。这可以解释为什么不同的东西写逻辑会令人讨厌。 [对于不熟悉R的人来说,它支持许多逻辑上的数值运算,例如sum(myVector)、mean(myVector)等]
传统支持使得除了在 R 和 S-Plus 中长期以来所做的事情之外,做其他事情变得极其困难。此外,我怀疑在 S、S-Plus 和 R 的早期,如果有人在做很多布尔运算,他们会在 C 中进行,而不是尝试在 R 中使用逻辑来做这么多的工作。
对于如何实现更好的布尔处理而言,其他答案非常棒 - 不要天真地假设一个人可以获取任何单个位:加载一个单词,然后屏蔽不属于的位是最有效的正如德瓦尔所描述的那样。如果有人为 R 的布尔操作编写专门的代码(例如我关于交叉表的问题),这是非常非常有用的建议:不要迭代位,而是在字级别工作。
感谢大家提供非常全面的答案和见解。
【问题讨论】:
寻址单个位比寻址单个字节要困难得多。 @SLaks 你能详细说明一下吗?我想我明白你的意思,但是对于非常大的向量来说,这会浪费很多空间和循环。 如果您寻址位,则在 32 位系统上最大内存为 512Mb。 【参考方案1】:其他答案已经得到了(可能的)架构原因,即逻辑向量的实现占用与整数相同的空间。我想指出bit 包,它实现了一位(没有NA)逻辑。
【讨论】:
确实如此。我应该是准确的:在我看来,位向量是布尔值的“幼稚”(即基线)数据结构。我很好奇为什么有人会消耗 31 个额外的位。这里更准确的答案还指出逻辑和布尔值不是一回事:例如,R 的logical() 支持NA。但我可以用来自bit() 的 2 个向量得到它,所以每个条目似乎仍然有 30 个多余的位,这似乎很贪吃。【参考方案2】:
对 R 和 S-Plus 有所了解,我会说 R 很可能这样做是为了与 S-Plus 兼容,而 S-Plus 很可能这样做是因为它是最简单的事情。 .
基本上,逻辑向量与整数向量相同,因此sum 和其他整数算法在逻辑向量上的工作几乎没有变化。
在 64 位 S-Plus 中,整数是 64 位的,因此也是逻辑向量!这是每个逻辑值 8 个字节...
@Iterator 当然是正确的,逻辑向量应该以更紧凑的形式表示。由于已经有一个 1 字节的 raw 向量类型,因此将其用于逻辑似乎也是一个非常简单的更改。每个值 2 位当然会更好——我可能会将它们保留为两个单独的位向量(TRUE/FALSE 和 NA/Valid),如果没有 NA,NA 位向量可能为 NULL...
无论如何,这主要是一个梦想,因为有太多 RAPI 包(使用 R C/FORTRAN API 的包)会破坏......
【讨论】:
“每个逻辑值 8 个字节 ...”:请警告我下次你要对我这样做时,要得到嗅盐。 :) 顺便说一句,你能澄清“RAPI”的所有含义吗?我假设您的意思是 R 的 C 接口,对吗? 是的,8 字节的布尔值是可憎的,R 可能仍然会复制它……是的,RAPI 我的意思是 R API,它是 R 的 C/FORTRAN 接口。跨度>
这个遗留的想法非常合理。除了将sum 重新用于整数相加的目的外,我倾向于相信这可以解释问题。事实上,另一个问题是这是 R 中提供的最小数值类型,而 Matlab 有 1 字节整数。【参考方案3】:
在完全不了解 R 的情况下,我怀疑与 C 的原因大致相同,因为加载等于处理器本机字大小的大小要快得多。
加载单个位会很慢,尤其是从位域加载,因为您必须屏蔽不适用于特定查询的位。用一个完整的词,您可以将其加载到注册表中并完成它。由于大小差异通常不是问题,默认实现是使用字大小的变量。如果用户想要其他东西,总是可以选择手动进行所需的位移。
关于打包,至少在某些处理器上,它会导致从非对齐地址读取错误。因此,虽然您可以声明一个结构,其中包含一个 byte 并被两个 int 包围,但 byte 可能会被填充为 4 字节大小。同样,我对 R 没有任何特别的了解,但出于性能原因,我怀疑这种行为可能是相同的。
对数组中的单个字节进行寻址比较复杂,假设您有一个数组bitfield 并希望在其中寻址位x,代码将是这样的:
bit b = (bitfield[x/8] >> (x % 8)) & 1
为您请求的位获取 0 或 1。与从布尔数组获取值数 x 的直接数组寻址相比:bool a = array[x]
【讨论】:
谢谢,这很有趣,还有其他反馈。尽管如此,4 个字节仍然是对空间的巨大浪费。我理解位寻址的差异,但是什么可以证明 4 字节与 1 字节是合理的,例如与字符或短整数一样?在我的另一个问题中,通过从 4 字节逻辑切换到位向量来更快地执行任务,因为移动数据需要很多时间。我感觉 R 开发人员做出了我们尚未意识到的权衡决定。 对于字符,大小很重要。由于这些通常代表更多的数据,因此减小大小很重要。在非常特定的应用程序中可能会出现这种情况,由于引用的局部性等原因,位向量可能会提高性能,但这些情况可能很少而且相差甚远。通常你想要一个在本地使用的布尔值,在这种情况下,一个四字节的变量要快得多。 这是一个非常有用的答案。虽然我只能选择一个,但从上下文/历史的角度来看,似乎 Tommy 给出了最适合 为什么 事物在 R 中的方式的答案。但是,您的回答对于速度和简化布尔处理实现时的问题非常有用,这对于未来的专用代码更有用,非常感谢。 如果您实际上尝试对紧凑位向量与“每个值的 int”进行一些实际操作,您会发现紧凑位向量通常会在性能方面获胜。在当前的处理器上,内存访问很慢,位操作很快……而且您通常可以一次操作多个位(例如AND 操作)。以上是关于X4740 为啥是2个核心4个逻辑处理器的主要内容,如果未能解决你的问题,请参考以下文章